ICCV 2019 论文标题:Bayesian Graph Convolution LSTM for Skeleton Based Action Recognition 论文地址:http://openaccess.thecvf.com/content_ICCV_2019/papers/

简介
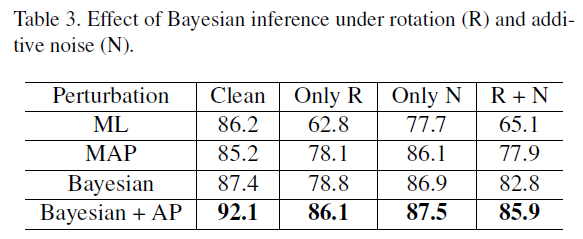
本文针对Skeleton Based Action Recognition任务,提出了GCN+LSTM+Bayesian framework的组合模型,从空间关系、时序关系和动作主体多样性这三个角度挖掘skeleton的运动模式。其中Bayesian framework的引入是本文的亮点所在,其类似于模型平均的思想,可以提高网络的泛化能力。另外,在网络训练过程中,作者设计了adversarial prior对模型参数正则化,也有助于网络学习到独立于运动主体,更加鲁棒的运动特征。
Methods
模型的整体结构如图1,可以看到Bayesian GCLSTM就是按照GCN->LSTM->Bayesian的顺序堆叠起来的组合模型: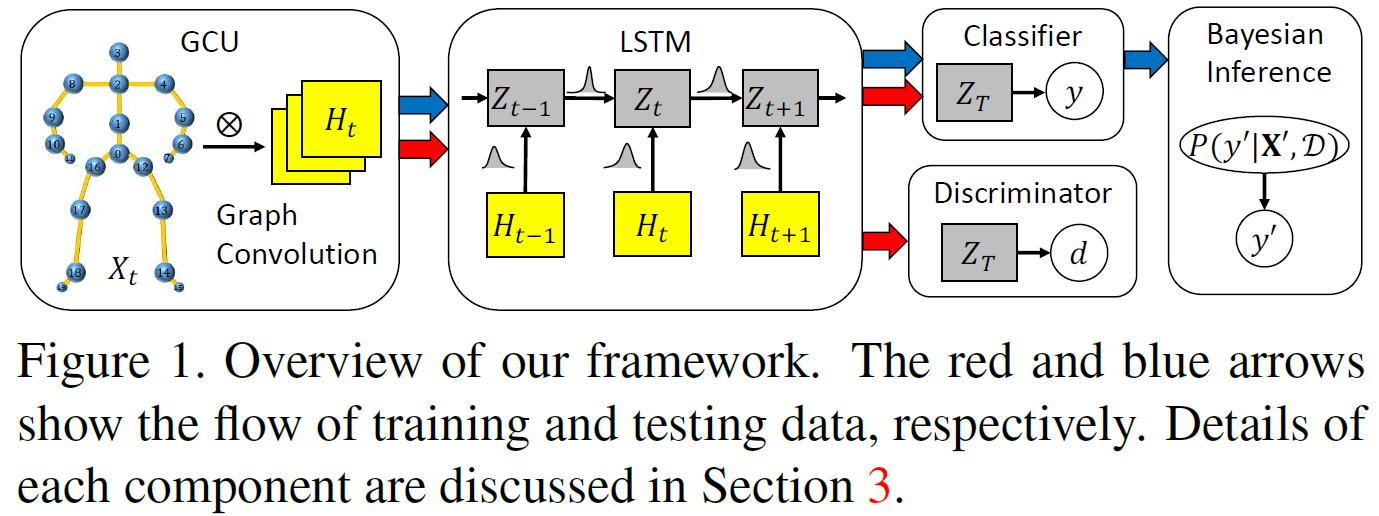
Representation Learning from Skeletons
首先利用GCN在skeleton上提取特征。文中skeleton graph的构造方式如图2,其初始的结点特征为三维的joint position和三维的joint speed,其中joint speed就是相邻时序上joint的位置变化值。因此对于每个node,其初始特征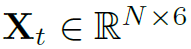 ,是个6维的特征向量。另外要注意,skeleton是有时序的,因此存在下标t,对于每个t时刻的skeleton都需要单独用GCN提取特征。邻接矩阵就是图二所示的local和global两种,相连通则为1,不连通则为0。
,是个6维的特征向量。另外要注意,skeleton是有时序的,因此存在下标t,对于每个t时刻的skeleton都需要单独用GCN提取特征。邻接矩阵就是图二所示的local和global两种,相连通则为1,不连通则为0。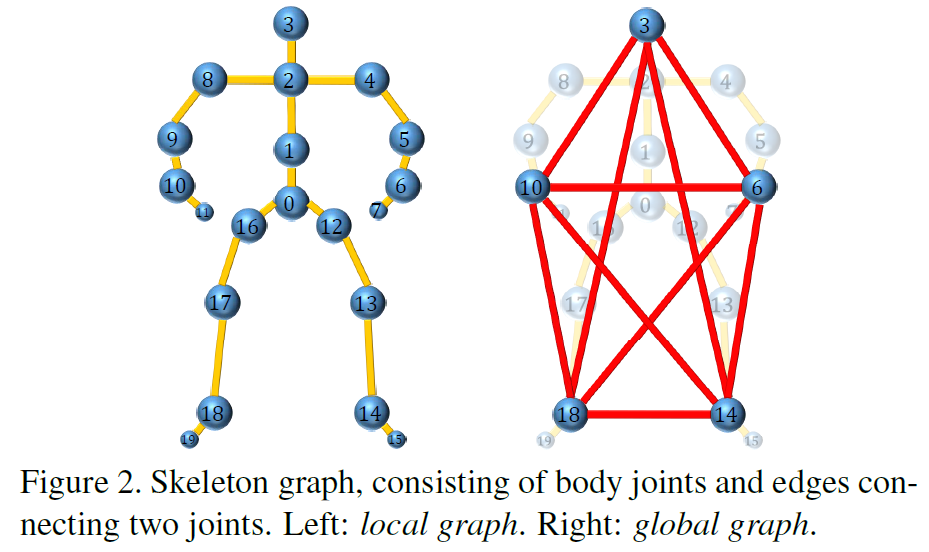
作者使用了经典的GCN结构,只是对标准化的邻接矩阵添加了一个learnable的mask,避免冗余的连接,公式如下: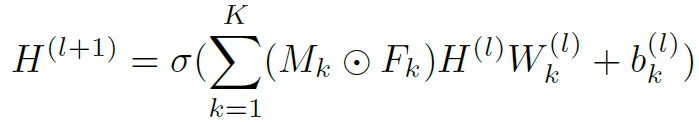
其中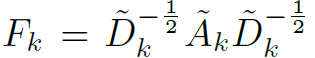 ,
,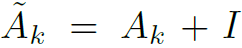 ,
