ECCV 2018 论文标题:Pairwise Body-Part Attention for Recognizing Human-Object Interactions 论文地址:https://arxiv.org/abs/1807.10889

简介
本文提出了Pairwise Body-Part Attention (PBPA)模型辅助解决HOI recognition任务。PBPA模型可以使网络聚焦于HOI中人体重要的body part,并且提取pairwise part间的关系特征。然后将这些细粒度的特征与整体的特征融合,可以提升recognition精度。本文虽然是recognition任务,但也是基于object detection的,所以相当于detection任务。最后作者在HICO和MPII数据集上做了实验。
Pairwise Body-Part Attention
本文的contribution主要集中在两个点:1.本文考虑了更细粒度的human body part特征以及pariwise part间的关系特征,包括了appearance和spatial configuration。2.本文提出了attention模型从众多的pariwise part中筛选出最重要的特征。因此,我们主要来解读这两个contribution,其他部分简要说明。
图1展示了作者的motivation:human part的特征以及两两之间的位置关系可以帮助网络识别HOI。
图2是网络的整体结构: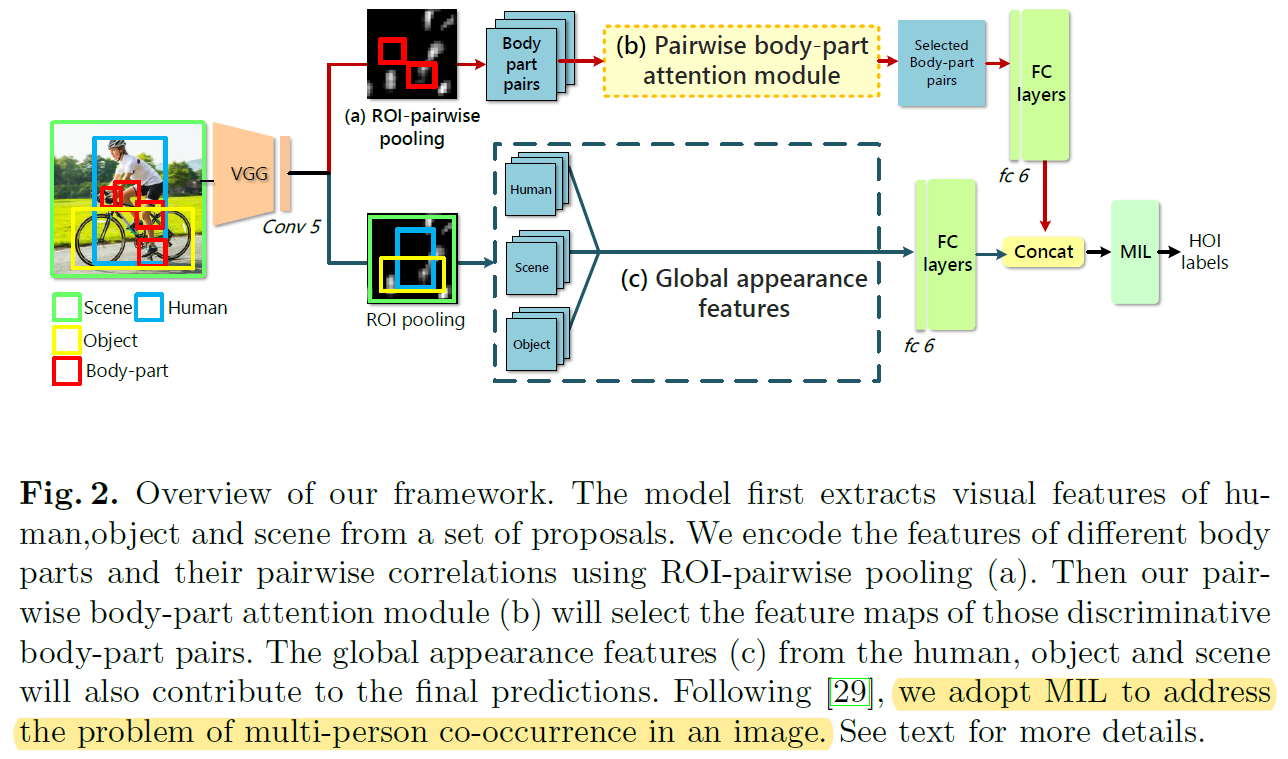
