参考资料: 处理数值型特征 如何处理类别型特征? 特征工程:时间特征处理方式 特征处理之统计特征 AI基础:特征工程-文本特征处理
一、特征与目标的概念
特征:作为判断条件的一组输入变量,是做出判断的依据
目标:判断和预测的目标,模型的输出变量,是特征所产生的结果
- 特征( feature):数据中抽取出来的对结果预测有用的信息。
- 特征的个数就是数据的观测维度
- 特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程
- 特征工程一般包括特征清洗(采样、清洗异常样本),特征处理和特征选择
- 特征按照不同的数据类型分类,有不同的特征处理方法
- 数值型
- 类别型
- 时间型
- 统计型
- 文本型
二、数值型特征处理
2.1 归一化
- 特征与特征之间应该是平等的,区别应该体现在特征内部
- 例如房屋价格和住房面积的幅度是不同的,房屋价格可能在3000000~1500000(万)之间,而住房面积在40~300(平方米)之间,那么明明是平等的两个特征,输入到相同的模型中后由于本身的幅值不同导致产生的效果不同,这是不合理的

-
2.2 离散化
将原始连续值切断,转换为离散值
- 让座问题:假设我们要训练一个模型判断在公交车上应不应该给一个人让座,按照常理,应该是给年龄很大和年岭很小的人让座
- 对于以上让座问题中的年龄特征,对于一些模型,假设模型为y=θx,输入的x (年龄)对于最后的贡献是正/负相关的,即x越大越应该让座,但很明显让座问题中,年龄和是否让座不是严格的正相关或者负相关,这样只能兼顾年龄大的人,无法兼顾年大的人和年龄小的人
- 对于让座问题,我们可以使用阈值将年龄进行分段,将一个age特征分为多个特征, 将连续值离散化
- 在电商中,每个人对于价格的喜好程度不同,但它不一定是严格的正相关或负相关,某些人可能就喜欢某一价格段内的商品
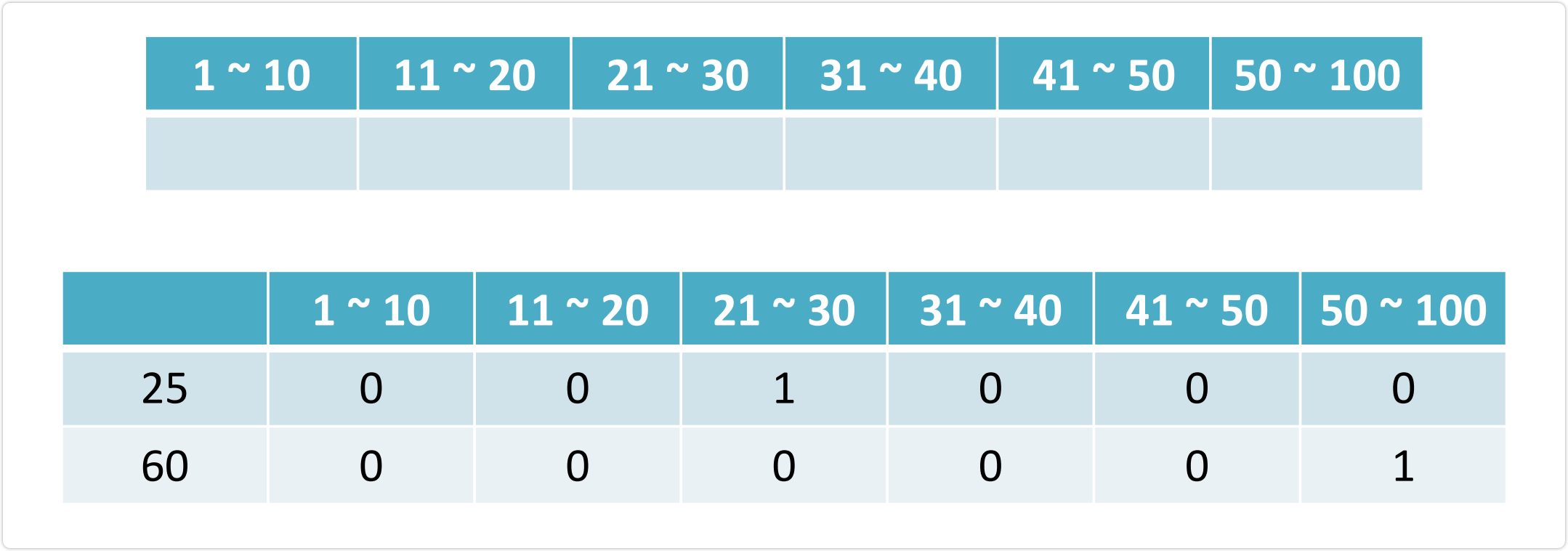
2.3.1 离散化的两种方式
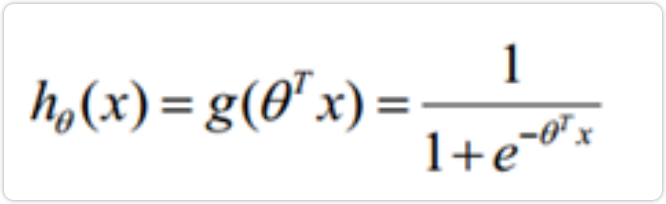
- 等频的离散化方法很精准,但需要每次都对数据分布进行一遍重新计算,因为昨天用户在淘宝上买东西的价格分布和今天不一定相同,因此昨天做等频的切分点可能并不适用, 而线上最需要避免的就是不固定,需要现场计算,所以昨天训练出的模型今天不一定能 使用
- 等频不固定,但很精准,等步长是固定的,非常简单,因此两者在工业上都有应用
2.3 特征缩放
用sklearn的MinMaxScaler来缩放一个特征数组,将一个数值型特征的值缩放到两个特定的值之间。
import numpy as npfrom sklearn import preprocessing#创建特征feature = np.array([[-500.5],[-100.1],[0],[100.1],[900.9]])#创建缩放器minmax_scale = preprocessing.MinMaxScaler(feature_range=(0,1))#缩放特征的值scaled_feature = minmax_scale.fit_transform(feature)#查看特征print(scaled_feature)
array([[0. ],[0.28571429],[0.35714286],[0.42857143],[1. ]])
2.4 特征标准化
对一个特征进行转换,使其平均值为0,标准差为1.
