机器学习拓展知识
拓展机器学习的原理与背景, 线性回归、逻辑回归的重难点讲解以及代码复现, 机器学习的基本pipeline, 机器学习模型评价指标探讨。
目录
1.背景与原理介绍
机器学习简介,机器学习的原理与背景。
2.回归与分类详解
线性回归、逻辑回归的重难点讲解以及代码复现。
3.机器学习评价
机器学习的基本pipeline以及机器学习模型评价指标探讨。
1.背景与原理介绍
分类
- 监督
- 无监督
- 强化
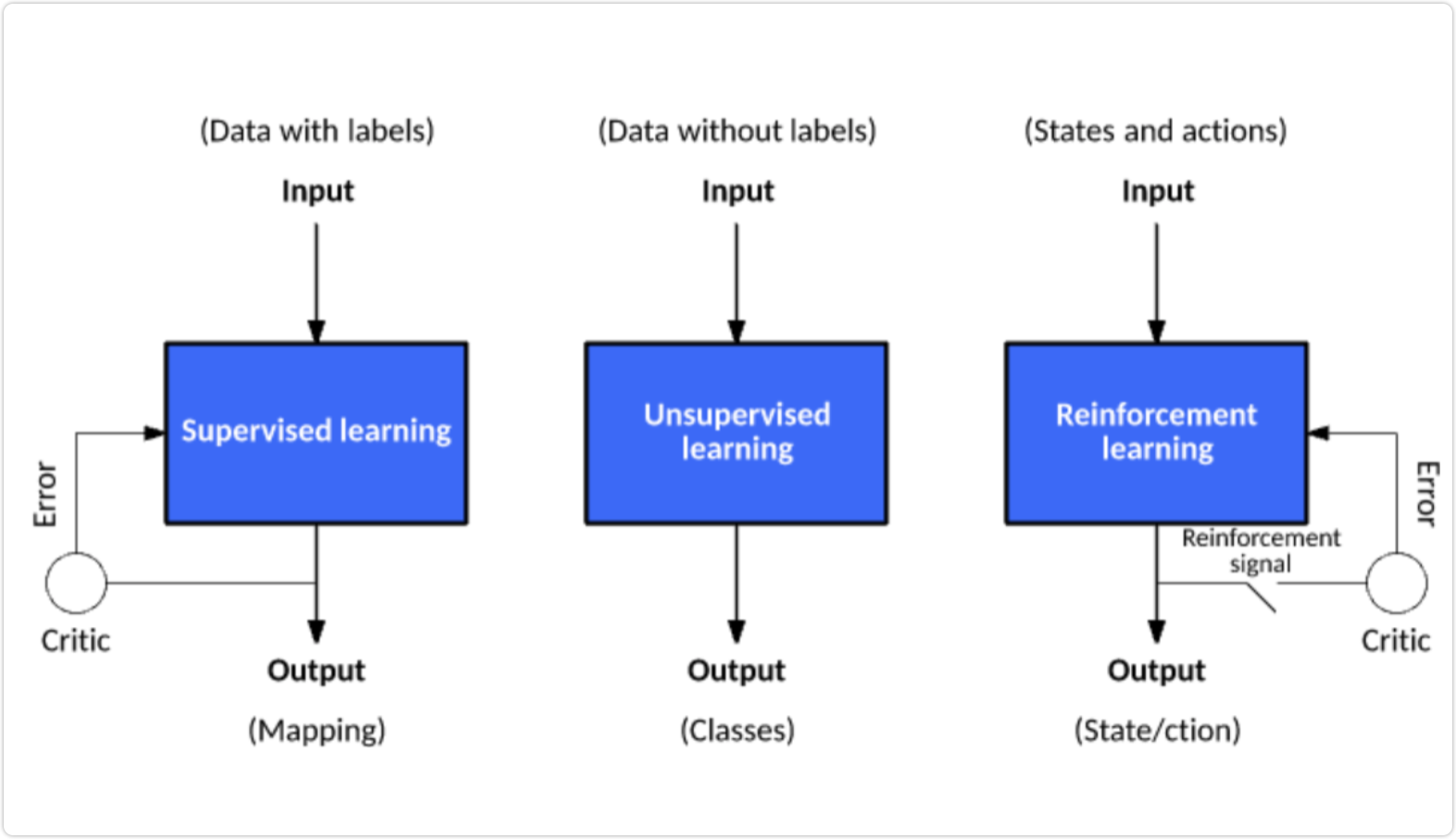
监督学习
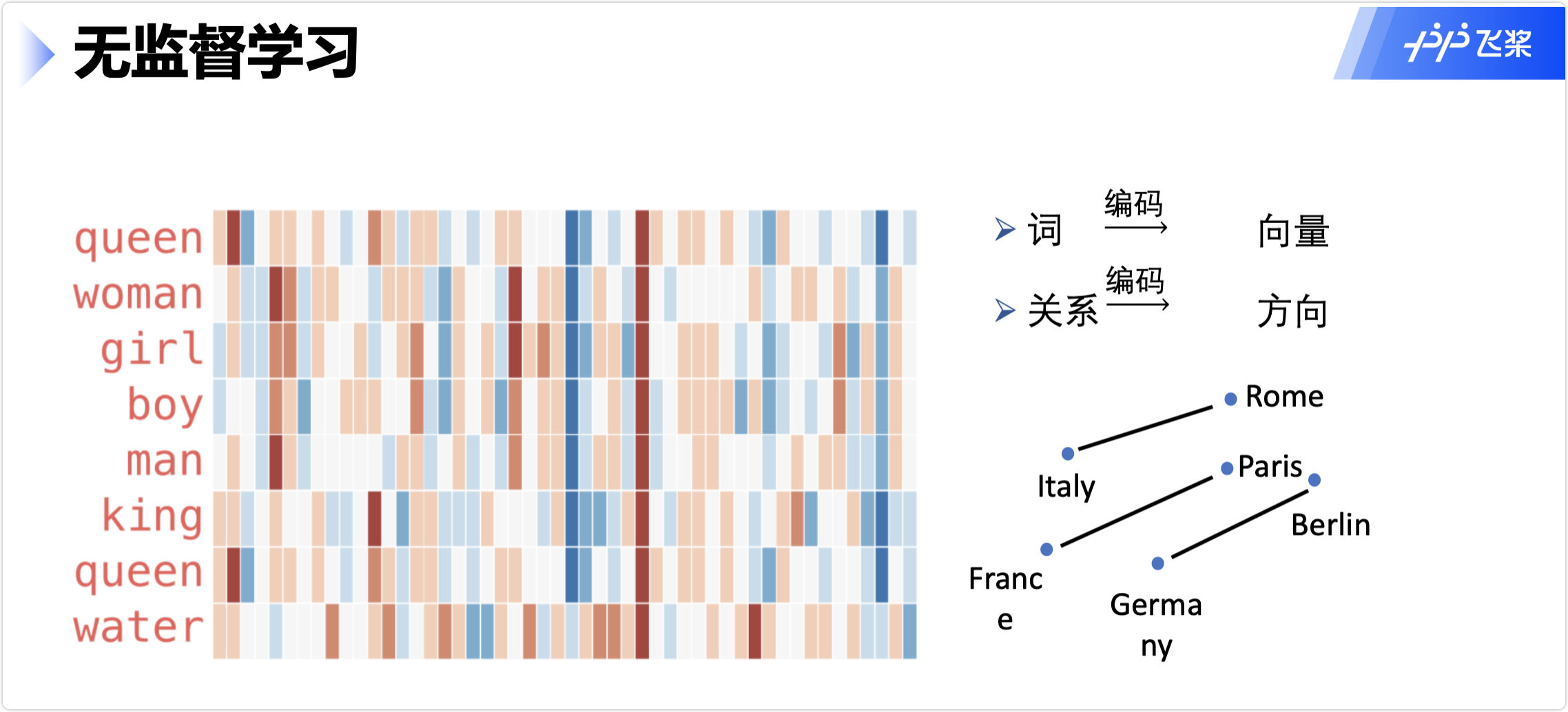
无监督学习

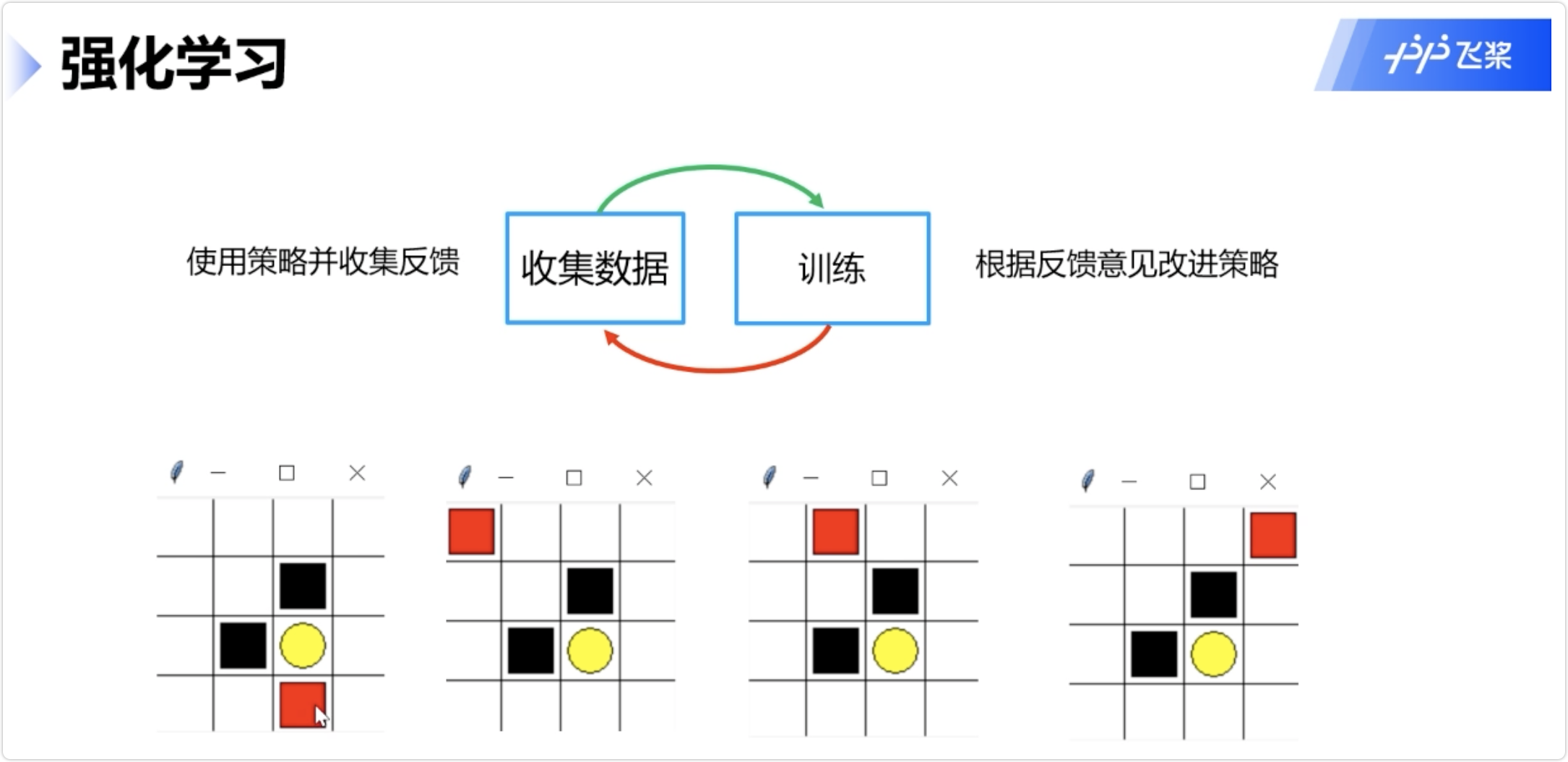
强化学习
2.回归和分类详解
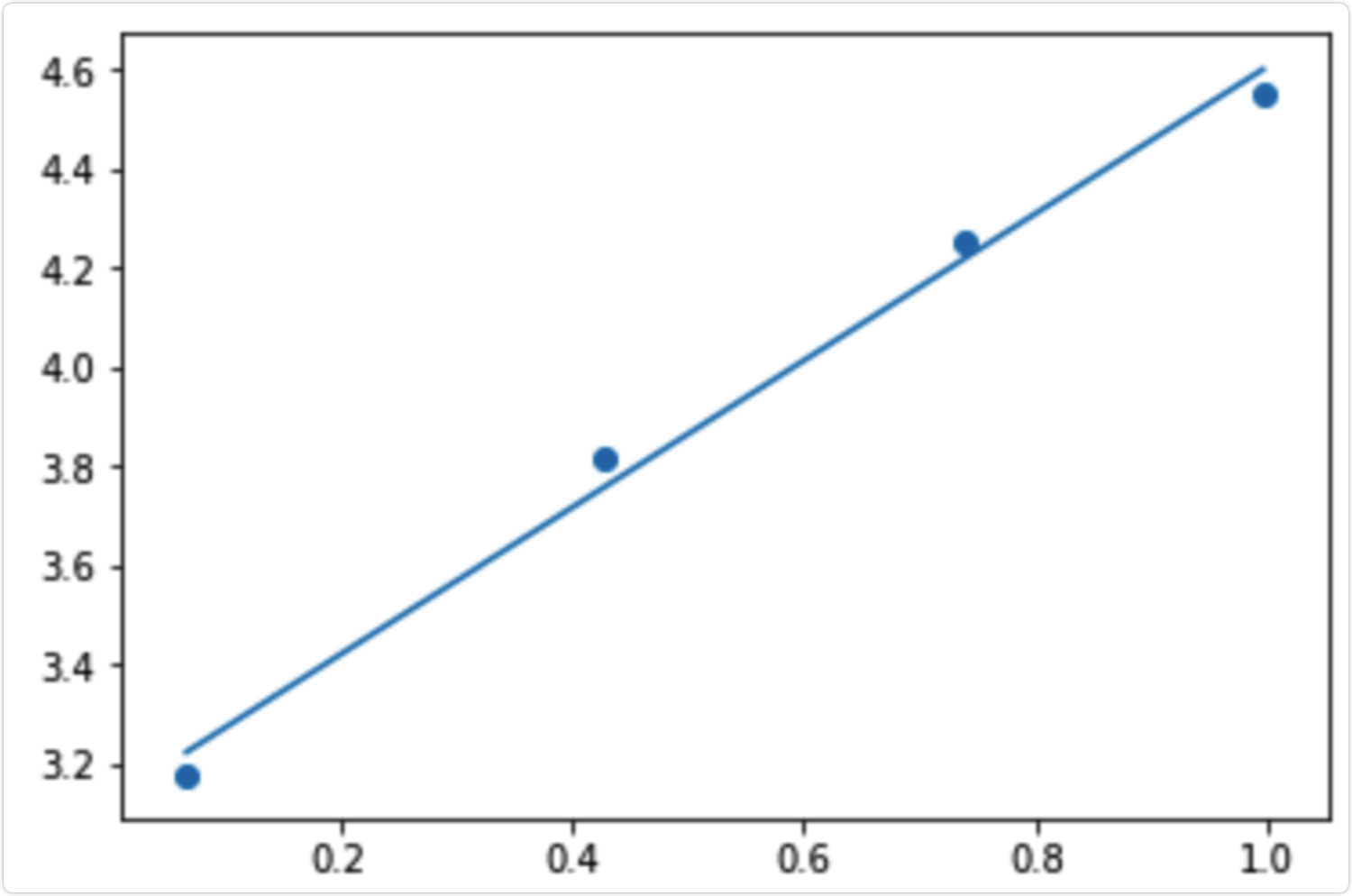
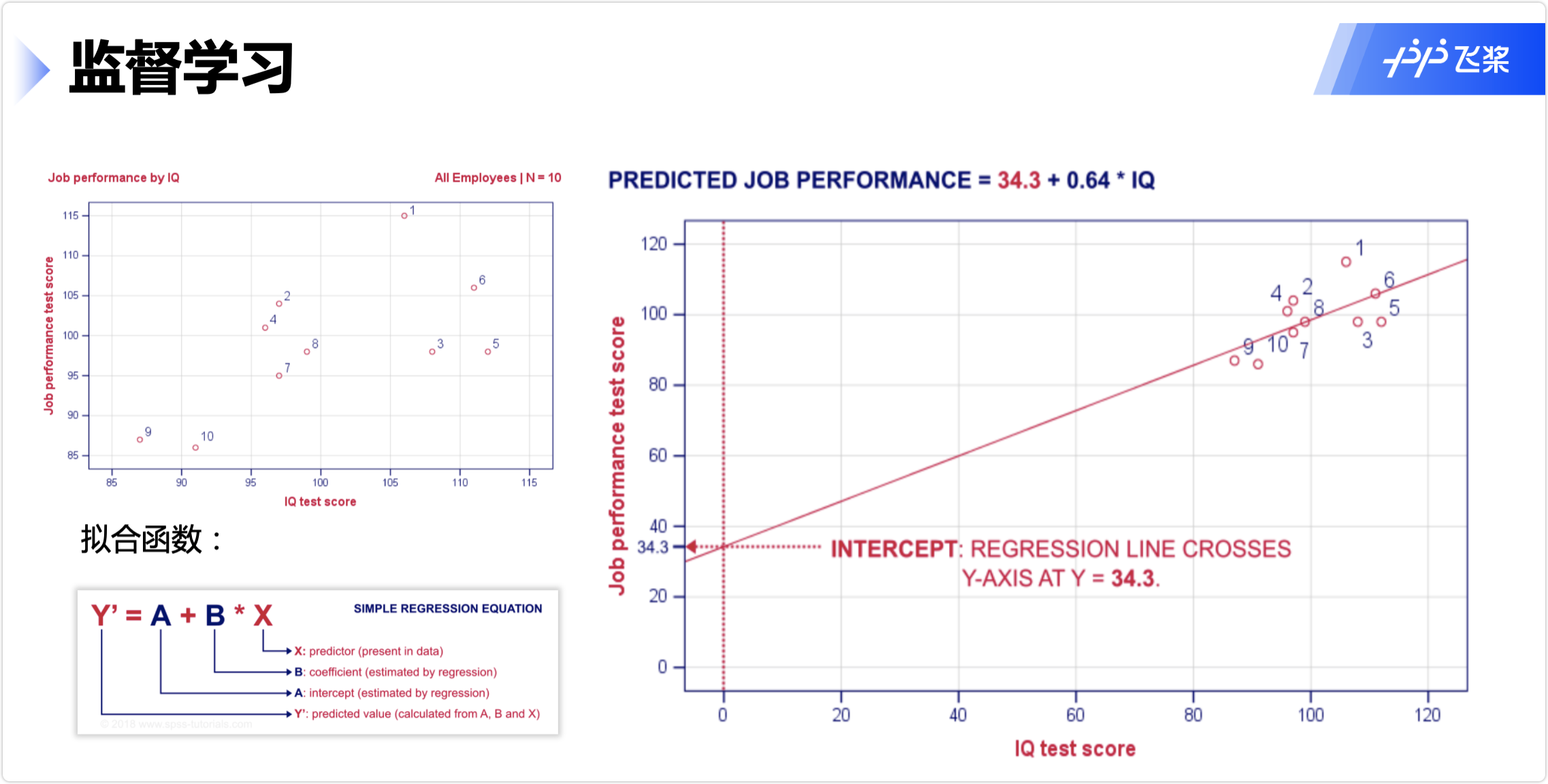
线性回归
