CVPR 2020 论文标题:Object Relational Graph with Teacher-Recommended Learning for Video Captioning 论文地址:https://arxiv.org/abs/2002.11566

简介
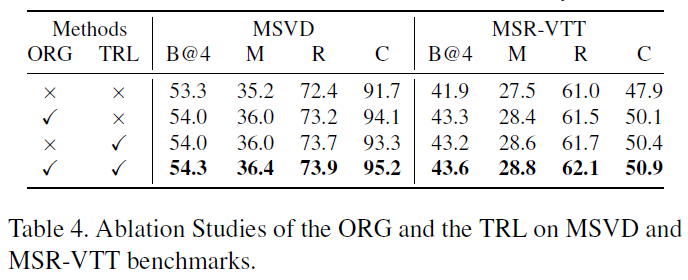
本文针对Video Captioning任务提出了基于对象关系图的编码器(ORG)以充分挖掘视频中的对象语义关系。同时以成熟的语言模型为teacher,提出了教师推荐学习方法(TRL)引入外部语料知识来缓解数据集长尾分布问题。以上两个创新点使模型在MSVD、MSR-VTT和VATEX数据集上的表现达到了SOTA。
Methodology
模型的整体结构如图2,这种CV+NLP的模型通常是比较复杂的,需要跨越语言和视觉特征表示之间的gap,因此Video Captioning也算是比较复杂的任务。本文的创新点主要是Object Encoder和Teacher-recommended Learning模块,设计都很巧妙。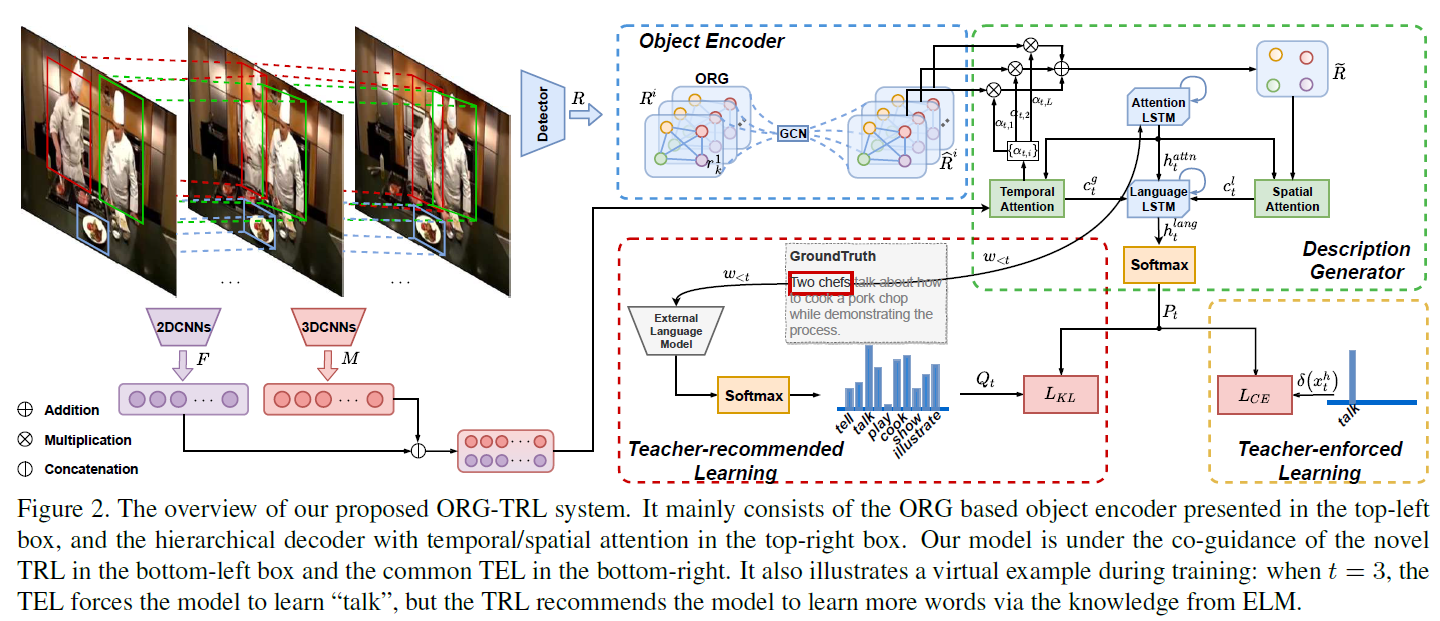
Object Relational Graph based Visual Encoder
本文首先要对视频提取以下三种特征:(1)利用2DCNN对采样的关键帧提取的全局特征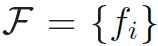 。(2)利用3DCNN对采样的片段提取的运动信息
。(2)利用3DCNN对采样的片段提取的运动信息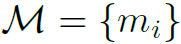 。其中