import numpy as npfrom sklearn import preprocessing#创建特征x = np.array([[-1000.1],[-200.2],[500.5],[600.6],[9000.9]])#创建缩放器scaler = preprocessing.StandardScaler()#转换特征standardized = scaler.fit_transform(x)#查看特征print(standardized)
array([[-0.76058269],[-0.54177196],[-0.35009716],[-0.32271504],[ 1.97516685]])
三、类别型特征处理
类别型数据本身没有大小关系,需要将它们编码为数字,但它们之间不能有预先设定的大小关系,因此既要做到公平,又要区分开它们,那么直接开辟多个空间
3.1 标签编码
第一种处理方法是标签编码,其实就是直接将类别型特征从字符串转换为数字,有两种处理方法:
3.1.1 直接替换字符串
转为 category 类型后标签编码
直接替换字符串,算是手动处理,实现如下所示,这里用 body_style 这列特征做例子进行处理,它总共有 5 个取值方式,先通过 value_counts方法可以获取每个数值的分布情况,然后映射为数字,保存为一个字典,最后通过 replace 方法进行转换。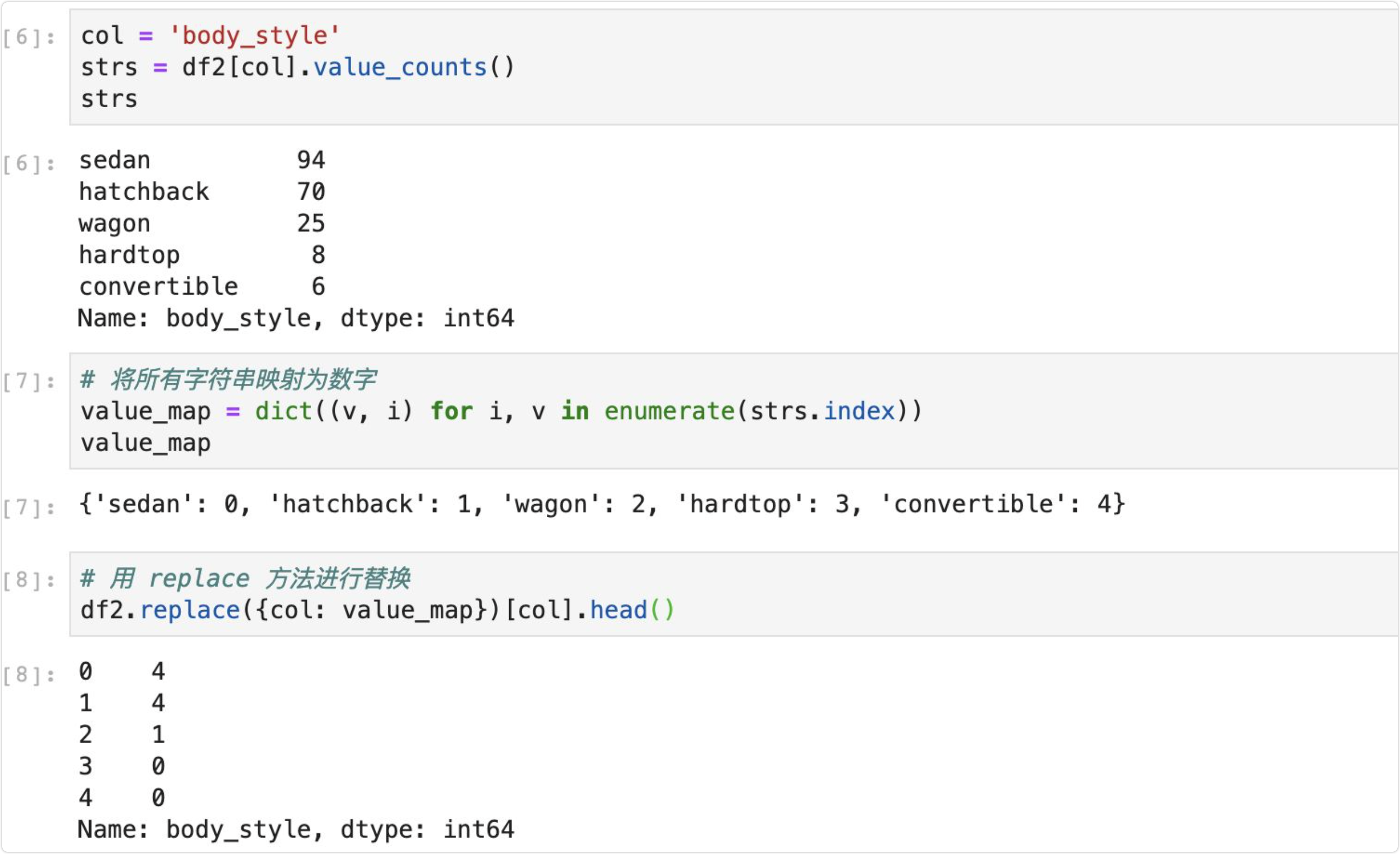
3.1.2 该列特征转化为 category 特征,然后再用编码得到的作为数据

3.2 自定义二分类
第二种方法比较特别,将所有的类别分为两个类别,这里用 engine_type 特征作为例子,假如我们仅关心该特征是否为 ohc ,那么我们就可以将其分为两类,包含 ohc 还是不包含,实现如下所示: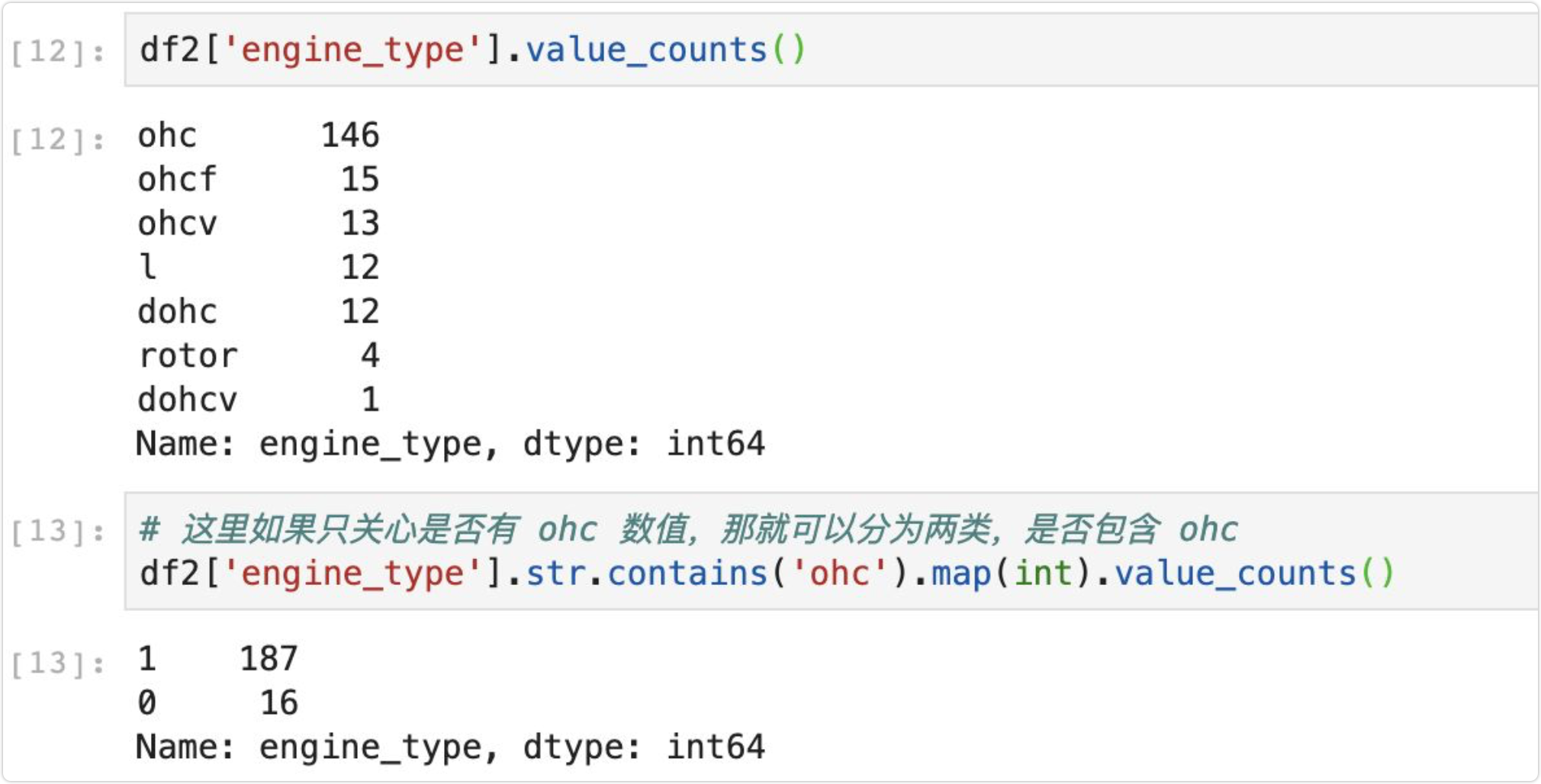
3.3 One-Hot编码
- One-Hot编码/哑变量所做的就是将类别型数据平行地展开,也就是说,经过One-Hot编码/哑变量后,这个特征的空间会膨胀
