CVPR 2019 论文标题:Learning to Detect Human-Object Interactions with Knowledge 论文地址:http://openaccess.thecvf.com/content_CVPR_2019/papers/ 代码地址:https://bitbucket.org/freezingmolly/hoi_graph

简介
目前的HOI数据集都存在长尾分布 (long-tail distribution) 的问题,即某些HOI类别仅有少量的训练样本,使得网络难以训练。本文基于HOI数据集的annotation和外部视觉关系数据集构建了先验的knowledge graph,对verbs和objects的语义关系进行建模,以缓解长尾分布问题。换句话说,本文利用先验的word embedding来辅助网络学习到更好的HOI语义特征embedding space。在这个embedding space中,相似的verbs会聚集在一起,由此提高对rare categories的分类能力。作者在V-COCO和HICO-DET数据集上做了实验,效果都有所提升,特别是对于rare categories。
Method
模型的整体结构还是继承自经典的iCAN,在Faster R-CNN目标检测的基础上分为三个stream,作者的改进主要在pairwise stream:
从图3中可以看到,pairwise stream的目标并没有变,依旧是利用human和object融合的feature,输出各类action的score。但这里加入了作者设计的knowledge graph,其作用是使human和object的visual representation space尽可能地靠近先验的word embedding space,同时利用GCN也使knowledge graph的word embedding space靠近human和object的visual representation space。换句话说,作者是想在word embedding space和visual representation space之间找到一个中间的feature sapce。这个feature sapce可以同时表达verbs的语义相关特征和视觉appearance特征。pairwise stream主要由三个部分组成,如图2:Graph Modeling for HOIs、Visual Representations和MultiModal Joint Embedding,下面分别介绍。
Graph Modeling for HOIs
这个部分就是本文的knowledge graph,定义为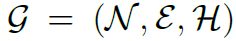 ,其中
,其中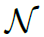 表示nodes,
表示nodes,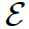 表示edges,
表示edges,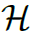 表示node features。knowledge graph中的nodes表示HOI任务中所有可能出现的verbs和objects,其初始的feature是由GloVe model得到的word embedding。knowledge graph中的edges表示
表示node features。knowledge graph中的nodes表示HOI任务中所有可能出现的verbs和objects,其初始的feature是由GloVe model得到的word embedding。knowledge graph中的edges表示
作者利用标准的GCN实现graph上特征的聚合更新,公式如下: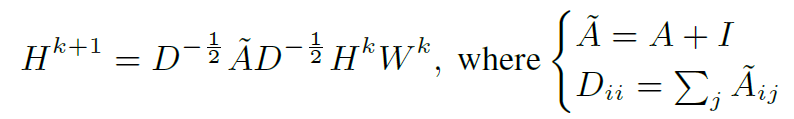
