一、机器学习算法概述
一个机器学习算法就是能从数据中学习到“知识”的一种方法。
在现实研究中,一般遇到的问题是:根据目标为给定的输入施加条件或算法,得到预期的结果。即无需训练样本,就可以把输入映射成目标输出。典型的例子就是:给定一个无序的集合,通过编写排序算法,将其编程有序的集合。
然而在很多时候,我们找不到理想的映射函数去获取想要的结果。幸运的是,我们依然可以依赖已有的实例数据(训练样本),通过机器学习把这种隐藏的知识(映射规律)挖掘出来,然后作用于新的输入得到新的输出,这个过程就是机器学习。
从构造模型的角度可以将机器学习理解为:从数据中产生模型的过程。
机器学习的典型过程,如图所示: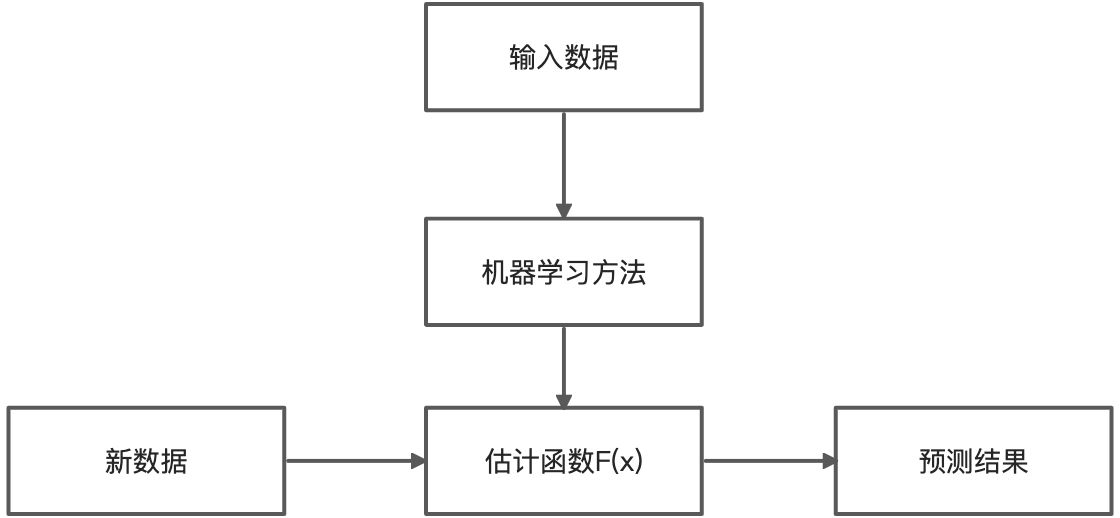
输入训练数据,利用特定的机器学习方法建立估计函数。在训练得到函数后,可将测试数据输入该函数,该函数的输出即预测结果。
由此可见,经过训练的函数有能力对没”见过“的数据进行正确估计,这就是机器学习的过程。
总之,机器学习就是根据系统的观测数据来研究预测理论并开发预测模型,进而做到自主地为后续研究和实际应用发现数据中的潜在规律性过程。
机器学习融合了多门学科,包括概率论、统计学、凸分析、最优化等,主要使用归纳、综合等方法从数据集中获取知识。机器学习致力于利用计算机模拟人类的学习行为来获取新的知识技能,进而重新组织已有的知识结构使其自身的性能不断得到改善。机器学习是将计算机智能化的根本途径,是人工智能的核心,目前已被应用于人工智能的各个领域,包括计算机视觉、语音识别、自然语言处理和智慧交通等。