- 常用于处理特征不同类别间具有大小关系的数据。例如成绩等级(A、B、C),对应成绩越来越好。转换后为(3,2,1),依然保留大小关系
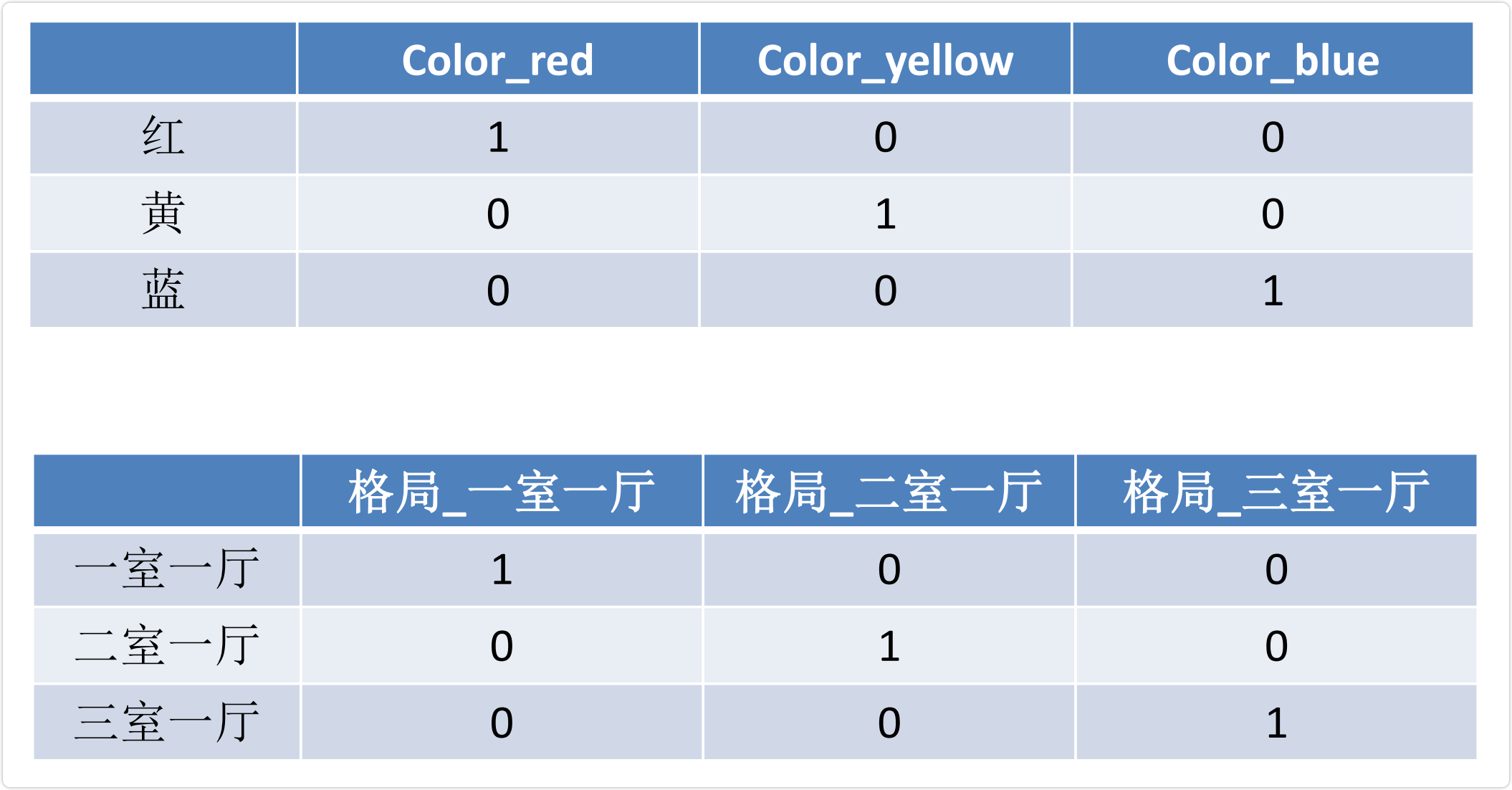
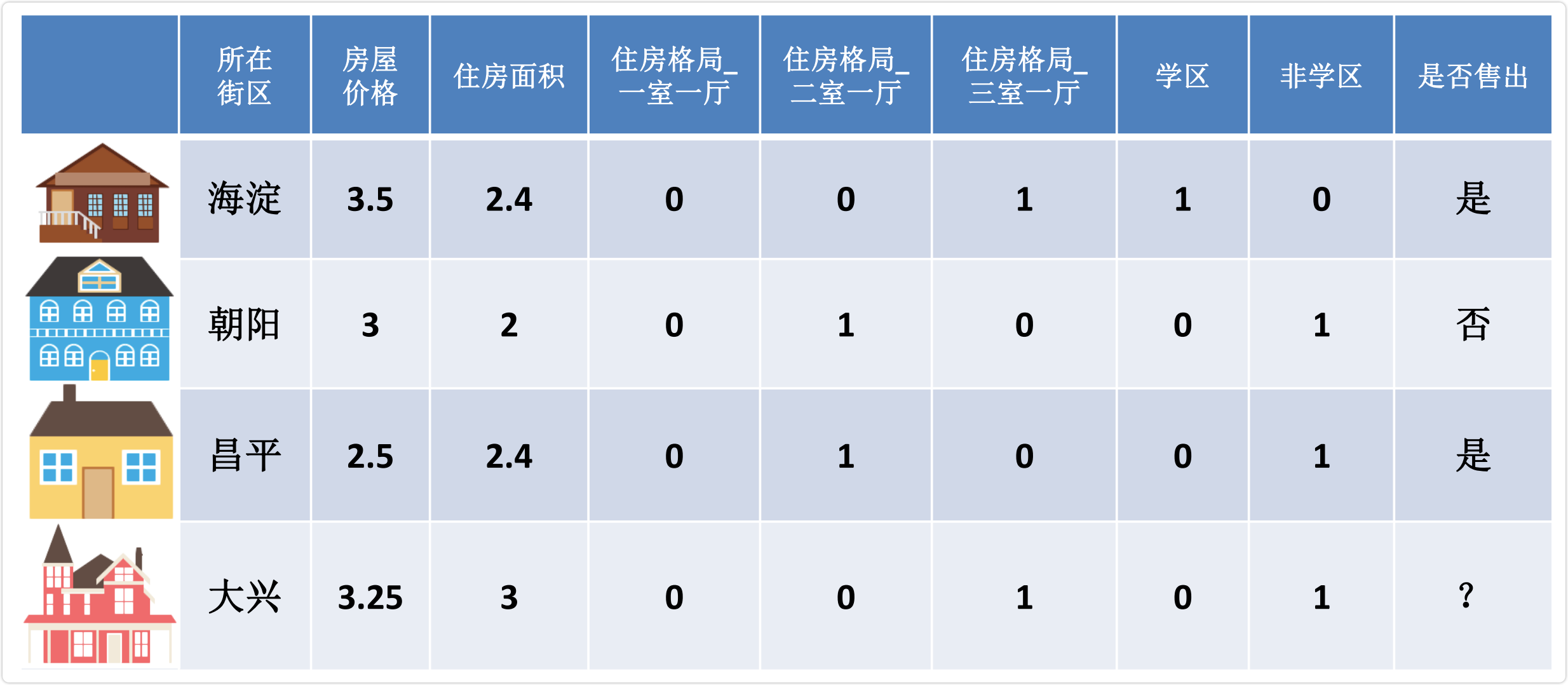
实现 One-hot 编码有以下 3 种方法:
- Pandas 的 get_dummies
- Sklearn 的 DictVectorizer
- Sklearn 的 LabelEncoder+OneHotEncoder
3.3.1 pandas-get_dummies
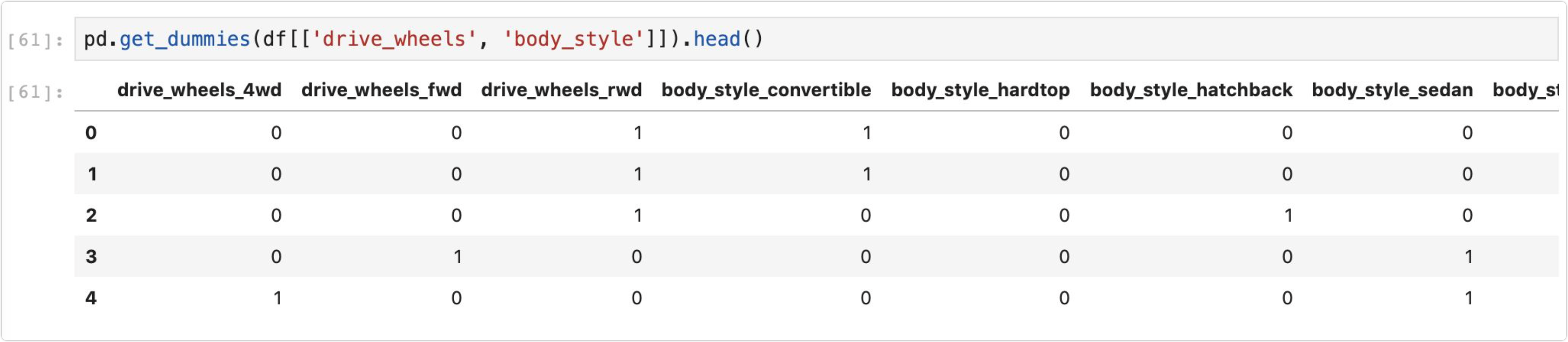
3.3.2 sklearn-DictVectorizer
第二种方法—Sklearn 的 DictVectorizer,这首先需要将 dataframe 转化为 dict 类型,这可以通过 to_dict ,并设置参数 orient=records,实现代码如下所示: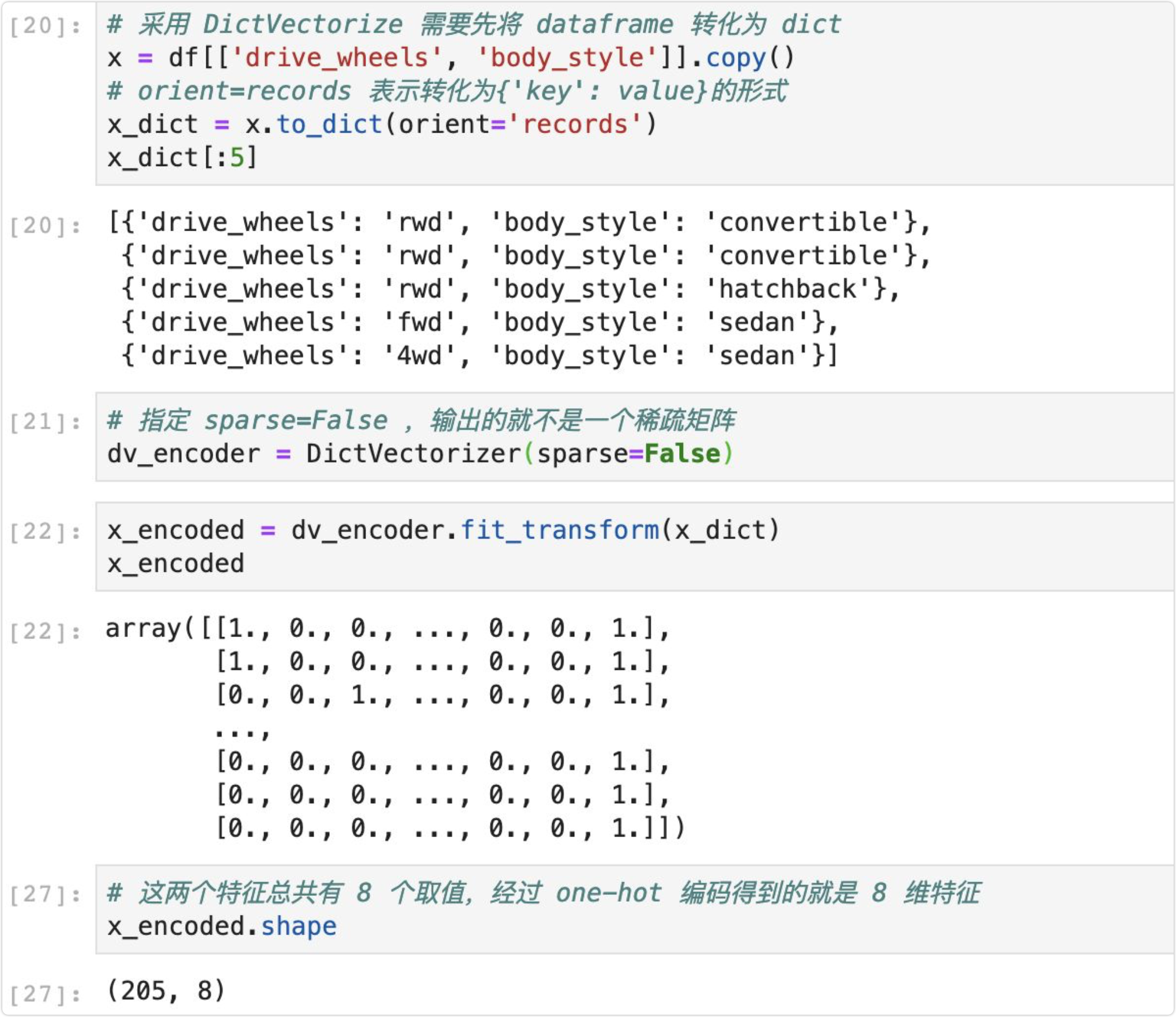
3.3.3 sklearn-LabelEncoder+OneHotEncoder
第三种方法—Sklearn 的 LabelEncoder+OneHotEncoder
首先是定义 LabelEncoder,实现代码如下,可以发现其实它就是将字符串进行了标签编码,将字符串转换为数值,这个操作很关键,因为 OneHotEncoder 是不能处理字符串类型的,所以需要先做这样的转换操作: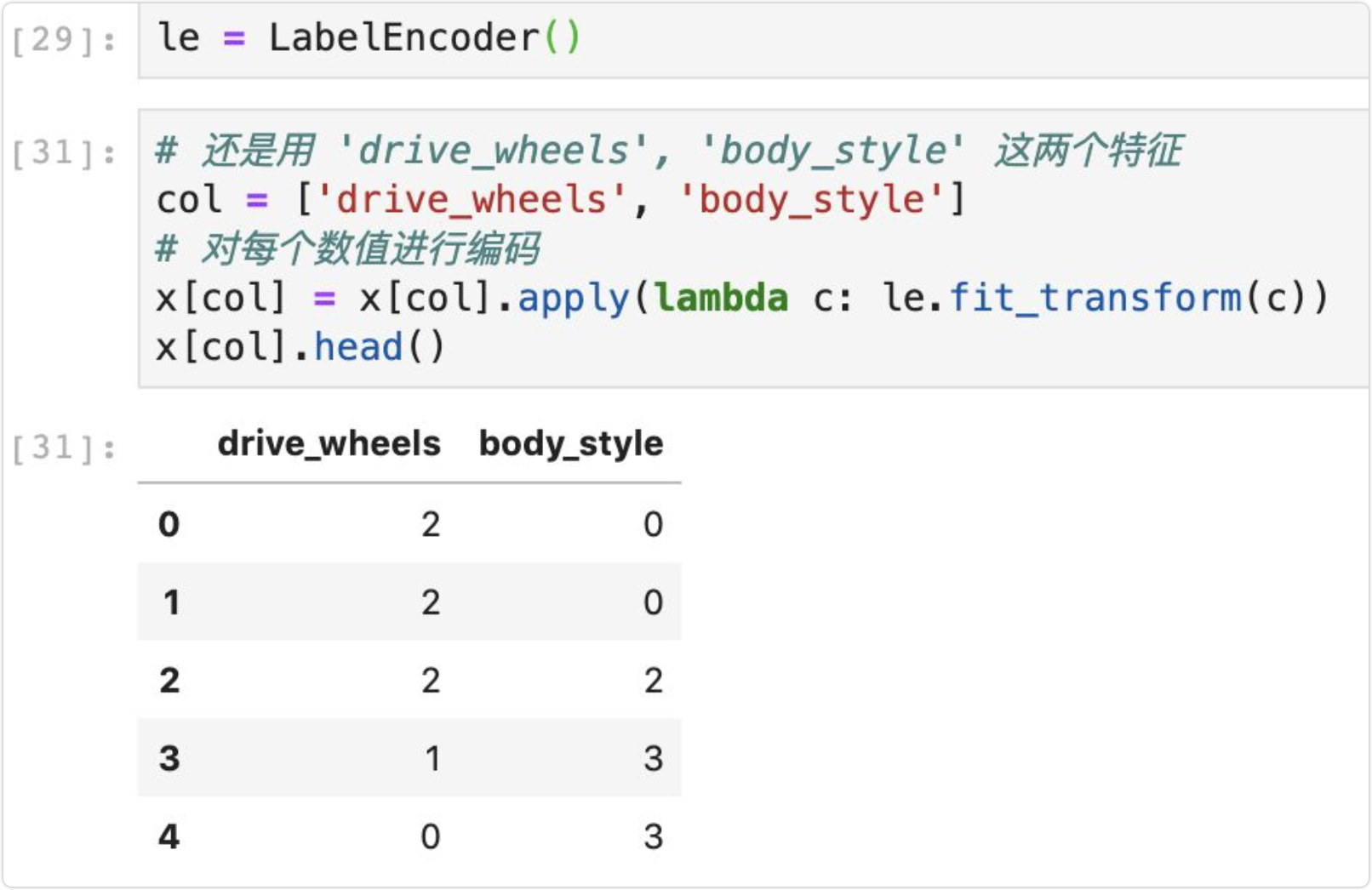
接着自然就是进行 one-hot 编码了,实现代码如下所示:
此外,采用 OneHotEncoder 的一个好处就是可以指定特征的维度,这种情况适用于,如果训练集和测试集的某个特征的取值数量不同的情况,比如训练集的样本包含这个特征的所有可能的取值,但测试集的样本缺少了其中一种可能,那么如果直接用 pandas 的get_dummies方法,会导致训练集和测试集的特征维度不一致了。
