WACV 2020 论文标题:Long-Short Graph Memory Network for Skeleton-based Action Recognition 论文地址:http://openaccess.thecvf.com/content_WACV_2020/papers/ 代码地址:https://github.com/bczhangbczhang/Long-Short-Graph-Memory-Network

简介
本文提出了LSTM+GCN的融合模型LSGM,以更有效地提取skeleton graph序列的spatial-temporal特征,来完成skeleton based action recognition任务。LSGM与AGC-LSTM的motivation相同但方法不同,起到的效果也是相似的。另外,为了对LSGM提取到的特征进行增强,作者还在模型中加入了temporal attention和GTSC模块。
Long-Short Graph Memory Network
本文LSGM中用到的GCN就是经典的GCN结构,这里略过,直接来看其如何与LSTM结合,如图2: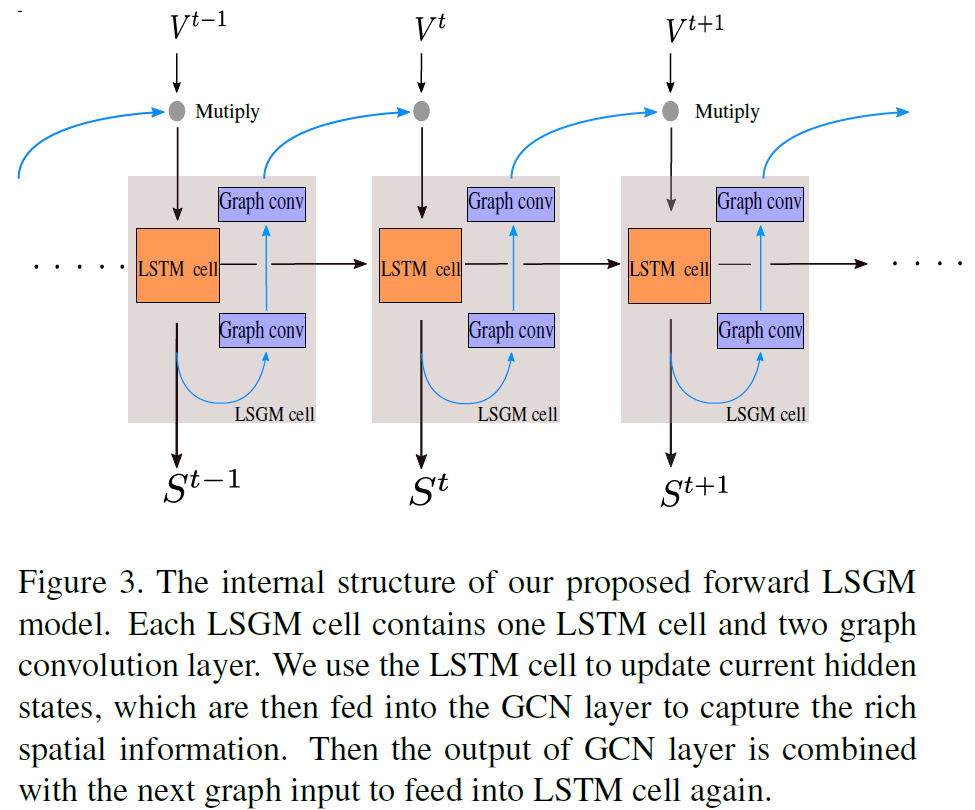
图中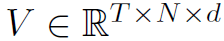 表示预处理后的graph序列结点特征,其中T表示时间,N表示结点个数,d表示特征维度。
表示预处理后的graph序列结点特征,其中T表示时间,N表示结点个数,d表示特征维度。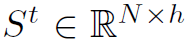 表示经过LSTM单元处理之后的t时刻的graph隐藏状态。这里作者对LSGM模型整个过程的描述并不是很清楚,貌似还出现了笔误,下面详细分析。