1.1 机器学习解决的四大类问题
1、分类问题
分类就是将实例数据划分到合适的类中。一般使用大量已分类的数据作为算法的训练集。在训练集上进行建模并拟合数据的类别标签和数据各维度的属性关系,然后再测试集上进行验证。当新的样本再次进入算法时,就可以判断它到底属于K个类中的哪一个(K为所有类别的个数)。
具体来讲,学习的目标就是从训练集上得到映射函数f(x),该函数表示样本x到类别标签y的映射关系,且f(x)输出的是一个概率分布,它给出了样本x属于每一个类别的概率,概率取值最高的就是x的分类标签。例如给定一张照片,要求判断它属于什么物体;给定病人器官的检查报告结果,判断其是否患癌等。
2、回归分析
回归问题与分类问题类似,不同之处在于其目标变量的值是连续的,而非离散的。回归模型的焦点在于得到唯一的因变量和多个连续型解释变量之间的映射关系。该类问题中,机器学习算法在给定的输入下,将根据学得的映射关系输出连续性数值结果。例如 Alphago下棋问题,学习算法需要在当前棋局下判断最佳的落棋位置,就是计算每一个空位的得分,这就是一个回归问题。
3、聚类分析
所谓聚类,就是将相似的事物聚集在一起的过程,此为数据分析中的重要方法。古典生物学中,在没有动物种类划分的前提下,人们仅仅通过物种的形貌特征将其分门别类就是一种朴素的人工聚类。聚类与分类的不同之处在于,因缺少标签,所以在聚类分析之前并不知道会将数据分为多少类,而是通过属性分析然后将数据聚合成多个群体,使得某一对象与同一群体中的对象彼此相似,与其他群体中的对象不同。实际运用中,聚类分析是数据预处理过程,是进一步分析和归纳的前提。