实现代码如下所示: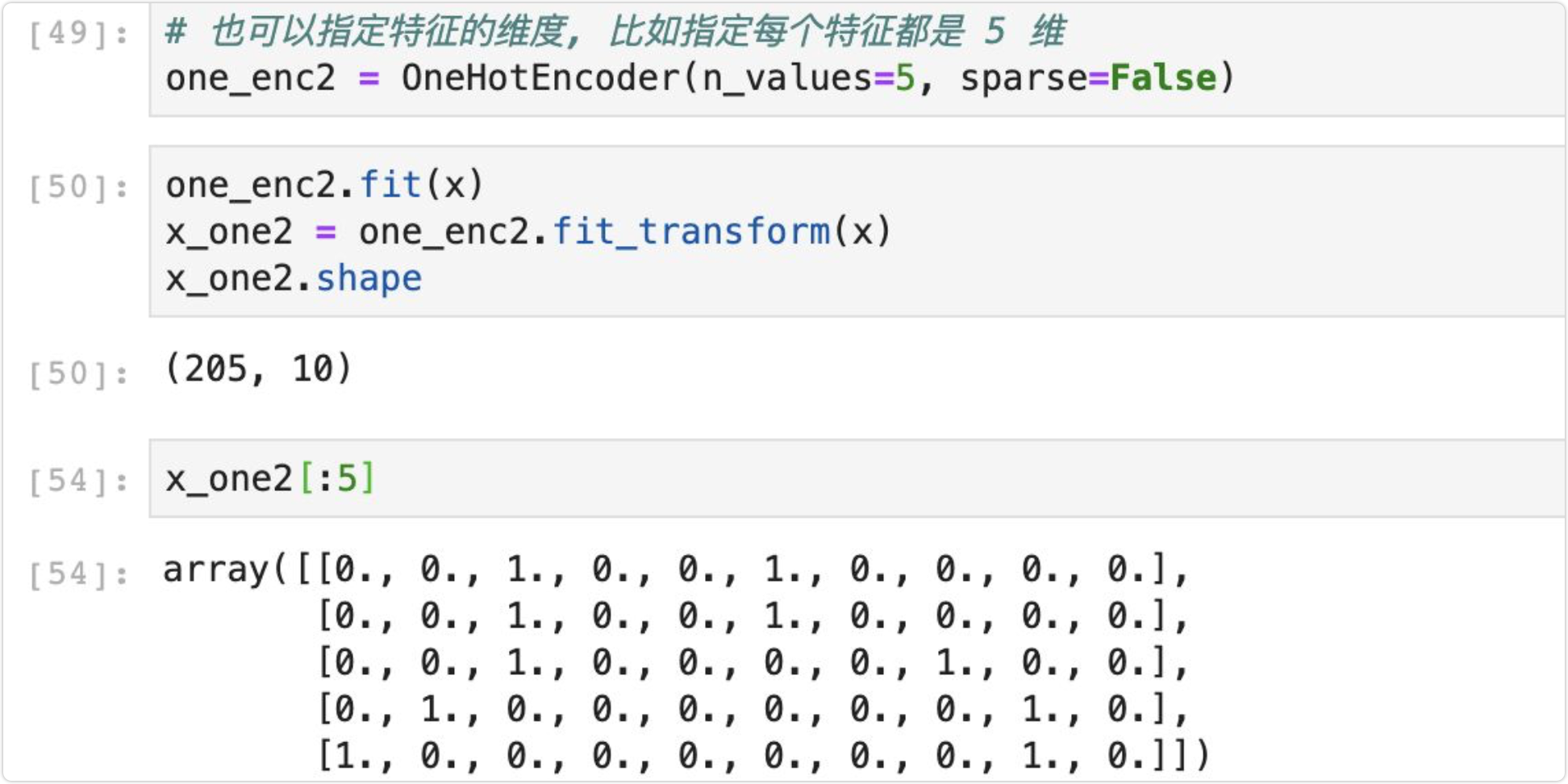
四、时间型特征处理
时间型特征既可以做连续值,又可以看做离散值。
- 连续值
- 持续时间(网页浏览时长)
- 间隔时间(上ー次购买/点击离现在的时间间隔)
- 离散值
- 一天中哪个时间段
- 一周中的星期几
- 一年中哪个月/星期
- 工作日/周末
4.1 时间本身的特征
如:用户在购买网站上的浏览、购买、收藏的时间;产品在购物网站上的上线时间;顾客在银行的存款和借款时间等。
形式:日期、时间戳等。
方法:将时间变量作为类别变量处理。
4.2 时间变量之间的组合特征
如:计算产品上线到现在经过了多长时间;顾客上次借款距离现在的时间隔;两个时可间隔之间是否包含节假日或其他特殊日期等。
方法:根据两个或多个时间变量的含义,进行特征组合。
4.3 时间序列相关特征
如:股票价格;天气温度;降雨量;订单量等 目的:基于历史数据预测未来信息。 方法:滞后特征、滑动窗口统计特征。
滞后特征:时间序列预测问题转化为监督学习问题的一种经典方法。 滑动窗口统计特征
例妙如计算前n个值的均值或者前n个值中每个类別的分布。
时间窗口的选取可以有多种方式,滞后特征是滑动窗口统计的一种特例,对应时间窗口宽度是1。
另一种常用的窗口设置包含所有历史数据,成为扩展窗口统计。
五、统计型特征处理
- 加权平均:商品价格高于平均价格多少,用户在某个品类下消费超过多少。
- 这个用户所买商品高于所有用户购买商品平均价格的多少(权衡一个人的消费能力),用户连续登录天数超过平均多少(表明这个用户对该产品的黏性)
- 分位线:商品属于售出商品价格的分位线处。
- 商品属于售出商品价格的多少分位线处。(比如20%,说明20%的人买东西都不会低于这个价格)。
- 次序性:商品处于热门商品第几位。
- 排在第几位。
- 比例类:电商中商品的好/中/差评比例。
- 电商中,某商品在某电商平台好/中/差评的比例
六、文本型特征处理
更多案例代码参考:AI基础:特征工程-文本特征处理
6.1 词袋