表示经过LSTM单元处理之后的t时刻的graph隐藏状态。这里作者对LSGM模型整个过程的描述并不是很清楚,貌似还出现了笔误,下面详细分析。
首先,LSGM的输入是t时刻的graph结点特征 ,其先与上一时刻产生的隐藏状态做element-wise multiplication之后,再经过一个LSTM单元处理,产生t时刻的隐藏状态
,其先与上一时刻产生的隐藏状态做element-wise multiplication之后,再经过一个LSTM单元处理,产生t时刻的隐藏状态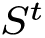 ,再经过两层的GCN处理之后得到
,再经过两层的GCN处理之后得到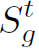 。下一个t+1时刻的输入
。下一个t+1时刻的输入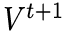 就要与这个隐藏状态相乘,再经过LSTM单元处理。不断重复这个过程。作者给出的公式描述如下,个人并不理解,可能存在上标笔误:
就要与这个隐藏状态相乘,再经过LSTM单元处理。不断重复这个过程。作者给出的公式描述如下,个人并不理解,可能存在上标笔误: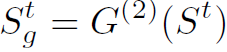
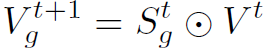 (等号右边应该是Vt+1吧)
(等号右边应该是Vt+1吧)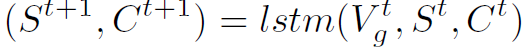 (同样,等号右边应该是Vgt+1)