4、关联分析
关联分析是数据挖掘领域中一种重要的技术手段,简单来讲就是在海量数据中发掘数据属性间的统计关系。沃尔玛超市的啤酒与尿布案例就是该方法最经典的运用。关联分析在商业领域中有重要地位,通过对大量的记录做分析,提取出对营销方案有重要影响的规则或者影响因素,从而挖掘潜在客户。关联分析也被泛应运于医疗、保险、电信等领域,主要是从繁复庞大的数据集中抽取事物之间的强关联规则,以辅助决策。
1.2 机器学习的分类
1、监督学习
训练数据集都是有标签的,比如患病和没有患病、某个时刻股票的价格。训练过程一般需要在训练集上满足一定的精确度,既不欠拟合也不过拟合,然后使用训练得到的模型对新样本做出推测。监督学习解决的问题通常是分类和回归,代表算法有逻辑回归LR和神经网络后向传播算法BP。
2、无监督学习
与监督学习相比,无监督学习的训练集是没有标签的,通过分析数据的已有结构和内部关系来建立模型。一般解决规则学习和聚类问题,代表算法有Apriori算法和k-means算法。
3、半监督学习
训练数据集的部分数据有标签,部分数据没有标签。该算法是针对于预测任务,但是模型必须在考虑数据已有结构的前提下做出预测,所以是监督学习和无监督学习的融合。其主要解决分类和回归问题,具体实施时需要在监督学习的算法上进行扩展,进而做到在部分没有标签的数据上建模。
4、强化学习
在这种学习方式中,一般是先构建模型,然后利用源自环境中的数据作为输入来刺激模型,根据得出的结果(反馈)反作用于模型,以便对模型进行修正。相较于监督学习,它的训练数据更多的是源于环境的反馈而非人为指定,该方法解决的问题倾向于系统控制和机器人控制等。