文本数据预处理后,去掉停用词,剩下的词组成的list,在词库中的映射稀疏向量。Python中用CountVectorizer处理词袋.
在词袋特征中,文本文档被转换成向量。(向量只是 n 个数字的集合。)向量包含词汇表中每个单词可能出现的数目。如果单词”aardvark”在文档中出现三次,则该特征向量在与该单词对应的位置上的计数为 3。如果词汇表中的单词没有出现在文档中,则计数为零。例如,“这是一只小狗,它是非常可爱”的句子具有如图所示的 BOW 表示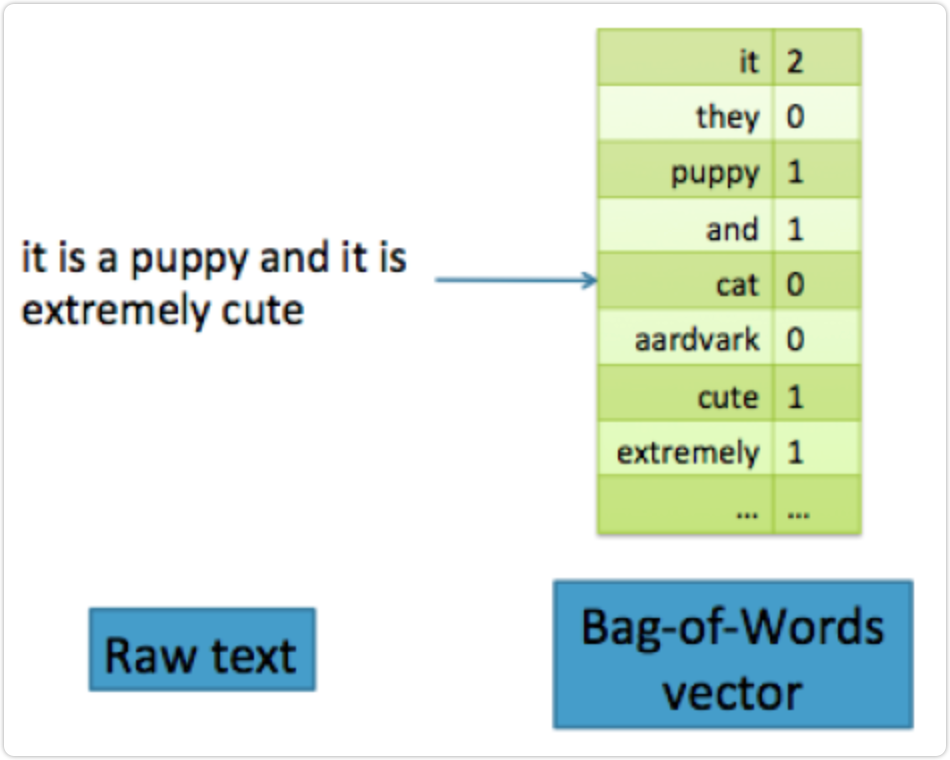
from sklearn.feature_extraction.text import CountVectorizerprint (norm_corpus)cv = CountVectorizer(min_df=0., max_df=1.)cv.fit(norm_corpus)print (cv.get_feature_names())cv_matrix = cv.fit_transform(norm_corpus)cv_matrix = cv_matrix.toarray()cv_matrix
['sky blue beautiful' 'love blue beautiful sky''quick brown fox jumps lazy dog' 'brown fox quick blue dog lazy''sky blue sky beautiful today' 'dog lazy brown fox quick']['beautiful', 'blue', 'brown', 'dog', 'fox', 'jumps', 'lazy', 'love', 'quick', 'sky', 'today']array([[1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0],[1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0],[0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0],[0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0],[1, 