。其中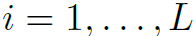 表示关键帧或片段的个数。(3)目标检测网络提取的关键帧上所有的实体特征
表示关键帧或片段的个数。(3)目标检测网络提取的关键帧上所有的实体特征 ,其中i=1,…,L,k=1,…,N,分别表示关键帧个数和目标个数。
,其中i=1,…,L,k=1,…,N,分别表示关键帧个数和目标个数。
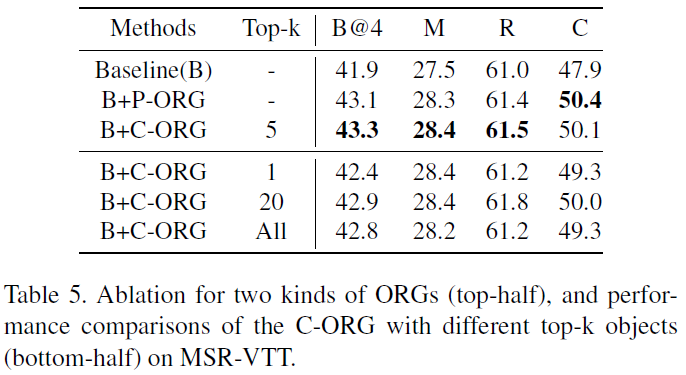
本文对象关系图分为两种:P-ORG和C-ORG,分别是局部图和全局图。P-ORG定义在单个关键帧上,以一帧图像上的实体为结点。C-ORG定义在所有关键帧上,以检测到的所有实体为结点。图的邻接矩阵计算方式如下: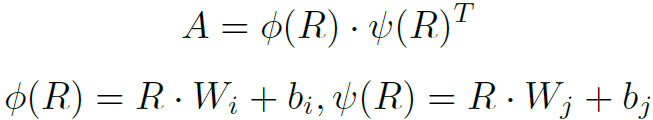
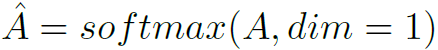
其中W和b是可学习的weights和bias。之后利用GCN在图上聚合信息,从而提取实体关系特征: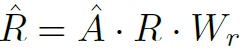
其中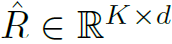 是GCN增强之后的结点特征,
是GCN增强之后的结点特征,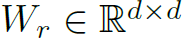 是可学习的权重矩阵。另外,在P-ORG上进行GCN的时候,不同P-ORG共享GCN权重。在计算C-ORG的邻接矩阵时,对于每个结点仅保留前K个邻接结点,其余视为不邻接(如图3)。
