ECCV 2018 论文标题:Compositional Learning for Human Object Interaction 论文地址:http://openaccess.thecvf.com/content_ECCV_2018/papers/

简介
本文针对HOI任务,提出了一种compositional learning方法,以实现zero-shot learning的目的。本文的motivation在于HOI任务中的action-object的组合是丰富多样的,而训练数据集有限,无法覆盖全部的action-object组合。例如数据集中包含“坐在沙发上”、“看电视”,但不太可能有“坐在电视上”,然而“坐在电视上”并不是不可能的组合,如图1。
对于这种网络没有见过的action-object组合,甚至网络没有见过的action和object,如何正确识别?作者提出了利用外部先验知识构造知识图,通过GCN学习潜在的action-object组合,从而实现zero-shot learning,让网络自动推理丰富多样的action-object组合。最后,作者设计了巧妙的实验,在HICO、Visual Genome 、Charades等数据集上验证了本文compositional learning方法的有效性。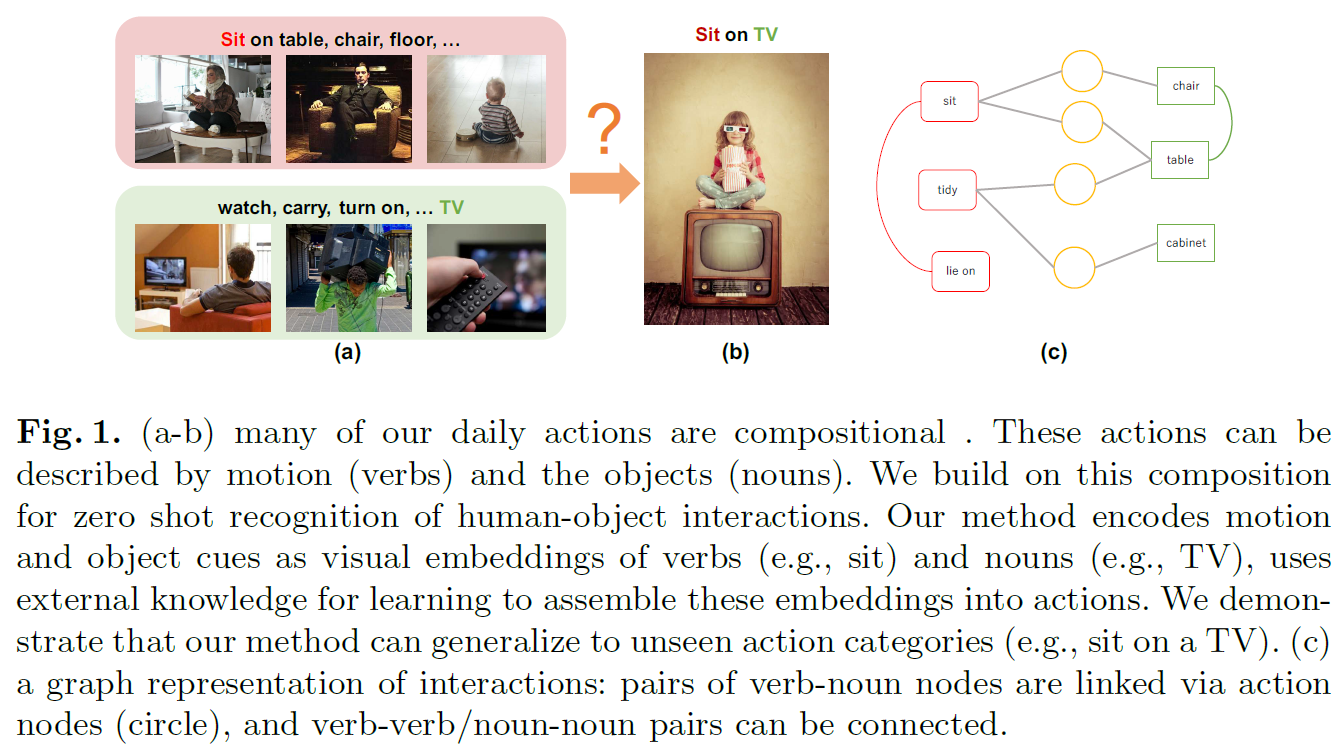
Compositional Learning
compositional learning是本文中贯穿全文的关键词,那么如何理解这个词,也就是理解本文思想的关键。以下是我的个人看法,如有错误,请不吝指教。
compositional learning包含两个层面:
1.网络的整体结构是compositional的。本文提出的网络结构由Knowledge Graph和ConvNet两部分组成。其中ConvNet仅用于从图像或视频中提取feature,是一个常见的CNN backbone。Knowledge Graph是本文的核心内容,其结合了NLP的word embedding,对HOI的先验知识建模,后文会详细介绍。
2.对HOI的识别是compositional的。本文将interaction分为action+object,也就是verb+noun。verbs和nouns的不同组合构成了多样的HOI。文中用Knowledge Graph表示verbs和nouns之间的联系,或verbs内部和nouns内部的联系,这也是实现zero-shot learning的基础。换句话说,网络对于zero-shot HOI的推理都是基于Knowledge Graph的,虽然网络在训练过程中没有见过“坐在电视上”的图像,但“坐+电视”这个概念是可以在Knowledge Graph上推理出来的。
Network Architecture
