参考资料:https://mp.weixin.qq.com/s/_0UokxSrKXAtQ-lnv_i_yw
日常笔面试中,常见考点举例:
▶ XGBoost原理是什么?
▶ XGBoost如何处理缺失值**?**
▶ XGBoost如何避免过拟合?
本文着重介绍 算法原理+高频笔面试题
温馨提示:
时间紧急的朋友可重点掌握原理+笔面试真题部分
时间充裕的 建议对照本文讲解,进一步了解推导部分。
———正文手动分割线———
本文结构速览:
一、XGBoost原理介绍
二、目标函数
1、损失函数
2、树的复杂度
三、模型训练
四、常见笔面试真题7个
一、XGBoost原理介绍
之前介绍过决策树,那么XGBoost和决策树有啥关系呢?
Xgoost可以简单的理解为一堆的Cart树。
下面以一棵Cart树进行展示: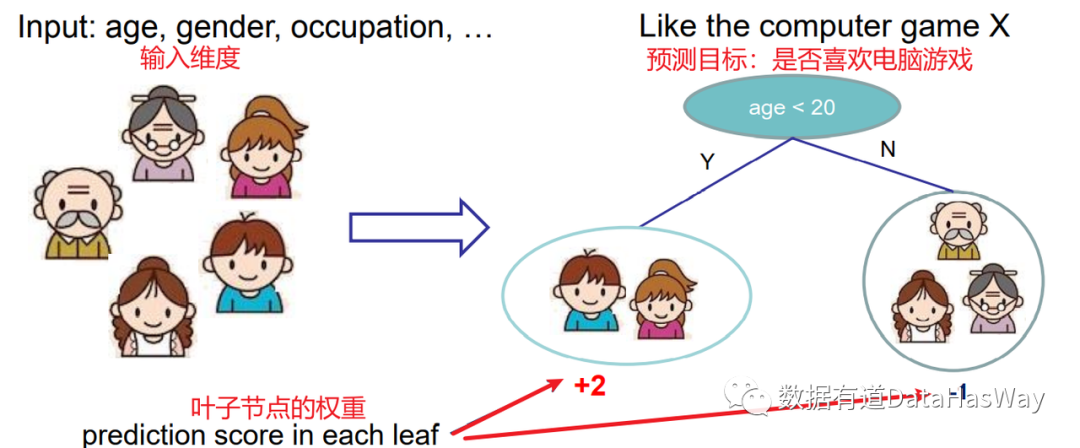
这棵树结果表明,首先对年龄进行判断是否小于20岁,
- 如果是,叶子节点得分2分
- 如果否,叶子节点得分-1分
接下来是两棵Cart树结果: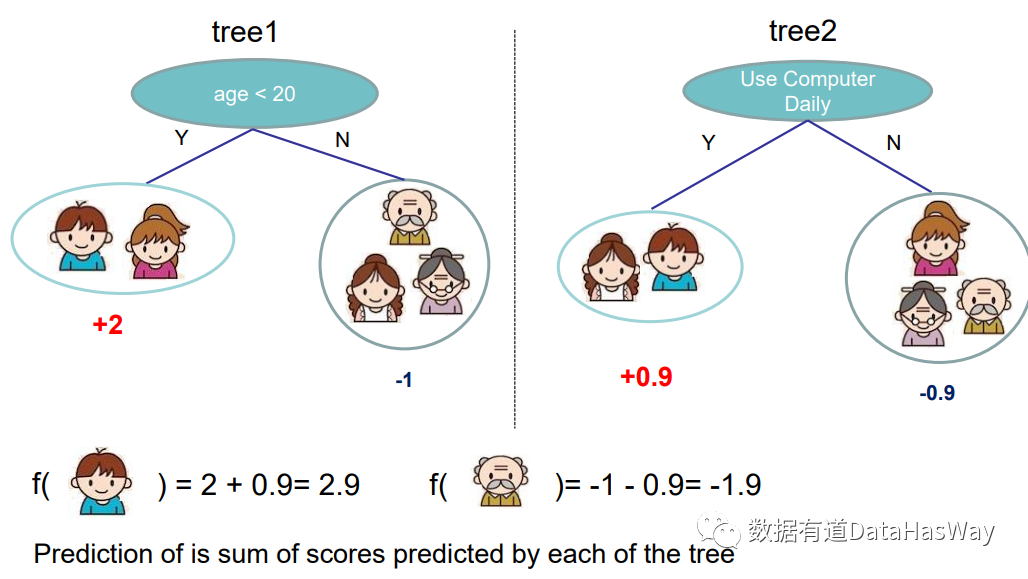
这颗树怎么进行解读呢?
