ICCV 2019 论文标题:LIP: Local Importance-based Pooling 论文地址:https://arxiv.org/abs/1908.04156 代码地址:https://github.com/sebgao/LIP

简介
本文对pooling结构提出了一个统一的框架Local Aggregation and Normalization (LAN)。在该框架下,传统的average pooling、max pooling和strided conv都存在一些缺点。因此,作者基于Local Importance思想,提出了一种更有效且更一般的pooling方法,称为Local Importance-based Pooling。该方法本质上是利用attention思想做pooling,传统的几种pooling方法都可以视为该方法的特例。
Local Aggregation and Normalization
先来看本文的LAN框架。很简单,就是将pooling过程看作加权平均的过程: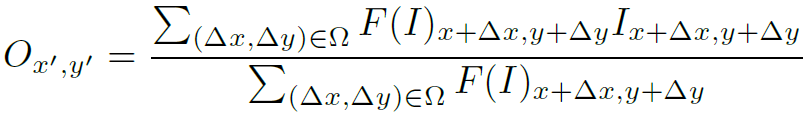
其中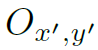 表示pooling后的feature map在x’,y’处的值。
表示pooling后的feature map在x’,y’处的值。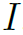 表示初始feature map。
表示初始feature map。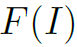 为importance map,即权重。这个式子仅表示1个channel,n个channel同理。但需要注意的是,与一般attention map不同的是,importance map在各个channel不共享,即每个channel的都会有自己的。
为importance map,即权重。这个式子仅表示1个channel,n个channel同理。但需要注意的是,与一般attention map不同的是,importance map在各个channel不共享,即每个channel的都会有自己的。
在LAN框架下,作者分析了传统的几种pooling方式: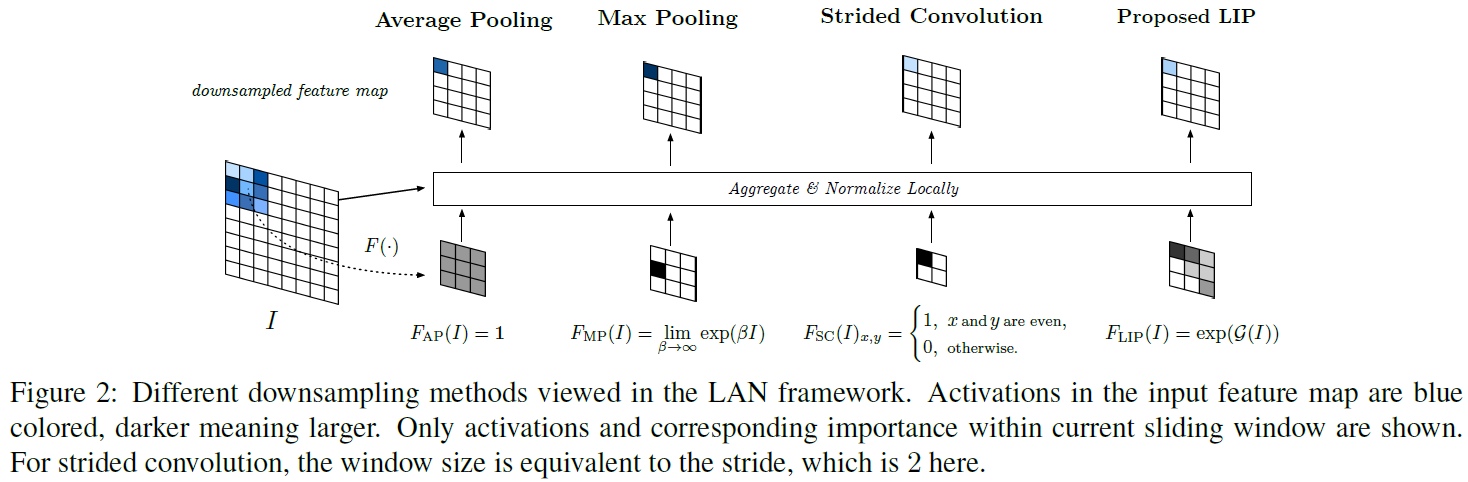
Average pooling
在LAN框架下,average pooling的权重函数是: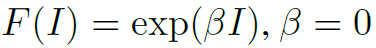 。也就是
。也就是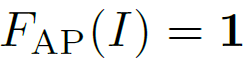 ,表示不同位置的值权重都是一样的。这样会降低feature map的分辨能力,是一种模糊的降采样过程,也会使feature map丢失小的细节。