二、机器学习算法实施流程
一般来说,不同的业务场景需要使用不同的机器学习算法;但是,就算法的实施流程而言,基本都是一致的。使用机器学习算法时,一定要避免陷于算法本身,有时简单粗暴地套用现有算法并不能得到理想的结果,因为算法的选择依托于业务的需求和数据的特征。很多时候,对业务的理解程度决定了实施结果的好坏。所以“以业务需求为导向,具体问题具体分析,拒绝生搬硬套”应当成为机器学习实践的指导思想。
2.1 抽象为数学问题
对目标问题进行剖析并明确解决方向是机器学习的第一步。通常情况下,机器学习的训练过程是相当耗时的,如果进行无方向尝试,时间成本巨大。将目标任务抽象成数学问题,具体指的是在明确了已获取数据的类型和结构关系后,确定目标的问题类型,判断是回归、分类还是关联,或是聚类;如果都不是,则划归为与上述类型最接近的一类。
2.2 数据的获取
对机器学习而言,数据决定了预测结果的上限,而算法仅仅是尽可能逼近这个上限。为了防止过拟合,数据要有代表性。而且对于分类问题,不同类别的数据所占的比例尽量均匀,杜绝数量级上的差异。对数据量级的评估也很重要,依据样本个数和特征个数可以估算学习算法对机器硬件的消耗程度:如果出现内存溢出的情况,则要考虑数据降维,或者采用分布式。
2.3 特征的选择
优质数据发挥效力的前提在于提取良好的特征,提取特征的关键在于数据清洗和特征预处理,这样才能使算法的效果和性能得到品著的提升。数据的预处理(归一化、离散化、插值处理、去共线性等)往往占据数据挖掘过程的绝大部分时间,是机器学习的必经步骤。特征的选择需要对业务有深入的理解,好的特征即使作用于简单的算法也能达到良好稳定的预测效果。