是可学习的权重矩阵。另外,在P-ORG上进行GCN的时候,不同P-ORG共享GCN权重。在计算C-ORG的邻接矩阵时,对于每个结点仅保留前K个邻接结点,其余视为不邻接(如图3)。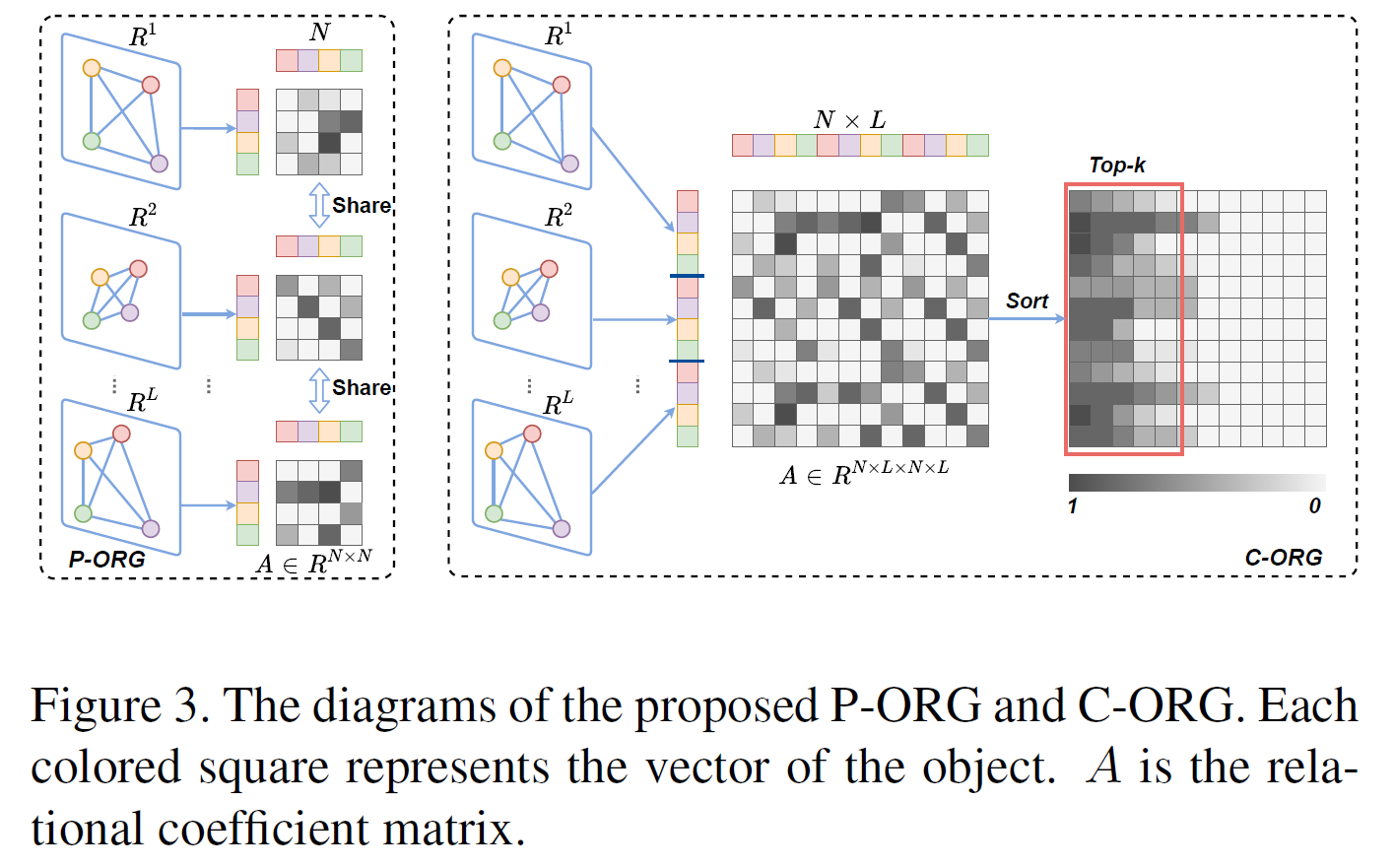
Description Generation
本人对Video Captioning任务比较陌生,这部分理解的不是很透彻。总体来讲,本文用两个LSTM模块逐步生成文本描述。首先是Attention LSTM: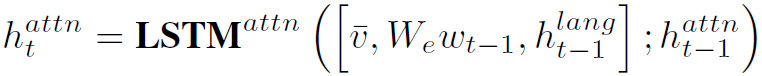
其中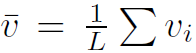
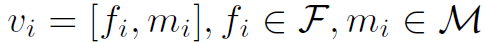 。
。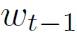 为t-1步解析得到的词向量。
为t-1步解析得到的词向量。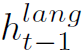 表示t-1步Language LSTM的隐藏状态。
表示t-1步Language LSTM的隐藏状态。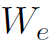 为可学习的词嵌入矩阵。
为可学习的词嵌入矩阵。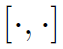 表示concat。
表示concat。
然后是Language LSTM: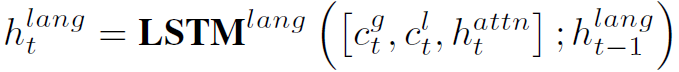