其中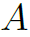 是邻接矩阵,
是邻接矩阵,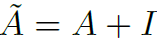 表示添加结点自环。
表示添加结点自环。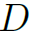 是结点度矩阵,
是结点度矩阵,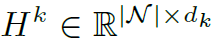 是结点的feature,
是结点的feature,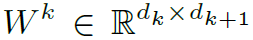 是可训练的参数。在GCN的layer之间,用Relu激活。
是可训练的参数。在GCN的layer之间,用Relu激活。
以上就是knowledge graph的构造。最后作者提到对于V-COCO数据集,graph一共有226个node。对于HICO-DET数据集,有313个node。并且graph的edge数量都没有超过193。因此GCN的计算量是在可接受的范围内的。
Visual Representations
这个部分的作用是提取human和object的appearance特征,具体方法可参照图2。首先利用ROI Pooling+Res5提取human和object的visual特征,再利用以下公式表达human和object的spatial configuration特征:
然后作者用了element-wise subtraction操作对human和object的特征进行融合(第一次见到用减法的)。分别得到spatial config.和visual的pairwise representation: 和
和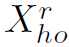 。最后将它们concat起来,经过全连接层,得到512维的特征向量:
。最后将它们concat起来,经过全连接层,得到512维的特征向量: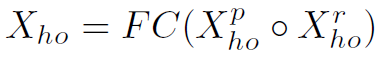
MultiModal Joint Embedding
本文的关键在于MultiModal Joint Embedding部分,这里体现了作者的初衷:找到一个折中的feature space同时表达语义关系和视觉特征。也就是说,作者想让语义上相似的verb的feature不仅能通过分类器得到正确的action score分类结果,同时在feature space中的距离也是相近的。MultiModal Joint Embedding部分实际上是定义了三个loss函数,以训练网络达到上述目的。
Similarity Loss
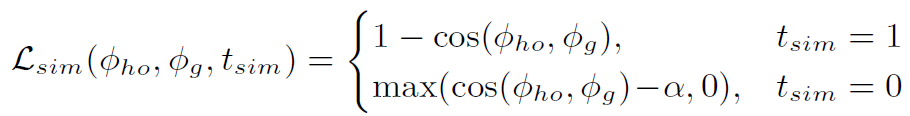
Similarity Loss用于衡量knowledge graph的node feature和visual representation之间的距离。其中当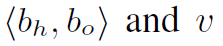 在ground truth中存在时,
在ground truth中存在时, 为1,否则为0。这个loss函数的目的就是让相同verb的node feature和visual representation在feature space中的距离相近,且不同verb保持一定的距离,从而增强visual representation表达verb语义特征的能力。因为node feature是用word embedding初始化的,先天具有语义特征:相似的verb往往在embedding space中聚集在一起。而visual representation是从图像中提取出的,不具有这种先天特性。因此,让相同verb的visual representation和node feature距离相近,也就间接让相似verb的visual representation距离相近,这也就是作者的初衷。同时node features也因GCN的存在而跟随网络在训练过程中一起调整,以适应visual representation。当网络训练完成后,在做inference的时候,是不用通过GCN的,直接用训练得到的node features就可以了。
