AAAI 2020 论文标题:Detecting Human-Object Interactions via Functional Generalization 论文地址:https://arxiv.org/abs/1904.03181

简介
本文针对HOI检测任务中数据集的长尾分布问题以及广泛存在的zero-shot问题提出了名为Functional Generalization Module的解决方法,贡献点十分突出,思路也很新颖。现实中人体的一种交互动作可以作用于很多对象,如“吃-xxx”,后面可以跟着任何食物。而数据集不可能包含人吃所有食物的图像样本。因此,作者提出的模型抛弃了object的视觉特征,而是用human和object的word embedding作为feature,来赋予模型zero-shot learning的能力。
Functional Generalization Module
作者的motivation在于人与功能相似的物体交互的时候,人体的动作也是相似的(如图1)。因此,识别人物交互的关键在于人体的视觉特征(动作)以及物体的功能相似性。本文提出的模型利用人和物的word vector,人和物的空间关系特征以及人的视觉特征完成HOI识别,并未直接利用物体的视觉特征,从而使模型对动作的识别不再依赖于特定的object。
模型的结构非常简洁,如图2: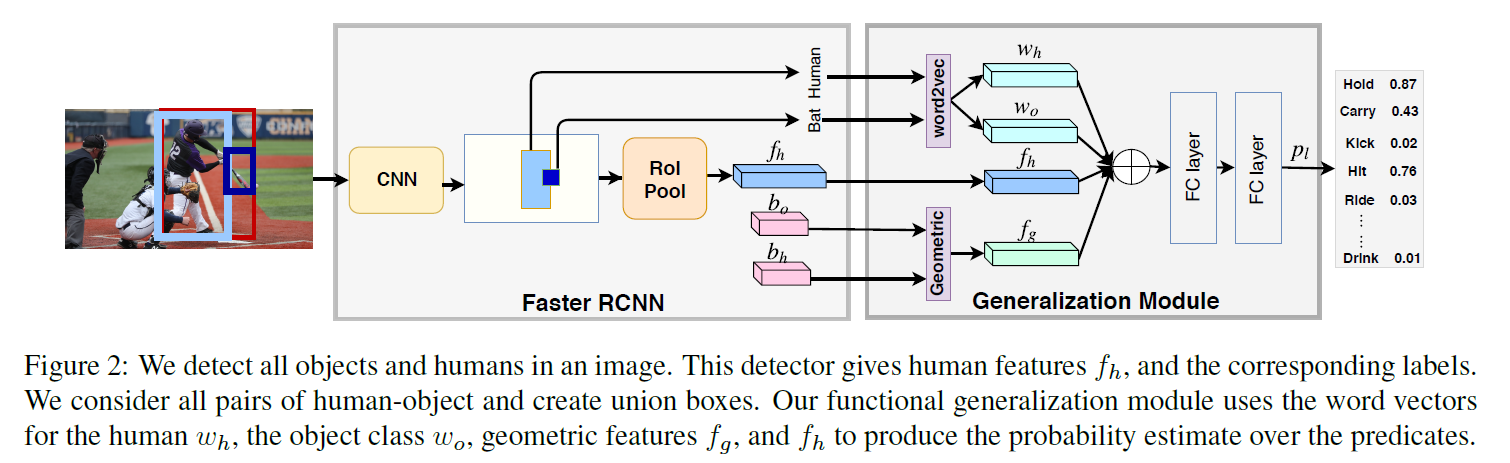
首先利用Faster RCNN做目标检测,这里Faster RCNN是在Open Images dataset (OID)上训练的,可以识别545种目标类别,其对human的识别会精确到man/woman/boy/girl/person,object的类别也远多于HICO-DET。之后用ROI pooling操作在feature map上得到human visual feature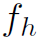 。是该模型中唯一直接利用的视觉appearance特征。
。是该模型中唯一直接利用的视觉appearance特征。
根据目标检测得到的边界框,作者构造了一个Geometric features来表达human和object的相对位置关系, 的计算方法如下:
的计算方法如下: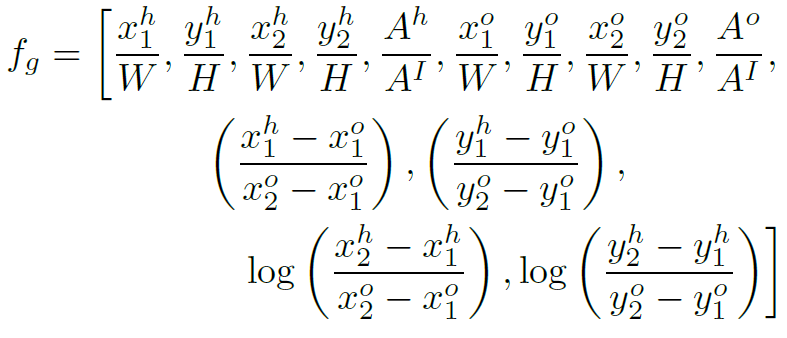
其中W和H是图像的宽和高,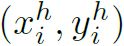 和
和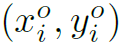 是人体和物体的bounding box,
是人体和物体的bounding box,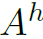 ,
,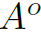 和