,表示不同位置的值权重都是一样的。这样会降低feature map的分辨能力,是一种模糊的降采样过程,也会使feature map丢失小的细节。
Max pooling
在LAN框架下,map pooling的权重函数是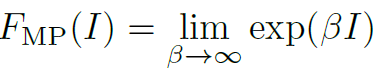 。它假设在feature map中最具有辨别能力的feature具有最大的激活值。这种假设存在两个缺点:1.在局部feature map中,最具有辨别能力的feature激活值不一定最大。2.map pooling会阻碍梯度的反向传播过程。
。它假设在feature map中最具有辨别能力的feature具有最大的激活值。这种假设存在两个缺点:1.在局部feature map中,最具有辨别能力的feature激活值不一定最大。2.map pooling会阻碍梯度的反向传播过程。
Strided convolution
strided convolution可以分解为两步:先以stride=1进行conv,再根据stride的值丢弃部分feature。其权重函数如下: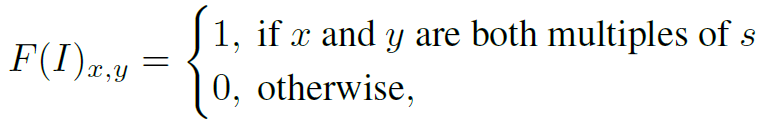
其中s表示stride size和sliding window size。这样来看,strided conv并没有对local importance进行建模,仅仅保留feature map中固定位置的feature,其余的丢弃,这是很不合理的。因此strided conv对feature map的微小变换不具有适应性。