其中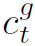 为temporal attention之后的全局特征:
为temporal attention之后的全局特征: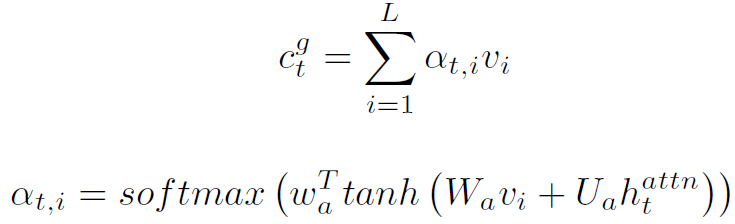
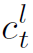 为temporal attention+spatial attention之后的局部特征。这里说明一下,局部特征指的是关键帧上的实体特征,要对其进行temporal attention必须先知道哪些实体表示的是不同帧上的同一实体,即要进行匹配操作。用特征向量cos定义实体相似度如下:
为temporal attention+spatial attention之后的局部特征。这里说明一下,局部特征指的是关键帧上的实体特征,要对其进行temporal attention必须先知道哪些实体表示的是不同帧上的同一实体,即要进行匹配操作。用特征向量cos定义实体相似度如下: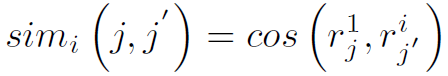
上式表示第一帧上实体 j 和第i帧上实体 j’ 的相似度用其初始特征向量的cos表示。这样就可以找到第一帧上每个实体在各帧的对应。然后用之前计算的temporal attention对同一实体特征加权求和,得到了N个实体的特征向量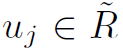 。再对其进行spatial attention,得到:
。再对其进行spatial attention,得到: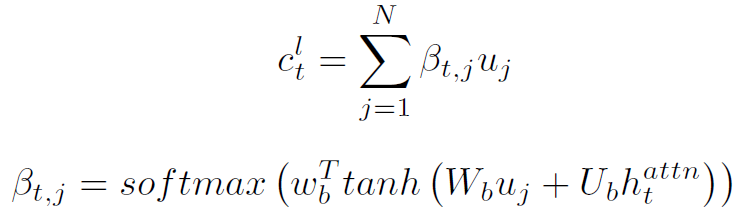
