CVPR 2019 论文标题:Relational Action Forecasting 论文地址:https://arxiv.org/abs/1904.04231

简介
本文针对视频中多个体的动作预测任务,提出了Discriminative Relational Recurrent Network (DRN)模型。DRN利用Faster R-CNN的RPN网络检测目标 (person),利用3D-CNN在视频中提取目标特征。然后以目标为node构建graph,通过node上特征的聚合和更新来分析目标间的关系,最终预测下一时刻目标的动作。另外,DRN中graph node上特征的聚合与更新是recurrent的,用到了GRU单元,可以很好地提取node间的relation。最后,实验表明在AVA和J-HMDB数据集上DRN都取得了SOTA的效果。本文最重要的contribution就是引入了graph解析目标间的关系,这对于动作预测很有帮助。
Discriminative Relational Recurrent Network
DRN的整体结构如图1,并没有特别新颖的地方。就是典型的CNN+GCN结构。CNN用于检测目标和提取目标特征,GCN用于分析目标间的关系。本文的重点在于对GCN的设计,下面详细介绍。
Creating the nodes in the graph
构建graph的第一步就是要明确graph的node是什么,从哪来,初始特征怎么提取。DRN中graph的node就是视频中出现的person,本文称为actor。DRN使用RPN网络在已知视频的最后一帧V(本文的任务是已知视频的-H:0帧,预测0:T帧actor的动作,因此V代表已知视频的最后一帧)提取actor proposal,也就是确定视频中出现的actor的bounding box。之后,DRN利用3D CNN在视频的V帧提取feature map。最后结合bounding box,利用ROI Pooling提取node的初始feature。
Modeling the edges
个人感觉原文对DRN的叙述有点啰嗦,适合对GCN了解较少的人看。因此,我就不按照原文的顺序介绍DRN了,而是直接介绍其核心内容,跳过循序渐进的推导过程。
在明确了node之后,构建graph的第二步是要知道edge怎么求。在CV领域众多的CNN+GCN模型中,对node的建模几乎都是一样的套路,但对edge的建模五花八门。本文的思路非常简单: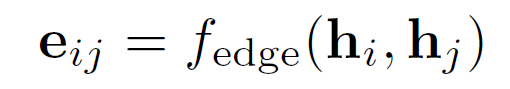
式中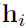 和
和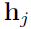 就是node i和node j的特征,
就是node i和node j的特征,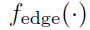 就是一个简单的MLP。这个公式将node i和node j的特征作为输入,输出node i和node j之间的
就是一个简单的MLP。这个公式将node i和node j的特征作为输入,输出node i和node j之间的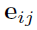 ,这个目前还不是一个scalar,至于为什么,之后会说到。需要注意的是,这种求edge的方式所得到的graph都是完全图,也就是每个node之间都有edge。这可以很好地适应node数量不确定的情况,比如视频中可能有2个人或3个人。
,这个目前还不是一个scalar,至于为什么,之后会说到。需要注意的是,这种求edge的方式所得到的graph都是完全图,也就是每个node之间都有edge。这可以很好地适应node数量不确定的情况,比如视频中可能有2个人或3个人。
Aggregate&Update
有了node和edge之后,我们来看这个graph如何进行aggregate&update。
对于aggregate,作者引入了attention: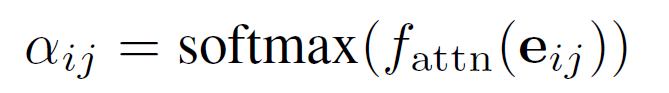
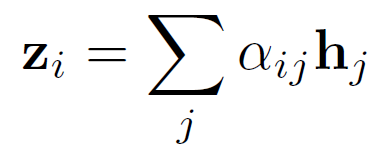
其中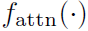 是attention function(也是个MLP),输出node j对于node i的重要性,也就是一个权重。这里输出的
是attention function(也是个MLP),输出node j对于node i的重要性,也就是一个权重。这里输出的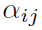 才是一个scalar,是graph真正的邻接权重,之前的只能看作edge的feature。然后对与node i相邻接的所有node j加权求和,得到aggregate之后的结果
才是一个scalar,是graph真正的邻接权重,之前的只能看作edge的feature。然后对与node i相邻接的所有node j加权求和,得到aggregate之后的结果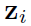 ,相当于GCN中的message。
,相当于GCN中的message。
对于update,作者使用了GRU单元: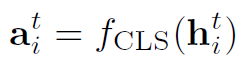