- 男孩在第一棵树中得分2分,第二棵树中得分0.9分
- 爷爷在第一棵树中得分-1分,第二棵树中得分-0.9分
模型结果是将两棵树结果加起来
- 男孩的最终得分就是2.9
- 爷爷的最终得分就是-1.9
下面就是论文中模型的得分展示结果:
假设模型有K棵树,对样本xi的得分就是将K棵树的所有结果加起来。
二、目标函数
以上树模型涉及到两个重要的取值问题:
- 用哪个特征的哪个取值进行分割
- 分割后,叶子结点的取值怎么定
有了树模型的结构以及叶子节点的取值,即可计算出所有样本的模型结果。
但问题是,如何得到这些树结构以及叶子结点的权重呢?
——这就是模型训练的问题。
在讲解模型训练之前,先讲讲xgboost目标函数是如何定义的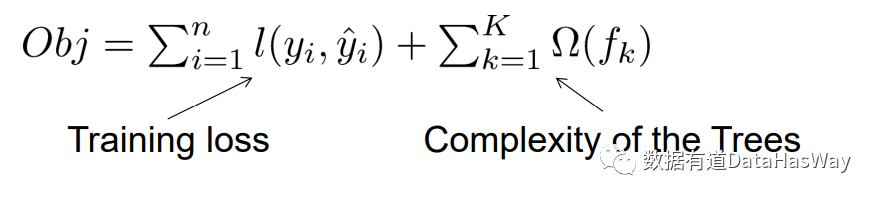
这里的目标函数涉及到两部分:
①损失函数(Training loss)
②树的复杂度(Complexity of the Trees)
Tips:
- 损失函数越小,目标函数越小
- 模型训练是为了使得目标函数最小
1、损失函数
先讲解一下损失函数。
针对回归问题和分类问题,损失函数的定义是不一样的.
回归问题,常用的损失函数是MSE: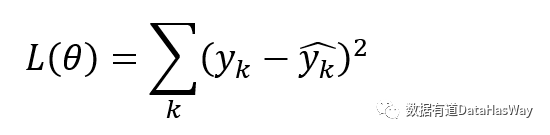
分类问题,常用的损失函数为对数损失函数: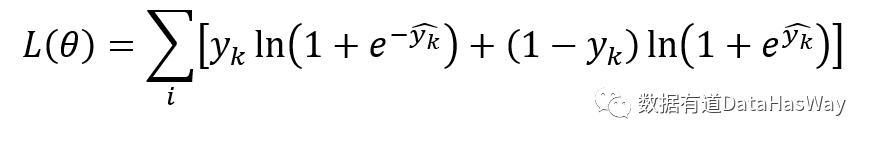
2、树的复杂度
关于树的复杂度,直接沿用论文中的结果: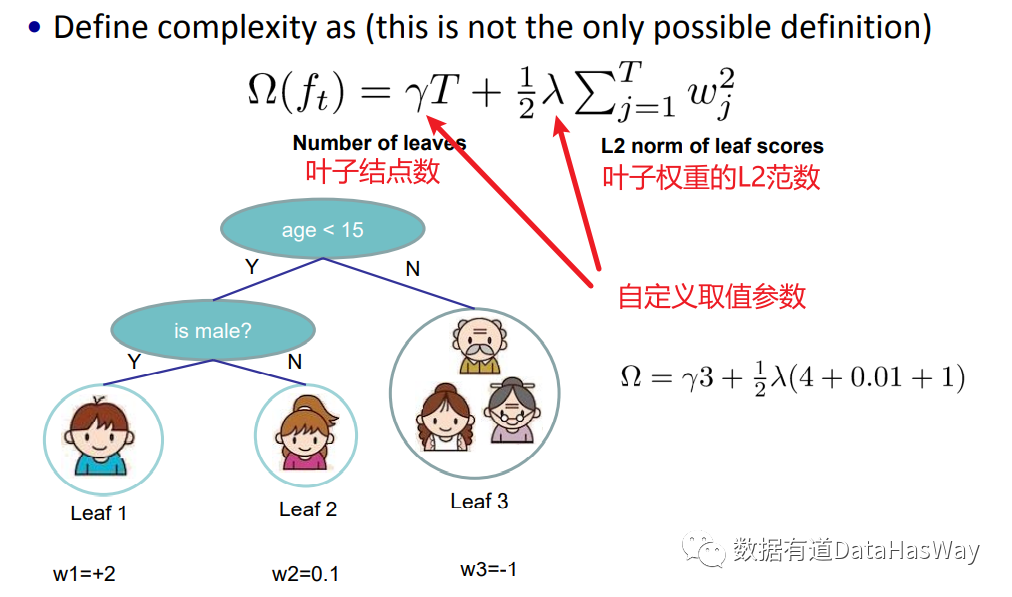
Tips:
① γ和λ是需要手动调整的超参,这两个超参设置的越大,树模型就会越简单。
② 将树的复杂度作为目标函数的一部分,是希望控制树的复杂度,减少过拟合。
三、模型训练
前面已经讲解过,xgboost就是一堆的树模型。
每一次训练都会增加一棵树,第K次训练模型的结果就是K棵树相加得到。
下面就是每次训练模型取值更新的过程:
下面我们讲解在已经前面t-1棵树的情况下,训练得到第t棵树。
将模型得到的Y’代入到目标函数中,模型训练的过程就是希望最小化目标函数:
上面以MSE损失函数为例,第t棵树的生成就是为了使得目标函数最小。
下面对目标函数obj进行泰勒二阶展开,然后找到极值点,最后确认使得目标函数最小第t棵树
gi和hi就是使得损失函数最小的取值结果。
下面,我们进一步考虑树的复杂度:
同样的,针对目标函数进行最小值求解
此刻,猜测大家已经开始有点云里雾里了,
下面结合一个实际的树模型进行理解吧:
再简单总计一下模型训练的步骤吧~
Step①:确定目标函数obj
Step②:每一次结点分割就是寻找使得目标函数最小的分割点
Step③:生成树模型
Step④:重复Step②
四、常见笔面试真题
