ICCV 2019 论文标题:Mixture-Kernel Graph Attention Network for Situation Recognition 论文地址:http://openaccess.thecvf.com/content_ICCV_2019/papers/

简介
本文针对situation recognition任务,提出了基于GNN的模型:Mixture-kernel Attention GNN。该模型在CNN提取图像特征的基础上,以situation recognition任务中的roles为node,利用node特征动态生成邻接矩阵,构建graph结构。本文提出的GNN有两个特点:1.dynamic attention 2.mixture kernel,后文会详细介绍。最后,作者在imSitu数据集上测试该模型,得到SOTA的结果。
Situation Recognition
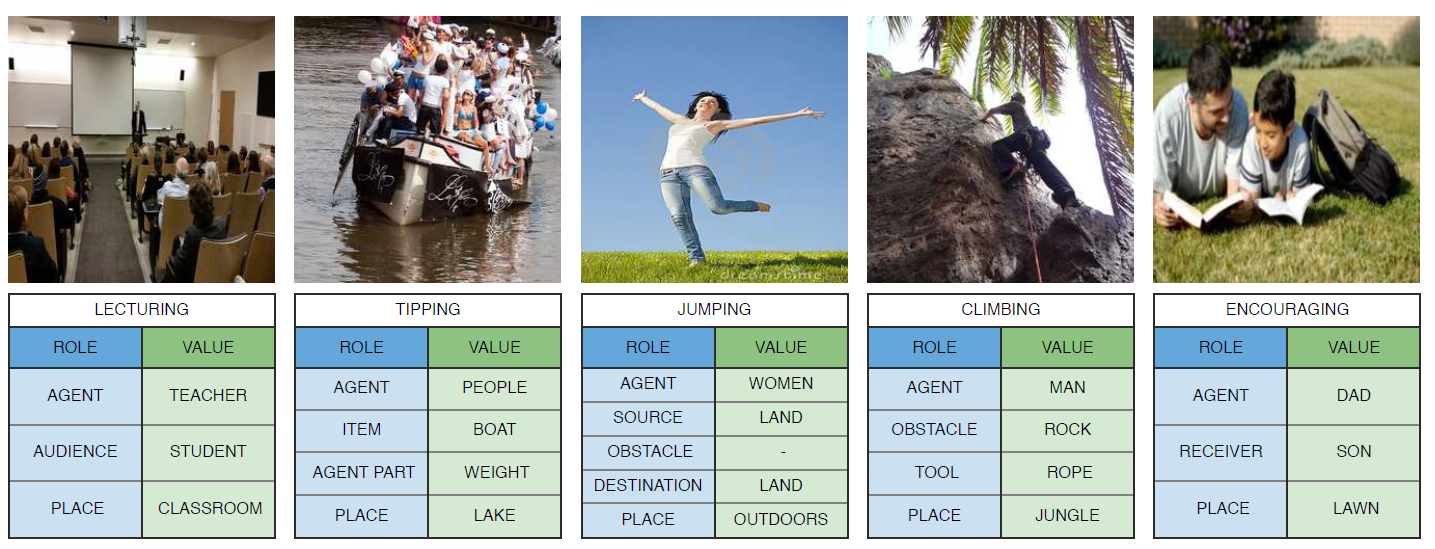
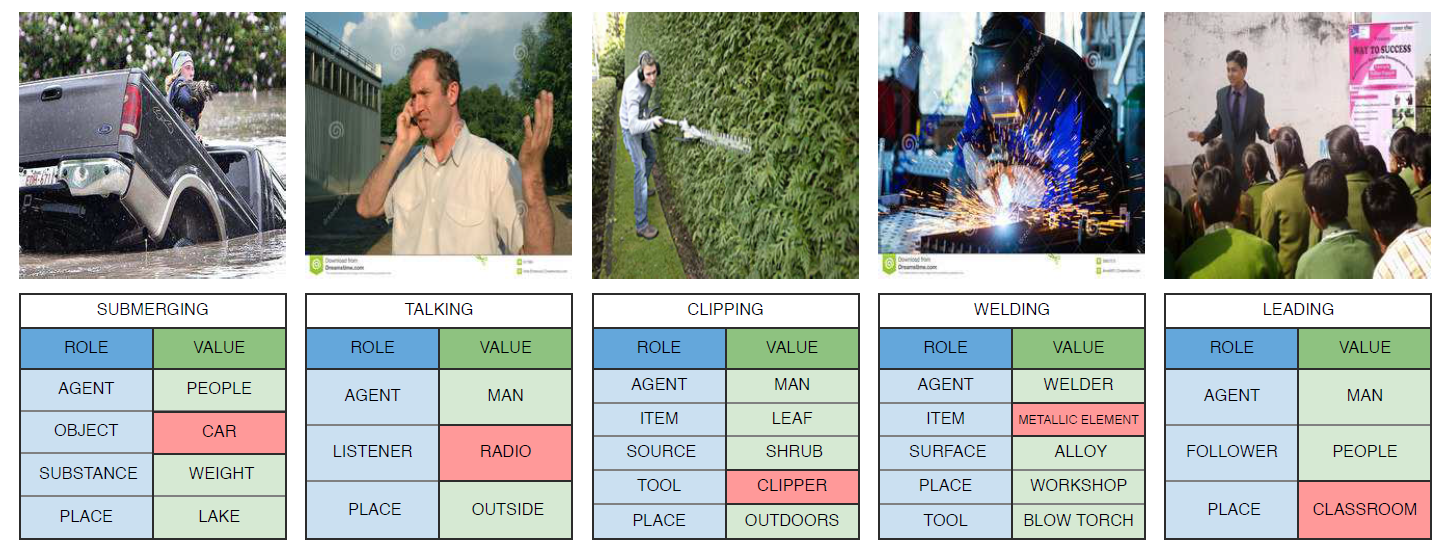
先解释一下Situation Recognition任务:该任务是要对图像主体的action进行分类,然后解析与这个action相关的语义实体,构成多个role-entity pairs。如图1所示,左边图片中主要的action是jumping,与其相关的role有agent、source、place等,对应的entity有jockey、land、outdoors等。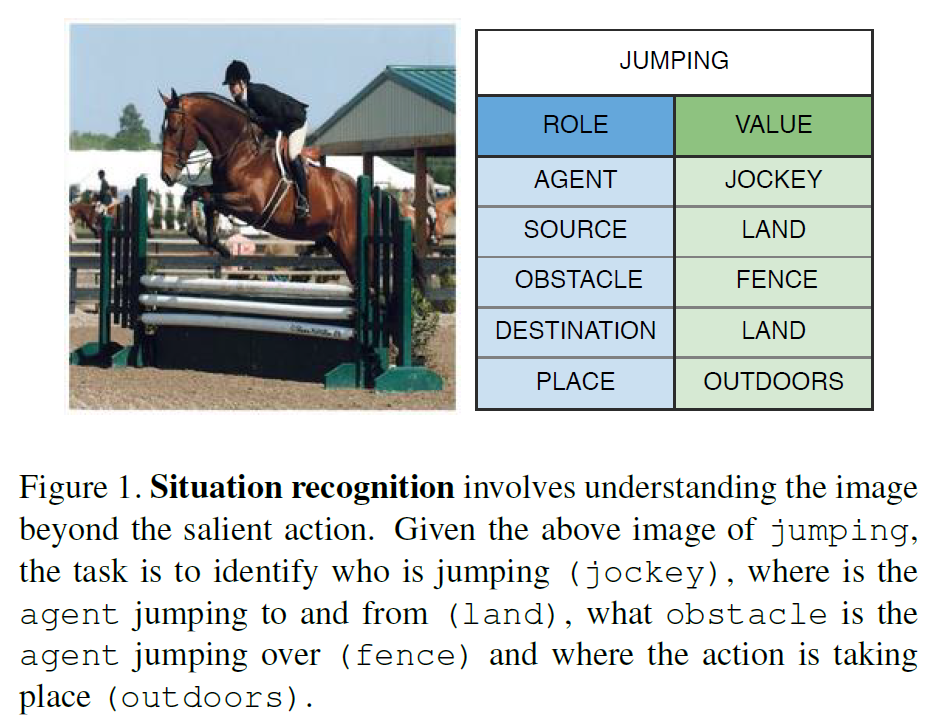
可以看到,Situation Recognition任务实际上是更深层次的图像内容理解,需要网络解析出图像中不同目标间的relation和dependence,而这正是GNN所拿手的。因此,用CNN+GNN解决这个问题在直觉上是很合理的,关键就在于这里的GNN如何设计,以及CNN和GNN如何结合。本文的重点在于GNN的设计,下面来详细分析。
Graph Neural Network
