CVPR 2020 论文标题:Discovering Human Interactions with Novel Objects via Zero-Shot Learning 论文地址:https://cse.buffalo.edu/~jsyuan/papers/2020/05225.pdf 代码地址:https://github.com/scwangdyd/zero_shot_hoi (未发布)

简介
针对HOI detection任务,本文并没有从交互特征提取与动作分类模块入手,而是从Region Proposal模块入手提出了适用于HOI检测的HO-RPN网络,并在目标分类中引入了外部word embedding来实现Zero-Shot Learning。本文的Zero-Shot Learning是针对交互目标的,和AAAI 2020这篇文章中的Zero-Shot Learning并不相同。本质上,本文的贡献点是提出了一种适用于HOI任务的,具有Zero-Shot Learning能力的目标检测框架。
Human-Object Region Proposal Network
传统的HOI检测模型都以现有的目标检测网络为基础,首先检测图像中所有的人体和物体,再组成人物对进行交互分类。这样会造成图像中有大量与人没有交互的物体也要参与交互分类,效率比较低。本文第一个创新点是在RPN阶段使用了human feature,来判断anchor box内的实体是否与human有交互,如果没有则不proposal,即在RPN阶段就过滤掉了与人无交互的物体。这个模块称为HO-RPN,结构如图2: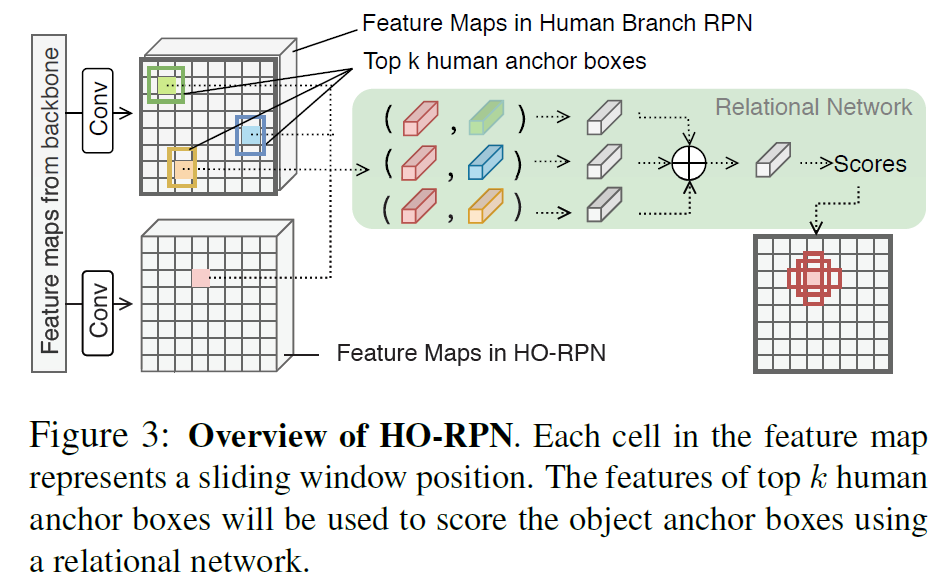
可以看到,HO-RPN并不是将人和物一起proposal,而是先推荐人体box,然后将anchor box内的特征与人体特征concat,最后计算一个score来判断这个anchor box中有无与人体交互的物体,从而给出物体proposal。这个过程公式表达如下: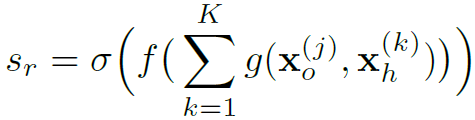
