ICCV 2019 论文标题:Local Relation Networks for Image Recognition 论文地址:https://arxiv.org/abs/1904.11491

简介
本文提出了一种新的图像特征提取网络,称为Local Relation Networks (LR-Net)。该网络由Local Relation Layers构成,属于一种bottom-up的特征提取结构:从底层视觉要素入手,通过要素间的appearance和position关系,不断聚合特征,从而组成高层次的feature map,这与传统的conv layer思路 (top-down) 有所不同。作者也在ImageNet上用实验证明了基于local relation的bottom-up特征提取结构确实比传统的conv layer要好。
top-down&bottom-up
个人第一次看到特征提取结构有top-down和bottom-up之分,感觉比较抽象,还有待深入理解。
作者给出了一张有趣的图(图1)解释本文提出的bottom-up与传统top-down的区别。传统的convolution方法对于目标要素的空间变化是非常敏感的,如鸟嘴和鸟头的三种不同相对位置,需要有三种不同的filter才能提取出相同的结果。但本文提出的bottom-up方法是从底层的要素入手,通过计算鸟嘴和鸟头要素的composability,从而适应要素的空间位置变化,再提取相应的特征。简单来讲,传统的top-down方法用固定weights的卷积核,滑动卷积从而在图像上提取特征。整个过程中卷积核的weights是网络学习得到的,是固定的。因此产生的feature map受到卷积核weights的控制。而本文的bottom-up方法是利用上一层的feature map中的要素来计算卷积核的weights。所以卷积核的weights是不固定的,是由feature map控制的。这也就可以适应feature map中要素空间位置的变化。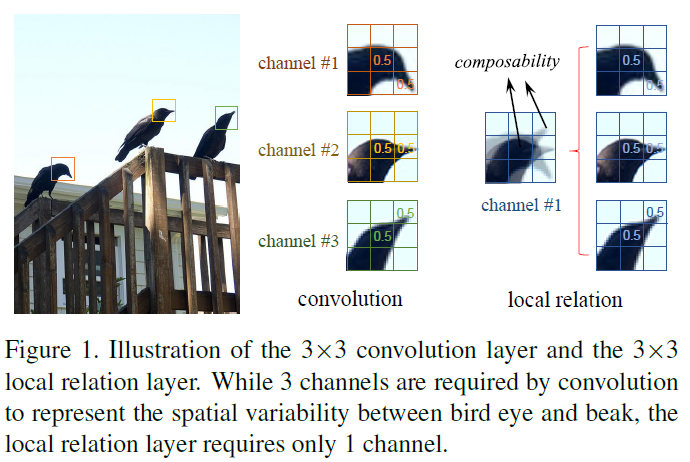
Local Relation Layer