GNN设计的第一步就是要确定node和node的初始feature。mixture-kernel attention GNN (以下简称MKA-GNN)中,node是与action相应的roles。也就是说,网络首先需要识别出图像中的salient action,而每个action对应的roles是确定的先验知识,这样就得到了node。例如对于jumping,其先验roles包括了agent、source等。只要先确定了图像中的action是jumping,我们就能够得到MKA-GNN的node个数和其指代的roles。
MKA-GNN中,node的初始feature和常见的CNN+GNN模型有所不同。常见的模型是用RPN网络生成目标proposal,然后roi pooling得到object feature作为node feature。但MKA-GNN并没有目标检测的过程。也就是说MKA-GNN中node是roles,但每个role对应的entity并不是在构建graph的时候确定的。MKA-GNN中node的初始feature由以下公式确定: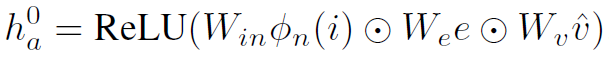
式中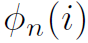 表示CNN得到的整幅图像的feature map。
表示CNN得到的整幅图像的feature map。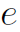 和
和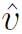 分别是one-hot编码的,CNN预测的roles和action。其中个人理解不是直接预测得到的,而是预测得到action,就能得到其先验的roles(没有开源代码,无法确定)。W均是learnable的weights,
分别是one-hot编码的,CNN预测的roles和action。其中个人理解不是直接预测得到的,而是预测得到action,就能得到其先验的roles(没有开源代码,无法确定)。W均是learnable的weights, 表示element wise的乘积。
表示element wise的乘积。
接着给出MKA-GNN聚合更新的方式: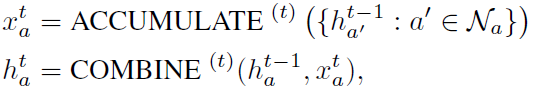