(同样,等号右边应该是Vgt+1)
式中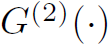 表示两层GCN。总之,作者所谓的LSGM并没有像AGC-LSTM那样深度融合,而是将(LSTM-GCN-GCN)视为一个LSGM单元,如此简单堆叠而已。
表示两层GCN。总之,作者所谓的LSGM并没有像AGC-LSTM那样深度融合,而是将(LSTM-GCN-GCN)视为一个LSGM单元,如此简单堆叠而已。
Graph Temporal-Spatial Calibration
以上是LSGM单元的结构,之后来看整个网络的结构以及作者使用的GTSC模块: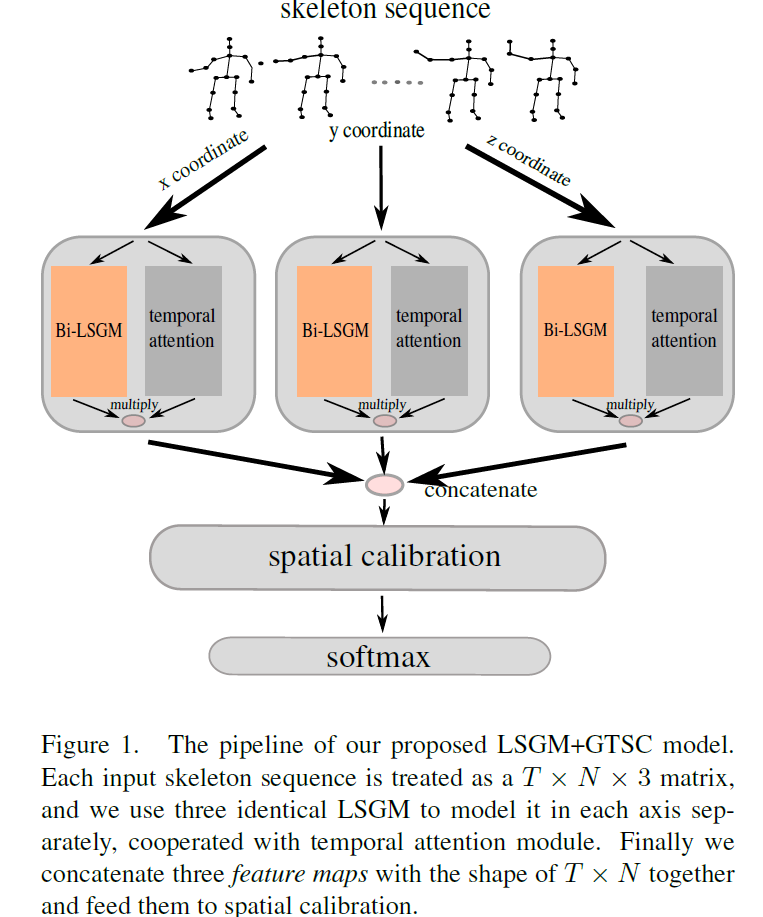
图1展示了网络的整体结构,还是比较有创新点的。作者没有将skeleton结点的xyz三维坐标一起处理,而是放入三个Bi-LSGM中分别处理,最后再concat起来。作者给出的理由是某些动作的细粒度特征可能只包含了某一维度坐标的信息。Bi-LSGM也就是双向LSGM,和双向LSTM原理相同,流程如图2: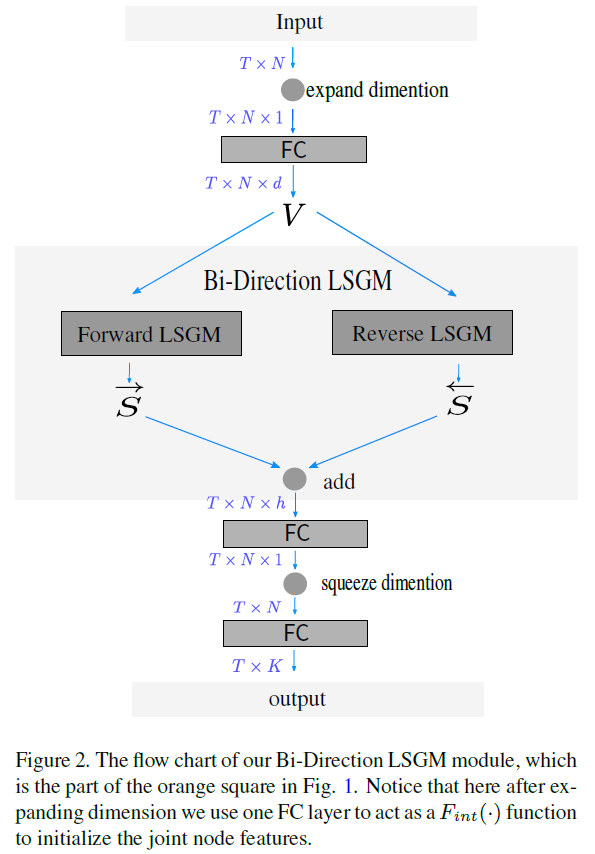
两个时序方向得到的特征S最后是直接相加: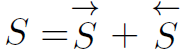
然后再经过全连接得到输出的特征: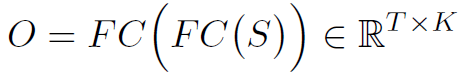
对于temporal attention模块,流程如图4: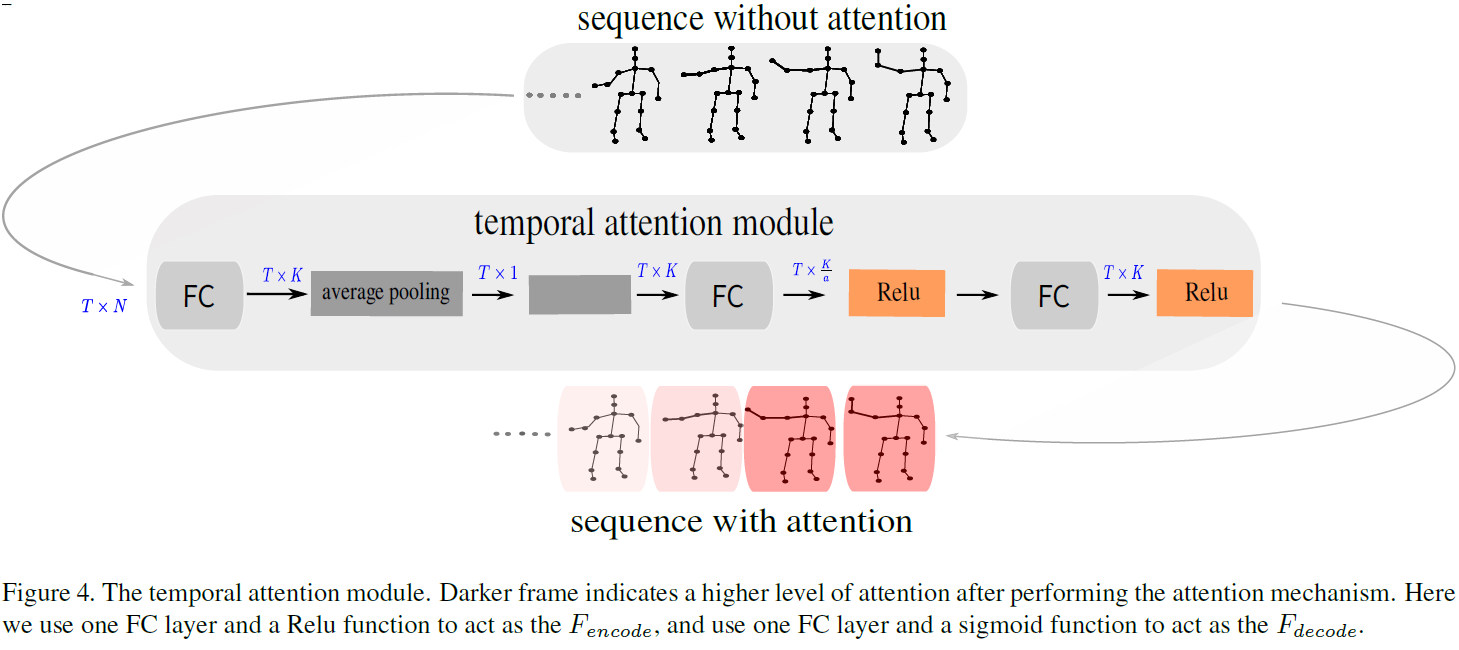