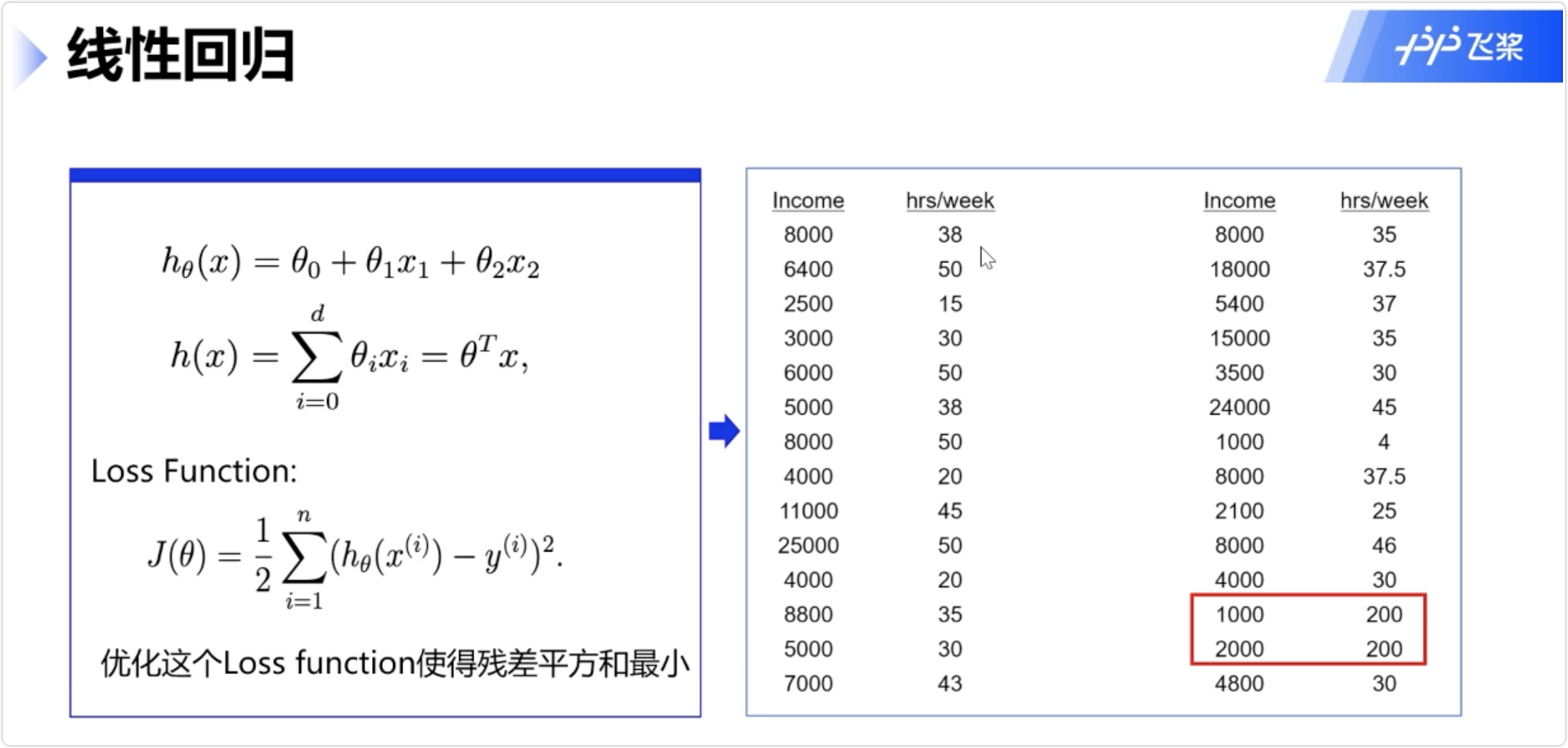
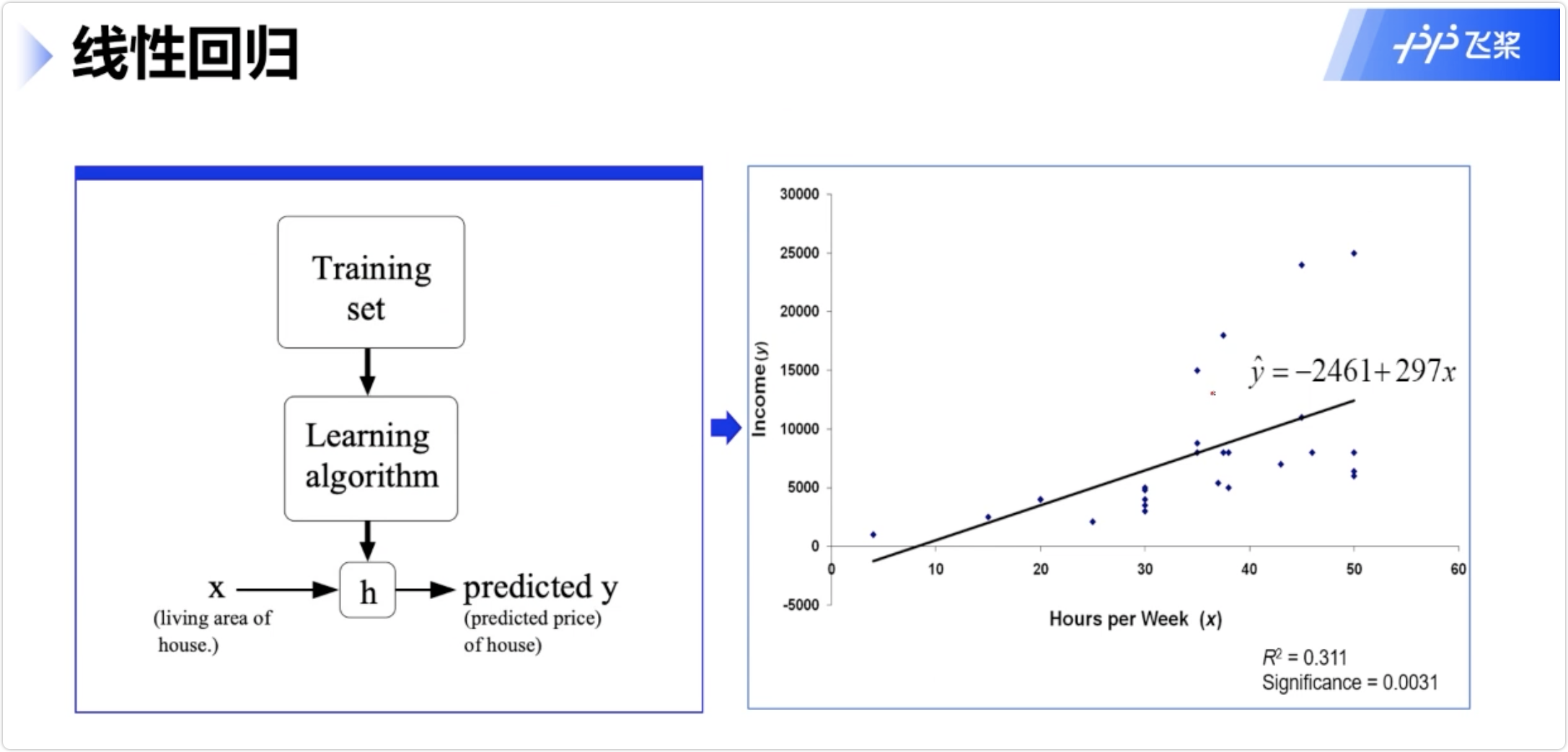
多元线性回归


多源线性回归解析解 θ

逻辑回归
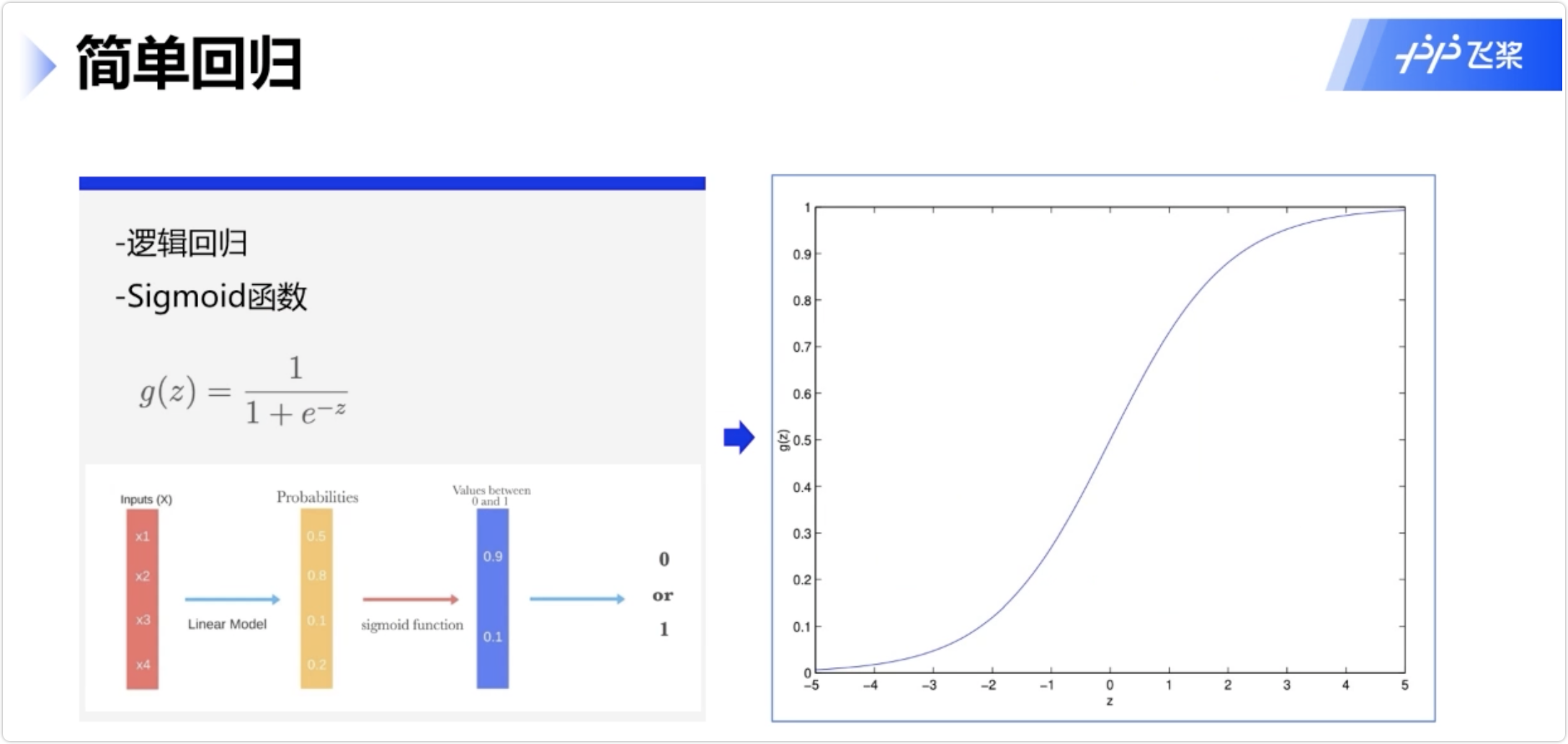
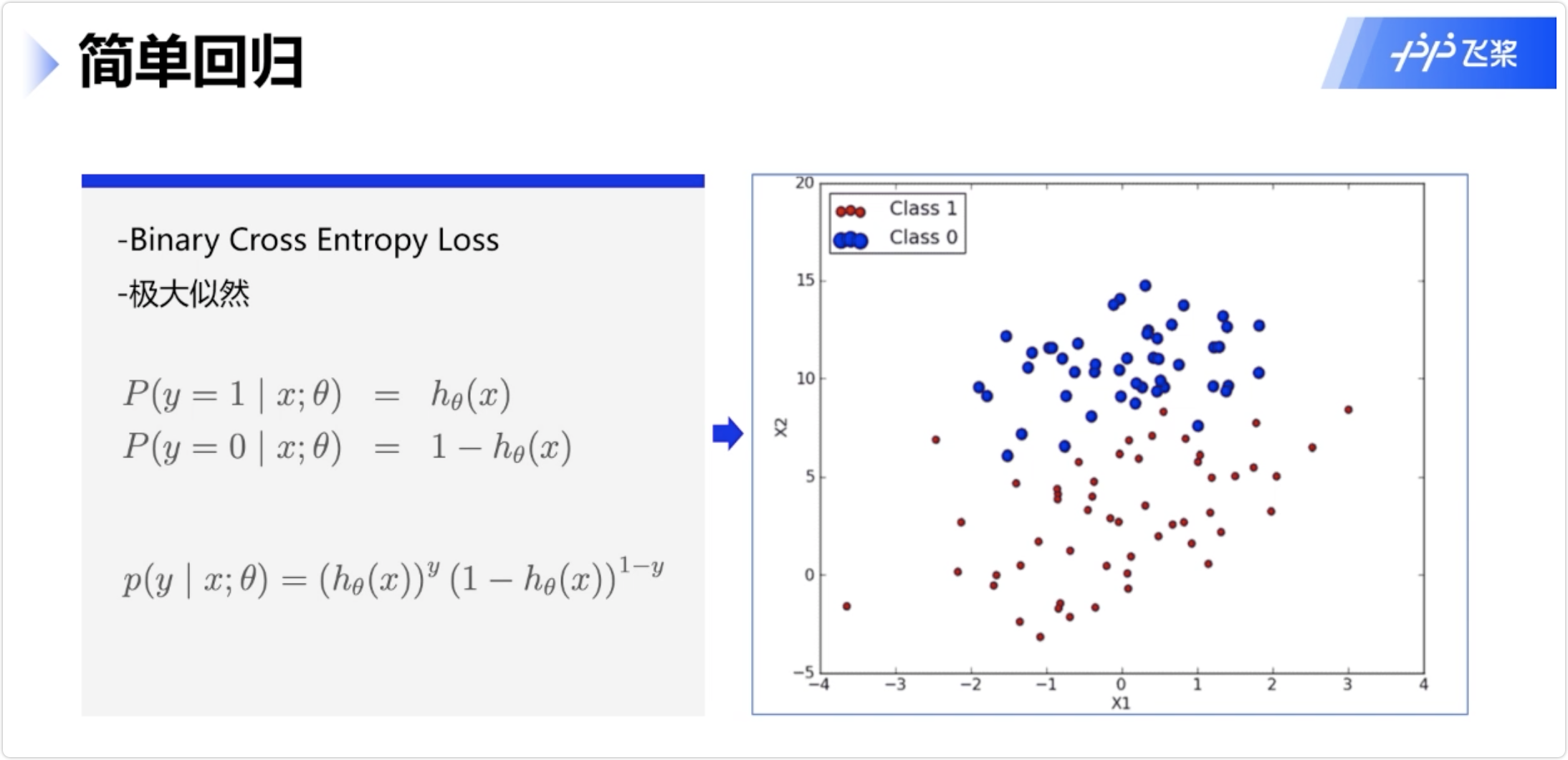

3.机器学习评价
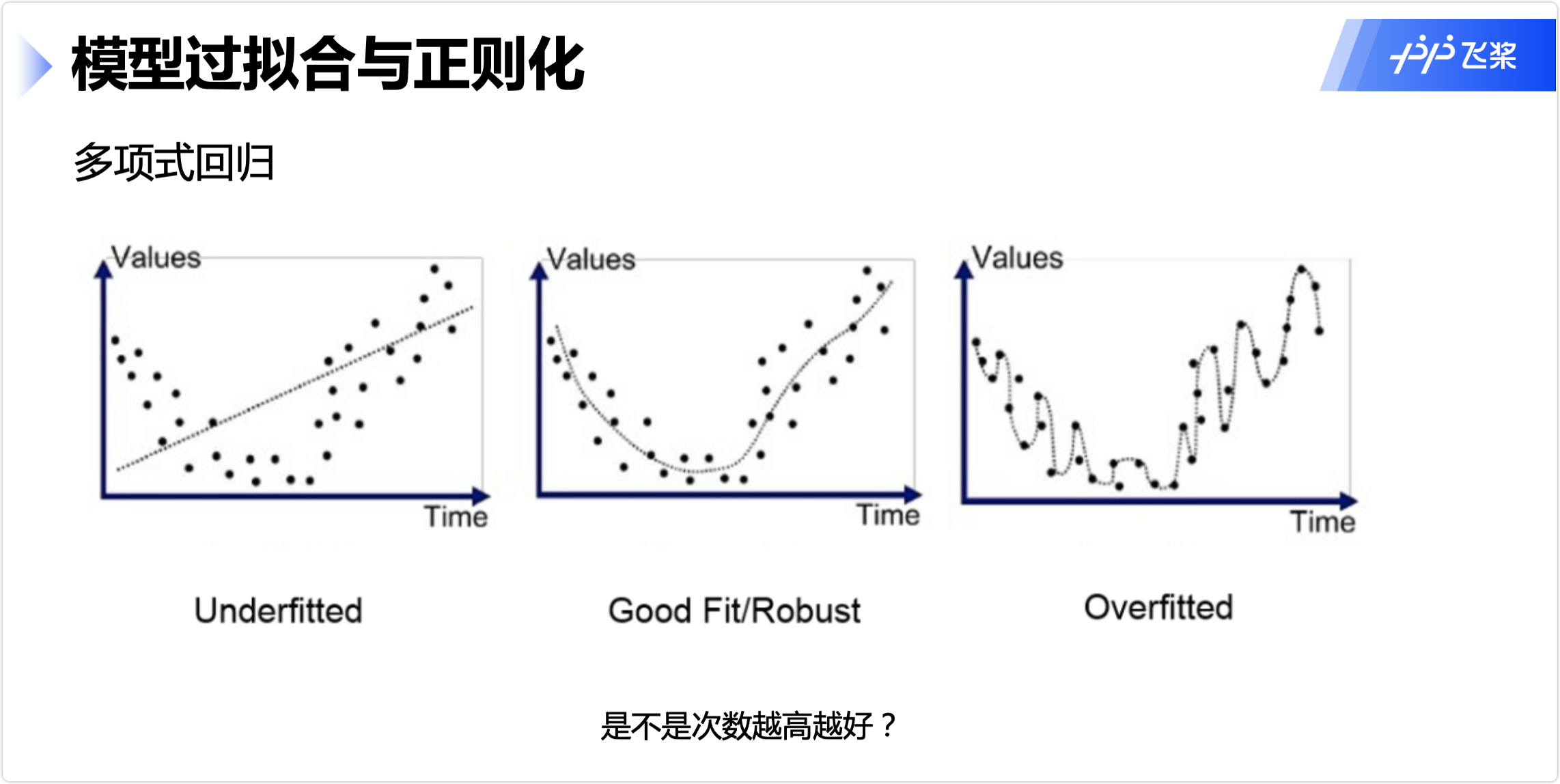
模型过拟合与正则化
预防过拟合

多项式回归
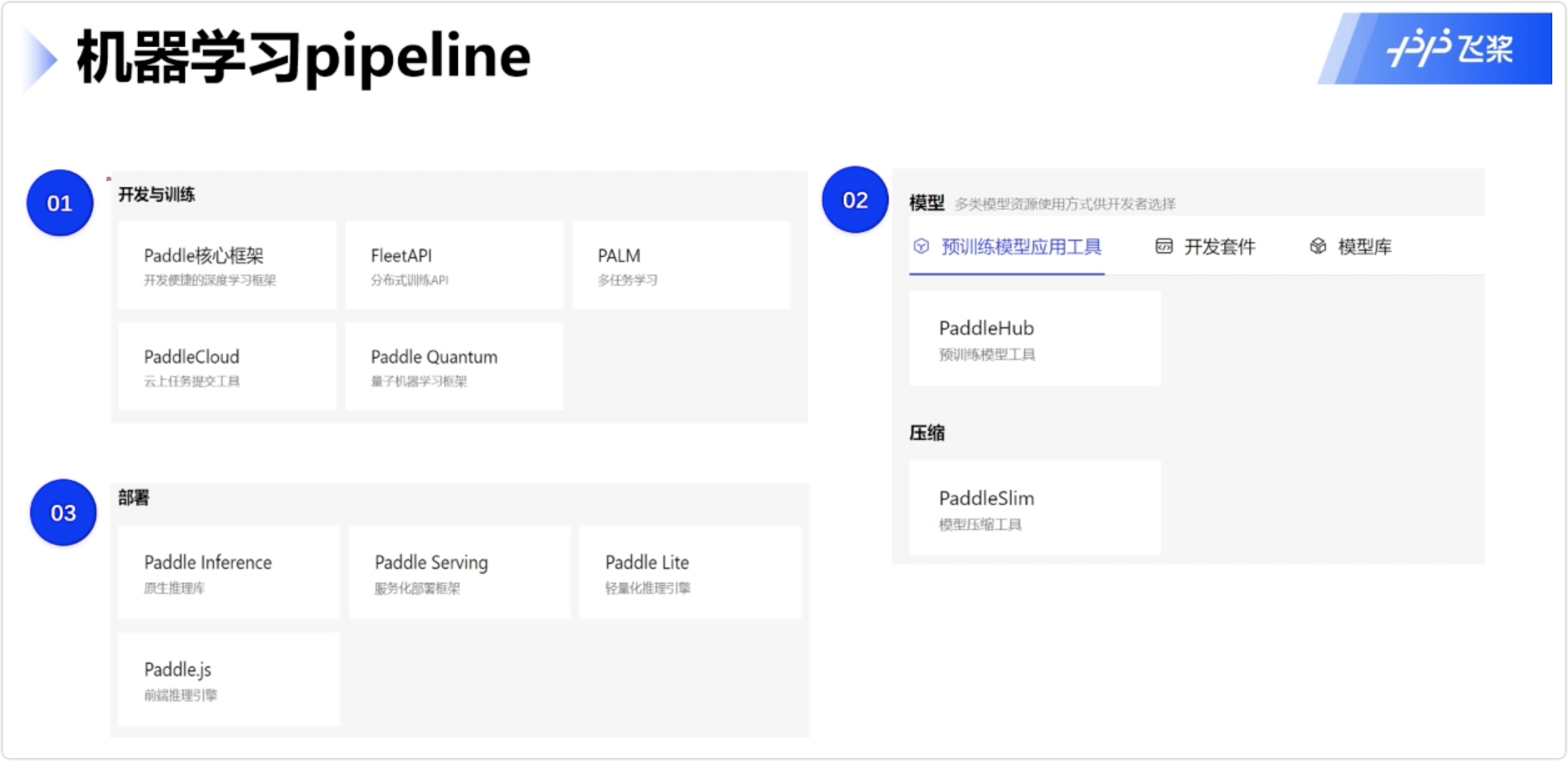
机器学习pipeline
- 开发与训练
- 模型
- 部署
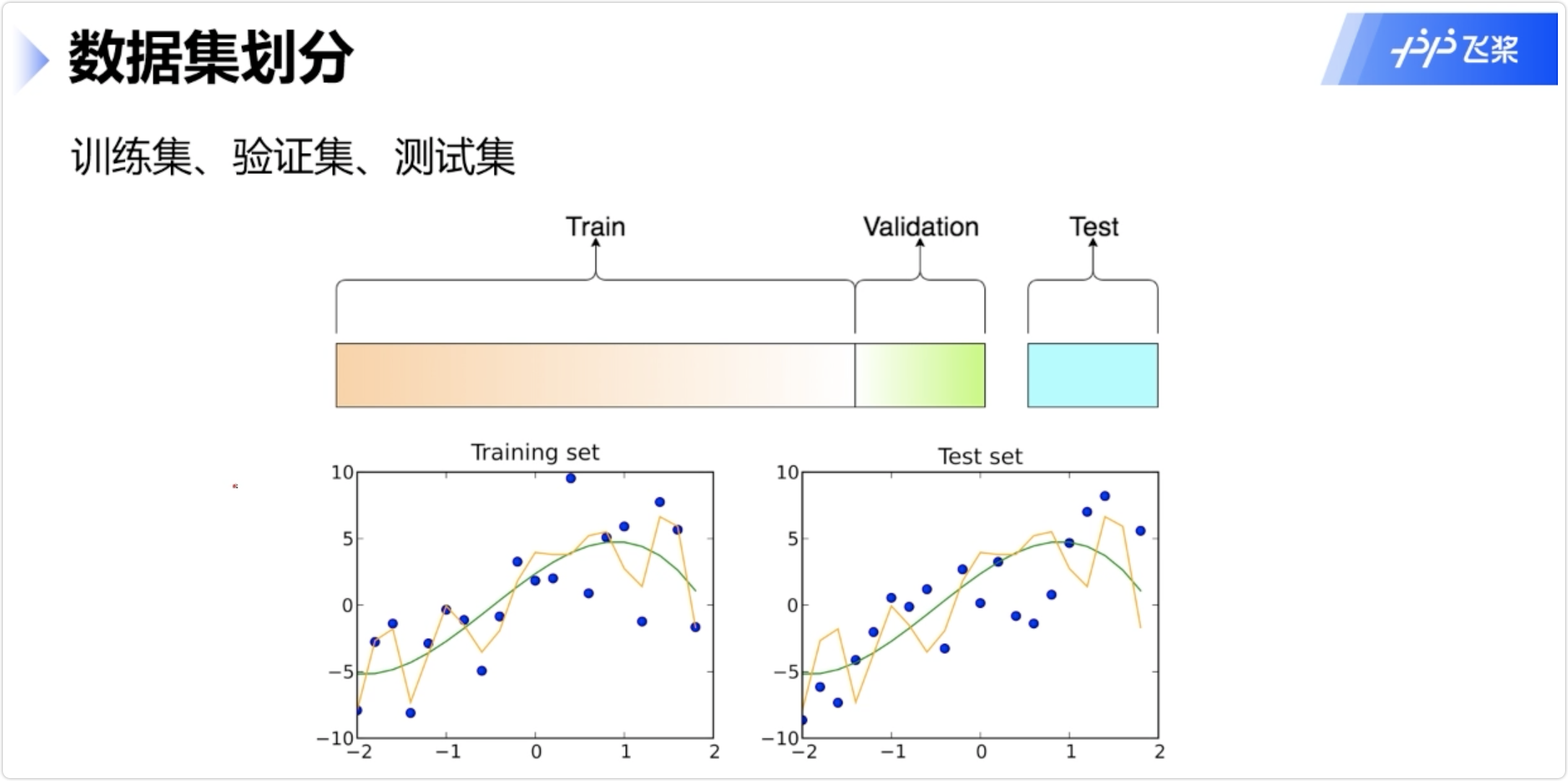
数据集划分
训练集、验证集、测试集
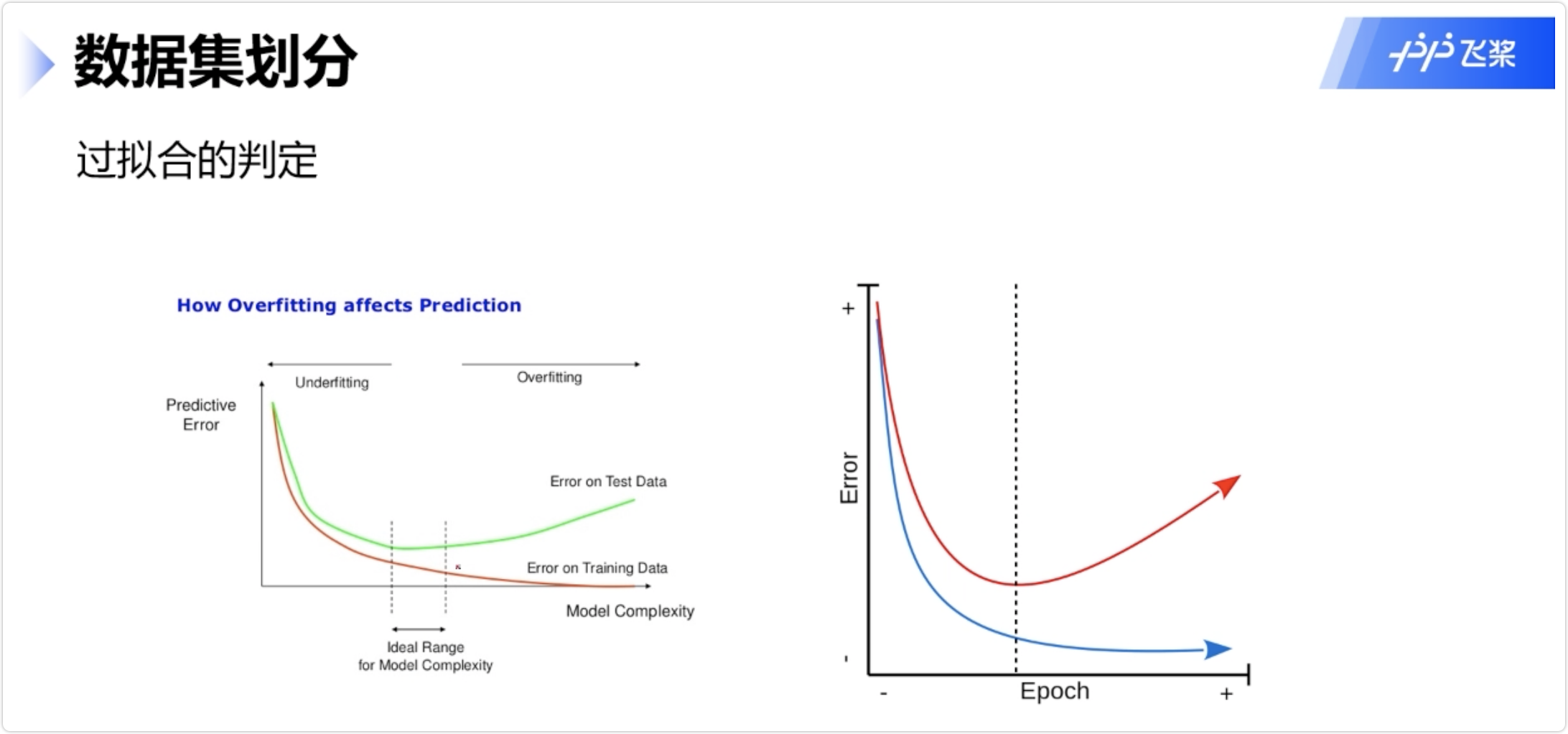
过拟合的判定