其中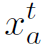 相当于message,由以下公式得到:
相当于message,由以下公式得到: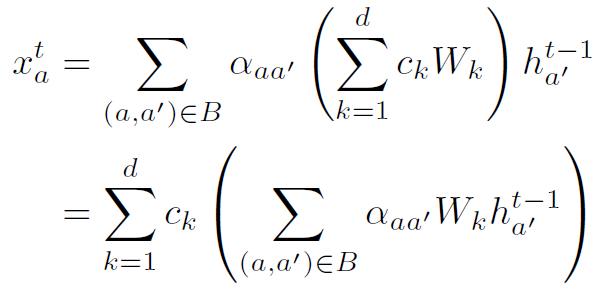
其中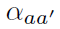 是邻接矩阵在下标aa’处的值。
是邻接矩阵在下标aa’处的值。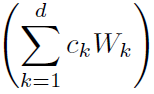 是MKA-GNN的核心之一mixture kernel,后文介绍。
是MKA-GNN的核心之一mixture kernel,后文介绍。
具体的COMBINE公式类似于一个GRU单元,如下:
GNN经过T步(实验中T=4)的聚合更新,最终用role feature得到其对应的entity: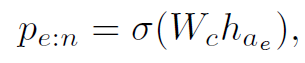
这里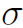 是指softmax函数,作者用的不是很规范(一般论文中
是指softmax函数,作者用的不是很规范(一般论文中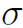 都表示sigmoid函数)。
都表示sigmoid函数)。
下面来讲MKA-GNN的两个核心内容。
Dynamic Graph Structure
有很多文章中将邻接矩阵的权重称为attention,本文亦是如此。MKA-GNN中邻接矩阵不是固定的,而是由node的特征生成的,作者称为dynamic attention,其实这种方式目前还是比较普遍的。下面是邻接权重的计算公式: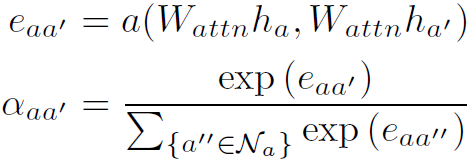
式中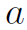 是一个得到scalar的计算公式,文中好像没有给,一般会是一个sigmoid函数。由softmax函数得到,这也是attention的典型计算方式。