以原始的graph序列为输入,最后得到TK维的attention map,直接与TK维的LSGM输出特征O相乘。中间的过程很好理解,直接看图。图中有个黑色方块里面没有标注,作用是将T1维tensor直接复制成TK维,作者可能忘了标注。temporal attention过程的公式表达如下: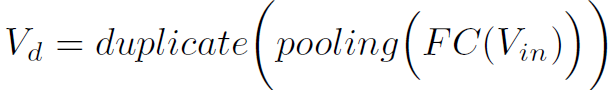
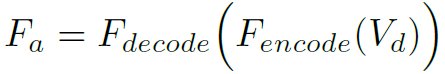
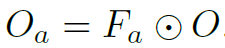
作者反复强调的创新点之一GTSC模块反而只用了很小一段文字介绍。其实就是在最后得到的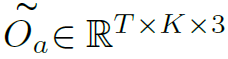 (有3个LSGM concat,所以最后一维为3)的特征基础上,再经过几个卷积层增强一下。
(有3个LSGM concat,所以最后一维为3)的特征基础上,再经过几个卷积层增强一下。
Experiments
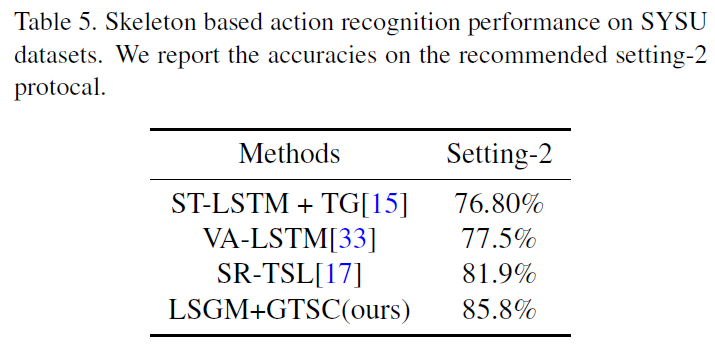
作者在NTU RGB+D Dataset和SYSU-3D Dataset上做了实验,表现还行吧,但是没超过现有SOTA。具体看原文。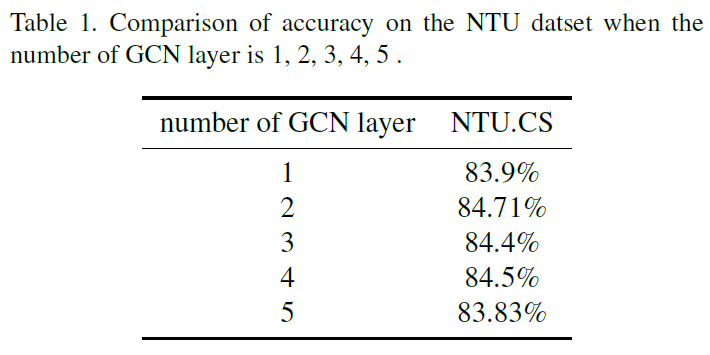
总结
文章在创新和完成度上和CVPR这类顶会还是有一定差距,但也是不错的工作。对于作者将xyz三维分离的这种做法,文中并没有给出消融实验,个人也是第一次见到,还是有点质疑其是否有必要的。这样做是否反而破坏了特征之间的dependence?

若有收获,就点个赞吧
0 人点赞