利用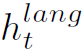 得到t步的word:
得到t步的word: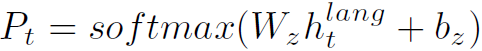
其中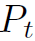 是D维的向量,D为所有单词数。
是D维的向量,D为所有单词数。
Teacher-recommended Learning via External Language Model
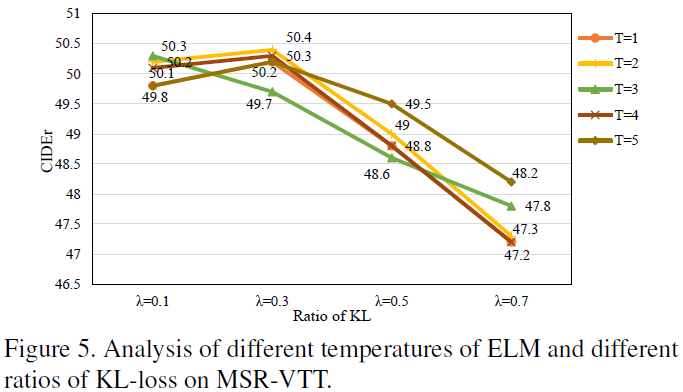
TRL模块是本文的亮点,其出发点是如果只用GT对Description Generation模块进行监督的话,存在严重的长尾分布问题。TRL用外部语料模型(ELM)在GT的每一个单词上生成一系列近似单词,来辅助监督,起到了数据增强的作用(如表1)。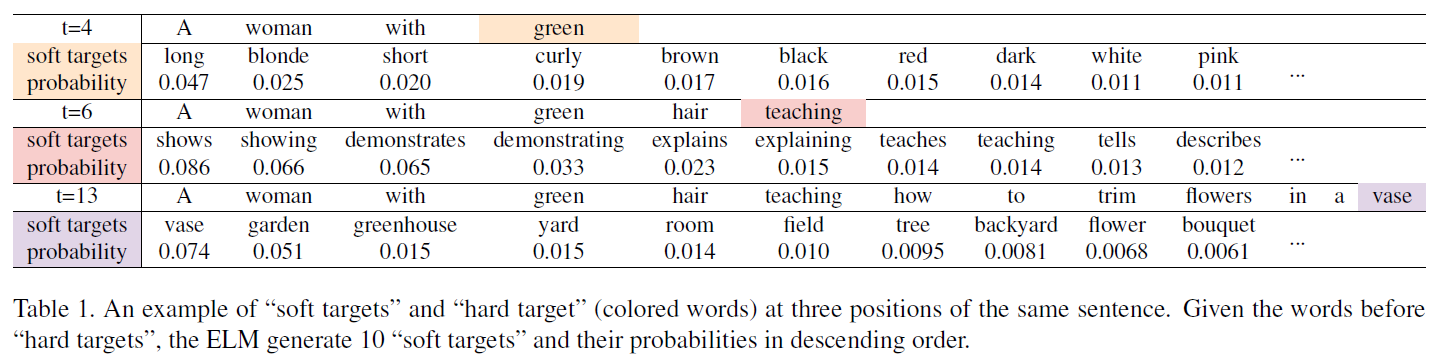
原始的loss如下: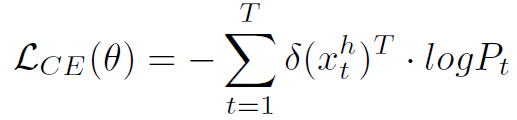
其中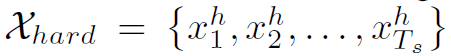 ,
,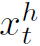 为第t步解码的gt单词,其是个D维的one hot向量。
为第t步解码的gt单词,其是个D维的one hot向量。
利用t步之前生成的word通过ELM生成D维的soft targets: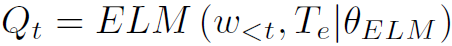