其中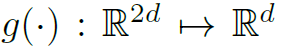 为一个MLP。
为一个MLP。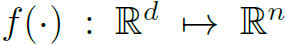 也是一个MLP,n为一个anchor所表示的不同形状的box的个数。
也是一个MLP,n为一个anchor所表示的不同形状的box的个数。
Zero-Shot Object Classification
本文第二个创新点是在目标分类的过程中引入外部word embedding来对图像中未知的object进行分类,整个过程如图4: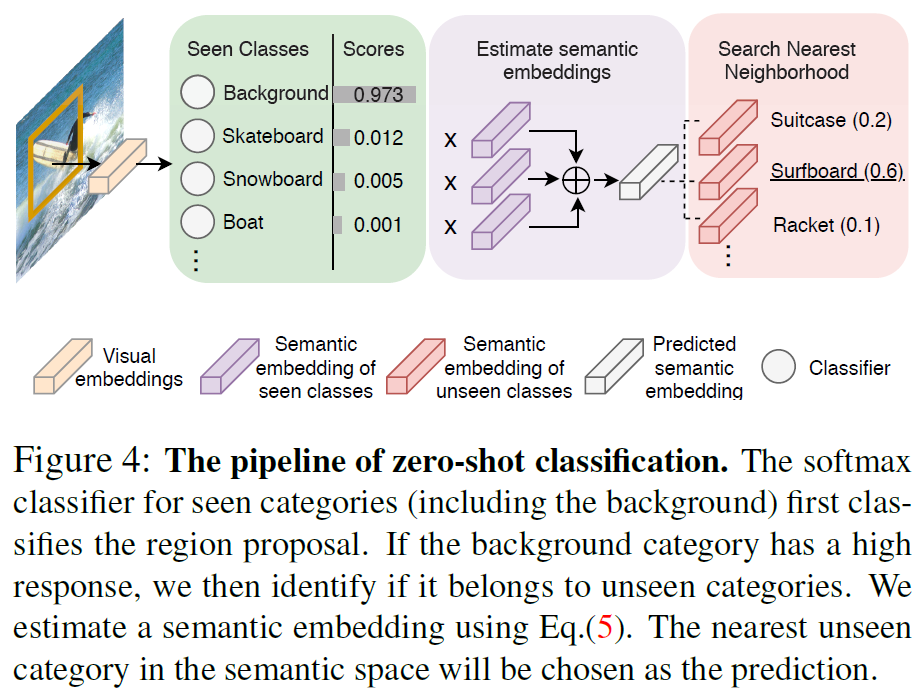
首先利用视觉feature进行softmax分类,如果其分类结果为background,则需要进一步判断是否是unseen的物体类别。选择softmax中除了background以外的前K种类别,将其word embedding以softmax结果为权加合起来作为其embedding向量,与外部知识库中的embedding比较相似度,从而得到unseen类别的分类结果。公式表达如下:
其中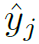 为softmax之后得分最高的第 j 个seen category。如果
为softmax之后得分最高的第 j 个seen category。如果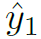 为background,则:
为background,则: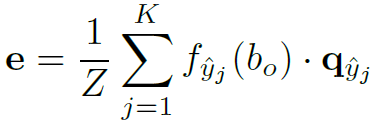
其中 表示除了background以外的其他K个seen category的word embedding。Z起到normalize的作用
