ECCV 2018 论文标题:Learning Human-Object Interactions by Graph Parsing Neural Networks 论文地址:https://arxiv.org/abs/1808.07962?context=cs.CV 代码地址:https://github.com/SiyuanQi/gpnn

简介
本文提出了一种解决图像或视频中human-object interactions (HOI)任务的深度模型,名为Graph Parsing Neural Networks (GPNN)。具体来讲,GPNN以Deformable Convolutional Network (论文地址) 为backbone,进行目标检测并提取目标feature。以改进的Graph Convolutional Network解析目标间的关系,提取HOI的Graph结构信息(邻接矩阵),并通过Graph上的message passing不断refine目标的feature,最终输出结果。在数据集HICO-DET、V-COCO、CAD-120上,该网络取得了SOTA的表现。
本文最大的亮点在于GCN的引入:将human和object视为Graph中的node,通过3层叠加的GPNN提取human与object之间的交互信息,以充分解析HOI任务中不同目标间的时空关系。
Graph Parsing Neural Networks (GPNN)
省略用于目标检测和特征提取的Deformable Convolutional Network,直接来看本文的核心框架GPNN。
GPNN中,一层layer(一个step)的计算过程包括四个函数:Link Function、Message Function、Update Function和Readout Function,以下依次分析。
Link Function
Link Function用于计算Graph的结构,也就是邻接矩阵。生成的邻接矩阵定义message在Graph上的传播方式与路径。实际上经典的GCN中,邻接矩阵是预先定义好的,作为网络的输入参数,邻接矩阵内的数值并不是trainable的。但在这里,邻接矩阵通过Link Function训练得到,可以视为对GCN的扩展,但其不再表示node间的连通情况,而是反应node间的信息传播规律。Link Function定义如下: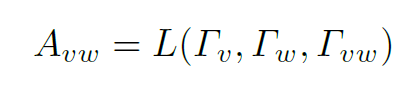
等号左边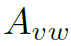 为结点v和w之间的权重,即邻接矩阵在下标vw处的数值。等号右边
为结点v和w之间的权重,即邻接矩阵在下标vw处的数值。等号右边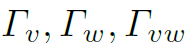 分别表示结点v和w的特征、vw之间边的特征。在第一个layer中,这些特征事先通过DCN提取获得。可以看到,L是以三个特征为参数的函数,通过结点各自的feature和结点间的feature,可以计算得到邻接矩阵。
分别表示结点v和w的特征、vw之间边的特征。在第一个layer中,这些特征事先通过DCN提取获得。可以看到,L是以三个特征为参数的函数,通过结点各自的feature和结点间的feature,可以计算得到邻接矩阵。
实际网络中,邻接矩阵的计算公式如下: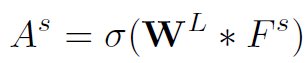
其中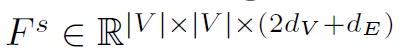 ,是将三个特征concat后的结果。
,是将三个特征concat后的结果。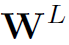 是可训练的权重。
是可训练的权重。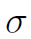 为sigmoid激活函数。
为sigmoid激活函数。 代表卷积操作。这里解释一下为什么是卷积操作:实际上这个卷积利用了11(2dv+de)的kernel实现了并行的全连接,每个全连接的input size是2dv+de。也就是说,最终得到的
代表卷积操作。这里解释一下为什么是卷积操作:实际上这个卷积利用了11(2dv+de)的kernel实现了并行的全连接,每个全连接的input size是2dv+de。也就是说,最终得到的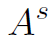 的维度为V*V,每一个值都是2dv+de个值全连接后的结果。经过sigmoid激活后,值都落在了(0,1)范围内,可以将这个Graph看作完全图。
的维度为V*V,每一个值都是2dv+de个值全连接后的结果。经过sigmoid激活后,值都落在了(0,1)范围内,可以将这个Graph看作完全图。
得到了邻接矩阵,我们就有了message在Graph上的传播规则。那么这个message如何得到?就需要引入Message Function了。
Message Function
Message Function用于计算Graph中每个node的message。这里对message和feature做一下区分:feature (第一层之后为h)是产生message的原始材料,message是feature聚合之后的结果,公式如下: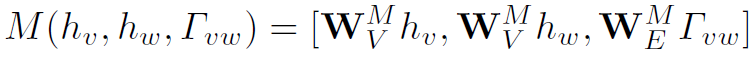
在第一层layer中,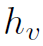 和
和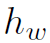 就是结点v和w的feature。之后的layer中,不再是原始的feature,而是更新之后的隐藏状态h(需要用到Update Function)。对于每一个feature,经过参数W实际上就是用全连接操作生成一个符合message size的结果。对于每个node,Message Function可以计算出与之对应的v(node个数)个message(每个message由和
