ICCV 2019 论文标题:Reasoning About Human-Object Interactions Through Dual Attention Networks 论文地址:https://arxiv.org/abs/1909.04743

简介
本文提出了一种Dual Attention Networks解决视频中human-object interactions (HOI)任务。其核心的Dual Attention Module利用HOI任务中action和object潜在的co-dependence关系,生成spatial域上的attention,使feature map聚焦于重要的语义区域(例如一个水瓶的瓶盖部分),从而识别interaction(例如打开水瓶)。与传统self-attention不同的是,本文的dual-attention是一种“互帮互助”的思路:利用先验的action生成object的attention map,利用先验的object生成action的attention map。需要注意,这里的先验知识并不是人为设定的,而是网络学习得到的。作者在Something-Something数据集上验证了该网络的有效性,并且将Dual Attention Module扩展到了其他不同的任务上。
Dual Attention Network for Human-Object Interactions
本文提出的Dual Attention Module可以应用于任何CNN-based action recognition models,对CNN提取出的feature map进行enhance。作者也顺带指出了目前GCN-based方法存在的局限:GCN-based方法需要先进行object和human的目标检测,并且预设好human-object之间的关系。如果场景中存在的human和object很多的话,他们的关系会比较复杂,难以枚举全部,也难以提取特征(如RPNN就假设一个human只与一个object进行interaction)。
对于CNN-based方法,目前有两种框架提取视频帧中的特征:Image-based和Video-based。下面分别介绍:
Image-based