2.4 模型训练与调优
这一步使用算法进行训练。如今的机器学习算法一般是被封装成黑盒,方便供他人使用,所以算法的参数对算法的性能至关重要,好的参数能使结果更加优良。算法调优的过程需要对算法的原理有深刻的理解,越是深入,越能发现问题所在,越能提出更好的调优方案。
2.5 模型诊断
通常我们建立的模型都会有过拟合或欠拟合问题,此时需要模型诊断技术解决该问题。过拟合的解决思路一般是增大训练数据集和降低模型复杂度;欠拟合一般采用提高特征数量和质量、增加模型复杂度等方法。除此之外还要进行误差分析。模型诊断和调优通常是配套进行、反复迭代的过程,需要不断尝试,从而达到最佳状态。
2.6 模型融合
一般而言,综合考虑多个模型的优势并将它们融合在一起,能够显著地提升预测性能。
2.7 线上部署
将模型运用到具体业务中去。工程上是以结果为导向,所以算法的线上运行效果直接决定了其成败。实际中,要综合考虑模型预测的准确度、误差承受度、运行速度、空间复杂度、魯棒性等多个指标,使得模型的运行能够满足业务的需要。
三、sklearn算法选择及模块介绍
3.1 sklearn-算法选择地图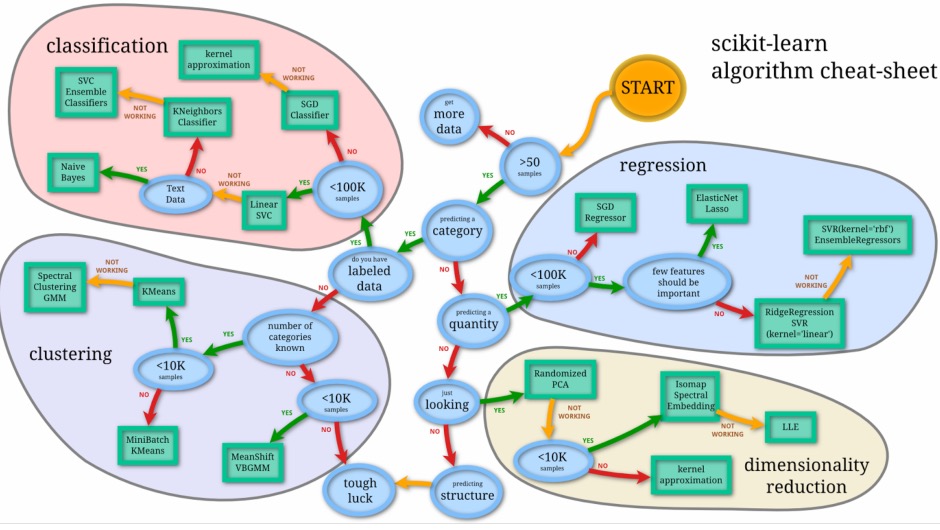
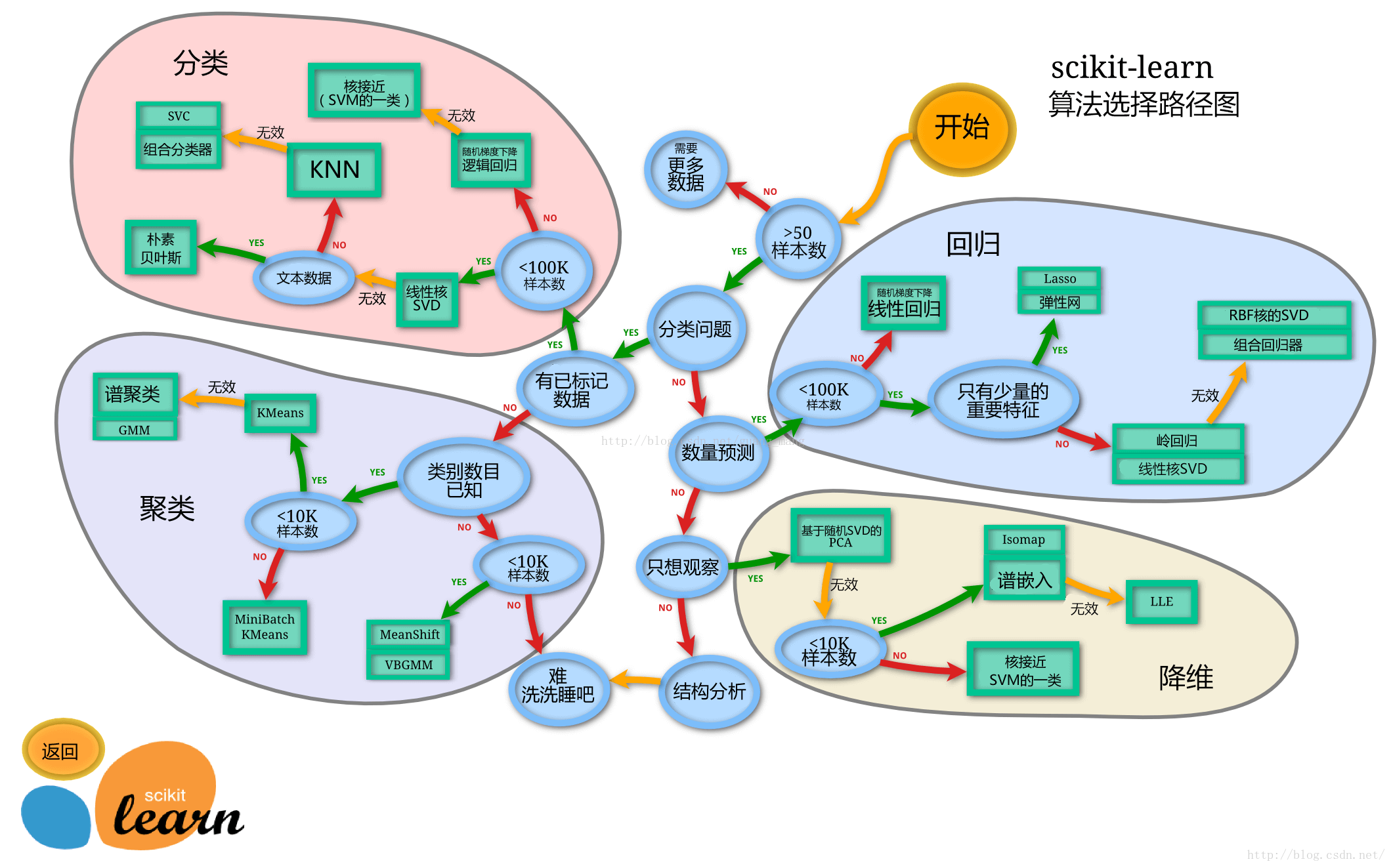
3.2 sklearn-各模块介绍(思维导图)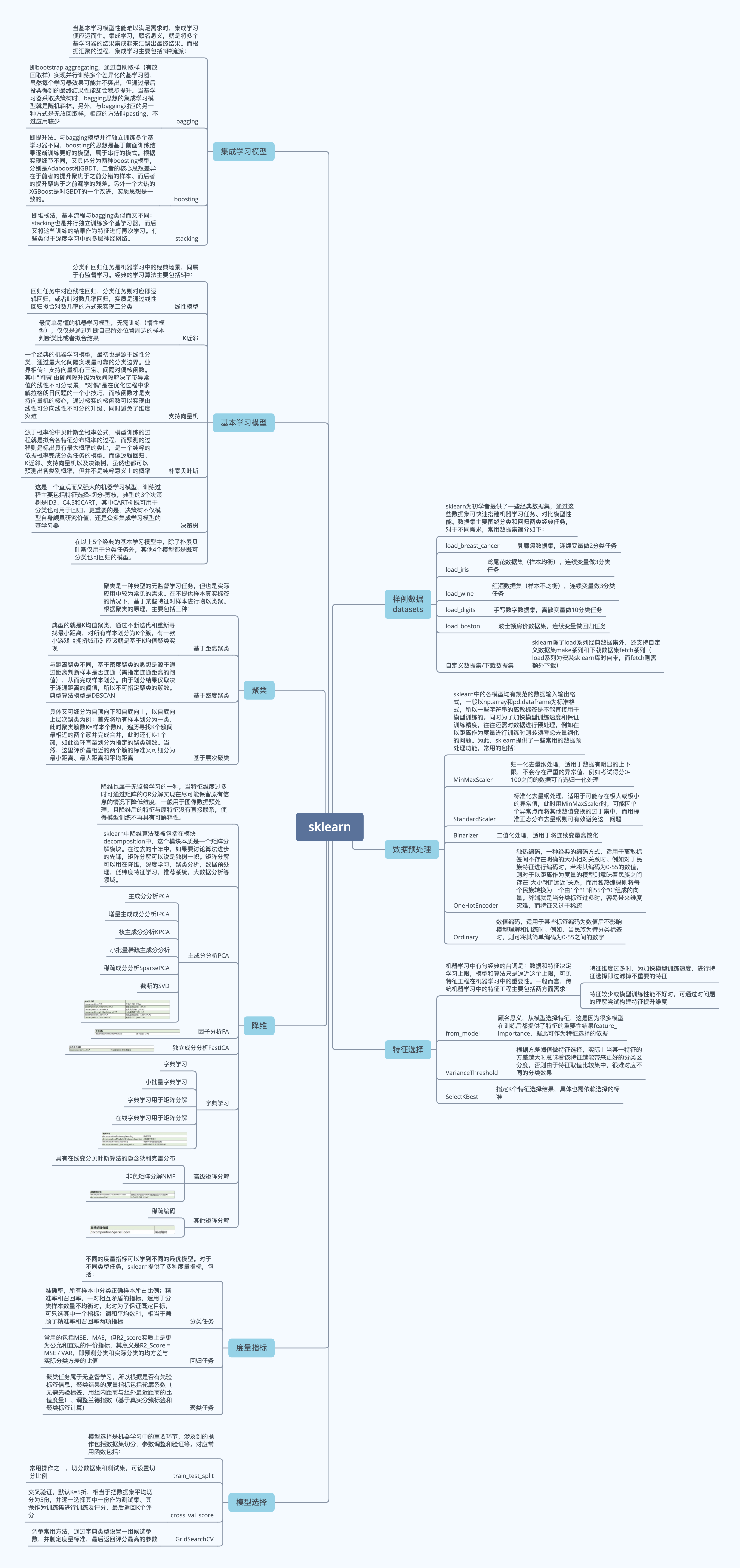

若有收获,就点个赞吧
0 人点赞