是一个得到scalar的计算公式,文中好像没有给,一般会是一个sigmoid函数。由softmax函数得到,这也是attention的典型计算方式。
文中作者给出了一些邻接矩阵attention的可视化,可以看到即使是相同的action,网络得到的attention也是不同的:
Context-aware Interaction
这部分讲如何得到mixture kernel。作者设计mixture kernel的motivation是对于同一个类型的action,其roles之间的attention往往是存在某些相似性的,或者说某种generalized的模式。而对于不同的action,其roles之间的关系往往是不同的模式,尽管roles的类别可能相同。原文中是这样描述的:
本文研究了imSitu数据集中512类action的相似性,将其分为252组。同组的action是有着相似的roles关系模式的,因此作者给网络设计了252个basis kernels。这里basis kernels其实就是252个先验的邻接矩阵,是网络在训练过程中学习得到的。然后在inference过程中,以不同action的置信度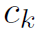 为权重,对252个先验的邻接矩阵加权求和,得到mixture kernel,也就是message公式中的
为权重,对252个先验的邻接矩阵加权求和,得到mixture kernel,也就是message公式中的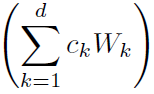 部分。
部分。
简单来讲,MKA-GNN有两个邻接矩阵,一个是由node特征生成的dynamic attention,另一个是先验的mixture kernel,两者共同控制GNN的信息聚合过程。mixture kernel的计算公式如下: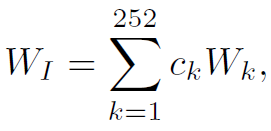
注意一下这里是252个置信度,但action的类别不止252个,所以要先将同类action的置信度加合起来。
最后贴一下网络的整体结构示意图3,如果没有上文的说明,直接看图还是很难看懂的: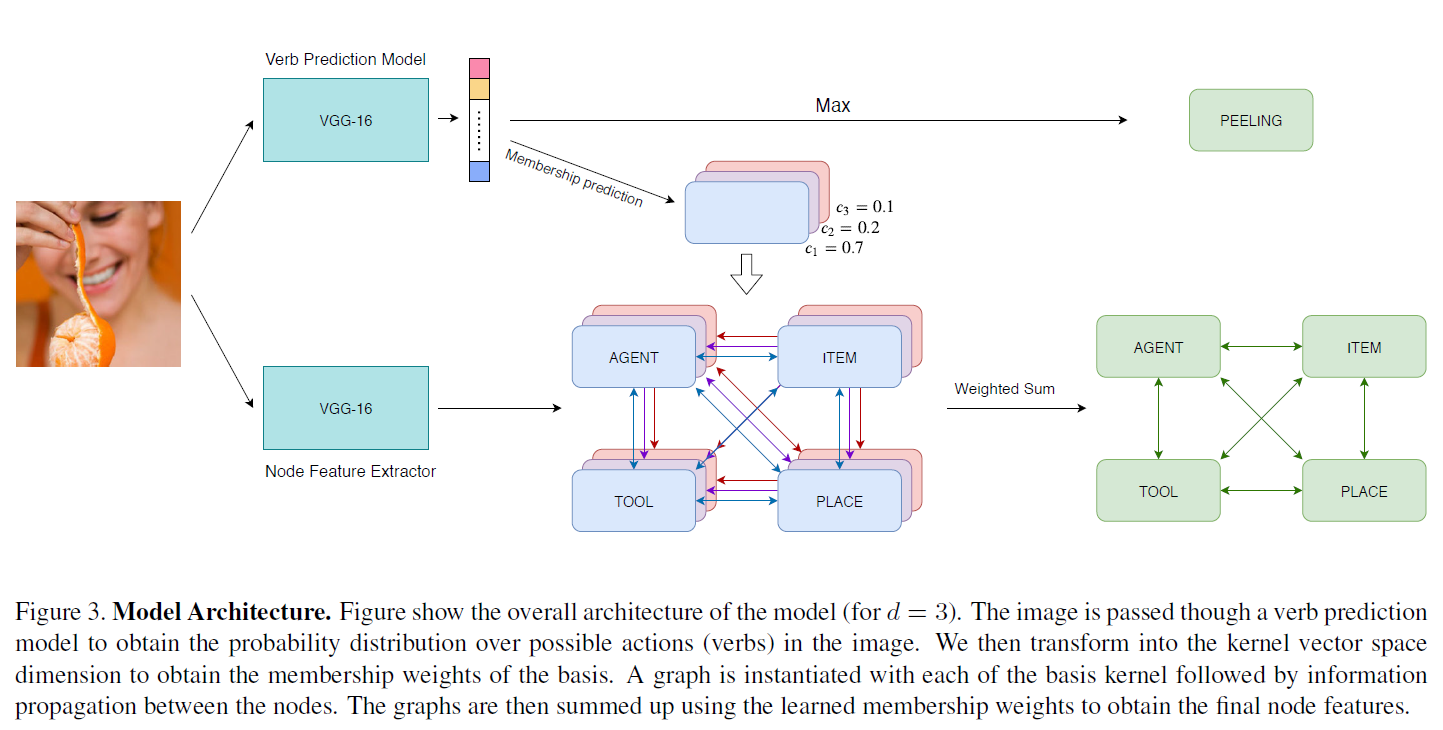