为1,否则为0。这个loss函数的目的就是让相同verb的node feature和visual representation在feature space中的距离相近,且不同verb保持一定的距离,从而增强visual representation表达verb语义特征的能力。因为node feature是用word embedding初始化的,先天具有语义特征:相似的verb往往在embedding space中聚集在一起。而visual representation是从图像中提取出的,不具有这种先天特性。因此,让相同verb的visual representation和node feature距离相近,也就间接让相似verb的visual representation距离相近,这也就是作者的初衷。同时node features也因GCN的存在而跟随网络在训练过程中一起调整,以适应visual representation。当网络训练完成后,在做inference的时候,是不用通过GCN的,直接用训练得到的node features就可以了。
Cross Entropy Regularization Loss
 就是pairwise stream的多标签二分类loss。
就是pairwise stream的多标签二分类loss。
Cross Entropy Loss
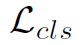 就是human stream和object stream的多标签二分类loss。
就是human stream和object stream的多标签二分类loss。
最后,整个网络的loss函数表示如下: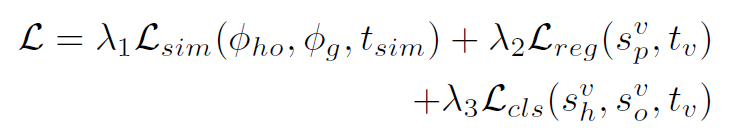
其中 λ 是超参数,作者在实验中分别取0.8,1,1。在网络inference时,pairwise stream的输出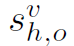 ,由
,由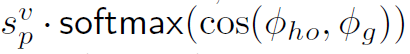 得到,最终的HOI score由以下公式得到:
得到,最终的HOI score由以下公式得到:
Experiments
作者在V-COCO和HICO-DET数据集上做了实验,本文模型在HICO-DET的rare categories中提升明显: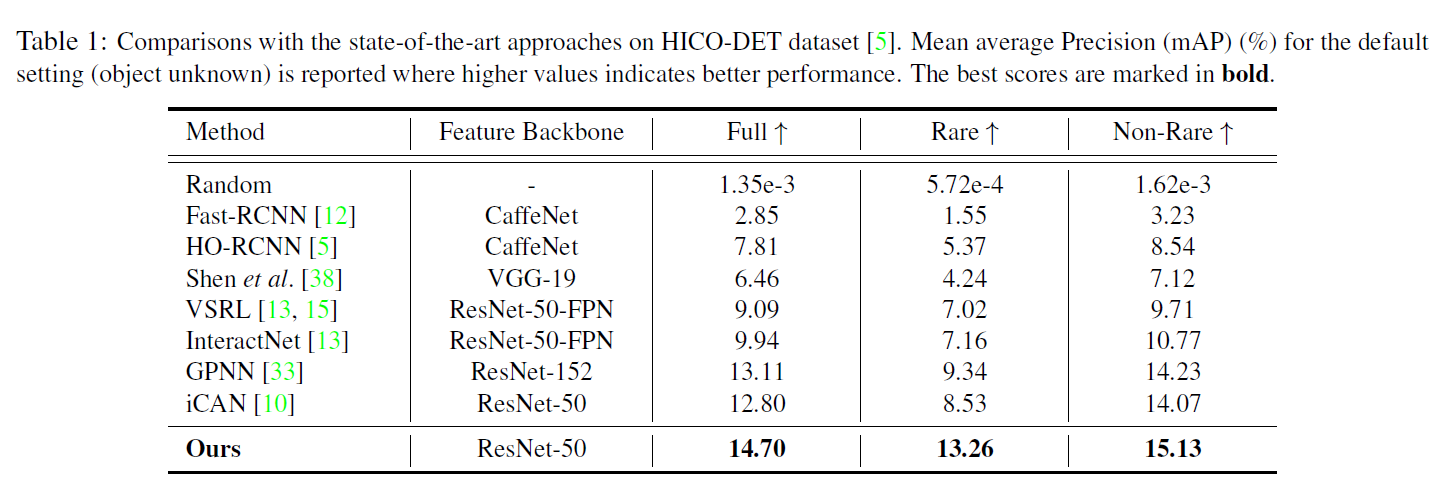
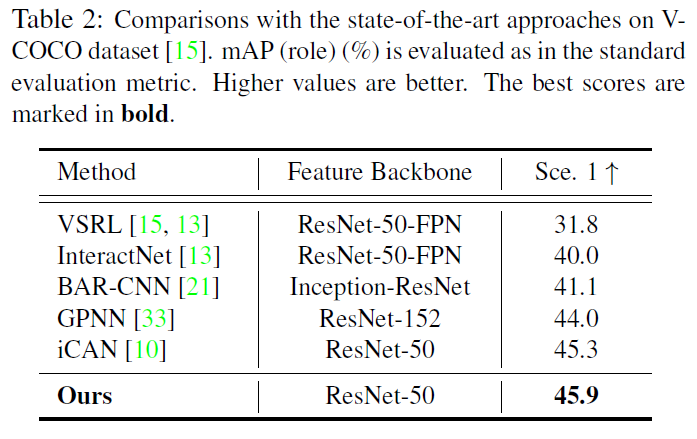
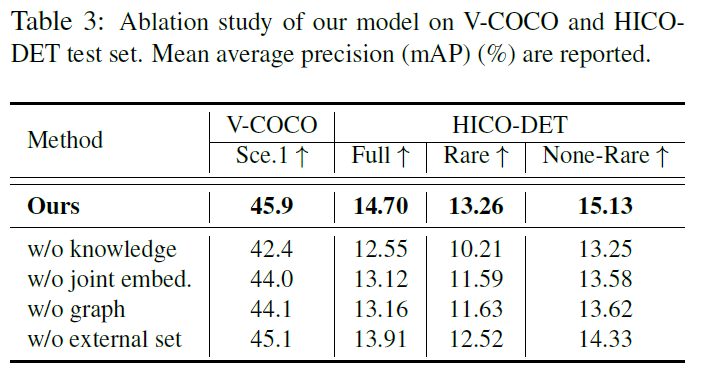

图6很有意思,展示了模型中GCN的作用。原本聚集在一起的brush with、drink with和cut with主要因为都包含with,但实际并不表示相似的verb。经过GCN的训练之后,网络对embedding space做了调整,使其更符合visual语义,如drink with和sip聚集在了一起。这样同时包含了word和visual语义的特征空间正是本文讨论的核心内容。
总结
long-tail distribution问题是HOI任务中真实存在的,也是在V-COCO和HICO-DET数据集下模型要面对的最大挑战,作者通过构建knowledge graph给出了一种不错的解决思路。结合ECCV 2018这篇文章来看,knowledge graph的潜力还不止于此,未来肯定还会有效果更好,更统一的模型。

若有收获,就点个赞吧
0 人点赞