1, 0, 0, 0, 0, 0, 0, 0, 2, 1],[0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0]], dtype=int64)
vocab = cv.get_feature_names()pd.DataFrame(cv_matrix, columns=vocab)
beautiful blue brown dog fox jumps lazy love quick sky today0 1 1 0 0 0 0 0 0 0 1 01 1 1 0 0 0 0 0 1 0 1 02 0 0 1 1 1 1 1 0 1 0 03 0 1 1 1 1 0 1 0 1 0 04 1 1 0 0 0 0 0 0 0 2 15 0 0 1 1 1 0 1 0 1 0 0
6.2 把词袋中的词扩充到n-gram
n-gram代表n个词的组合。比如“我喜欢你”、“你喜欢我”这两句话如果用词袋表示的话,分词后包含相同的三个词,组成一样的向量:“我 喜欢 你”。显然两句话不是同一个意思,用n-gram可以解决这个问题。如果用2-gram,那么“我喜欢你”的向量中会加上“我喜欢”和“喜欢你”,“你喜欢我”的向量中会加上“你喜欢”和“喜欢我”。这样就区分开来了。
Bag-of-N-gram 或者 bag-of-ngram 是 BOW 的自然延伸。n-gram 是 n 个有序的记号(token)。一个词基本上是一个 1-gram,也被称为一元模型。当它被标记后,计数机制可以将单个词进行计数,或将重叠序列计数为 n-gram。例如,”Emma knocked on the door”这句话会产生 n-gram,如”Emma knocked”,”knocked on”,”on the”,”the door”。N-gram 保留了文本的更多原始序列结构,故 bag-of-ngram可以提供更多信息。但是,这是有代价的。