从图3中可以看到,本文模型中使用了两个VGG16作为CNN backbone。一个用于识别action,生成不同action的置信度,另一个用于提取role feature,两个VGG16不共享参数。
在下方GNN部分,作者用叠加的图形表示mixture kernel。为什么要这样描述,我们从另一个角度再来看一下本文中GNN message的计算公式:
上式是本文中GNN的信息聚合方式,作者特意对其的形式做了进一步推导。从这个导出式子来看,括号内的部分可以当做一个传统的GNN信息聚合。而括号外表示将很多个GNN以为权重加权和。也就是说,MKA-GNN可以理解为d个GNN以为权重的加权和,这些GNN是共享node feature的,文中d=252。
以上就是MKA-GNN的主要内容。对于loss函数,模型中用到的都是cross entropy。
Experiments
目前situation recognition的数据集好像只有imSitu。作者也做了Ablation Study说明了mixture kernel的有效性。
总结
本文的MKA-GNN算是对GNN的结构有所创新,尤其是mixture kernel,很有意思。但模型训练了两个独立的VGG16,肯定是为了提升效果,但感觉有点浪费资源,要是能整合在一个CNN backbone中就好了,实现一下特征重用。
另外说明一下为什么有的论文中是GNN,有的是GCN。其实统称为GNN比较好。现在这些花里胡哨的GNN结构应该都是没有严格数学证明的,即不是对graph进行傅里叶变换再与核函数乘积再反变换得到的。就和CNN的发展过程一样,现在常用的deformable convolution之类各种奇奇怪怪的CNN也都是抛弃了卷积严格的数学推导。总之效果好就对了。其中GCN在有的理论性文章中特指一种有严格数学证明的GNN,是在图傅里叶变换的基础上,在谱域推导出来的。但在CVPR、ICCV之类的很多文章中,GNN和GCN都是指广义的定义在graph上的神经网络。所以如果不是严格的理论性文章,GNN和GCN区别不大。但在理论性文章中,GNN包含的范围更广一些,GCN往往是特指。

若有收获,就点个赞吧
0 人点赞