,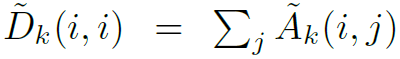 。这里就是经典的GCN,不做多余介绍。在实验中,作者使用的layer数为4,并且用了类似于resnet的skip connection。
。这里就是经典的GCN,不做多余介绍。在实验中,作者使用的layer数为4,并且用了类似于resnet的skip connection。
GC-LSTM
通过GCN在时序T上可以得到T个skeleton的graph representation。作者好像没有给出如何从node representation得到graph representation,但通常的做法就是求和或求平均。然后利用经典的LSTM在T个graph representation上提取时序特征,如图3: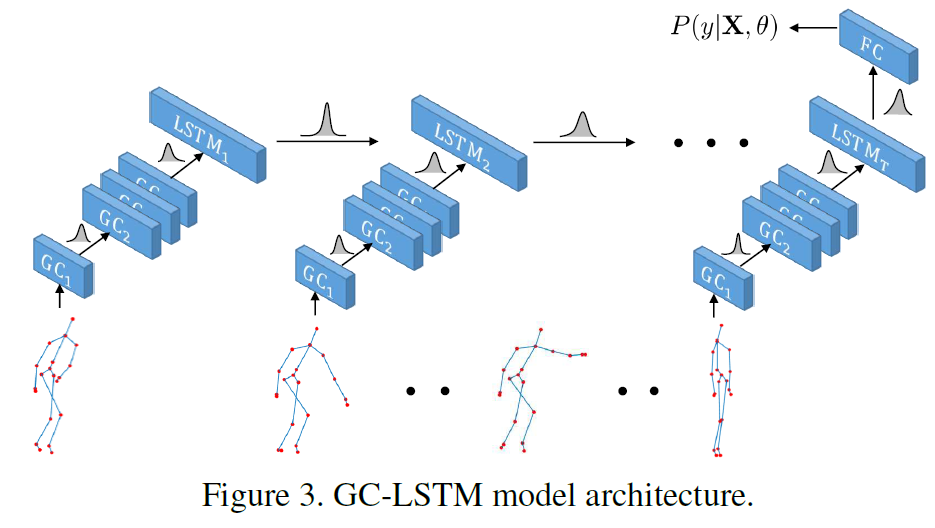
这样,我们就能得到一个综合了空间特征和时序特征的skeleton representation,可以直接用来分类action。但这样粗糙的方法会造成模型的过拟合,泛化能力也不强。因此,作者作出了一下改进。
Bayesian extension
提升模型泛化能力的最直接方法就是模型平均,其实Dropout的本质也是如此。用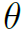 表示GCN和LSTM的所有learnable参数,作者的思路很简单:若一套固定的训练结果
表示GCN和LSTM的所有learnable参数,作者的思路很简单:若一套固定的训练结果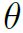 会导致模型的过拟合和泛化能力差,那就给模型多套不同的
会导致模型的过拟合和泛化能力差,那就给模型多套不同的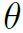 ,构造结构相同但参数不同的多个模型,最后求平均。同时,为了在训练过程中约束
,构造结构相同但参数不同的多个模型,最后求平均。同时,为了在训练过程中约束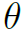 的分布,作者用高斯分布作为先验,同样可以提升模型的泛化能力。这样从另一个角度来看,对action的分类就成了一个最大似然估计,而对于每个,就是一个最大后验估计。因此作者称这是一个Bayesian framework。再结合公式来看:
的分布,作者用高斯分布作为先验,同样可以提升模型的泛化能力。这样从另一个角度来看,对action的分类就成了一个最大似然估计,而对于每个,就是一个最大后验估计。因此作者称这是一个Bayesian framework。再结合公式来看: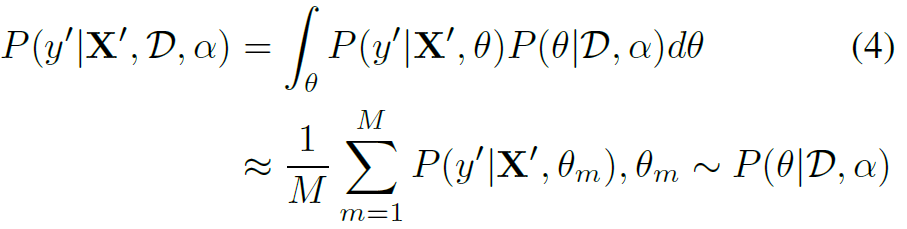