本文的核心内容是Local Relation Layer结构。在此之前,作者写了比较详细的Related Works来总结目前的图像特征提取方法。视角独特,值得阅读。从表1中我们也可以看出top-down和bottom-up的区别:top-down直接学习卷积核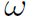 ,bottom-up间接学习其他参数。
,bottom-up间接学习其他参数。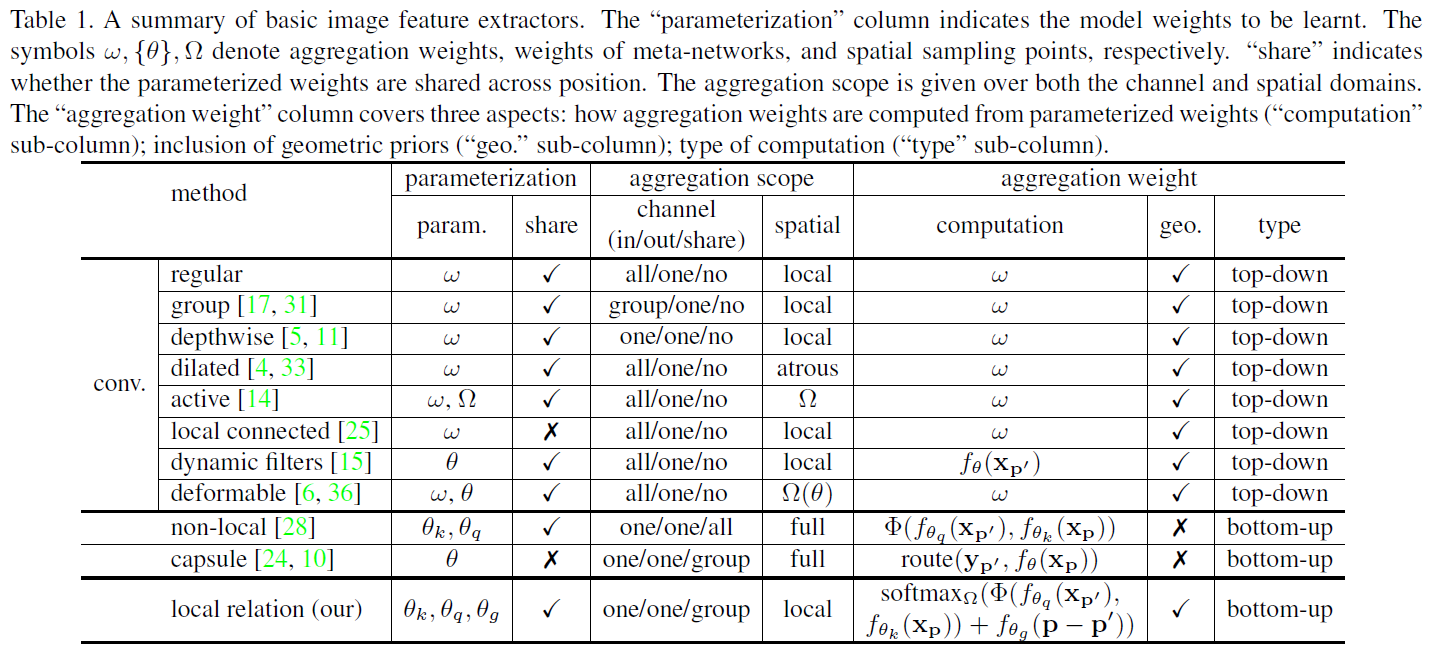
下面来介绍Local Relation Layer:
对于表1中所有的特征提取方式,都能用以下公式概括: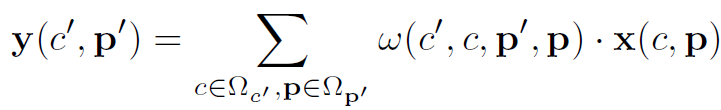
式中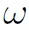 表示权重。
表示权重。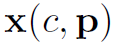 表示feature map在c channel,p位置的值。
表示feature map在c channel,p位置的值。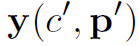 表示提取后的feature map在c’ channel,p’位置的值。
表示提取后的feature map在c’ channel,p’位置的值。 表示特征提取的感受野。不同的特征提取方法仅仅是或不同。Local Relation Layer的计算公式如下:
表示特征提取的感受野。不同的特征提取方法仅仅是或不同。Local Relation Layer的计算公式如下: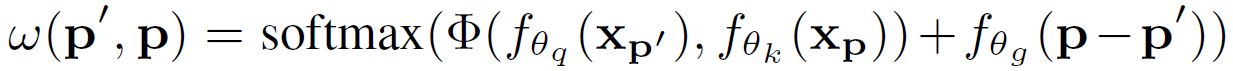
其中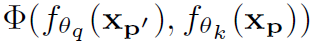 表示p和p’要素值 (appearance) 的composability。
表示p和p’要素值 (appearance) 的composability。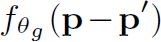 表示geometric prior条件下p和p’要素相对位置的composability。两者从不同角度衡量了要素p和p’的composability,然后相加,再经过softmax标准化得到最终的。
