圣人曾说过:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
再好的模型,如果没有好的数据和特征质量,那训练出来的效果也不会有所提高。数据质量对于数据分析而言是至关重要的,有时候它的意义会在某种程度上会胜过模型算法。
数据缺失的原因
首先我们应该知道:数据为什么缺失?数据的缺失是我们无法避免的,可能的原因有很多种,博主总结有以下三大类:
- 无意的:信息被遗漏,比如由于工作人员的疏忽,忘记而缺失;或者由于数据采集器等故障等原因造成的缺失,比如系统实时性要求较高的时候,机器来不及判断和决策而造成缺失;
- 有意的:有些数据集在特征描述中会规定将缺失值也作为一种特征值,这时候缺失值就可以看作是一种特殊的特征值;
- 不存在:有些特征属性根本就是不存在的,比如一个未婚者的配偶名字就没法填写,再如一个孩子的收入状况也无法填写;
总而言之,对于造成缺失值的原因,我们需要明确:是因为疏忽或遗漏无意而造成的,还是说故意造成的,或者说根本不存在。只有知道了它的来源,我们才能对症下药,做相应的处理。
数据缺失的类型
在对缺失数据进行处理前,了解数据缺失的机制和形式是十分必要的。将数据集中不含缺失值的变量称为完全变量,数据集中含有缺失值的变量称为不完全变量。而从缺失的分布来将缺失可以分为完全随机缺失,随机缺失和完全非随机缺失。
- 完全随机缺失(missing completely at random,MCAR):指的是数据的缺失是完全随机的,不依赖于任何不完全变量或完全变量,不影响样本的无偏性,如家庭地址缺失;
- 随机缺失(missing at random,MAR):指的是数据的缺失不是完全随机的,即该类数据的缺失依赖于其他完全变量,如财务数据缺失情况与企业的大小有关;
- 非随机缺失(missing not at random,MNAR):指的是数据的缺失与不完全变量自身的取值有关,如高收入人群不原意提供家庭收入;
对于随机缺失和非随机缺失,直接删除记录是不合适的,原因上面已经给出。随机缺失可以通过已知变量对缺失值进行估计,而非随机缺失的非随机性还没有很好的解决办法。
缺失处理
方式1:删除
直接去除含有缺失值的记录,这种处理方式是简单粗暴的,适用于数据量较大(记录较多)且缺失比较较小的情形,去掉后对总体影响不大。一般不建议这样做,因为很可能会造成数据丢失、数据偏移。
func: df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)# 1、删除‘age’列df.drop('age', axis=1, inplace=True)# 2、删除数据表中含有空值的行df.dropna()# 3、丢弃某几列有缺失值的行df.dropna(axis=0, subset=['a','b'], inplace=True)
直接去除缺失变量,基于第一步我们已经知道每个变量的缺失比例,如果一个变量的缺失比例过高,基本也就失去了预测意义,这样的变量我们可以尝试把它直接去掉。
# 去掉缺失比例大于80%以上的变量data=data.dropna(thresh=len(data)*0.2, axis=1)
方式2:常量填充
在进行缺失值填充之前,我们要先对缺失的变量进行业务上的了解,即变量的含义、获取方式、计算逻辑,以便知道该变量为什么会出现缺失值、缺失值代表什么含义。比如,‘age’ 年龄缺失,每个人均有年龄,缺失应该为随机的缺失,‘loanNum’贷款笔数,缺失可能代表无贷款,是有实在意义的缺失。全局常量填充:可以用0,均值、中位数、众数等填充。平均值适用于近似正态分布数据,观测值较为均匀散布均值周围;中位数适用于偏态分布或者有离群点数据,中位数是更好地代表数据中心趋势;众数一般用于类别变量,无大小、先后顺序之分。
# 均值填充data['col'] = data['col'].fillna(data['col'].means())# 中位数填充data['col'] = data['col'].fillna(data['col'].median())# 众数填充data['col'] = data['col'].fillna(stats.mode(data['col'])[0][0])
也可以借助Imputer类处理缺失:
from sklearn.preprocessing import Imputerimr = Imputer(missing_values='NaN', strategy='mean', axis=0)imputed_data =pd.DataFrame(imr.fit_transform(df.values),columns=df.columns)imputed_data