理论上,用 k 个独特的词,可能有 k 个独立的 2-gram(也称为 bigram)。在实践中,并不是那么多,因为不是每个单词后都可以跟一个单词。尽管如此,通常有更多不同的 n-gram(n > 1)比单词更多。这意味着词袋会更大并且有稀疏的特征空间。这也意味着 n-gram 计算,存储和建模的成本会变高。n 越大,信息越丰富,成本越高。
为了说明随着 n 增加 n-gram 的数量如何增加,我们来计算纽约时报文章数据集上的 n-gram。我们使用 Pandas 和 scikit-learn 中的CountVectorizer转换器来计算前 10,000 条评论的 n-gram。
bv = CountVectorizer(ngram_range=(2,2))bv_matrix = bv.fit_transform(norm_corpus)bv_matrix = bv_matrix.toarray()vocab = bv.get_feature_names()pd.DataFrame(bv_matrix, columns=vocab)
beautiful sky beautiful today blue beautiful blue dog blue sky brown fox dog lazy fox jumps fox quick jumps lazy lazy brown lazy dog love blue quick blue quick brown sky beautiful sky blue0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 11 1 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 02 0 0 0 0 0 1 0 1 0 1 0 1 0 0 1 0 03 0 0 0 1 0 1 1 0 1 0 0 0 0 1 0 0 04 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 1 15 0 0 0 0 0 1 1 0 1 0 1 0 0 0 0 0 0