机器学习评价体系(分类问题)
Accuracy在数据不平衡时参考意义不大
主要看F1_Score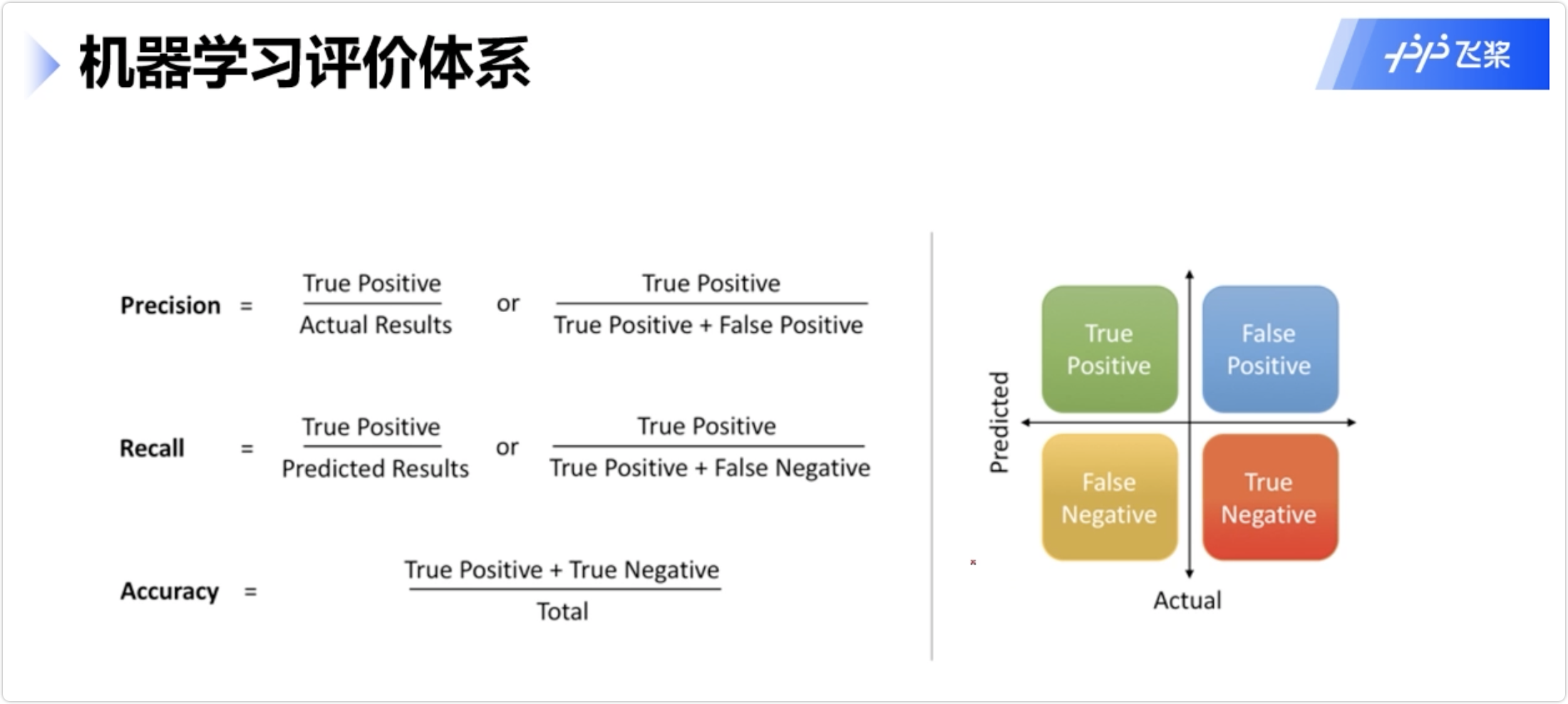
代码
线性回归
from numpy import *import matplotlib.pylab as pltdef loadDataSet(fileName):dataMat = []labelMat = []fr = open(fileName)for line in fr.readlines():lineArr = []curLine = line.strip().split('\t')for i in range(2):lineArr.append(float(curLine[i]))dataMat.append(lineArr)labelMat.append(float(curLine[-1]))return dataMat,labelMatdef standRegres(xArr,yArr):xMat = mat(xArr)yMat = mat(yArr).TxTx = xMat.T * xMatif linalg.det(xTx) == 0:returnws = xTx.I * (xMat.T * yMat)return wsdef regression1():xArr, yArr = loadDataSet("./data/data.txt")xMat = mat(xArr)yMat = mat(yArr)ws = standRegres(xArr, yArr)fig = plt.figure()ax = fig.add_subplot(111) #add_subplot(349)函数的参数的意思是,将画布分成3行4列图像画在从左到右从上到下第9块ax.scatter(xMat[:, 1].flatten().tolist(), yMat.T[:, 0].flatten().A[0].tolist()) #scatter 的x是xMat中的第二列,y是yMat的第一列xCopy = xMat.copy()xCopy.sort(0)yHat = xCopy * wsax.plot(xCopy[:, 1], yHat)plt.show()if __name__ == "__main__":regression1()
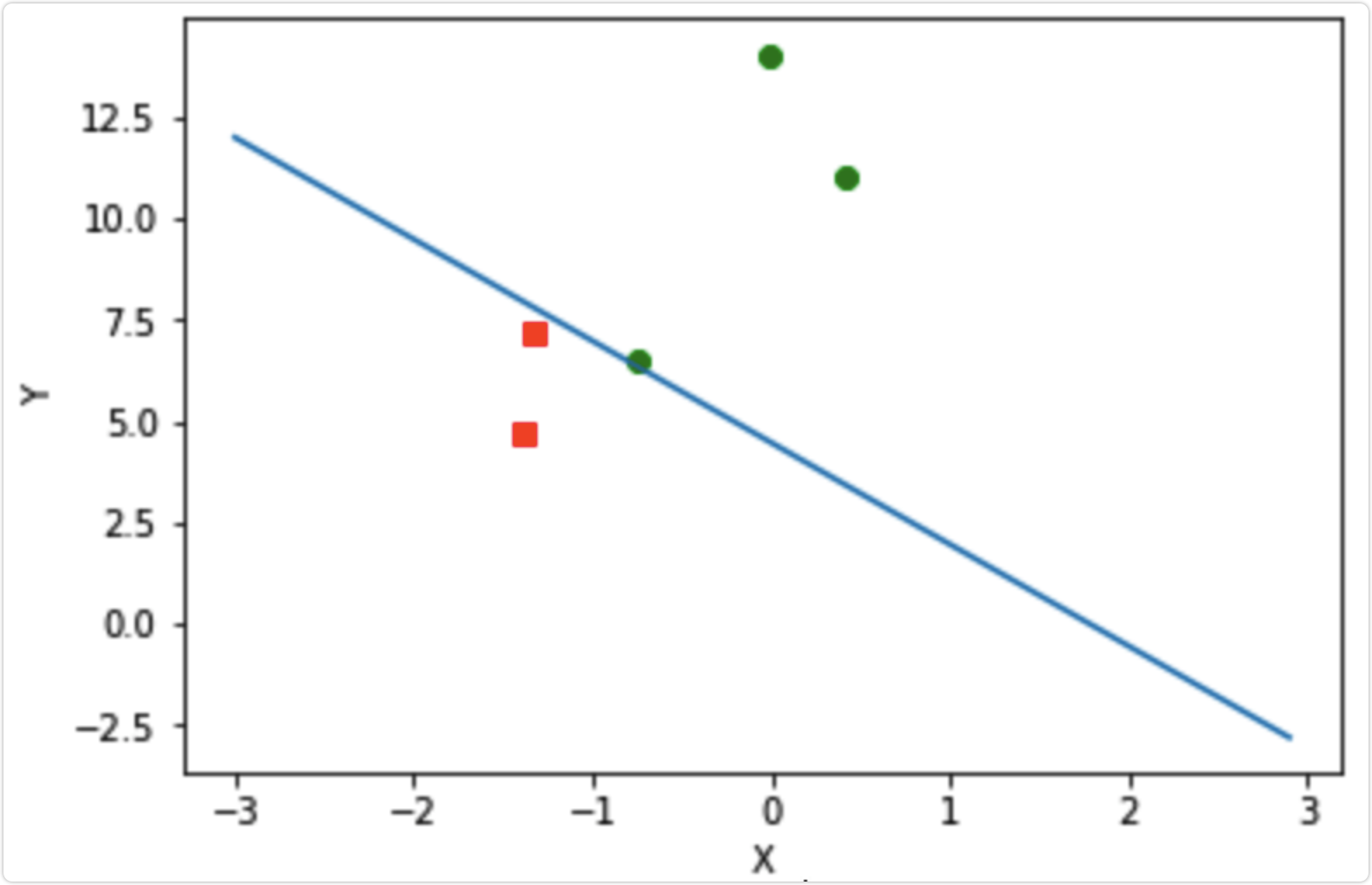
逻辑回归
from numpy import *import matplotlib.pylab as plt# 解析数据def loadDataSet(file_name):dataMat = []labelMat = []fr = open(file_name)for line in fr.readlines():curLine = line.strip().split()dataMat.append([1.0,float(curLine[0]),float(curLine[1])])labelMat.append(int(curLine[2]))return