Detail-preserving pooling
这是这篇CVPR2018论文中提出的pooling方法,大致是通过计算滑动窗口内特征的方差确定其detailed,是一种启发式的pooling方法,具体可看原文。这种方法的缺点是最具辨别力的feature不一定是最detailed的。例如背景中的噪音可能比纯色的鸟具有更高的detail。同时,这种手工设计的启发式方法具有很强的先验性质,而先验知识并不总是正确的。
Requirements of ideal pooling
对比以上几种传统的pooling方法,作者总结出了理想pooling方法需要具备的特点:1.要对feature map的微小扭曲和变换具有鲁棒性,不能简单地固定特征保留的位置。2.需要保留最具有辨别能力的特征,而不能依赖于某些先验知识。因此,作者设计了具备以上特点的Local Importancebased Pooling。
Local Importance-based Pooling
其实思路很简单:既然我们不能通过先验知识确定权重函数,那么就交给网络自己去学习吧!类似于attention函数,作者设计的权重函数如下: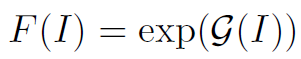
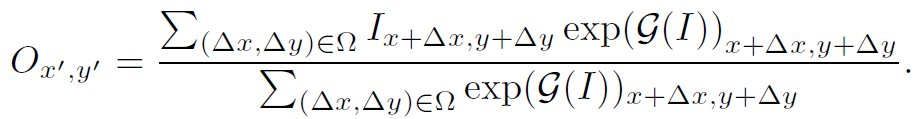