作者用以下公式(score function)抽象表示整个网络的结构: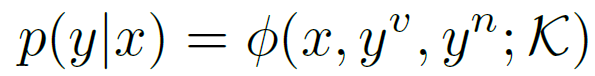
其中y表示HOI,x表示图像或视频的feature。 分别表示构成HOI的verb和noun。
分别表示构成HOI的verb和noun。 表示先验知识。本文的key idea就是利用Graph对建模
表示先验知识。本文的key idea就是利用Graph对建模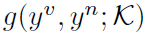 ,然后利用GCN从上聚合信息,生成各种HOI的representation,用
,然后利用GCN从上聚合信息,生成各种HOI的representation,用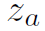 表示。最后将
表示。最后将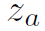 与
与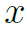 比较,从而找到
比较,从而找到 对应的HOI,也就是图像或视频对应的HOI。下面结合图示加以解释。
对应的HOI,也就是图像或视频对应的HOI。下面结合图示加以解释。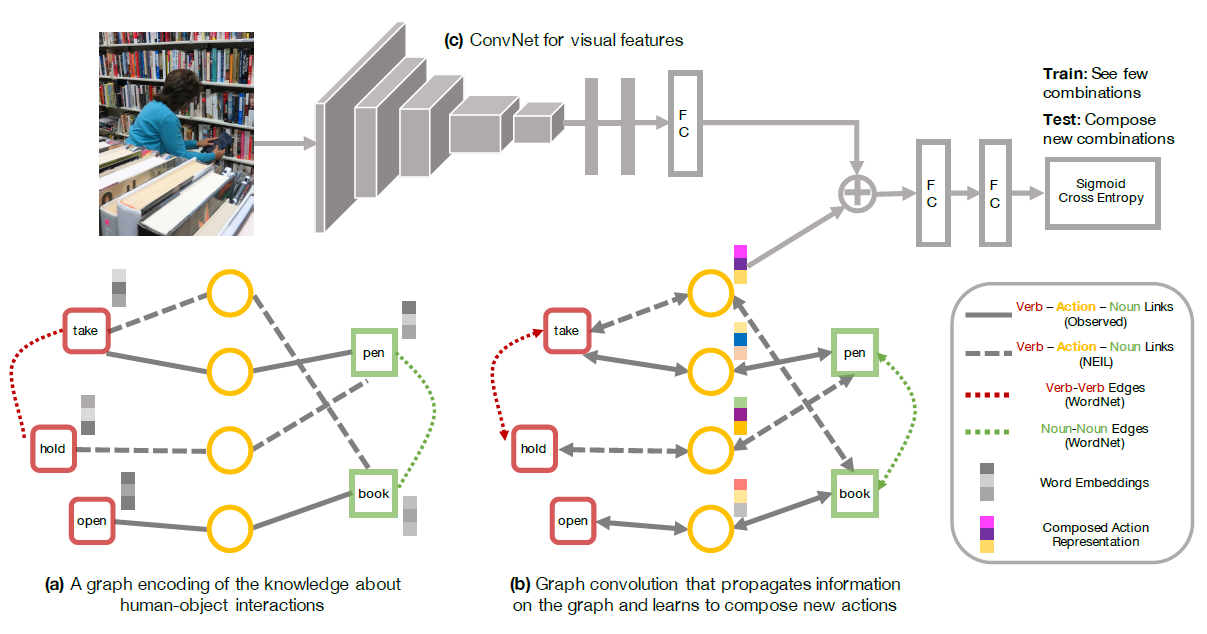
上图清晰展示了网络的整体结构,包括Knowledge Graph(下)和ConvNet(上)两部分。Knowledge Graph中红色框和绿色框分别表示verb和noun,他们的特征初始化为对应单词的word embedding。黄色圆圈表示HOI,特征初始化为0。每个黄色圆圈只与对应的一个verb和一个noun相连。但verb(红)和noun(绿)除了与HOI(黄)相连之外,自身内部也存在联系,这部分参考论文WordNet。Knowledge Graph构成的GCN只有两层,在第二层中,HOI(黄)结点聚合了相邻verb和noun的信息,所以能够表示HOI的feature,也就是公式中的。
ConvNet就是普通的CNN结构用于提取图像或视频的feature,也就是公式中的,本文实验中分别用ResNet152和I3D Network。提取出的feature与GCN生成的HOI feature经过concat,再进入一个MLP结构,输出一个[0, 1]之间的score,表示两者的相似程度。取相似程度最高的HOI作为这个图像或视频所表示的HOI。
可以看到,这个网络的功能其实是将图像或视频的feature映射到与word embedding相同的语义空间中,从而让二者具有可比性。通过计算广义的距离,完成图像/视频和先验HOI的匹配,属于一项CV和NLP的交叉研究。文中用到许多NLP领域的典型方法,需要进一步阅读参考文献才能读懂。
下面来看另一个需要重点关注的内容:GCN的邻接矩阵如何表示以及如何聚合和更新node feature。