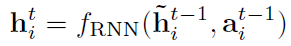
其中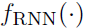 是GRU单元。
是GRU单元。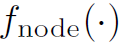 是个MLP,作用是将message与node i自身的特征再聚合一次。
是个MLP,作用是将message与node i自身的特征再聚合一次。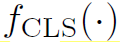 是一个分类器,相当于对每一次迭代生成的node特征都检测出一个action,并且作为下一次迭代的输入。和对于graph中所有的node都是共享的。
是一个分类器,相当于对每一次迭代生成的node特征都检测出一个action,并且作为下一次迭代的输入。和对于graph中所有的node都是共享的。
Loss function
DRN是一个end-to-end的模型,其loss function如下: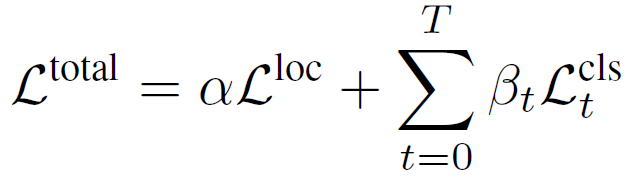
其中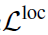 是bounding box的定位loss,与RPN网络中的定位loss计算方式相同。
是bounding box的定位loss,与RPN网络中的定位loss计算方式相同。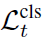 是对t时刻动作类别的预测误差。在J-HMDB实验中,作者用的是softmax cross entropy。在AVA实验中,作者用的是sigmoid cross entropy。二者的区别参照这个博客。
是对t时刻动作类别的预测误差。在J-HMDB实验中,作者用的是softmax cross entropy。在AVA实验中,作者用的是sigmoid cross entropy。二者的区别参照这个博客。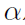 和
和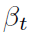 是权重参数,作者在实验中分别设置为1和0.5。
是权重参数,作者在实验中分别设置为1和0.5。
以上就是DRN的整体结构。最后需要注意的是,在GCN的每一次迭代中,都会输出一个预测的action,如果迭代t步,就输出t个action。每次输出的action就代表DRN对下一时刻动作的预测。如此循环下去,DRN会不断根据上一个时刻的动作预测下一个时刻的动作。显然,随着循环次数增多,预测精度会逐步下降。
Experiments
作者在AVA数据集和J-HMDB数据集上做了实验。这里注意一下图5,展示的是top3 relation,也就是对orange box里的actor算出的权重最高的3个attention。可以看到,RPN网络生成的actor proposal是有大量重复的actor,这是RPN网络本身的特性决定的。也就是在graph中,有很多node指代的都是同一个actor,他们的初始feature也是相似的。合理不合理,无法评论,但可以视为DRN的一个特点吧。在网络inference时,如何对一个actor确定一个bounding box?用NMS吗?作者好像没有说明。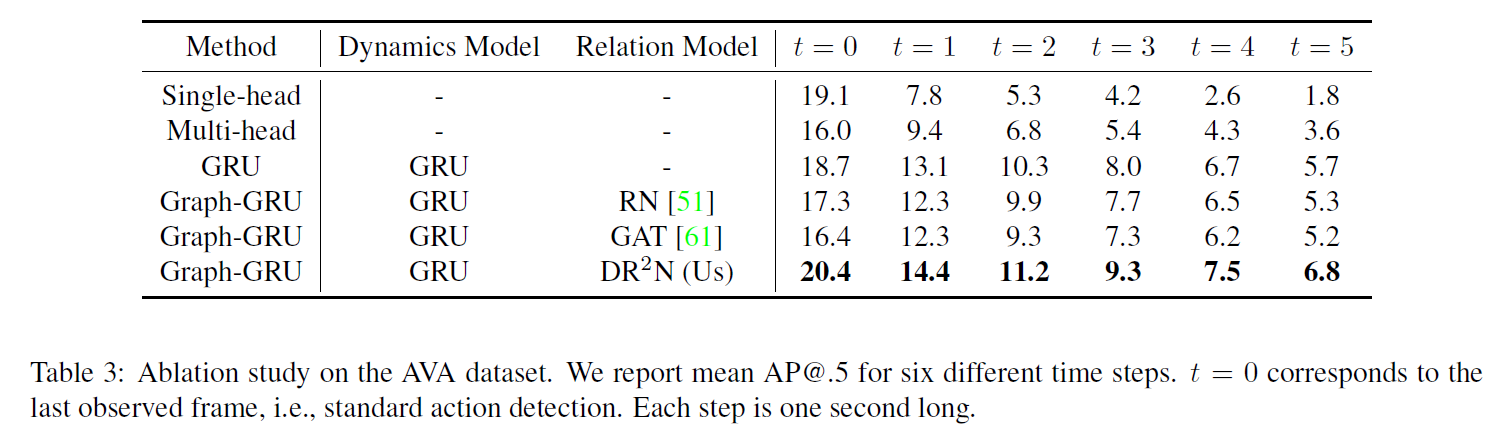


总结
本文提出的DRN应该算是非常典型的CNN+GCN模型,CNN用于提取目标特征,GCN用于解析目标关系,整体结构也很简洁优美。但总感觉动作预测这个任务有那么点玄学。就直观感受来讲,人对动作的预测应该也是主观性的。就像图6中第一列最后一个error predict的例子,如果看到一个人蹲下,那么下一刻他是继续蹲着还是要站起来,可能需要对视频内容有很深的理解才能预测准确吧,DRN真的能做到吗?所以个人感觉,这个动作预测本质上是个动作识别,然后网络会做一个简单的推理,如蹲下->起立,并不会深刻理解剧情。另外,动作或许不仅和人之间的交互有关,人与物的交互,甚至是人与场景的交互,可能也能提供有用的信息。这些在本文中都是没有考虑的。

若有收获,就点个赞吧
0 人点赞