然后以 和
和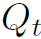 之间的KL散度为loss,让接近:
之间的KL散度为loss,让接近: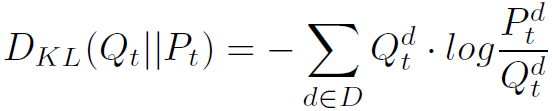
为了减小当中的噪声对模型的影响,只筛选top k个soft target: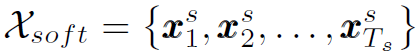 ,其中
,其中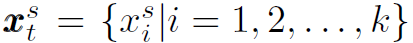 为第t步top k个soft word,其是D维的向量。
为第t步top k个soft word,其是D维的向量。
对KL散度进行简化: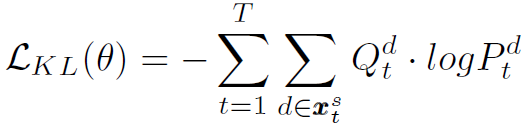
以上式作为辅助的loss函数与原始loss结合并加权: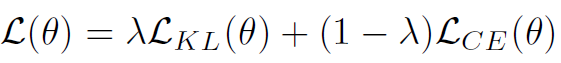
以上就是TRL模块的原理,总体来讲就是利用ELM当teacher对模型进行soft监督,和T-S learning思路有点像,但解决的问题不同。
Experiments
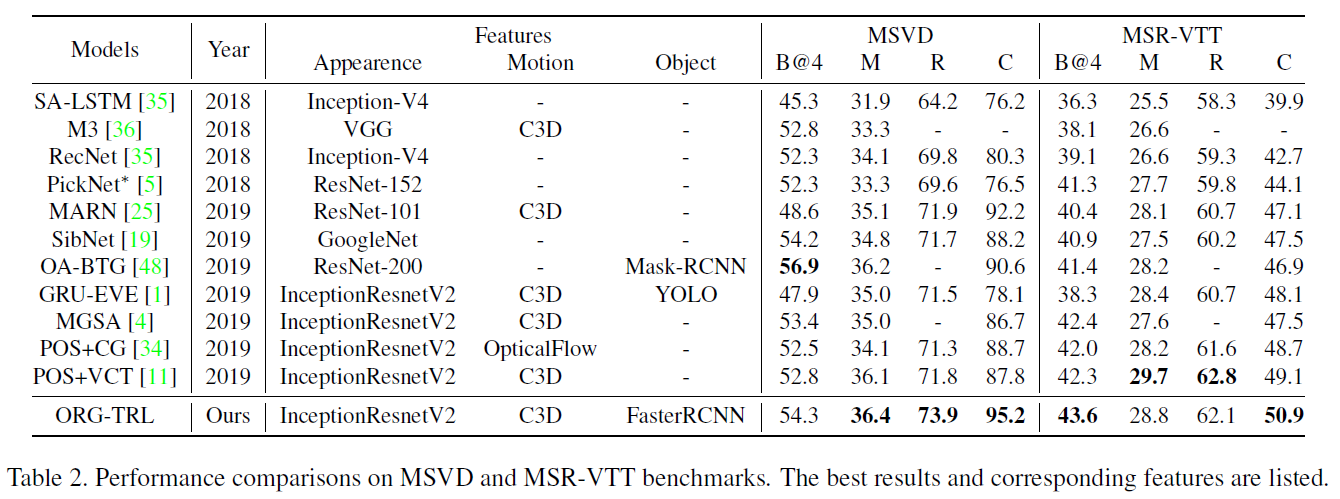
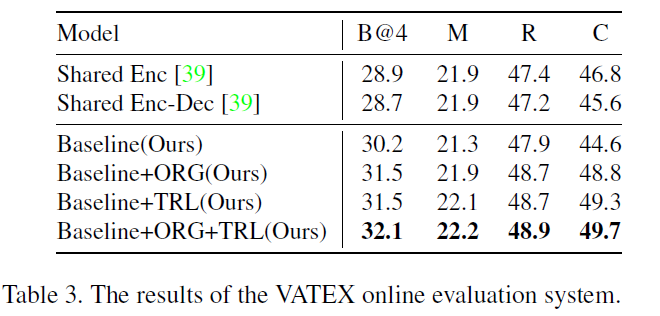

总结
本文P-ORG和C-ORG的设计以及attention的设计可以应用在其他Video Relational Reasoning任务中。TRL模块的想法也是非常巧妙。

若有收获,就点个赞吧
0 人点赞