方式3:插值填充
采用某种插入模式进行填充,比如取缺失值前后值的均值进行填充:
# interpolate()插值法,缺失值前后数值的均值,但是若缺失值前后也存在缺失,则不进行计算插补。df['c'] = df['c'].interpolate()# 用前面的值替换, 当第一行有缺失值时,该行利用向前替换无值可取,仍缺失df.fillna(method='pad')# 用后面的值替换,当最后一行有缺失值时,该行利用向后替换无值可取,仍缺失df.fillna(method='backfill')#用后面的值替换
下述2个方式需要先处理数据
# 需要先对a列数据做插值填充,后续作为训练数据df['a'] = df['a'].interpolate()# 拆分空数据和非空数据df_notnull = df[df.is_fill==0] # 非空数据df_null = df[df.is_fill==1] # 空数据x_train = df_notnull[['b', 'a']] # 训练数据x, a,b列y_train = df_notnull['c'] # 训练数据y, c列(目标)test = df_null[['b', 'a']] # 预测数据x, a,b列
方式4:KNN填充
利用knn算法填充,其实是把目标列当做目标标量,利用非缺失的数据进行knn算法拟合,最后对目标列缺失进行预测。(对于连续特征一般是加权平均,对于离散特征一般是加权投票)
sklearn类
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressordef knn_filled_func(x_train, y_train, test, k = 3, dispersed = True):# params: x_train 为目标列不含缺失值的数据(不包括目标列)# params: y_train 为不含缺失值的目标列# params: test 为目标列为缺失值的数据(不包括目标列)if dispersed:knn= KNeighborsClassifier(n_neighbors = k, weights = "distance")else:knn= KNeighborsRegressor(n_neighbors = k, weights = "distance")knn.fit(x_train, y_train.astype('int'))return test.index, knn.predict(test)index,predict = knn_filled_func(x_train, y_train, test, 3, True)
方式5:随机森林填充
随机森林算法填充的思想和knn填充是类似的,即利用已有数据拟合模型,对缺失变量进行预测。
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifierdef RandomForest_filled_func(x_train, y_train, test, dispersed = True):# params: x_train 为目标列不含缺失值的数据(不包括目标列)# params: y_train 为不含缺失值的目标列# params: test 为目标列为缺失值的数据(不包括目标列)if dispersed:rf= RandomForestRegressor()else:rf= RandomForestClassifier()rf.fit(x_train, y_train.astype('int'))return test.index, rf.predict(test)index,predict = RandomForest_filled_func(x_train, y_train, test, True)
预测完成后处理操作
# 填充预测值df_null['c'] = predict# 回填到原始数据中df['c'] = df['c'].fillna(df_null[['c']].c)df.info()
效果预览
红色为填充数据,绿色为原始数据
上图为随机森林填充
下图为插值填充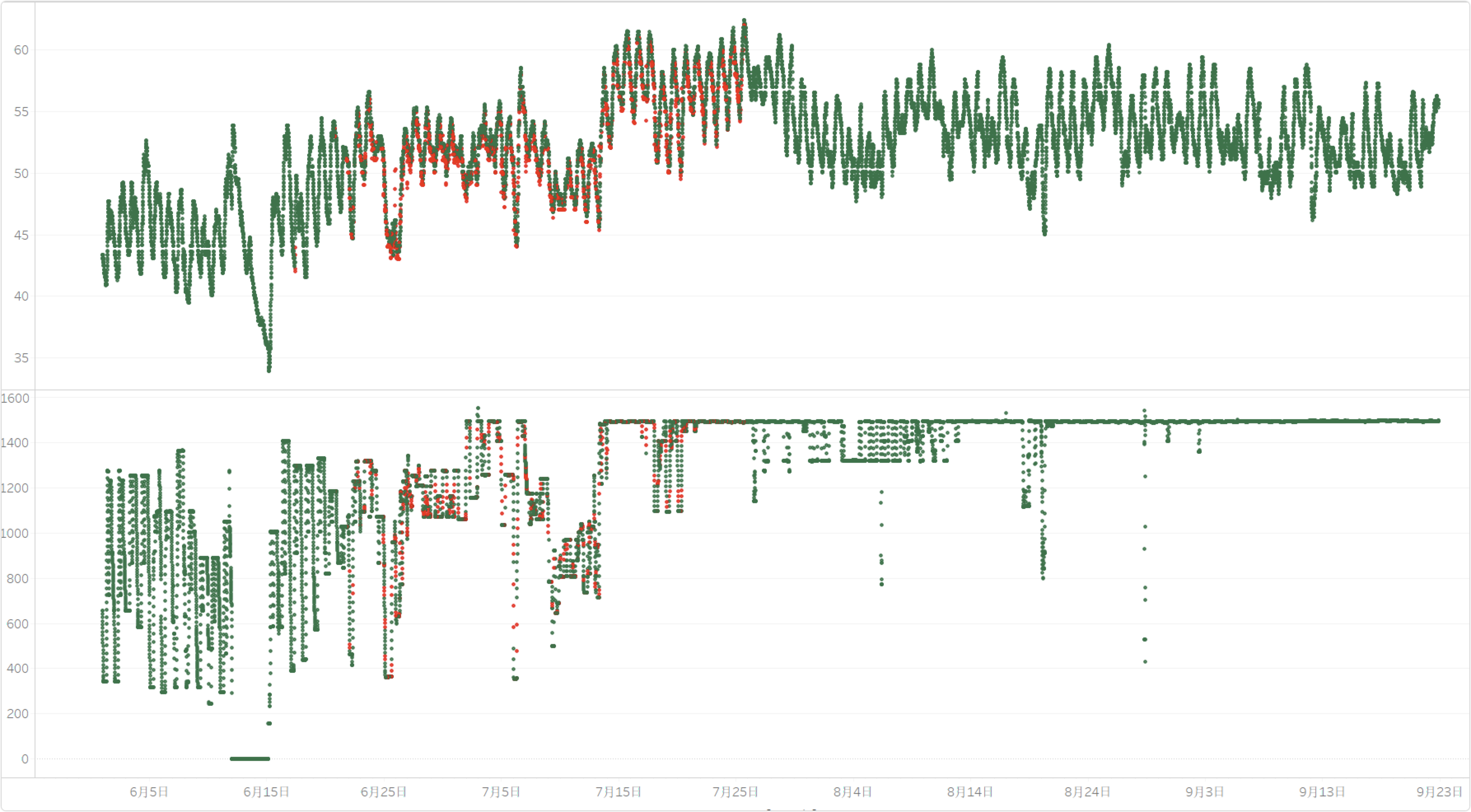

若有收获,就点个赞吧
0 人点赞