其中exp()是为了保持权重>1。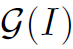 就是一个小的子网络,用于学习权重,可以根据具体问题具体设计。pooling的操作过程以及pytorch实现如下:
就是一个小的子网络,用于学习权重,可以根据具体问题具体设计。pooling的操作过程以及pytorch实现如下: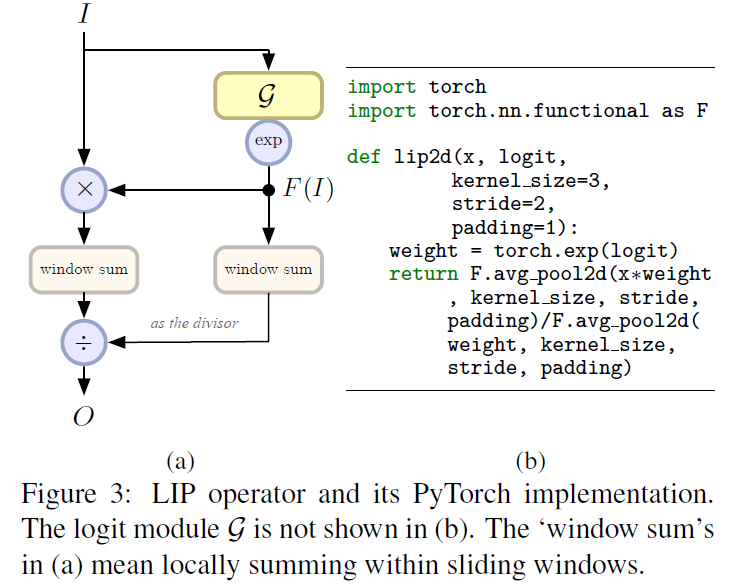
作者的代码也是很巧妙,用两个ave_pool2d()实现了Local Importance-based Pooling。这里需要仔细理解一下。对于,作者设计了两种形式(图4d和e):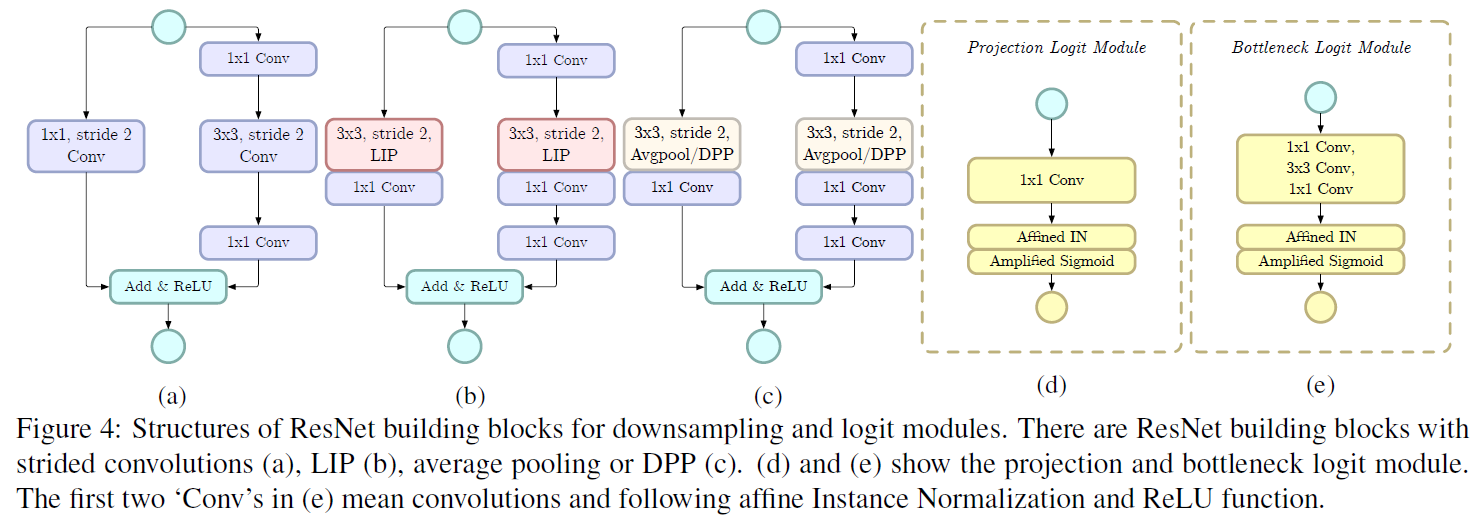
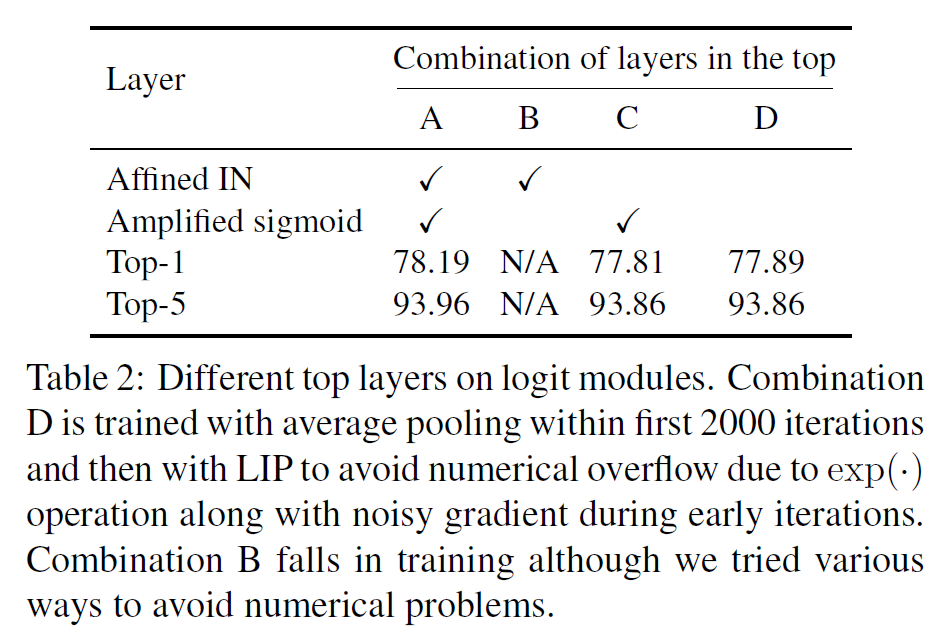
图4(d)叫做projection from,就是11Conv+Affined IN+Amplified Sigmoid。其中Affined IN是affine instance normalization,类似于BN,是一种归一化方法,参考文献在这。Amplified Sigmoid用于维持数值稳定,amplification coefficient作者取了12。加入Affined IN和Amplified Sigmoid也会提高LIP泛化为传统pooling的能力,如max pooling。图4(e)叫做bottleneck from,就是把11Conv换成bottleneck结构。