就是结点v和w的feature。之后的layer中,不再是原始的feature,而是更新之后的隐藏状态h(需要用到Update Function)。对于每一个feature,经过参数W实际上就是用全连接操作生成一个符合message size的结果。对于每个node,Message Function可以计算出与之对应的v(node个数)个message(每个message由和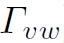 经过全连接操作得到),然后再将这些message用邻接矩阵加权求和,得到最终的对应于某一个node的message。每个node都会得到一个message。
经过全连接操作得到),然后再将这些message用邻接矩阵加权求和,得到最终的对应于某一个node的message。每个node都会得到一个message。
感觉论文中这个Message Function公式不是很清晰。原文中说[.,.]代表concatenation,这里我就对结果的维度产生疑惑。查看代码发现,代码中的Message Function有两种不同的实现,如果用concat,那么message size需要一个降维的操作,变为原来的1/2。也有用+实现的,此时message size不需要降维。
结合Link Function,我们就可以进行Graph中的message passing过程了,公式如下: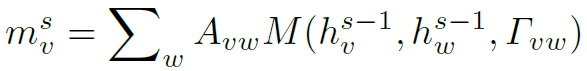
其中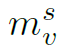 表示结点v在第s层中的message。在代码中,为了保持维度一致,会对邻接矩阵做一个expand操作。
表示结点v在第s层中的message。在代码中,为了保持维度一致,会对邻接矩阵做一个expand操作。
需要注意的是,Message Function中的参数:结点的特征,只有在第一层layer中用的是DCN提取出的feature。之后的层中,使用的都是Update后的feature,称为隐藏状态h。但边的特征始终使用最初的feature。
另外,邻接矩阵在两层之间是不断更新的,公式如下: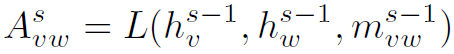
这里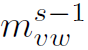 与的含义和计算方式不同,没有考虑node的h,相当于是在计算edge的隐藏状态,具体细节可看代码实现。
与的含义和计算方式不同,没有考虑node的h,相当于是在计算edge的隐藏状态,具体细节可看代码实现。
Update Function
Update Function用于更新结点feature,也就是结点的隐藏状态。其公式如下: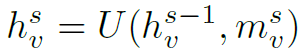
可以看到,Update Function以h和message为参数,相当于用message去更新结点的状态。在实际网络中,Update Function用Gate Recurrent Unit (GRU)实现状态更新: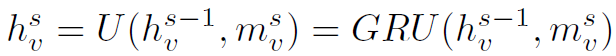
Readout Function
Readout Function作用于最后一层node的隐藏状态 ,得到最终的输出:
,得到最终的输出: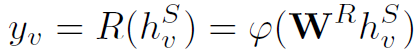
这里实际上也是一个全连接操作,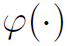 可以根据不同的任务定义不同的激活函数。如one-class outputs用softmax,或multi-class outputs用sigmoid。
可以根据不同的任务定义不同的激活函数。如one-class outputs用softmax,或multi-class outputs用sigmoid。
以上就是GPNN中的四个核心函数,总的来看,GPNN实际上是GCN的扩展,抛弃了严谨的数学约束,使之更加灵活,具有更强的特征提取能力。
最后要注意的是,我们虽然用层来定义GPNN(文中是3层),但这里层与CNN中并不相同。这里的层都是共享参数的,是一种Recurrent结构,原文中也用的是step,但是用层来讲对我而言更好理解。
Experiments
作者分别在image (HICO-DET、V-COCO)和video (CAD-120)上对GPNN作了测试,两者的网络结构在实现上会有一些微小的区别。主要体现为在针对video的网络中,Link Function使用了convLSTM(1024-1024-1024-1)-sigmoid



总结
最近越来越多的研究将GCN应用于human activity,因为GCN可以很好的提取关系特征,很自然的表达人与物体之间的交互关系。针对本文,目前还有两个疑问有待解决:
在video实验中作者使用了convLSTM作为Link Function。这里convLSTM的更新过程是在一个视频帧中,GPNN的不同step之间更新的(有待求证)。忽略了不同视频帧中的时域信息。实际上convLSTM好像并没有发挥出提取时域信息的能力。
看了代码,1这里没问题。
在网络训练过程中,作者提到:We employ an L1 loss for the adjacency matrix. For the node outputs, we use a weighted multi-class multi-label hinge loss. 对于loss的具体形式,文中没有明确说明。而且针对adjacency matrix计算loss,它的ground truth是什么,怎么得到?还有待在代码中寻找答案。
adjacent matrix的gt是作者自己构造的,即一幅图片中所有人和物实体之间有交互关系则为1,否则为0。以这个反映是否存在交互的邻接矩阵为gt,和模型得到的adjacent matrix求L1 loss。其实相当于对人和物是否交互先做个初步二分类,用L1 loss训练。

若有收获,就点个赞吧
0 人点赞
