ICCV 2019 论文标题:Pose-aware Multi-level Feature Network for Human Object Interaction Detection 论文地址:https://arxiv.org/abs/1909.08453 代码地址:https://github.com/bobwan1995/PMFNet

简介
针对human-object interaction (HOI) detection任务,本文提出了一种Pose-aware Multi-level Feature Network (PMFNet)。该模型从多尺度的语义信息入手,结合了human pose,构造出multi-branch deep network检测人物交互。其优势在于考虑了全局的global configuration同时,生成attention兼顾局部语义线索。多尺度的特征对于识别易混淆的HOI起到重要作用(如图1),attention也能让网络聚焦于HOI的重要局部语义区域并且可以实现可视化。在数据集V-COCO和HICO-DET上,PMFNet的表现均优于现有SOTA模型。
Pose-aware Multi-level Feature Network
对于一幅图像I,HOI detection任务的目标是对于I中的所有HOI instances,检测出四元组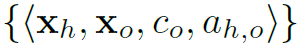 。其中
。其中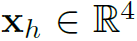 表示human location,
表示human location,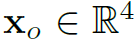 表示object location,
表示object location,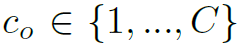 表示object category,
表示object category,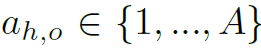 表示action category。最终HOI score用以下公式求出:
表示action category。最终HOI score用以下公式求出: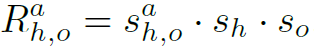
其中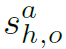 是interaction score,
是interaction score,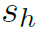 和
和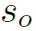 分别是human和object的score。
分别是human和object的score。
在一般的HOI detection模型中,和均由目标检测网络得到,如Faster R-CNN。所以要解决的主要问题就是。另外,PMFNet中用到了human pose信息,表示为一系列的关键点: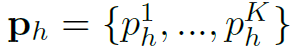 ,
,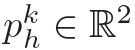 。作者用CVPR2018 CPN网络检测human pose。综上,作者给出了PMFNet的抽象公式表达:
