ICCV 2019 论文标题:Graph Convolutional Networks for Temporal Action Localization 论文地址:http://openaccess.thecvf.com/content_ICCV_2019/papers/

简介
本文将GCN引入视频动作识别和定位任务,提出了用P-GCN解析action proposal之间的时域关系 (proposal-proposal relation),从而使单个proposal的特征聚合其邻域proposal的特征,提高识别和定位精度。作者以action proposal为node创建graph,将node之间的relation分为两类:contextual和surrounding,作为edge。再用GCN经典的信息聚合更新函数对每个node的feature进行refine。最后,为了解决node的邻接结点过多,计算量大的问题,作者采用SAGE method在邻域进行采样,以降低网络计算量。在数据集THUMOS14和ActivityNet上进行测试,P-GCN表现出SOTA的效果。
Proposal Graph Construction
本文的P-GCN模型是构建在视频特征提取网络的基础上的。在实验中作者用了Two-stream Inflated 3D ConvNet
(I3D)模型提取视频的proposal和feature,这里就不详细介绍了,直接来看本文的核心内容P-GCN。
先给出一个概括性的公式说明P-GCN在做些什么: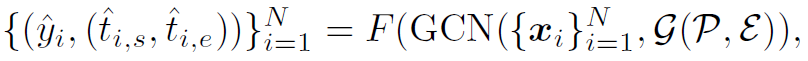
式中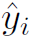 表示动作类别,
表示动作类别,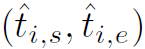 表示动作时域定位,
表示动作时域定位,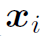 表示node feature,
表示node feature, 表示graph。N为node的个数,即action proposal的个数。可以看出,P-GCN就是以action proposal为node构建graph,经过GCN网络在graph上聚合更新feature,最后经过映射函数F将特征映射为识别和定位的结果。简单来讲,本文就是用GCN对CNN提取的feature根据temporal relation做一个refine,使feature具有更强的表达能力。
表示graph。N为node的个数,即action proposal的个数。可以看出,P-GCN就是以action proposal为node构建graph,经过GCN网络在graph上聚合更新feature,最后经过映射函数F将特征映射为识别和定位的结果。简单来讲,本文就是用GCN对CNN提取的feature根据temporal relation做一个refine,使feature具有更强的表达能力。
再来看一下网络的整体结构,如图1:
可以明显看到,P-GCN由两个独立的GCN组成,他们的输入输出各不相同,但graph结构是相同的(并不共享参数)。其中GCN1用于做动作分类,GCN2用于做定位。因此作者让GCN2的输入做一个boundary extension,定位效果会更好。以上就是P-GCN的整体结构,下面来看网络细节。
Graph Node
前面讲到过,P-GCN以视频特征提取网络输出的action proposal为graph的node,以其提取出的feature为node的初始特征。这是一种很典型的方法,用GCN解决CV问题的论文大都这么做。但需要指出的是,其他论文中graph的各个node大多是在spatial域的,将空间划分为单个目标。而这篇论文的各个node是在temproal域的,对时间划分。很有意思。
Graph Edge
作者将proposal-proposal relation分为两类。第一类是contextual edge,由以下公式确定: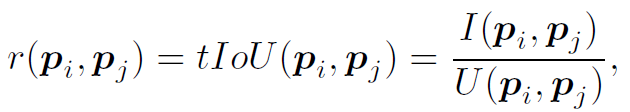
当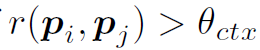 时,两个proposal之间存在edge。很好理解,
时,两个proposal之间存在edge。很好理解,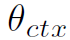 是阈值,这个公式就是指时域邻近的两个proposal之间存在relation,用tIOU判断是否邻近。
是阈值,这个公式就是指时域邻近的两个proposal之间存在relation,用tIOU判断是否邻近。
第二类是surrounding edge,由以下公式确定: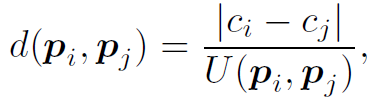
当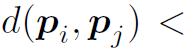
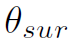 时,两个proposal之间存在edge。这个公式可以画个图帮助理解,式中c是指proposal的时间中心值。整个公式表达的是两个proposal中心靠得越近,但边界离得越远,则存在surrounding关系。作者给出的解释是这种proposal有可能存在不同的action,但很可能场景是相同的,场景信息也有助于action的识别。
