ICCV 2019 论文标题:RepPoints: Point Set Representation for Object Detection 论文地址:http://openaccess.thecvf.com/content_ICCV_2019 代码地址:https://github.com/microsoft/RepPoints

简介
本文提出了一种运用representative points表示图像中的objects的方法。该方法可以应用于目标检测任务,相比于传统的bounding box方式,效果有一定提升。基于RepPoints和FPN backbone,本文设计了目标检测网络RPDet。这是一种multi-stage的目标检测方法,在COCO数据集上取得了SOTA的效果。相比于Object as Points这篇文章,虽然都是尝试用points表示目标,但其实原理大相径庭。本文提出的方法,更多是借鉴于Deformable Convolutional Networks:通过显式地回归坐标偏移量,让卷积核映射于object的关键语义部位上。这里的卷积核,实际就是本文中的RepPoints。总的来讲,作者的思路还是非常巧妙的。
RepPoints
Related Work部分介绍了传统的bounding box方式表示object的缺点,总结一下:
1.bounding box只能粗略地定位目标,无法表达目标的形状和姿态。
2.在规则的bounding box中提取特征容易受到background和uninformative foreground部分的干扰,导致特征质量不高,不利于后续的目标检测等任务。
3.传统的anchor box方法需要预设大量不同scale和ratio的anchor box,检测效率不高。
针对以上缺点,本文提出的RepPoints方法可以自适应地检测目标的空间范围和语义信息,聚焦于目标重要的语义区域。下面详细介绍。
图1展示了RepPoints是如何表示object的。对于一个object,本文用9个point表示其空间位置和语义重要性。空间位置用pseudo box表示,即利用9个点生成的虚拟框。文中给出了三种不同的生成方式,但效果都差不多,分别是:
在训练过程中,ground truth依旧用box的形式表示,通过与pseudo box的比较,计算loss,来监督目标localization的学习。这里loss使用的是box左上角点和右下角点的smooth L1 loss。
语义重要性用RepPoints的位置分布表示。通过学习偏移量offset,可以让points聚集于目标更重要的区域。这里比较难理解,需要首先熟悉DFN的原理,下面详细介绍。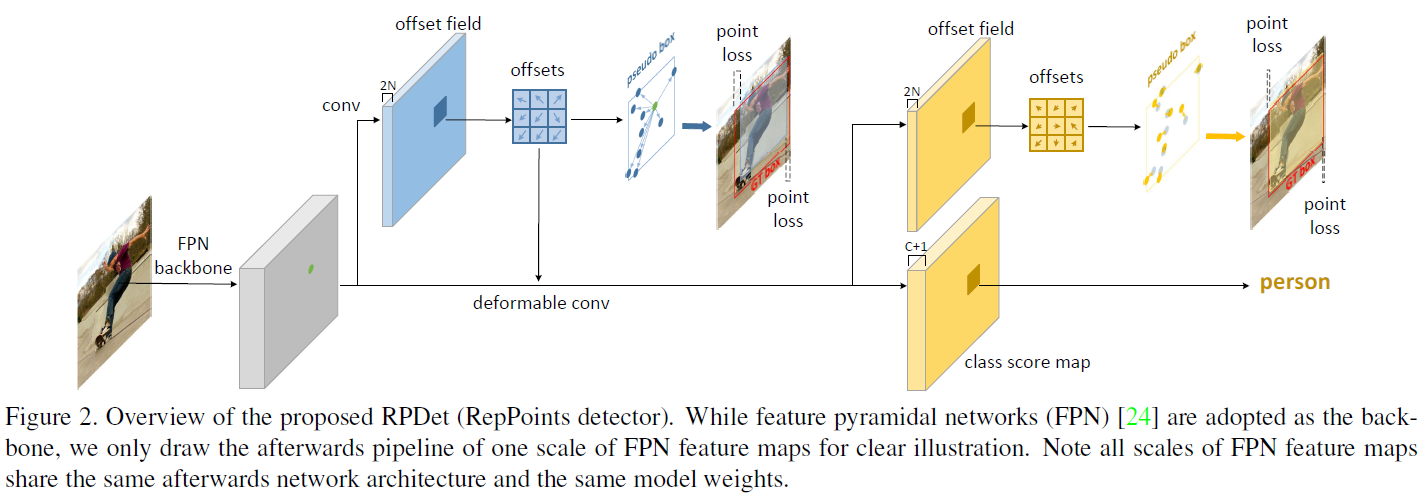
本文设计的RPDet目标检测网络的backbone采用的是FPN。RPDet取了其中的5层作为5种尺度的feature map,用于检测不同大小的object。图2仅以其中一层feature map的处理过程为例,展示了RepPoints如何学习语义信息。
首先将提取出来的feature map经过conv操作,生成channel数为2N (N=9)的offsets field。也就是说,对于每一个RepPoint,首先生成其x和y的偏移量。每个object用9个RepPoint表示,每个RepPoint又有2个偏移量,所以channel数量为2*9=18。那么偏移之前RepPoint的位置是什么呢?答案就是Center Point。这里Center Point和YOLO里的用中心点表示object是一样的,就是feature map中的每一个位置。feature map中每一个位置都表示该尺度下一个Center Point,而一个Center Point通过offsets偏移出9个RepPoints。这就是本文产生RepPoints的方式。