将视频帧看作独立的图片,利用CNN在每一张图片上提取特征,所有帧构成特征集合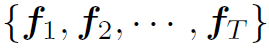 ,
,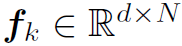 。其中d是feature的维度,N=HW是feature的空间维度。然后对其空间维global pooling:
。其中d是feature的维度,N=HW是feature的空间维度。然后对其空间维global pooling: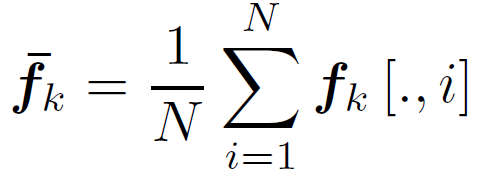
得到的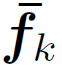 为视频第k帧的feature。之后利用LSTM或TRN (Temporal Relational Reasoning in Videos),聚合各帧的feature,提取视频的feature:
为视频第k帧的feature。之后利用LSTM或TRN (Temporal Relational Reasoning in Videos),聚合各帧的feature,提取视频的feature: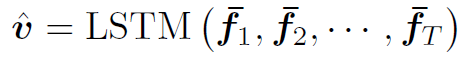
或: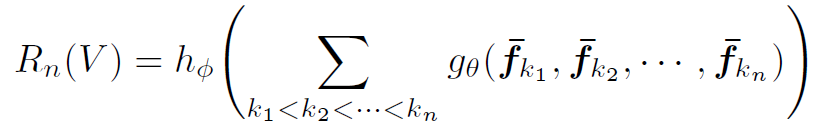
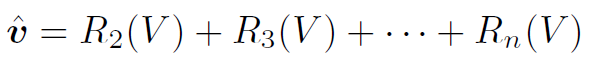
其中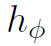 和
和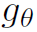 都是多层感知机,详见TRN原文。
都是多层感知机,详见TRN原文。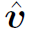 为视频的feature map。
为视频的feature map。
Video-based
Video-based方法将视频视为整体提取feature。这类方法通常会在时域降采样,生成一系列super frame的特征集合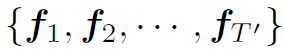 ,然后对每一个super frame的特征global pooling。最后在时域上average pooling,得到视频的feature:
,然后对每一个super frame的特征global pooling。最后在时域上average pooling,得到视频的feature: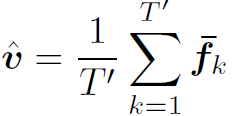
前面介绍了两种常见的视频特征提取的方法。我们也可以看到,本文解决HOI任务的CNN-based思路和GCN-based思路是有很大不同的。GCN-based在目标检测的基础上将图像细分为不同的目标,甚至不同的parts,每个目标提取不同的feature。而CNN-based简单粗暴地从整个视频中提取feature,其中蕴含了视频中的有用信息,在此基础上直接做更高级的HOI语义识别。所以个人理解GCN-based方法可能更加适用于内容复杂的视频或帧数更多的视频,因为其可以更精细化地分析视频中的HOI信息。下面结合网络结构来看核心内容Dual Attention Module。
Dual Attention Module
Dual Attention是一种spatial域的attention,也就是说其生成的attention map是在spatial域对feature map加权。直观来讲就是生成一幅“热力图”,数值高的地方权重大,表示该区域包含的语义信息更加重要。Dual Attention最重要的特点在简介中也提到过,这里引用原文“The dual attention uses action priors to attend image features for objects, and object priors for actions”。下面来看如何计算: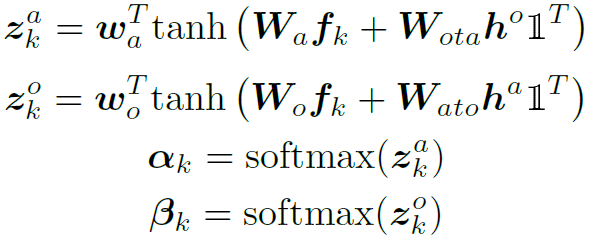
其中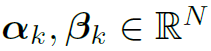 分别表示action和object的attention map。
分别表示action和object的attention map。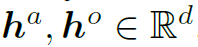 分别是object的先验概率和action的先验概率经过MLP encode之后的d维隐藏特征。