时,两个proposal之间存在edge。这个公式可以画个图帮助理解,式中c是指proposal的时间中心值。整个公式表达的是两个proposal中心靠得越近,但边界离得越远,则存在surrounding关系。作者给出的解释是这种proposal有可能存在不同的action,但很可能场景是相同的,场景信息也有助于action的识别。
那么以上两个公式确定了node之间有没有edge,但edge的权值具体是多少,本文用以下公式计算: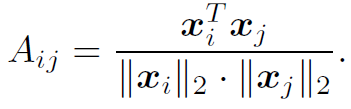
式中A就是邻接矩阵,x表示node feature。整个公式是在衡量特征的相似性,称为cosine similarity。作者指出,在计算cosine similarity之前,可以先对特征做一个线性映射,也就是加一个全连接层。
Graph Convolution
以上,我们已经定义好了graph的结构,下面来看如何进行graph的聚合与更新。很多论文在这里下了很多功夫,但本文只用了最基础的方式:
其中A是邻接矩阵, 是node feature,
是node feature,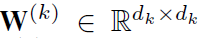 是learnable的weights。
是learnable的weights。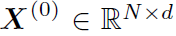 就是初始权重,直接从特征提取网络获得。之后,对式中得到的
就是初始权重,直接从特征提取网络获得。之后,对式中得到的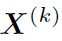 做一个非线性激活 (Relu),作为下一层GCN的输入。对于K层的CGN来说,其输出的特征为
做一个非线性激活 (Relu),作为下一层GCN的输入。对于K层的CGN来说,其输出的特征为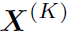 。作者为了保留初始特征的信息,让
。作者为了保留初始特征的信息,让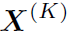 与
与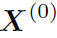 concat起来,作为node最终输出的feature:
concat起来,作为node最终输出的feature: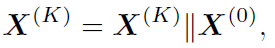
得到了最终的feature之后,用传统的全连接MLP做分类与位置回归: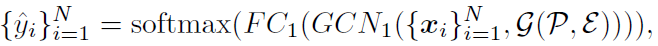
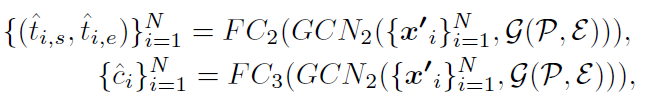
其中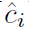 作者说是completeness,目的是防止出现tIOU很低,但分类score很高的情况,影响模型精度的评价。
作者说是completeness,目的是防止出现tIOU很低,但分类score很高的情况,影响模型精度的评价。
SAGE Sampling
最后,作者提到一个问题:通常特征提取网络会得到成百上千个action proposal,如果将他们之间的relation全部考虑的话数量太多了,计算量比较大。所以在GCN聚合更新时,作者用SAGE method对node的邻接node进行采样。SAGE采样的具体方法我还没看懂,这里给出作者的描述:
(补充:大概看了下GraphSAGE原文,这里top-down passway大概就是说GCN上层node的embeding是聚合下层node的embeding得到的,聚合方法是固定数量在邻域随机采样。)
所以,聚合更新的函数变为以下形式: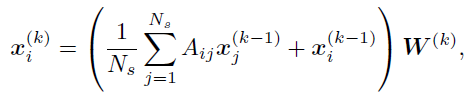
其中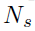 是固定的采样个数,实验中作者取4。另外,我们注意到这个公式中有
是固定的采样个数,实验中作者取4。另外,我们注意到这个公式中有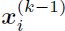 项,实际上这是在邻接矩阵中加了自环。
项,实际上这是在邻接矩阵中加了自环。
Experiments
作者在Experiments中描述了很多网络细节,比如特征的维度之类的。我们重点关注一下loss函数。本文中分类结果y和completeness c使用的loss分别是cross entropy和hinge loss。时域边界回归loss是smooth L1。另外,在模型训练时需要SAGE采样,但测试时并不需要。在THUMOS14和ActivityNet数据集上,P-GCN都表现很好。作者还做了一些消融实验,详见原文。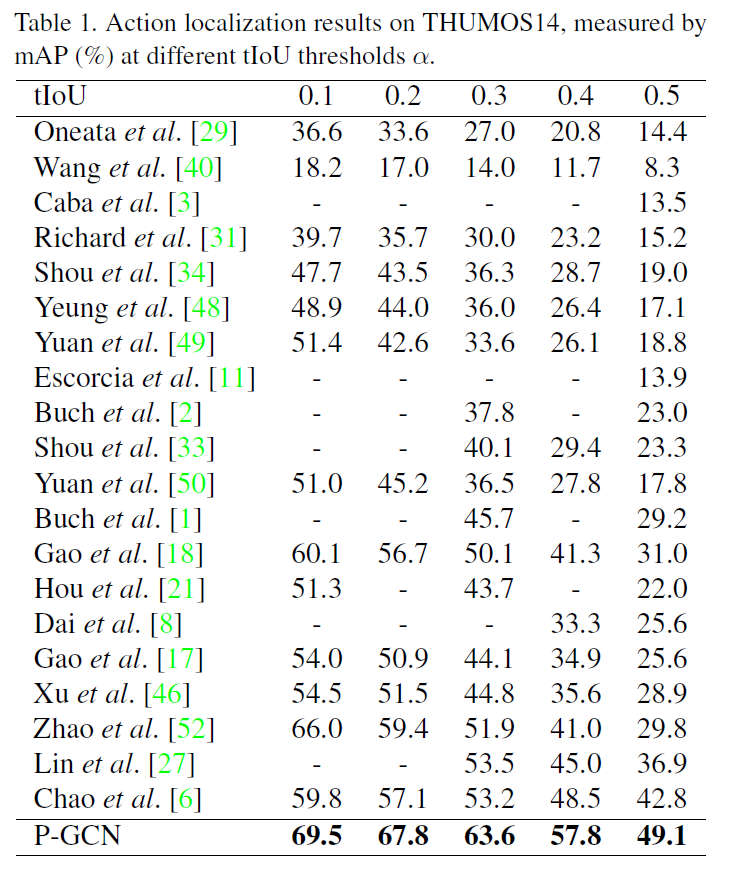


总结
个人第一次见到用GCN分析时域relation的文章,思路很新颖,模型好理解,值得借鉴。目前GCN已经开始蔓延到CV领域的各个角落了!但这些精巧的设计,为什么都不开源呢???另外,本文的GCN1和GCN2是否在计算上有点重复呢,要是能在保证精度的前提下合并起来就更好了。

若有收获,就点个赞吧
0 人点赞