dataMat, labelMatdef sigmoid(inX):return 1.0 / (1 + exp(-inX))def stocGradAscent1(dataMatrix, classLabels, numIter=500):m,n = shape(dataMatrix)weights = ones(n) # 创建与列数相同的矩阵的系数矩阵,所有的元素都是1# 随机梯度, 循环150,观察是否收敛alpha = 0.001for j in range(numIter):# [0, 1, 2 .. m-1]dataIndex = range(m)for i in range(m):randIndex = int(random.uniform(0,len(dataIndex)))h = sigmoid(sum(dataMatrix[dataIndex[randIndex]]*weights))error = classLabels[dataIndex[randIndex]] - hweights = weights + alpha * error * dataMatrix[dataIndex[randIndex]]# del(dataIndex[randIndex])return weightsdef plotBestFit(dataArr, labelMat, weights):n = shape(dataArr)[0]xcord1 = [];ycord1 = []xcord2 = [];ycord2 = []for i in range(n):if int(labelMat[i]) == 1:xcord1.append(dataArr[i, 1]);ycord1.append(dataArr[i, 2])else:xcord2.append(dataArr[i, 1]);ycord2.append(dataArr[i, 2])fig = plt.figure()ax = fig.add_subplot(111)ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')ax.scatter(xcord2, ycord2, s=30, c='green')x = arange(-3.0, 3.0, 0.1)y = (-weights[0] - weights[1] * x) / weights[2]ax.plot(x, y)plt.xlabel('X');plt.ylabel('Y')plt.show()def testLR():# 1.收集并准备数据dataMat, labelMat = loadDataSet("data/data2.txt")dataArr = array(dataMat)# print dataArrweights = stocGradAscent1(dataArr, labelMat)# 数据可视化plotBestFit(dataArr, labelMat, weights)if __name__ == '__main__':testLR()

若有收获,就点个赞吧
0 人点赞