分别是object的先验概率和action的先验概率经过MLP encode之后的d维隐藏特征。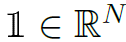 是要素全1的张量,用于将的维度扩展到Nd维。
是要素全1的张量,用于将的维度扩展到Nd维。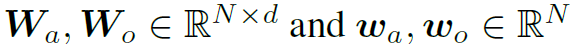 和
和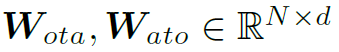 都是learnable的weights。最后的softmax函数起到对attention map标准化的作用。
都是learnable的weights。最后的softmax函数起到对attention map标准化的作用。
需要注意的是最终得到的attention map是N维的,不是Nd维,所以括号内的运算过程像是在用N个d维的filter分别对N个d维的feature进行fully connected(如图3)。得到了action和object的N维attention map之后,我们用attention加权平均取代空间维的global pooling: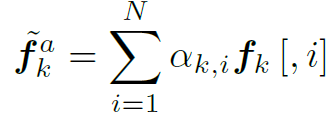
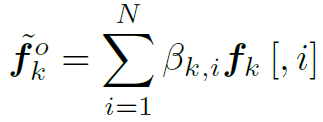
针对上面的过程,作者给出了图示帮助我们理解: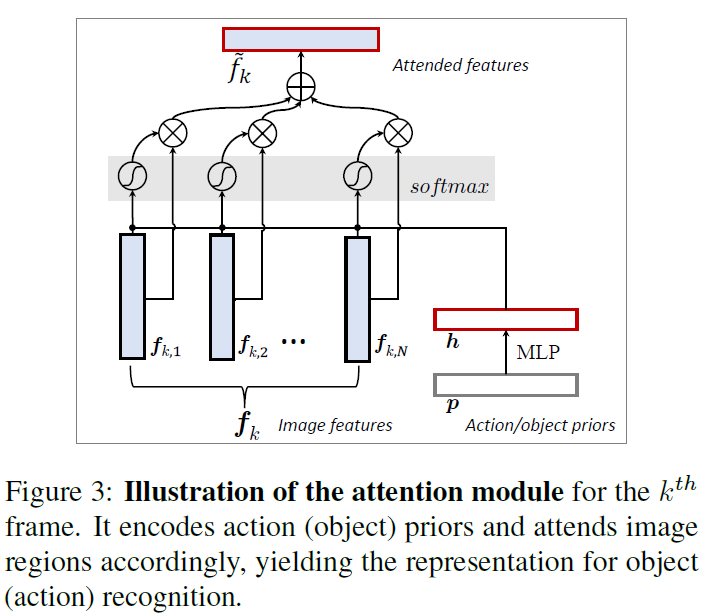
最后要说明的就是上式中用到的object的先验概率和action的先验概率究竟怎么求?这就需要来看网络的整体结构图: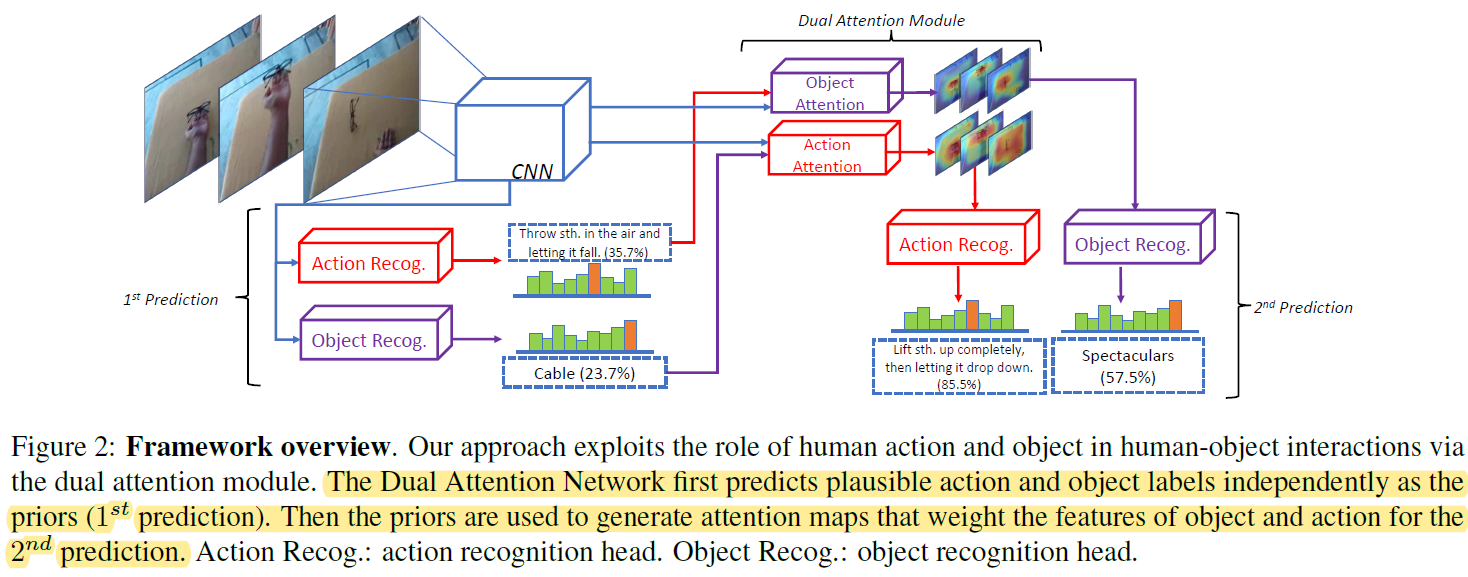
从图2中可以看到,Dual Attention Module的输入包含两部分:CNN提取的feature map和1st Prediction的结果。其中1st Prediction的结果就是object和action的先验概率。Dual Attention Module利用这两个输入,对所有帧生成各自的attention map,然后利用attention map分别enhance出用于Action Recog.和Object Recog.