图4(a)(b)(c)是将LIP结构加入Resnet的例子,作者为了减小计算量,将Conv放在LIP之后。具体讲就是将stride2的33Conv替换成stride2 33LIP+stride1 1*1Conv。
LIP结构输出的channel和size与输入的feature map是相同的,所以在实现时,所有的weights都是一起被计算出来的,看了图3中的代码就可以理解这里。原文中还有很多具体的实现细节,作者也开源了代码,可以参考。
Experiment
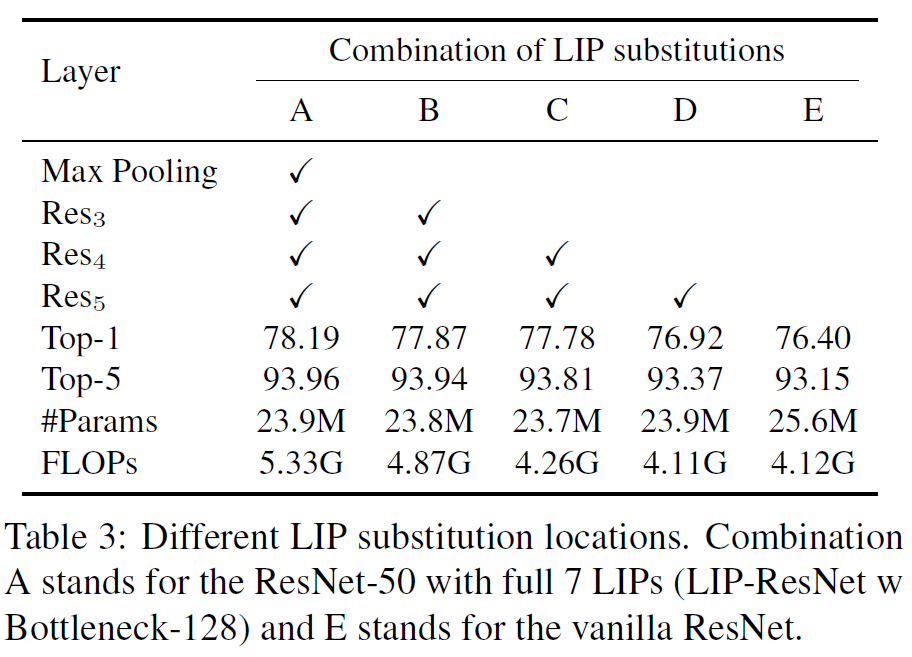
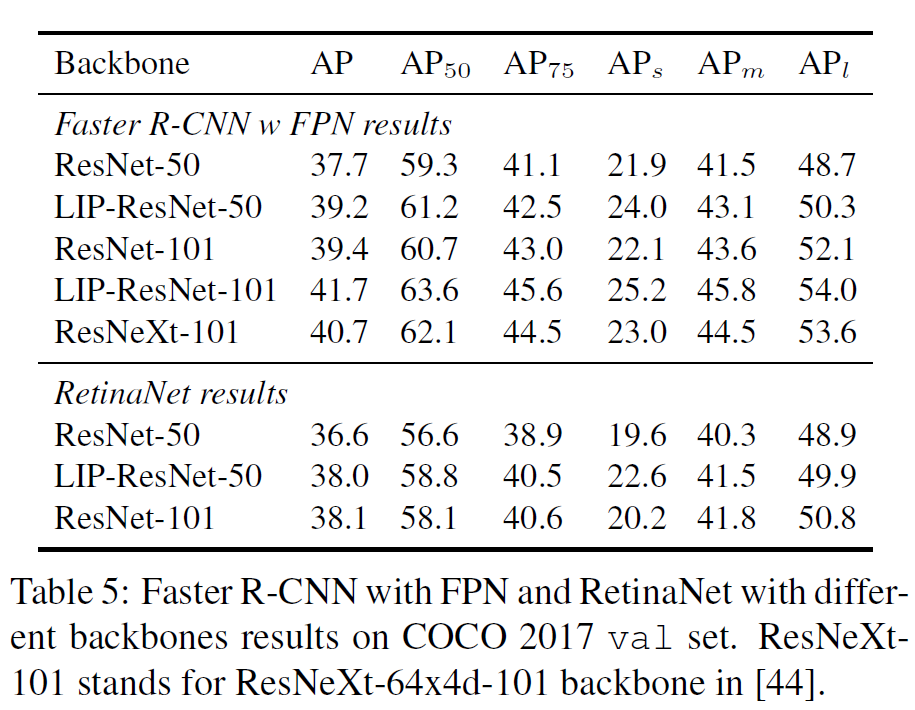
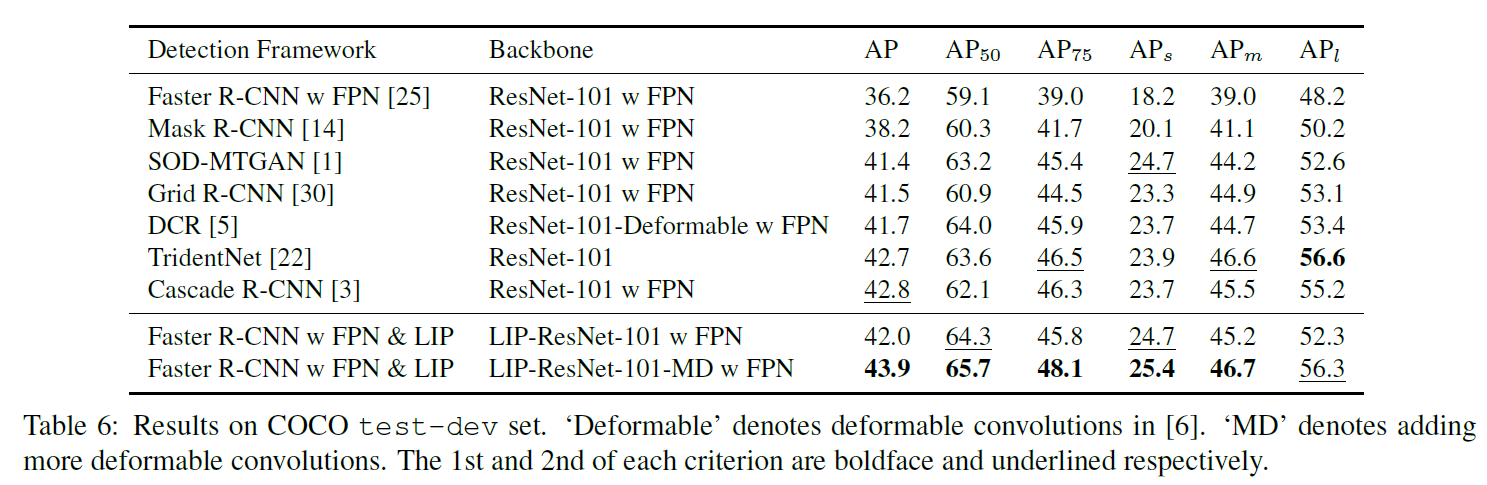
作者将LIP应用在了classification (ImageNet)和detection (COCO)任务上,测试了LIP+Resnet和LIP+Densenet等经典网络结构,均能提升一些精度。另外,LIP可以显著增强网络对于小目标的识别能力。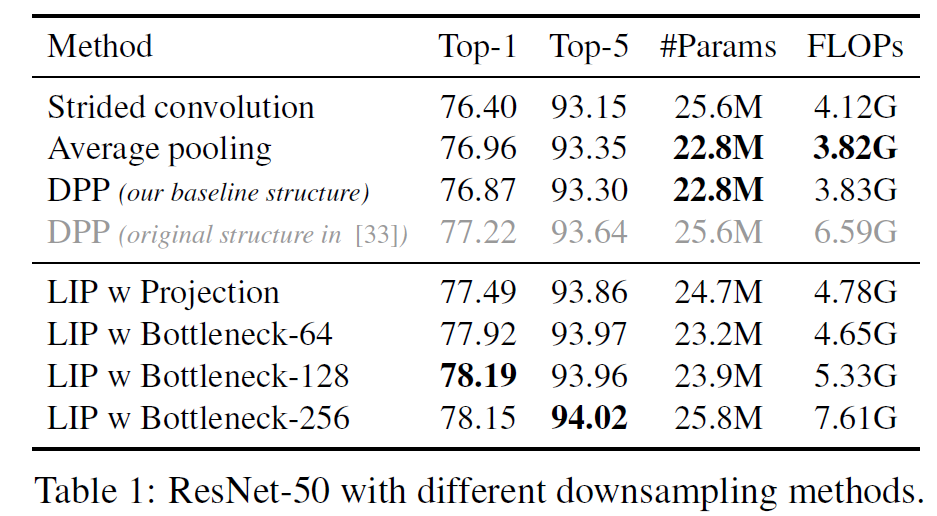

总结
思路很简单却很有效。但LIP是无法取代ROI pooling和Global pooling的,这也是一个可以改进的点。可见顶会模型也不一定复杂,实验做得好,内容完整,easy to follow也是相当重要。

若有收获,就点个赞吧
0 人点赞