表示除了background以外的其他K个seen category的word embedding。Z起到normalize的作用 。以
。以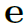 为待分类的对象的embedding,计算其与其他unseen category的相似度:
为待分类的对象的embedding,计算其与其他unseen category的相似度: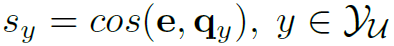
如果对于所有的unseen category ,有
,有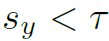 ,则这个目标分类为background,否则为相应的unseen category。最后,这个目标的得分为:
,则这个目标分类为background,否则为相应的unseen category。最后,这个目标的得分为: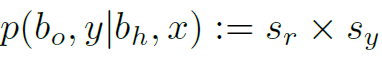
Verb Prediction
本文动作分类模块就是经典的三流卷积结构,只用proposal的视觉特征进行分类:
Experiments
实验做得非常完整,重点在于unseen category的识别能力: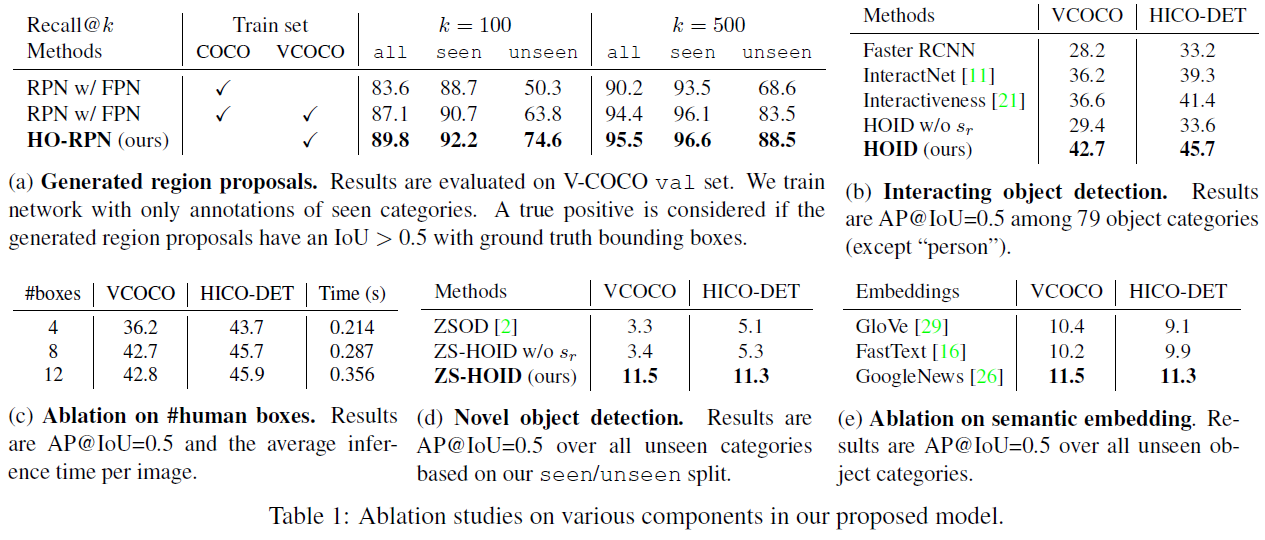

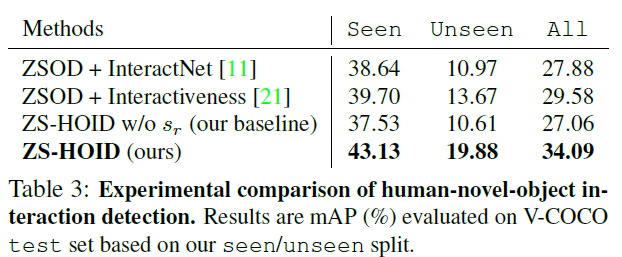

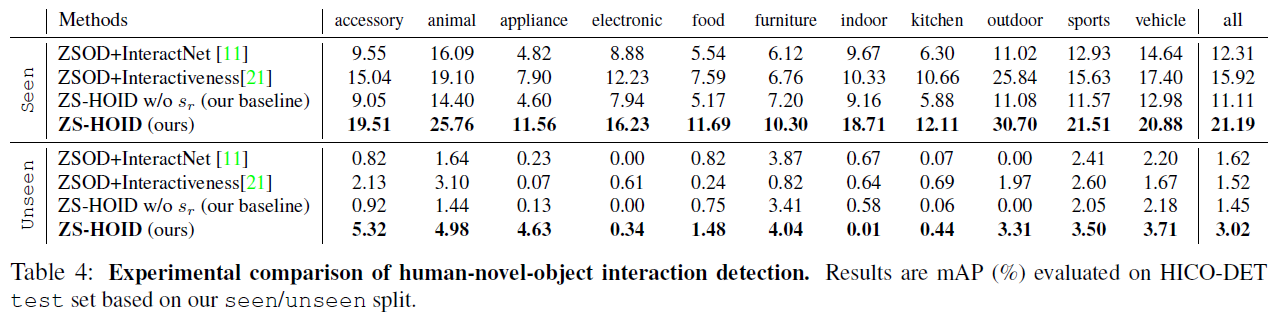
总结
本文本质上是将Zero-Shot的目标检测器整合进了HOI任务中,并将人物之间interactiveness的分类在RPN阶段就完成了,从而减少了与交互无关的object proposal,同时能识别数据集中unseen的object。

若有收获,就点个赞吧
0 人点赞