。作者用CVPR2018 CPN网络检测human pose。综上,作者给出了PMFNet的抽象公式表达: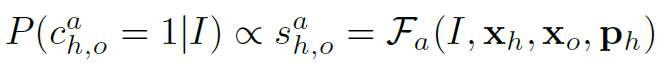
PMFNet分为四个模块:backbone module、holistic module、zoom-in module和fusion module,图2是网络的整体结构: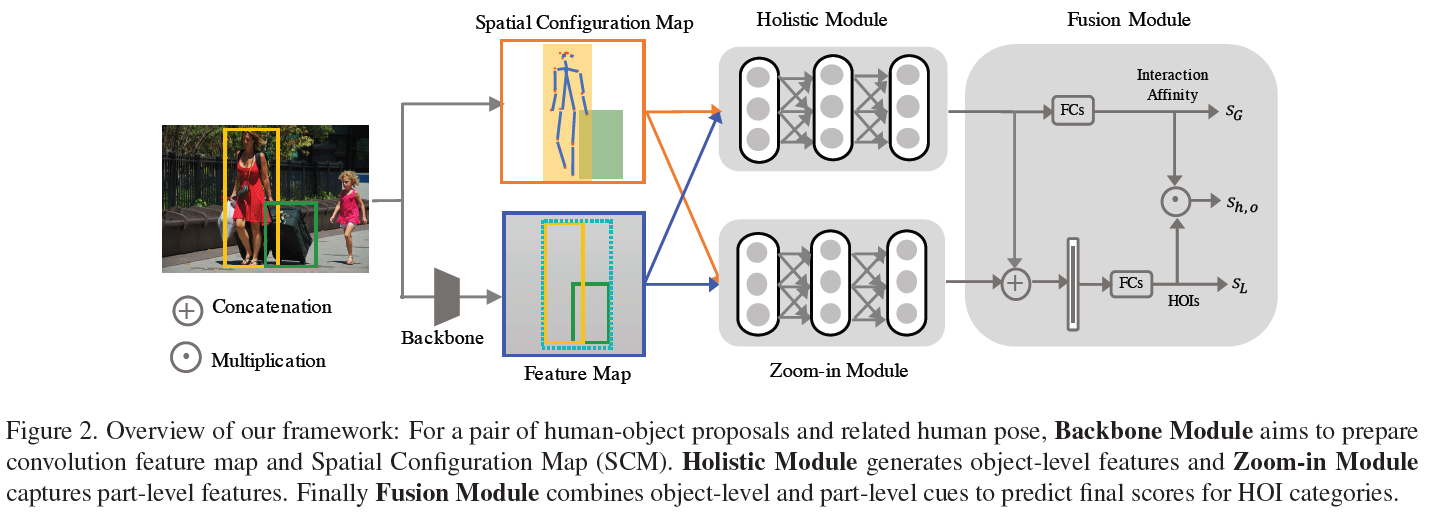
Backbone Module
首先,一幅图像中可能存在多个human,一个human也可能和多个object交互。作者先利用Faster R-CNN检测出所有的human和object,然后将其两两组合生成HOI proposal,作为PMFNet的输入。也就是说,PMFNet每次处理的都是一个human-object proposal,尽管其之间可能不存在interaction。
对于输入网络的一个human-object proposal和human pose,先生成其Spatial Configuration Map (SPM)。其中human和object的SPM就是其二值化的mask。human pose的SPM是将关键点用width=3的像素点栅格化,用[0.05, 0.95]的值表示不同的关键点而得到的一个mask。将以上三个mask缩放到相同的M*M size (M=64),在channel wise叠加起来,生成3 channel的Spatial Configuration Map。Feature Map是用ResNet-50-FPN backbone生成的图像feature map。
Holistic Module
图3左展示了Holistic Module的细节: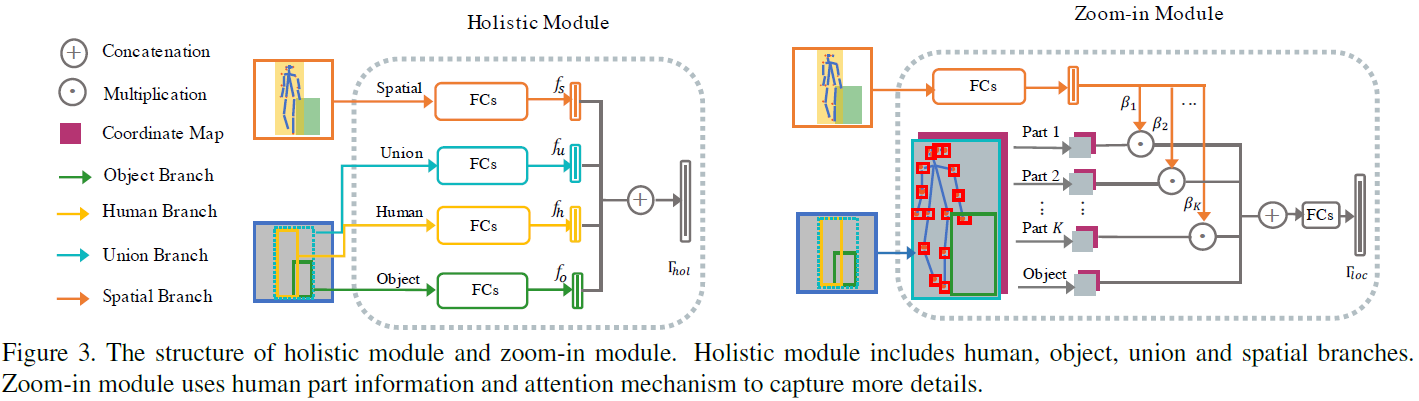
这个模块首先利用RoI-Align操作将human、object和union的feature map统一成 resolution。然后用不共享的全连接层(2层),针对human、object、union。spatial生成四个feature向量:
resolution。然后用不共享的全连接层(2层),针对human、object、union。spatial生成四个feature向量: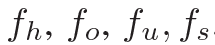 。再将四个feature向量concat起来,作为holistic feature:
。再将四个feature向量concat起来,作为holistic feature: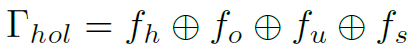
holistic feature主要包含了object-level的语义特征,是一种大尺度的feature。
Zoom-in Module
这个模块是PMFNet的亮点所在,用于提取细粒度part-level的语义特征。图3右展示了Zoom-in Module的结构,其又包含了三个步骤:Part-crop component、Spatial align component和Semantic attention component。我们一次介绍:
Part-crop component用于生成细粒度的feature map。首先对于给定的human pose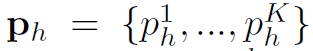 ,用一个比例系数
,用一个比例系数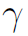 生成一系列local region
生成一系列local region 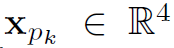 。
。 的中心点就是human pose的关键点,width和height由确定。是local region相对于整个human proposal的比例,文中取0.1。然后利用RoI-Align将这些local region和object proposal,统一成
的中心点就是human pose的关键点,width和height由确定。是local region相对于整个human proposal的比例,文中取0.1。然后利用RoI-Align将这些local region和object proposal,统一成 的feature map。最终得到了K+1个
的feature map。最终得到了K+1个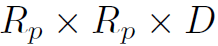 维的local feature map:
维的local feature map: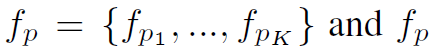 。
。
Spatial align component用于编码object和human parts之间的位置关系,因为二者的位置关系很大程度上决定了action的类别。例如object在human的手附近,那么这个action很可能是hold,而不太可能是kick。具体方法是首先生成2 channel的coordinate map 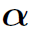 ,分别表示不同位置对于object中心位置的x,y偏移量。的size和图像的feature map是一样的。然后利用RoI-Align得到每一个human part和object的spatial map。最后将spatial map和对应的local feature map进行concat,得到
,分别表示不同位置对于object中心位置的x,y偏移量。的size和图像的feature map是一样的。然后利用RoI-Align得到每一个human part和object的spatial map。最后将spatial map和对应的local feature map进行concat,得到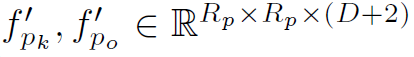 :
: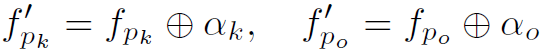
Semantic attention component用于生成K+1个local feature的attention,因为不同HOI往往有不同的关键语义区域,例如看书的关键区域是人的眼睛。作者用Spatial Configuration Map生成attention map。具体方法是利用两个全连接层,第一层Relu激活,第二次sigmoid激活,生成K个attention权重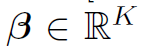 。为什么是K个不是K+1个,因为对于object feature,其attention始终是1。最后用以下公式计算Zoom-in Module输出的feature:
。为什么是K个不是K+1个,因为对于object feature,其attention始终是1。最后用以下公式计算Zoom-in Module输出的feature: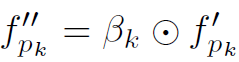
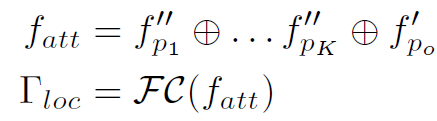
至此,我们得到了两个feature: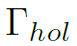 和
和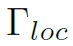 ,分别对应大尺度和小尺度,实现了多尺度的特征提取。
,分别对应大尺度和小尺度,实现了多尺度的特征提取。
Fusion Module
这个模块用于得到HOI detection的结果,也就是。首先利用确定该human-object proposal之间是否存在interaction: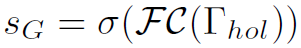
然后将和 concat起来,对不同action确定其action score: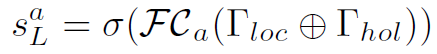
最后将二者相乘得到interaction score: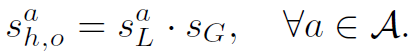
对于输入网络的一个human-object proposal,每一个action a都会得到一个interaction score。
Loss Function
在模型训练时,作者使用sigmoid cross entropy作为loss function: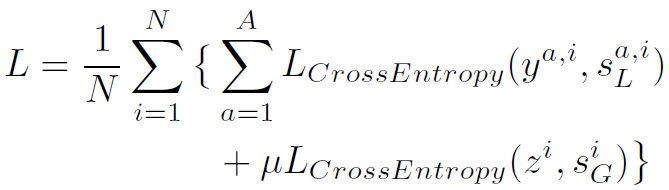
其中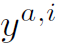 为对于proposal i,action a的one hot标签。
为对于proposal i,action a的one hot标签。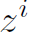 为对于proposal i,是否存在interaction的标签。
为对于proposal i,是否存在interaction的标签。
Experiments
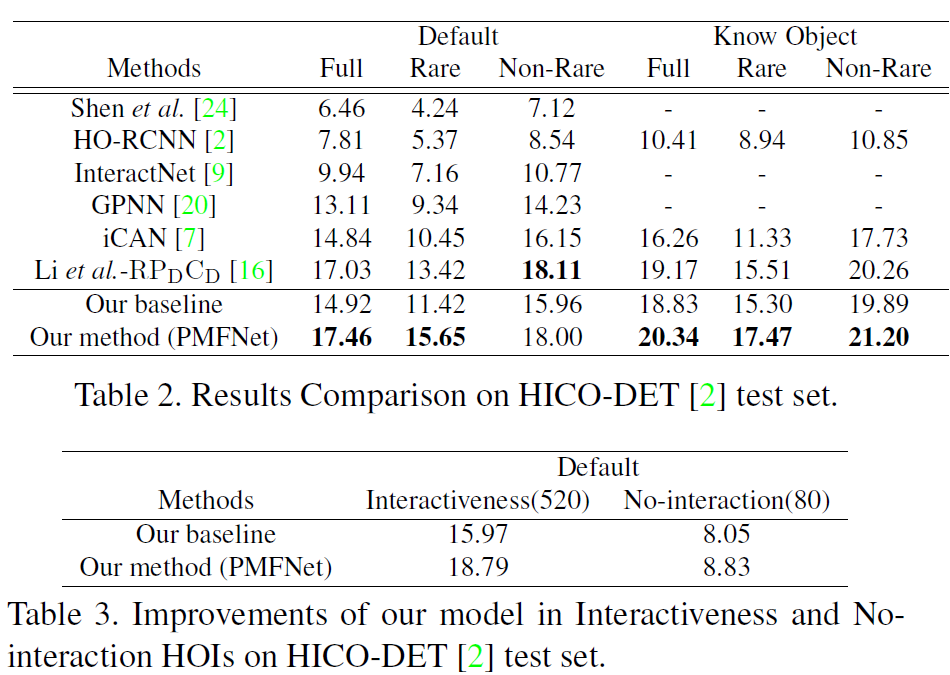
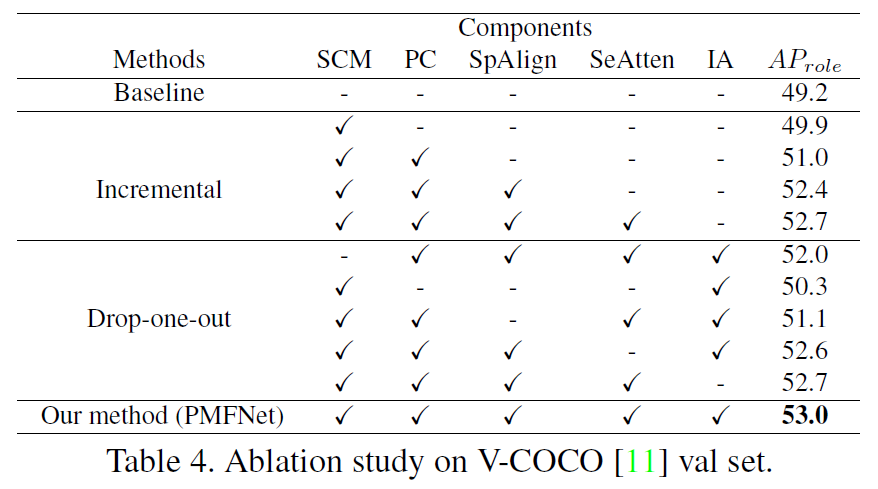
作者在V-COCO和HICO-DET数据集上测试了PMFNet: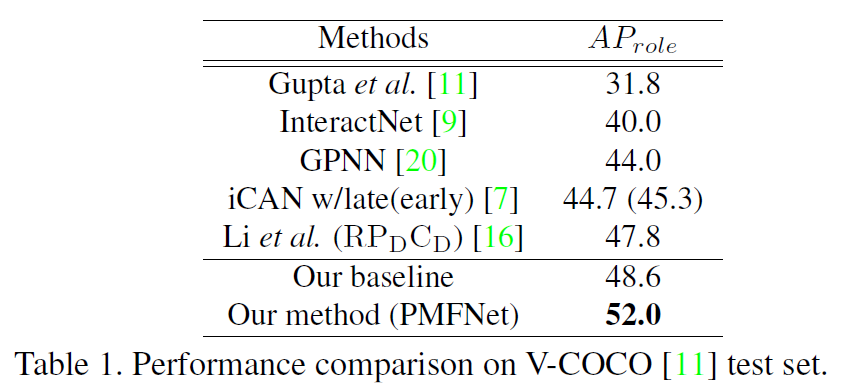


总结
Zoom-in Module是亮点,考虑了细粒度的语义特征和空间位置关系,对HOI detection非常有用。但这种CNN based网络有个缺点就是要对每一个human-object pair都检测一遍HOI,而必然有大量的proposal pair是不存在interaction的,效率还是比较低。

若有收获,就点个赞吧
0 人点赞