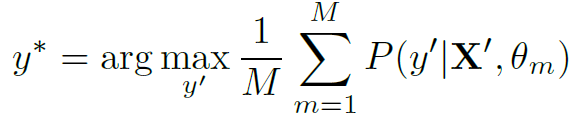
其中X表示观察到的skeleton数据,y表示action label。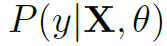 表示在参数和数据X的条件下,这个skeleton的action label为y的概率。
表示在参数和数据X的条件下,这个skeleton的action label为y的概率。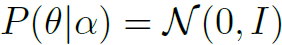 是指的先验分布为高斯分布。
是指的先验分布为高斯分布。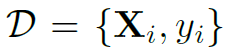 表示所有的训练数据集。这两个公式看似复杂,其实就是说模型的最终结果是对M个以不同
表示所有的训练数据集。这两个公式看似复杂,其实就是说模型的最终结果是对M个以不同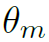 为参数的模型结果的平均,而以高斯分布为先验。最后还有个重要的问题:M个不同的如何得到?之后详细来讲。
为参数的模型结果的平均,而以高斯分布为先验。最后还有个重要的问题:M个不同的如何得到?之后详细来讲。
Adversarial prior
泛化能力较强的模型学习到的各种action的特征应该是和动作主体无关的。为达到这个目的,最简单的办法就是用更多的数据训练。但作者利用adversarial learning思想,显式地设计了Adversarial prior,让网络更好地学习与主体无关的运动特征。具体做法就相当于在GCN+LSTM之后,构造了两个不同功能的对抗分类器,并设计了相应的loss函数。第一个softmax分类器用于分类action,第二个sigmoid分类器用于判断两个样本是否是同一主体。
构造两个后验分布(其实就相当于负的loss函数)如下: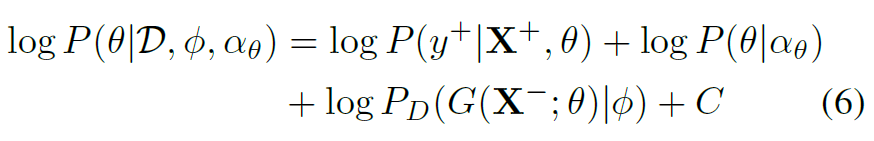
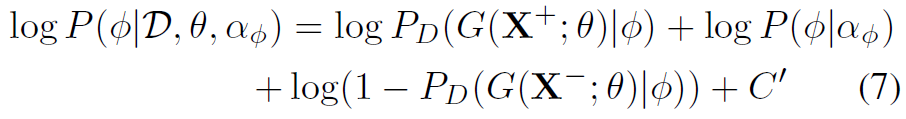
其中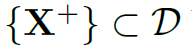 是mini-batch的训练样本,
是mini-batch的训练样本,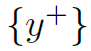 是其标签。
是其标签。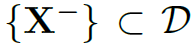 是和训练样本动作相同但主体不同的样本。
是和训练样本动作相同但主体不同的样本。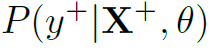 表示action分类器对标签的输出概率,