我们从另一个角度来看本文的RepPoints:实际上,并不存在什么RepPoints,所谓的RepPoints只不过是给Center Point加上xy偏移量。而加偏移量的作用之一,就是为了由Center Point生成目标的范围,也就是pseudo box。对比一下传统bounding box的回归方式(YOLO中的),也是由中心点坐标,加上box的宽和高(类似于偏移量),表示出目标的位置范围。也就是传统的bounding box,也可以看做Center Point加上偏移量生成2个RepPoint去表示目标的左上角和右下角点,从而得到目标的范围。本文中的RepPoints,仅仅是数量由2变为9,然后计算pseudo box的方式有所不同罢了。
那么本文中的RepPoints是否是多此一举呢?答案是否定的。因为RepPoints的巧妙之处实际上在于其天设地造地与DFN相结合,从而自适应地聚集于目标的重要语义区域。具体来讲:通过第一步我们得到了Center Point的偏移量offset,而这个offset可以直接当成DFN中卷积核的偏移量offset。利用这个offset,对feature map进一步deformable conv,就相当于让feature map的注意力集中在目标重要的语义区域,也就是RepPoints所对应的区域,实现了利用RepPoints学习目标语义信息。所以,DFN在本文中起到了关键作用。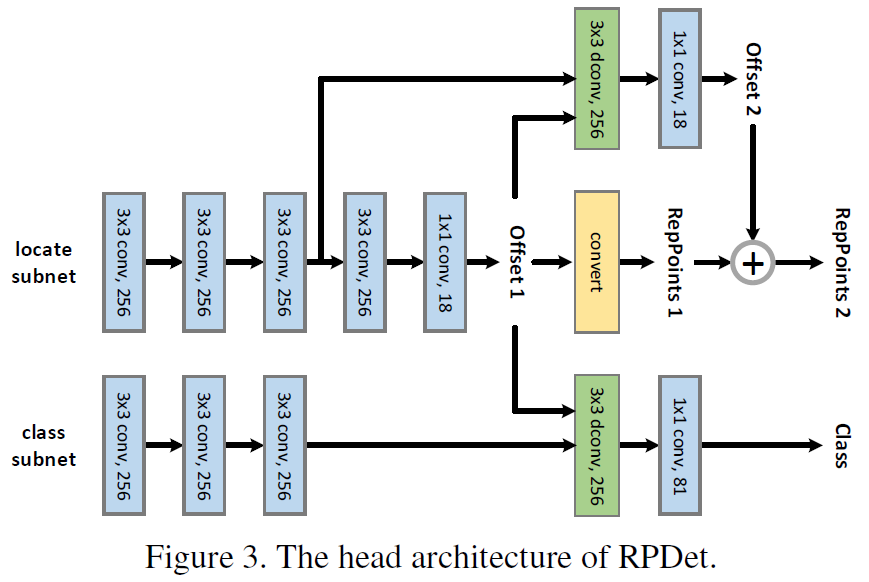
至此,我们得到了deformable conv之后的feature map。RPDet用这个feature map,再经过1181conv直接预测目标的class。而目标的location,还要再refine一次。同样这个feature map,再经过11(2*9)conv,针对9个RepPoints再做一次微小的offset调整,生成最终的RepPoints,从而得到pseudo box,也就是目标的location。以上就是本文的核心内容RepPoints。图三展示了RPDet head的细节,个人感觉这张图有一定迷惑性,需要仔细理解。
最后补充一下论文中RepPoints的表示和offsets的表示: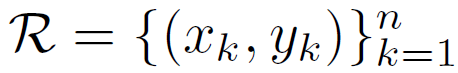
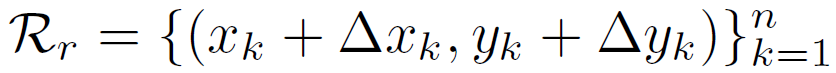
Experiments
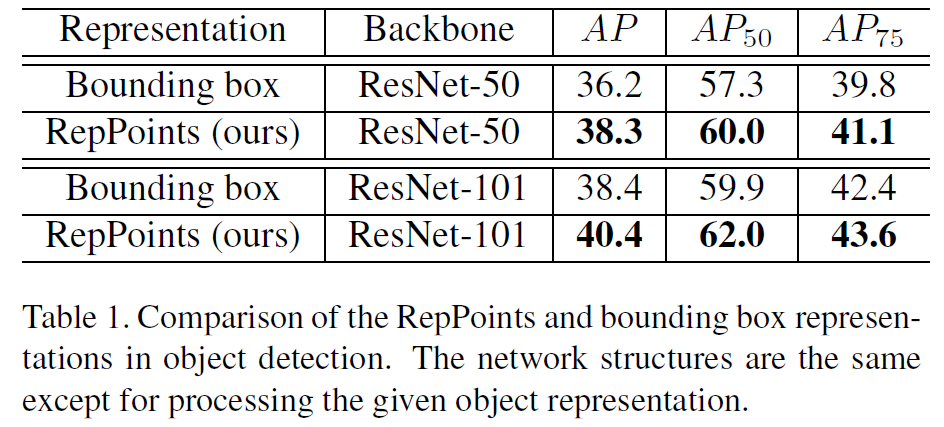
作者在COCO数据集上做了实验,总之就是优于其他anchor-free的methods,也略好于基于anchor box的methods。同时,RepPoints也确实能提取出重要的语义区域。更多的实验结果见原文。
总结
感触良多。
设想一下,如果这篇文章换一个视角去写,写成基于DFN的目标检测网络,那所表现出的contribution似乎就少了许多。因为DFN本身就具有粗略的目标检测效果,本文只是将偏移后的采样点用box框了起来,对位置进一步refine了一下。所以付导给我说过:“写论文就像讲故事一样,如何把故事讲好,是值得你仔细思考的。”
当然,本文的构思真的是非常巧妙,RepPoints可谓一箭双雕。

若有收获,就点个赞吧
0 人点赞
