参考资料:
https://www.kaggle.com/code/frtgnn/pycaret-introduction-classification-regression/notebook
https://blog.csdn.net/weixin_42608414/article/details/123822096
https://blog.csdn.net/weixin_35888603/article/details/112663600
https://www.kaggle.com/code/frtgnn/pycaret-introduction-classification-regression/notebook
1、PyCaret介绍
PyCaret是Python中的一个开源、低代码的机器学习库,它自动化了机器学习工作流。它是一个端到端的机器学习和模型管理工具,可以加快机器学习实验的周期,并使你更有效率。
与其他开放源代码机器学习库相比,PyCaret是一个低代码库,可以用很少的代码来替换数百行代码。这使得实验具有指数级的速度和效率开发。
官方:https://www.pycaret.org
文档:https://pycaret.readthedocs.io/en/latest/
git:https://www.github.com/pycaret/pycaret
2、分类案例
读取数据集:
train = pd.read_csv('../input/titanic/train.csv')test = pd.read_csv('../input/titanic/test.csv')sub = pd.read_csv('../input/titanic/gender_submission.csv')
导入分类模型:
from pycaret.classification import *
查看数据类型:
clf1 = setup(data = train,target = 'Survived',numeric_imputation = 'mean',categorical_features = ['Sex','Embarked'],ignore_features = ['Name','Ticket','Cabin'],silent = True)
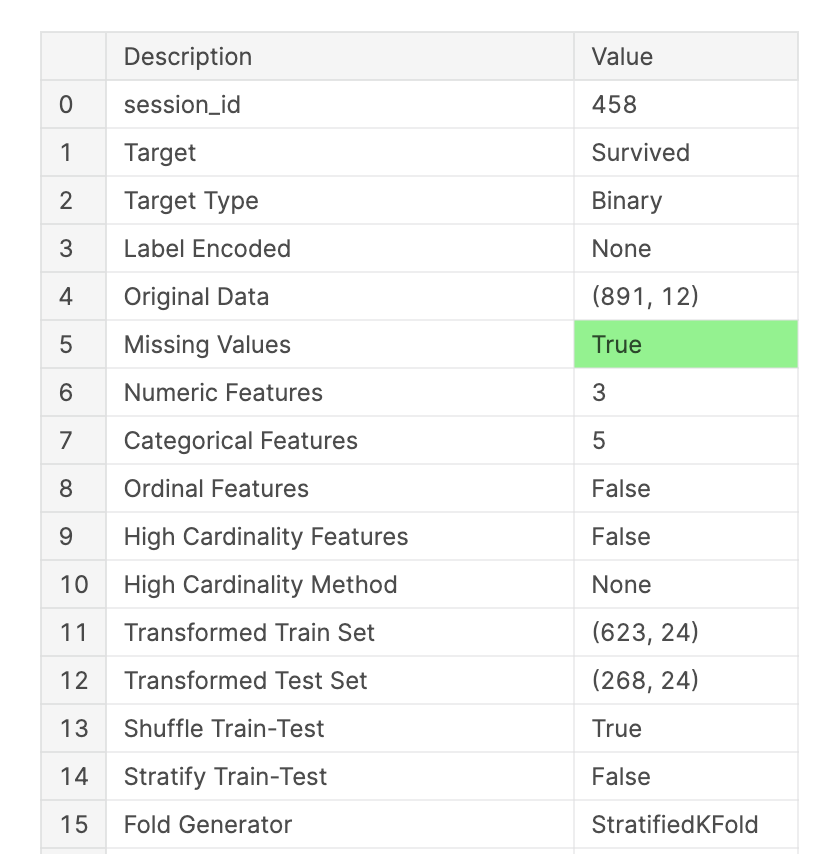
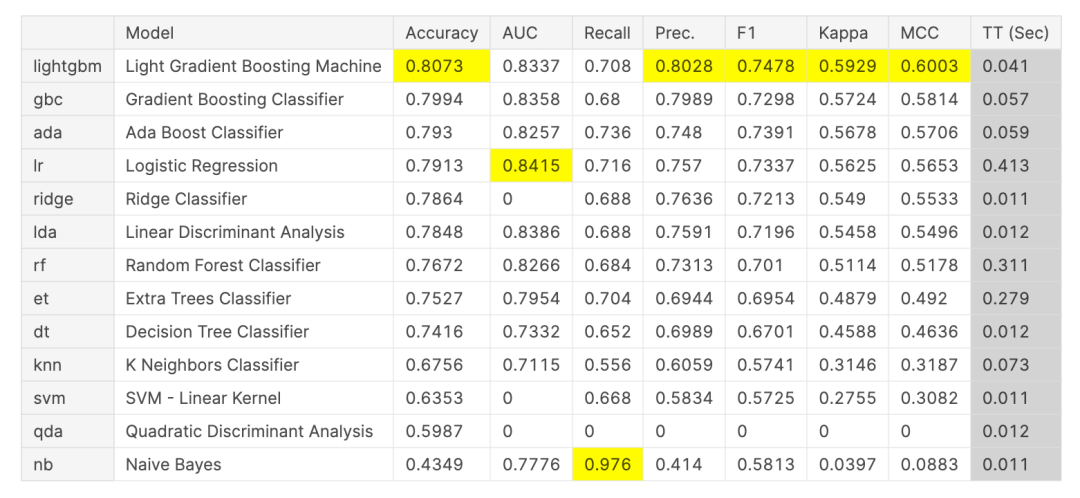
运行 & 对比精度:
compare_models()
创建单个模型:
lgbm = create_model('lightgbm')
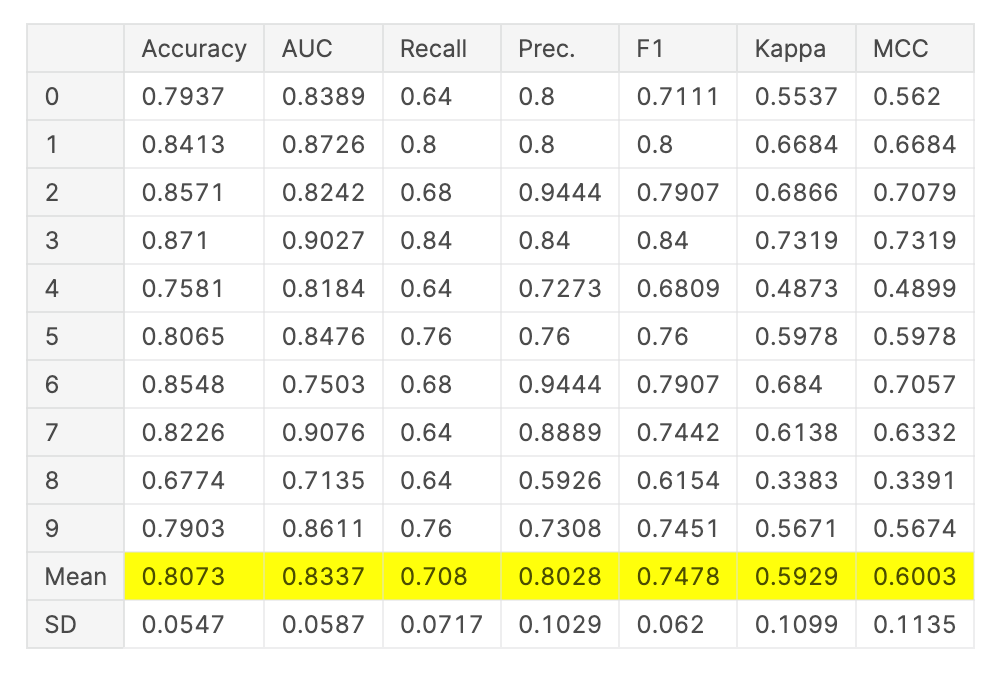
对单个模型进行调参:
tuned_lightgbm = tune_model(lgbm)plot_model(estimator = tuned_lightgbm, plot = 'learning')
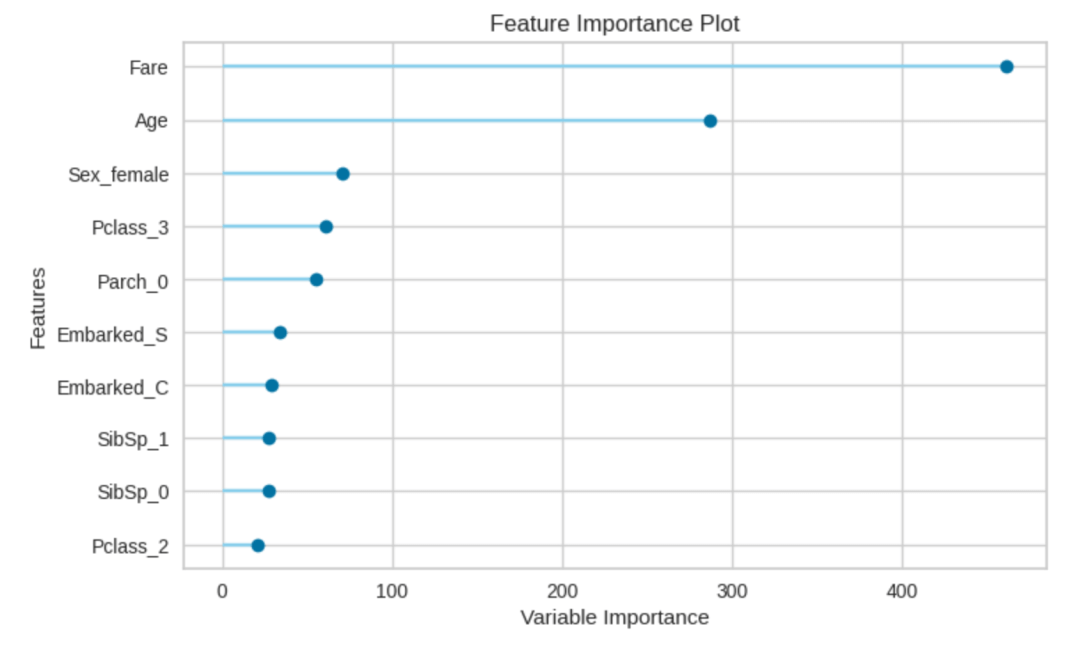
打印重要性:
plot_model(estimator = tuned_lightgbm, plot = 'feature')
对测试集进行预测:
predict_model(tuned_lightgbm, data=test)
3、回归案例
读取数据集:
train = pd.read_csv('../input/house-prices-advanced-regression-techniques/train.csv')test = pd.read_csv('../input/house-prices-advanced-regression-techniques/test.csv')sample= pd.read_csv('../input/house-prices-advanced-regression-techniques/sample_submission.csv')
导入回归模型:
from pycaret.regression import *
运行 & 对比精度:
compare_models()
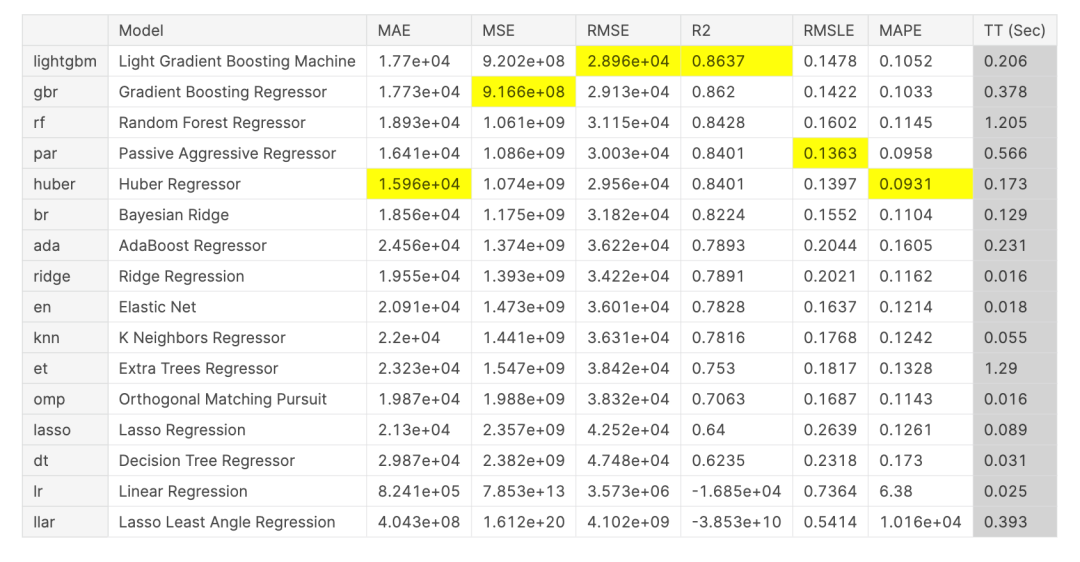
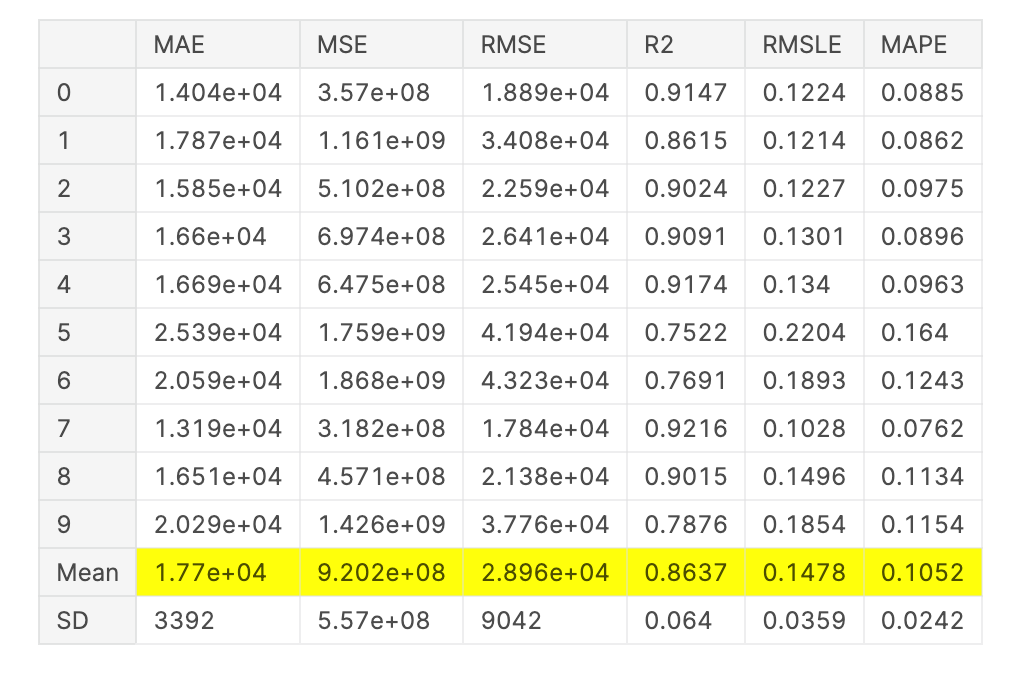
创建单个模型:
lgbm = create_model('lightgbm')
4、数据及代码
https://www.kaggle.com/code/frtgnn/pycaret-introduction-classification-regression/notebook
5、可能的Bugs
5.1 compare_models()返回结果为空数组
解决方案:添加参数查看报错信息
compare_models(errors = “raise”)
若报错信息为:UnicodeEncodeError: ‘ascii’ codec can’t encode characters
则找到对应的源码文件,将ascii改为utf-8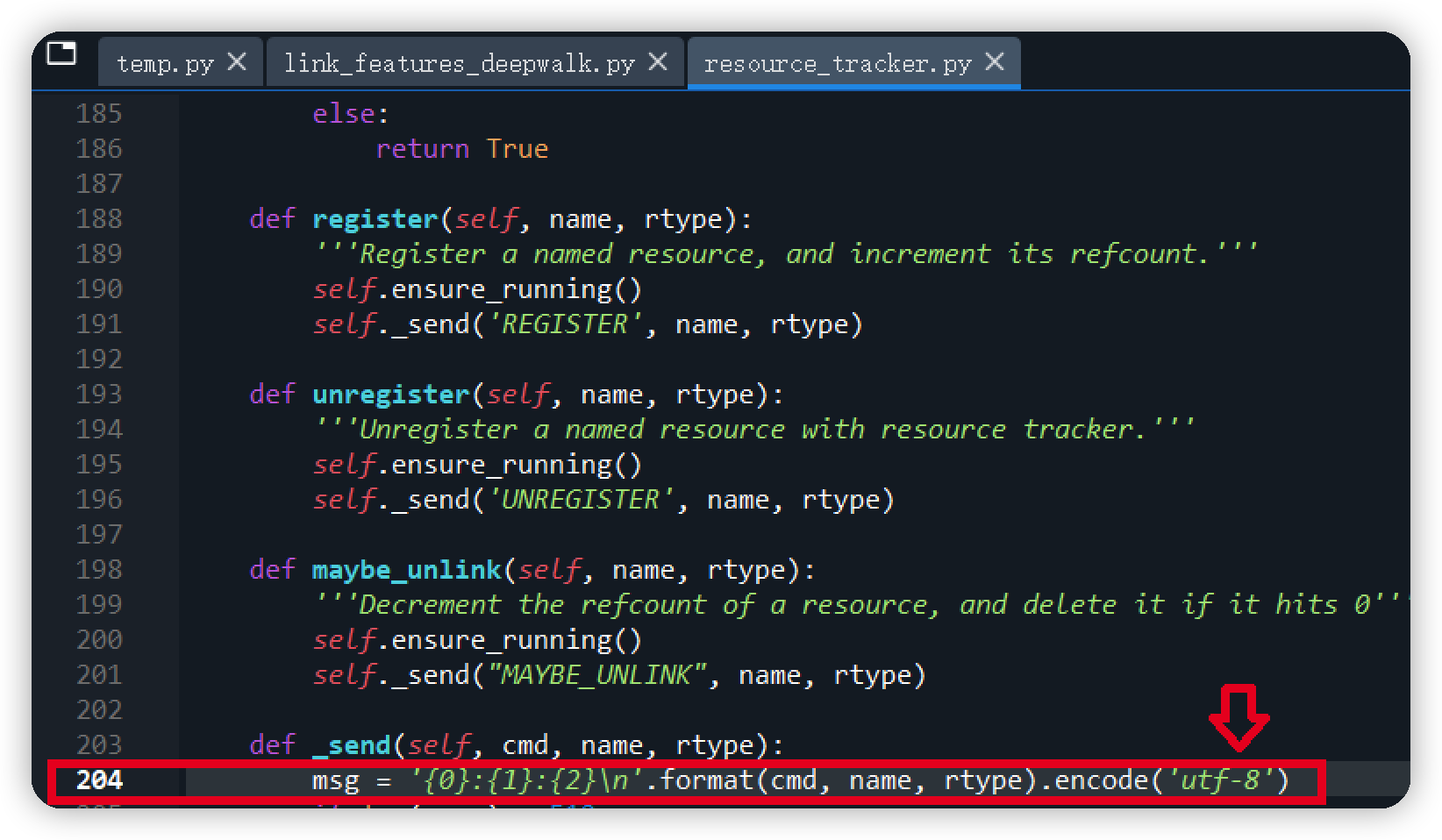

若有收获,就点个赞吧
0 人点赞