表示action分类器对标签的输出概率,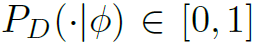 表示主体分类器输出的概率。C表示正则化的常量。
表示主体分类器输出的概率。C表示正则化的常量。
这两个式子是adversarial的,作用和loss函数相同。式(6)是在训练action分类器,让网络能更准确地分类action,并且尽可能地提取到能使主体分类器无法区分的样本特征。式(7)是在训练主体分类器,让其尽可能地区分不同主体。二者对抗训练,使模型学习到和主体无关的action特征。
Bayesian Inference
最后来解答之前的问题:M个不同的如何得到。其实是取了网络训练过程中不同阶段的。如下:
可以看到在模型训练过程中有个对采样的间隔 ,最后采样得到M个。模型训练过程中,的更新方式如下:
,最后采样得到M个。模型训练过程中,的更新方式如下: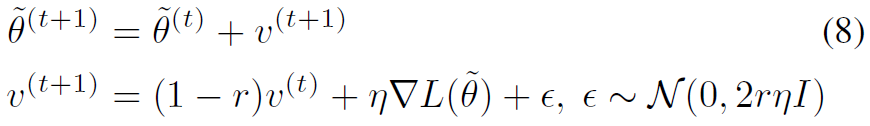
这个式子是对的优化过程,称为stochastic gradient Hamiltonian Monte Carlo (SGHMC)。其实就相当于momentum的梯度下降,其中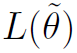 就是式(6)和式(7)定义的后验概率公式,作用相当于负的loss函数。
就是式(6)和式(7)定义的后验概率公式,作用相当于负的loss函数。
最后再看一下图1的后半部分,其中classifier和discriminator就是对抗学习的两个分类器,discriminator只在训练过程中有用。Bayesian Inference就是这个约束模型参数的先验概率分布,并且多模型求平均的过程。
Experiments
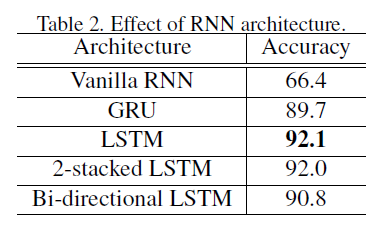
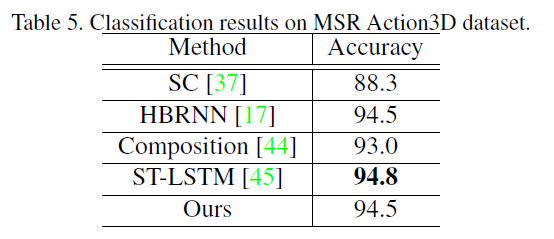
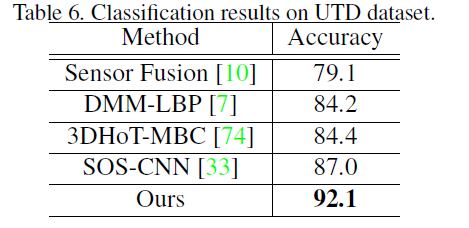
作者在MSR Action3D、UTD MHAD、SYSU和NTU RGB-D数据集上做了充分的实验,详见原文。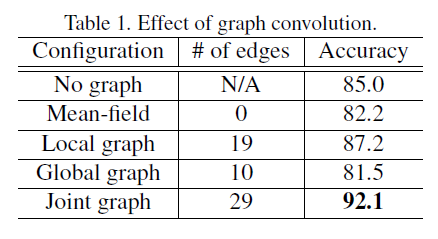
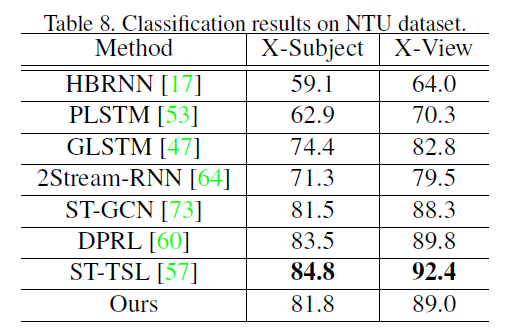
总结
个人第一次看Skeleton Based Action Recognition任务的论文,文中有很多经典的数学理论理解的并不是很透彻,只是记录一下自己的见解。Skeleton作为一个重要的action语义线索,和GCN结合也很方便,值得深入学习。

若有收获,就点个赞吧
0 人点赞