的feature map,输入各自任务的head中,最终分别输出action和object的recognization的结果。需要注意一个细节:1st Prediction中Action Recog.和Object Recog.的输入是同一个feature map,而2st Prediction中是不同的feature map分别用于action和object。对于识别action和object的语义重要区域是不同的,这样做显然是有效的。最后,作者明确说明了1st Prediction和2st Prediction的head部分是不共享参数的。
Experiments
本文的实验部分非常丰富。对于Image-based方式,作者用Temporal Segment Networks (TSN) 和TRN作为backbone。对于Video-based方式,作者用Temporal Shift Module (TSM)为backbone。在此基础上加入Dual Attention Module,都表现出了较好的效果。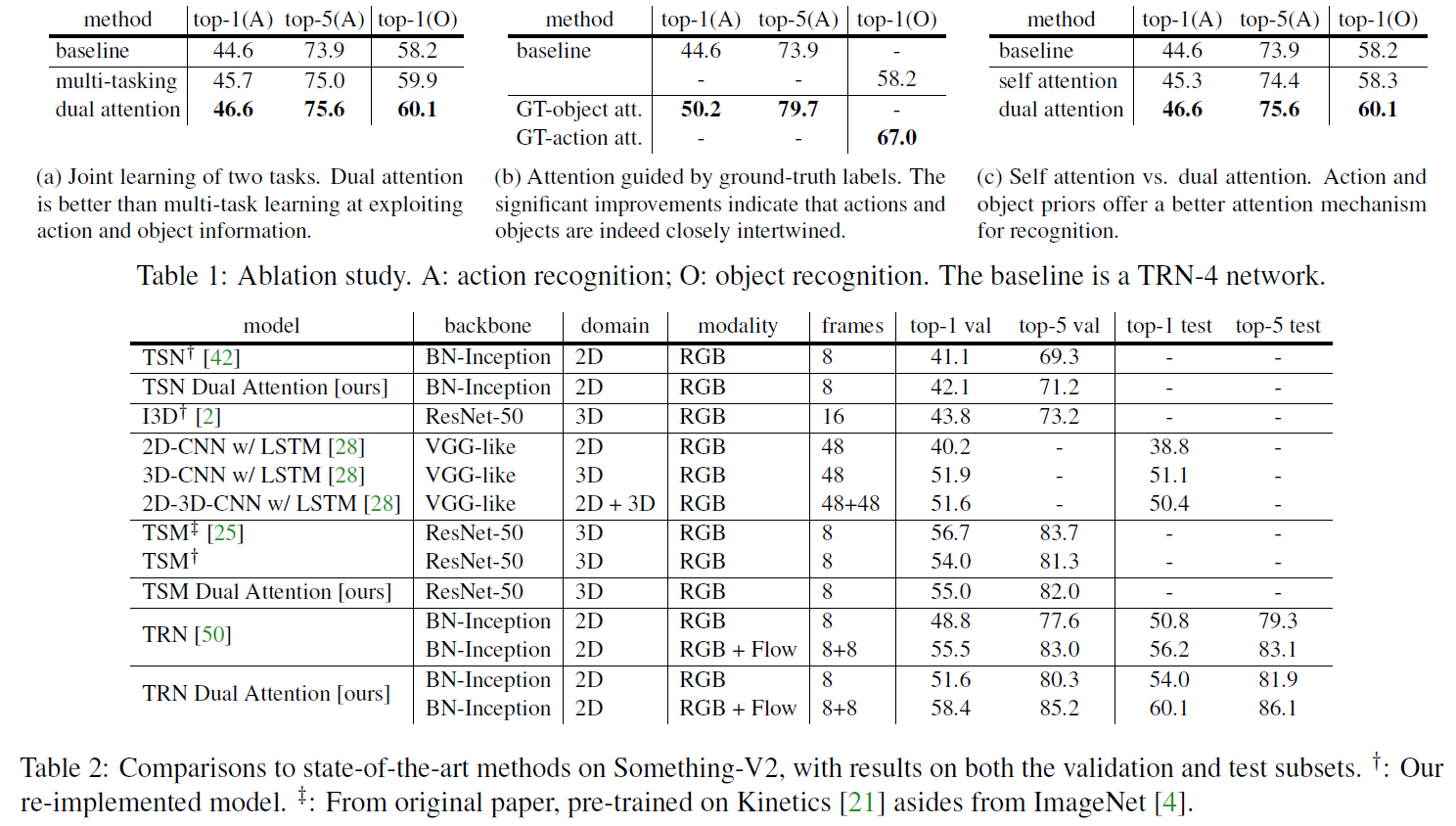
对于attention的效果,作者还做了丰富的可视化,并扩展到了spatiotemporal localization和object-affordance segmentation,详见原文。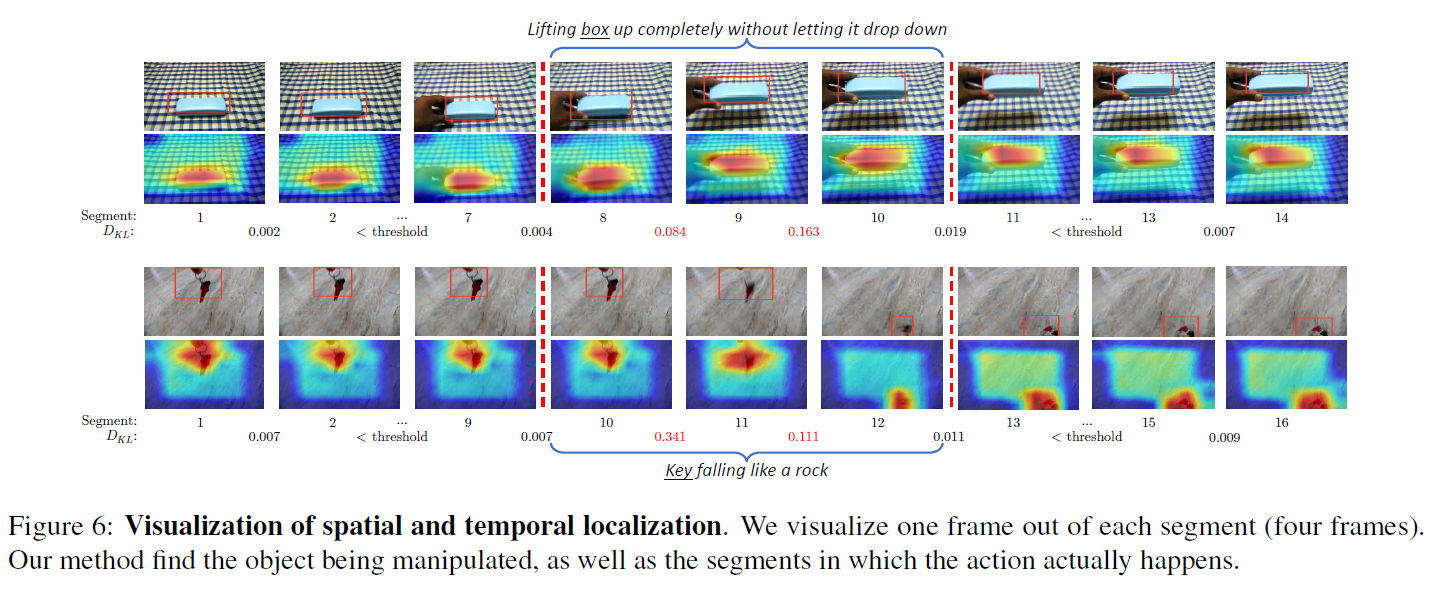

总结
ICCV2019中与attention相关的文章真的很多,但本文的亮点也非常明显,其实现了dual-attention这种“互帮互助”的attention思路,这也是符合我们对HOI任务的认知的:action和object之间存在相互约束,如“打开水瓶”和“折纸”是合理的,但“折水瓶”是不合理的。当我们有了“打开”这个先验action之后,就可以将注意力放在“水瓶”这个object上,并且聚焦于其“瓶盖”区域。
作者用Dual Attention Module对这种隐含的语义约束建模,取得了很好的成果。如果将CNN中丰富的attention模型扩展到GCN中,或在GCN-based方法的backbone中加入attention帮助网络更好地提取特征,可能也会起到不错的效果。

若有收获,就点个赞吧
0 人点赞