可以看到这是个two stream的网络。下面的stream就是普通的粗粒度特征提取过程,包括了human、object和scene。只是需要注意作者在提取object特征的时候用的bounding box是object和human的union box,目的是融合更多的context信息。上面的stream是本文的核心内容,用于提取细粒度的pairwise body part特征。其包括了ROI-pairwise Pooling、Attention Module两个主要模块,以下分别介绍:
ROI-pairwise Pooling
pairwise body-part是将body part两两组合,这也就造成了ROI pooling的困难。因为两个body part之间可能间隔很远,如果用一个union box做pooling的话,会引入很多没用的噪声。因此作者设计了ROI-pairwise Pooling方法,如图3左:
思路很简单,将union box中不属于两个bounding box部分的值设置为0,两个bounding box内的特征保持不变。然后在这个新的feature map上做ROI pooling就可以了,作者使用的是max pooling。
Attention Module
这里的attention module是一种self-attention的结构,即用自己的feature生成自己的attention。简单来讲就是将pooling后的feature经过几个全连接层,得到一个scalar作为权重。共有m个pairwise body part,就生成m个attention权重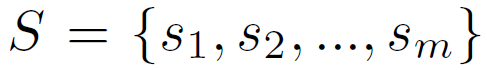 。然后按照权重的大小排序,筛选出前k个权重最高的pairwise body part保留,其余都舍弃:
。然后按照权重的大小排序,筛选出前k个权重最高的pairwise body part保留,其余都舍弃: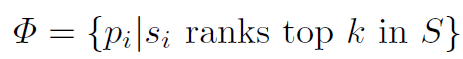
最后将attention权重与feature相乘,得到k个pairwise body part feature。这些特征用于和全局的特征进行融合,提升HOI识别精度。这整个流程在图3中表现地很清晰,虽然思路很简单,但既保留了重要的细粒度特征,也考虑了body part间的spatial configuration,还是值得借鉴的。
Experiment
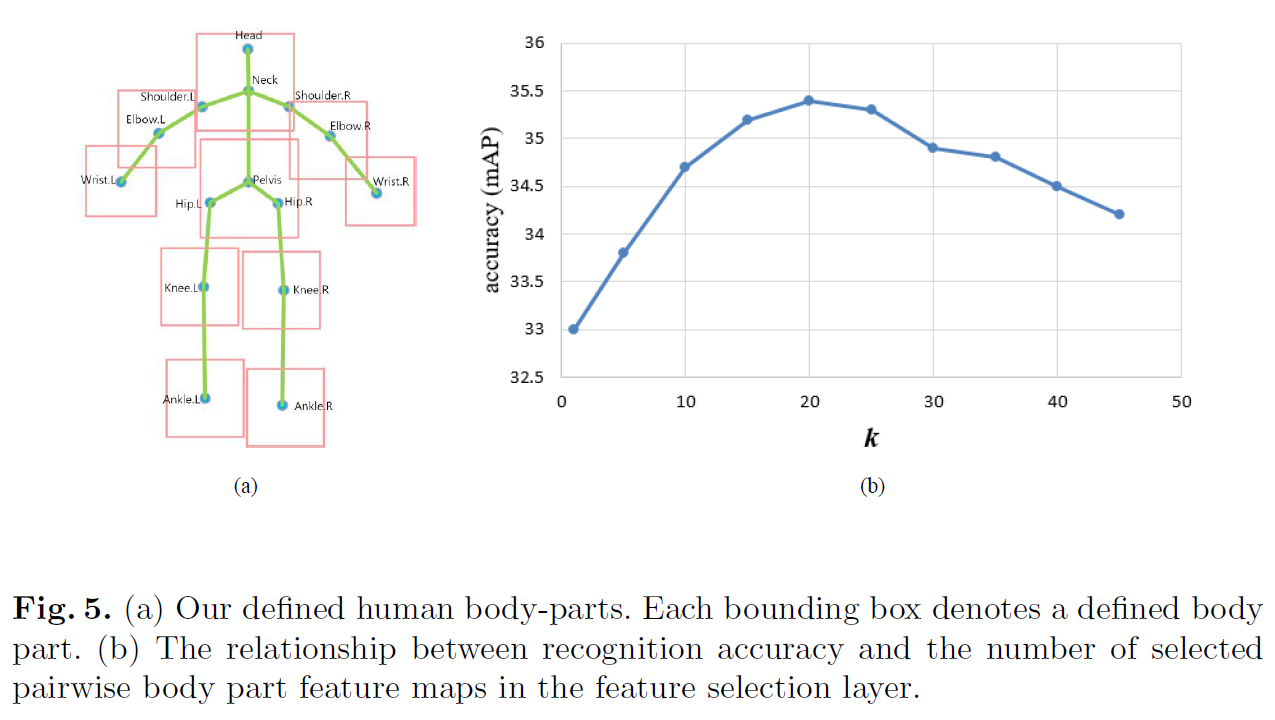
作者在HICO和MPII数据集上做了实验。注意一下图5,如果k值取的过大,网络的效果不升反降。可能原因是过多的pairwise body part引入了大量没用的特征和噪声,反而不利于模型识别HOI。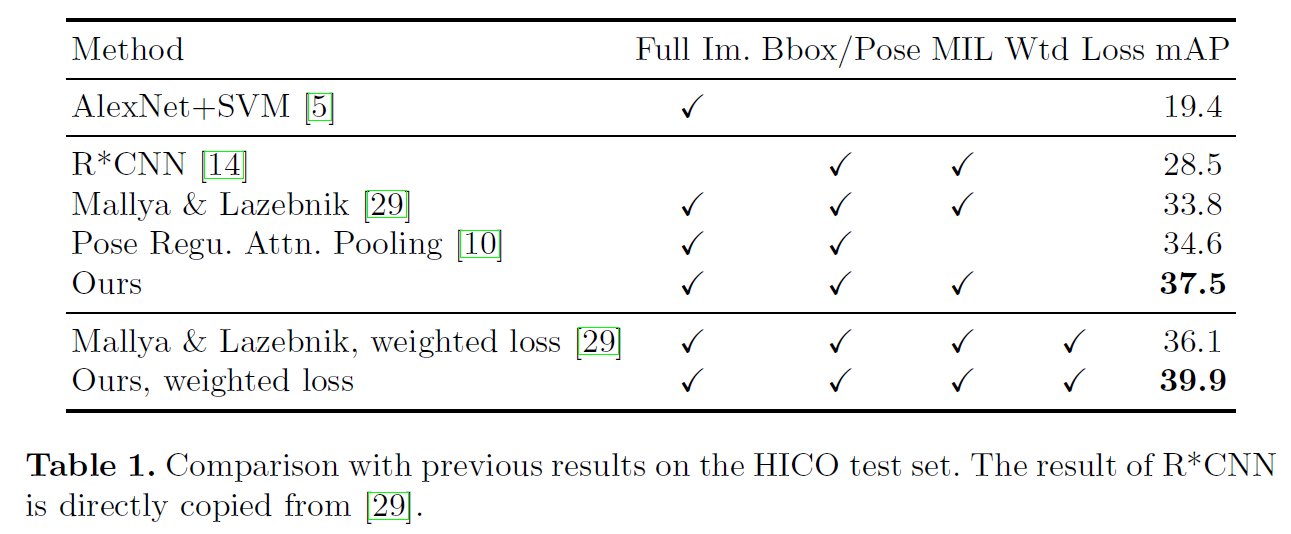


总结
本文思路很简单。将body part两两组合,考虑其pairwise特征和spatial configuration这种想法也很巧妙。

若有收获,就点个赞吧
0 人点赞