本文使用的GCN结构是非常标准且有严格数学证明的,并不像CV领域的其他GCN那样花里胡哨。Knowledge Graph的邻接矩阵表示如下: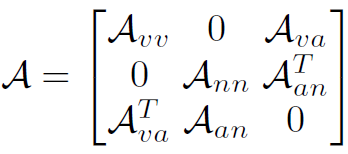
其中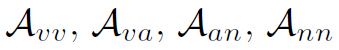 分别表示verb-verb、verb-action、action-noun、noun-noun的邻接矩阵(action即HOI)。这里的所谓邻接矩阵是真邻接矩阵,也就是连通为1,不连通处0,不带权重。
分别表示verb-verb、verb-action、action-noun、noun-noun的邻接矩阵(action即HOI)。这里的所谓邻接矩阵是真邻接矩阵,也就是连通为1,不连通处0,不带权重。
Knowledge Graph中node的初始特征表示如下: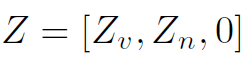
其中 分别是verb和noun的word embedding,0表示action node的初始特征。
分别是verb和noun的word embedding,0表示action node的初始特征。
对邻接矩阵标准化,我们得到: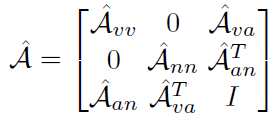
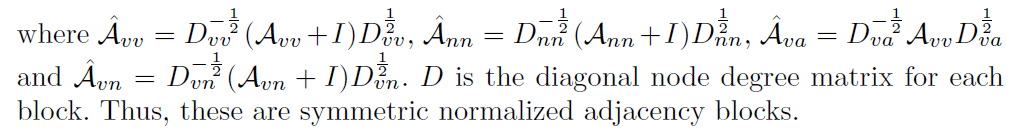
GCN的更新规则为: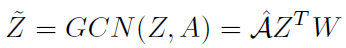
其中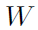 是learnable的权重,维度为
是learnable的权重,维度为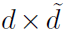 。
。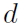 是输入特征的维度,
是输入特征的维度,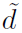 是输出特征的维度。这个公式中作者没有将非线性激活relu表示出来,其实GCN两层之间是有relu激活的。
是输出特征的维度。这个公式中作者没有将非线性激活relu表示出来,其实GCN两层之间是有relu激活的。
为了简化计算,同时减小参数量,作者使用了共享权值: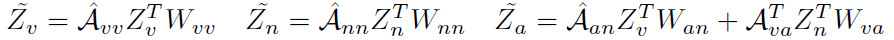
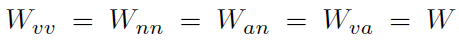
这里我们重点关注一下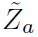 ,因为它是我们最终需要的HOI的特征,用于和比较。
,因为它是我们最终需要的HOI的特征,用于和比较。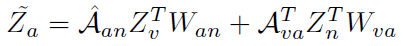 ,从这个公式中我们也可以看出,聚合了verb和noun的word embedding。如果GCN有k层,那么将聚合k阶的verb和noun,但是本文的GCN只有两层。