经典问题1:xgboost如何处理缺失值?
解题思路:对树中的每个非叶子结点,XGBoost可以自动学习出它的默认分裂方向。如果某个样本该特征值缺失,会将其划入默认分支。对缺失值的处理方式如下:
- 在特征k上寻找最佳分割点,不会对该列特征缺失的样本进行遍历,而只对该列特征值为非缺失样本上对应的特征值进行遍历,通过这个技巧来减少了为稀疏离散特征寻找分割点的时间开销。
- 在逻辑实现上,为了保证完备性,会将该特征值缺失的样本分别分配到左叶子结点和右叶子结点,两种情形都计算一遍后,选择分裂后增益最大的那个方向(左分支或是右分支),作为预测时特征值缺失样本的默认分支方向。
- 如果在训练中没有缺失值而在预测中出现缺失,那么会自动将缺失值的划分方向放到右子结点。
经典问题2:xgboost为什么要进行泰勒二阶展开?
解题思路:相对于GBDT的一阶泰勒展开,XGBoost采用二阶泰勒展开,可以更为精准的逼近真实的损失函数。
经典问题3:xgboost支持自定义损失函数吗?有什么要求?
解题思路:损失函数支持自定义,只需要新的损失函数二阶可导。
经典问题4:XGBoost为什么可以并行训练?
解题思路:XGBoost的并行,并不是说每棵树可以并行训练,XGBoost本质上仍然采用boosting思想,每棵树训练前需要等前面的树训练完成才能开始训练。
XGBoost的并行,指的是特征维度的并行。在训练之前,每个特征按特征值对样本进行预排序,并存储为Block结构,在后面查找特征分割点时可以重复使用,而且特征已经被存储为一个个block结构,那么在寻找每个特征的最佳分割点时,可以利用多线程对每个block并行计算。
经典问题5:XGBoost为什么要加入正则项?
解题思路:XGBoost目标函数中树的复杂度这一项就是正则项, 加入正则项, 相当于预剪枝,使得学习出来的模型更加不容易过拟合。
经典问题6:XGBoost都有哪些防止过拟合的设计?
解题思路:XGBoost在设计时,为了防止过拟合主要设计了以下4个优化措施:
- 目标函数加入正则项:叶子节点个数+叶子节点权重的L2正则化
- 列抽样:训练的时候只用一部分特征(不考虑剩余的block块即可)
- 子采样:每轮计算可以不使用全部样本,使算法更加保守
- shrinkage: 可以叫学习率或步长,为了给后面的训练留出更多的学习空间
经典问题7:XGBoost如何评价特征的重要性?
解题思路:XGBoost采用三种方法来评判XGBoost模型中特征的重要程度
- weight :该特征在所有树中被用作分割样本的特征的总次数。
- gain :该特征在其出现过的所有树中产生的平均增益。
- cover :该特征在其出现过的所有树中的平均覆盖范围。
(注:以上主要参考陈天奇博士的XGBoost论文及讲解PPT)

若有收获,就点个赞吧
0 人点赞