表示geometric prior条件下p和p’要素相对位置的composability。两者从不同角度衡量了要素p和p’的composability,然后相加,再经过softmax标准化得到最终的。 其实就是衡量差异的函数,文中给出了三种计算方法,效果相同:
其实就是衡量差异的函数,文中给出了三种计算方法,效果相同: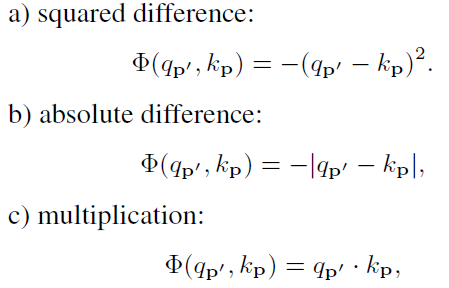
解释一下:这个函数首先通过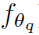 和
和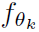 将p’和p的要素值转换到query和key embedding
将p’和p的要素值转换到query和key embedding
space,本文中query和key embedding space都是标量 (scalar)。再计算二者的差异,差异越大,composability越小。
解释一下:这个函数先计算p和p’的相对位置p-p’,再通过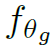 计算相对位置的composability。文中是一个小网络,由conv11->relu->conv11构成。
计算相对位置的composability。文中是一个小网络,由conv11->relu->conv11构成。
通过以上公式还是很难理解Local Relation Layer做了什么,这就需要结合图2来看: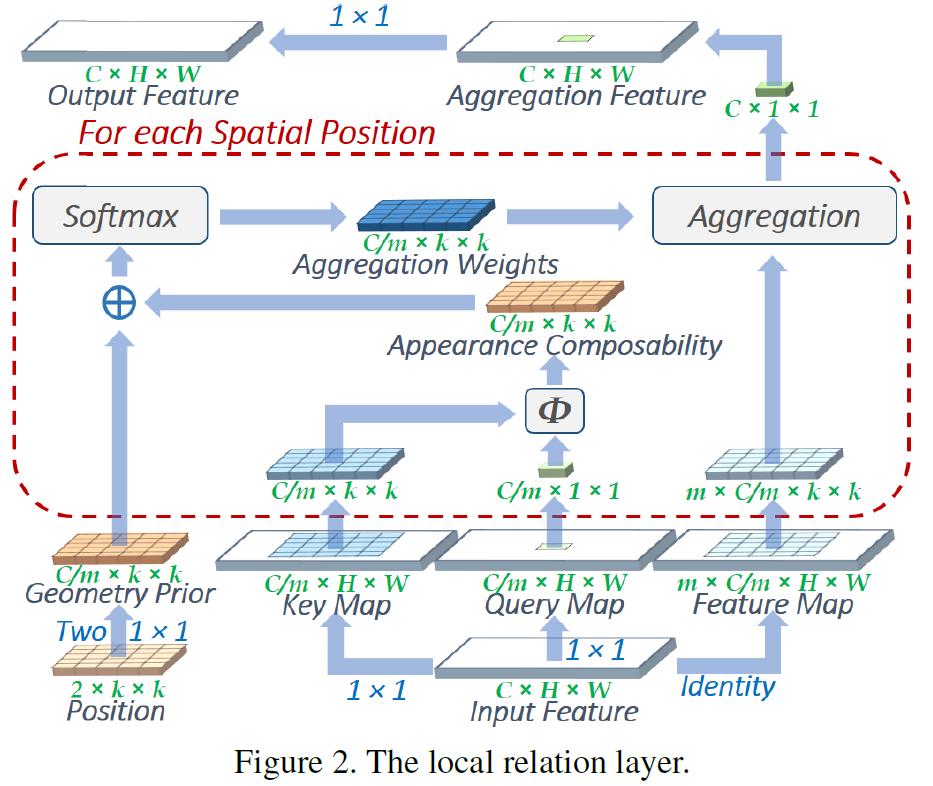
图2展示了Local Relation Layer的全部操作流程。可以看到一个Local Relation Layer有两个输入:Input Feature和Position。其中Position作者只说是相对位置,没有说明具体的计算方法,也没有注明参考文献。
首先2kk的Position经过conv11生成C/mkk的Geometric Prior。这里k表示Local Relation Layer的spatial scope的大小,也就是kernel的大小,文中推荐取7。Geometric Prior就是相对位置的Composability。