,从这个公式中我们也可以看出,聚合了verb和noun的word embedding。如果GCN有k层,那么将聚合k阶的verb和noun,但是本文的GCN只有两层。
得到了之后,我们将它与x进行比较:
其中 用于将x的维度转换到与一致,
用于将x的维度转换到与一致,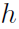 是一个两层的MLP,最后用sigmoid激活,输出一个[0, 1]的score。
是一个两层的MLP,最后用sigmoid激活,输出一个[0, 1]的score。
以上就是本文中GCN的详细设计,这是一个非常经典的GCN结构,有着严格的数学基础与不错的实际表现,同时也具有进一步改进的潜力。
最后重申一下,文中邻接矩阵的构造和node feature的初始化用到了很多NLP领域的知识,我不全了解,具体的实现细节还得去阅读相关的参考文献。
Train
作者对于loss函数的设计和网络的训练过程描述的内容很少。只是说对于图像的ResNet,在ImageNet上预训练。对于视频的I3D Network,在kinetics上预训练。然后CNN部分的参数就被固定了,再利用HOI相关的数据集单独训练GCN部分。使用的loss函数是logistic loss,使用的优化器是minibatch SGD。另外,为了保持minibatch内正负样本平衡,将其比例控制在1:3。
Experiments
Experiments的内容好多,不详细写了。总结一下就是作者为了验证zero-shot learning,设计了很多实验方法。例如将数据集的verb和noun按类别进行划分,只用一部分训练网络。从而验证网络对于unseen HOI的识别能力。实验部分也详细说了如何构造Knowledge Graph。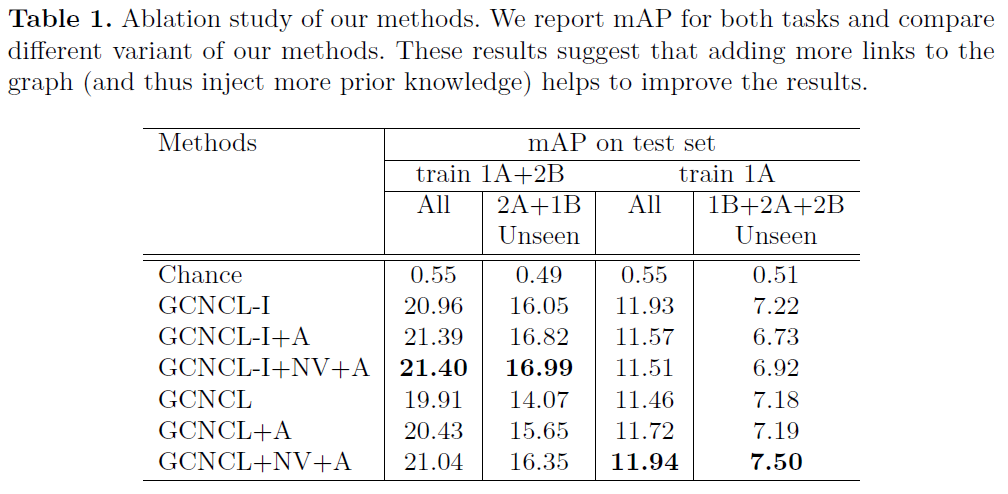
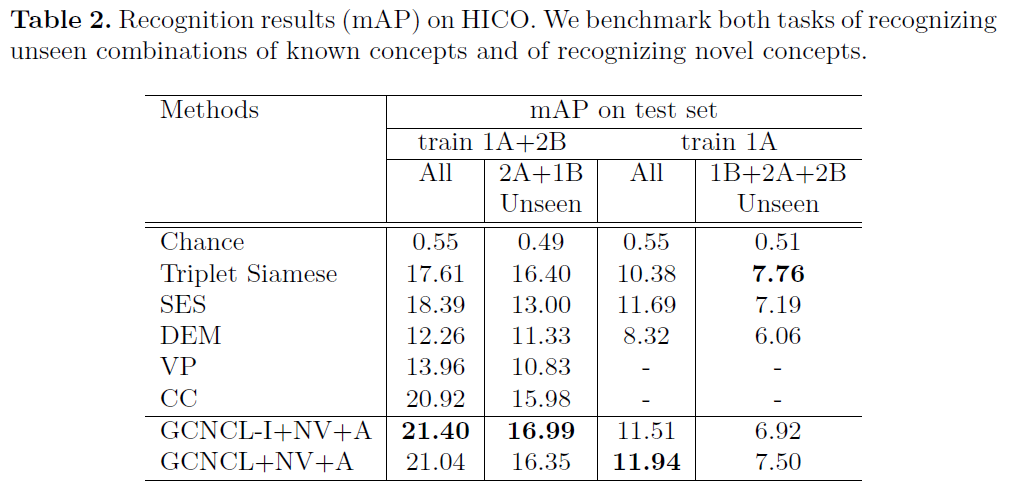
总结
本文是一个很好的CV与NLP相结合的例子,作者所谓的zero-shot,其实是将CV的问题转移到了NLP中,美其名曰external knowledge。换句话说,虽然网络在训练过程中对于很多HOI是unseen的,但这些知识早已被储存在了Knowledge Graph中,通过GCN在Graph上聚合信息,就可以推理出网络训练时没有见过的verb-noun组合。
最后有一个疑问:本文GCN在更新过程中,verb node和noun node的feature也是聚合更新了的,其聚合了与自身有联系的node的信息(邻接矩阵的verb-verb和noun-noun连接)。但该GCN只有2 layers,更新后的verb node和noun node并没有被后续操作用到,计算这个更新有什么作用?

若有收获,就点个赞吧
0 人点赞