和 分别是人体框,物体框和图像的面积。直接构造Geometric features这种方式相比于iCAN中构造spatial configuration的方式,参数量和计算量更小。
分别是人体框,物体框和图像的面积。直接构造Geometric features这种方式相比于iCAN中构造spatial configuration的方式,参数量和计算量更小。
图2中最上面那部分word2vec是本文的核心贡献点。作者没有使用视觉appearance feature,而是利用目标检测得到的人和物类别的词嵌入向量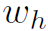 和
和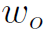 作为特征。最后,作者将,,和 concat起来,放入MLP直接分类。
作为特征。最后,作者将,,和 concat起来,放入MLP直接分类。
Generalizing to new HOIs
如果上述模型结构还不能体现出本文思路的巧妙,那这部分肯定能让人眼前一亮。之前说了,本文提出的模型不使用object的视觉appearance特征,直接使用object类别的词嵌入。这就意味着,这个模型的训练不再约束于数据集中已有的object类别,而是可以用功能相似的object替换图像中的object。例如训练样本中存在“吃热狗”这个动作样本,那此处的“热狗”实体可以随意替换成相似的“披萨”、“汉堡”等等。这样相当于扩充了数据集的样本数量,实现了zero-shot learning。这部分作者就详细介绍了这个思路的具体操作。
首先要找到功能相似的object。作者将各类object的视觉appearance特征和词嵌入向量concat起来,构造一个更加鲁棒的特征表示。用这个特征表示对objects进行非监督聚类,得到K种功能相似的object种类。
之后生成数据集中没有的训练数据。就是利用功能相似的object的wordvec替换样本中原有的wordvec,而label保持不变,人体的视觉特征以及人物位置关系也保持不变(如图3)。通过这种方式,可以构造大量数据集中不存在的交互样本。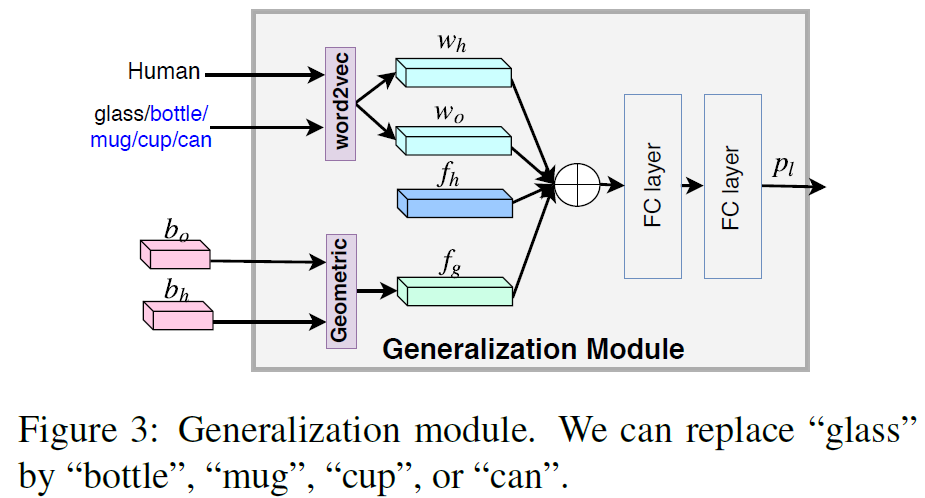
最后,在训练过程中,作者也有用到一些小trick。人物交互动作识别是一种多类别二值分类,例如
Experiments
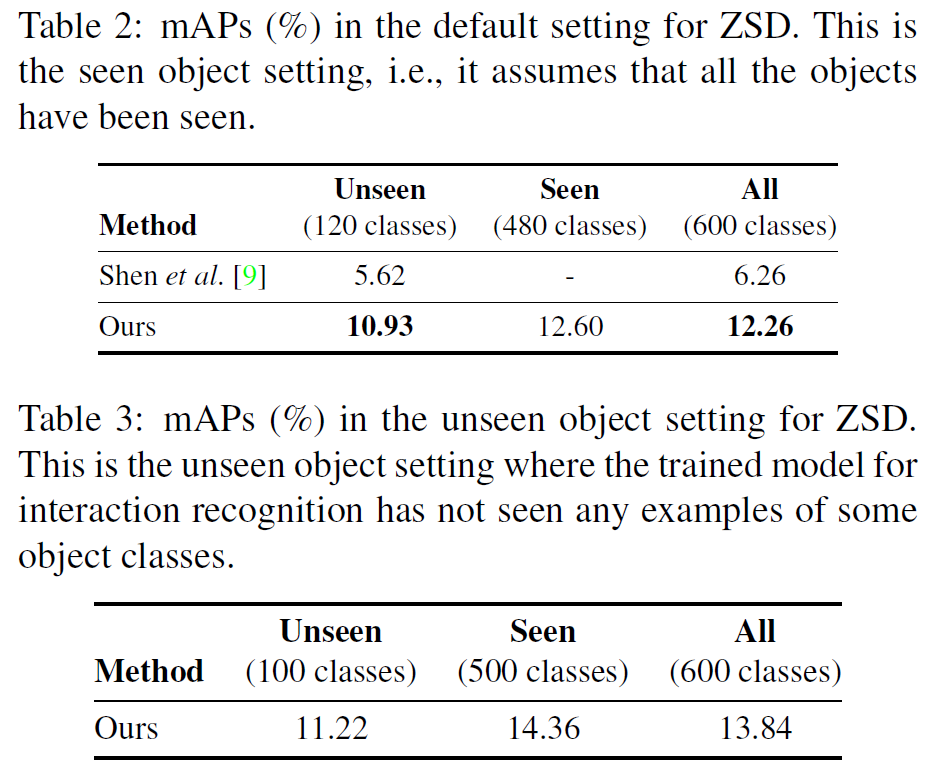
作者只在HICO-DET数据集上做了实验,并没有V-COCO的实验。但HICO-DET上的结果超过现有SOTA不少。另外,针对zero-shot HOI detection,作者专门验证了模型的有效性。


总结
贡献点很突出,思路让人眼前一亮!模型结构简洁,没有任何所谓的context feature、reasoning之类的东西,就达到了如此好的效果。真的是一篇很有启发性的文章。

若有收获,就点个赞吧
0 人点赞