6.3 使用TF-IDF特征
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF(t) = (词t在当前文中出现次数) / (t在全部文档中出现次数),IDF(t) = ln(总文档数/ 含t的文档数),TF-IDF权重 = TF(t) * IDF(t)。自然语言处理中经常会用到。
from sklearn.feature_extraction.text import TfidfVectorizer #中国 蜜蜂 养殖 它们的片频数都是20次tv = TfidfVectorizer(min_df=0., max_df=1., use_idf=True)tv_matrix = tv.fit_transform(norm_corpus)tv_matrix = tv_matrix.toarray()vocab = tv.get_feature_names()pd.DataFrame(np.round(tv_matrix, 2), columns=vocab)
beautiful blue brown dog fox jumps lazy love quick sky today0 0.60 0.52 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.60 0.001 0.46 0.39 0.00 0.00 0.00 0.00 0.00 0.66 0.00 0.46 0.002 0.00 0.00 0.38 0.38 0.38 0.54 0.38 0.00 0.38 0.00 0.003 0.00 0.36 0.42 0.42 0.42 0.00 0.42 0.00 0.42 0.00 0.004 0.36 0.31 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.72 0.525 0.00 0.00 0.45 0.45 0.45 0.00 0.45 0.00 0.45 0.00 0.00

若有收获,就点个赞吧
0 人点赞