然后CHW的Input Feature经过conv11生成两个C/mHW的map(文中m推荐取8),分别叫做Key Map和Query Map。Key Map和Query Map用来计算appearance的composability,具体方法是:从Query Map取出要素p’ (C/m11),从Key Map取出p’对应感受野内的要素p (C/mkk),分别计算p’和p的差异,生成C/mkk的Appearance Composability。
将Geometric Prior和Appearance Composability相加,经过softmax标准化之后,就生成了一个C/mkk的卷积核Aggregation Weights。将该卷积核作用于Input Feature对应的位置p,就得到了Aggregation Feature对应位置p’处的值。之后对整个Aggregation Feature做conv1*1,得到最终的Output Feature。
最后解释一下为什么Output Feature和Input Feature都是C个channel的:我们得到的Aggregation Weights是C/m个channel。每个Aggregation Weights和Input Feature的作用方式与Depthwise Conv相同。相当于将Input Feature分为m个组,分别和Aggregation Weights做Depthwise Conv,每个组的in/out channel都为C/m。各个组共享相同的Aggregation Weights。所以最终输出的channel为C。
以上就是Local Relation Layer的全部操作过程。相比于传统的conv,计算过程是相当的复杂,但实际参数量还要略小,主要原因是其采用了分组共享和Depthwise策略。
Local Relation Networks
作者将ResNet的Convolutional Layer替换成了Local Relation Layer,构造了LR-Nets。没什么特别需要说明的,就贴个网络结构图吧: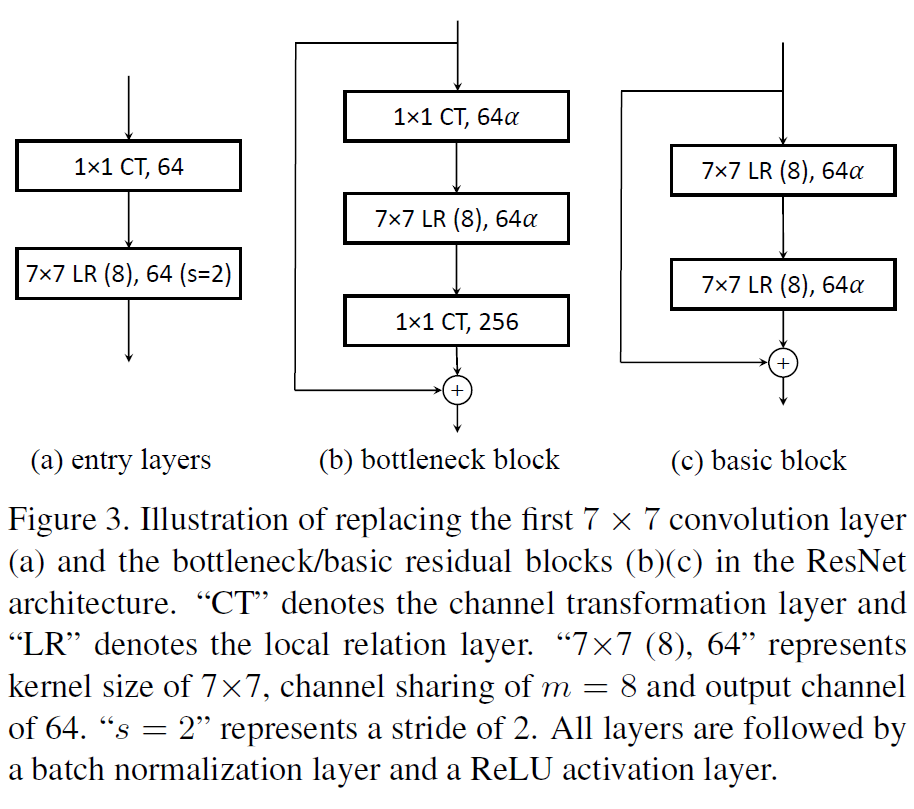
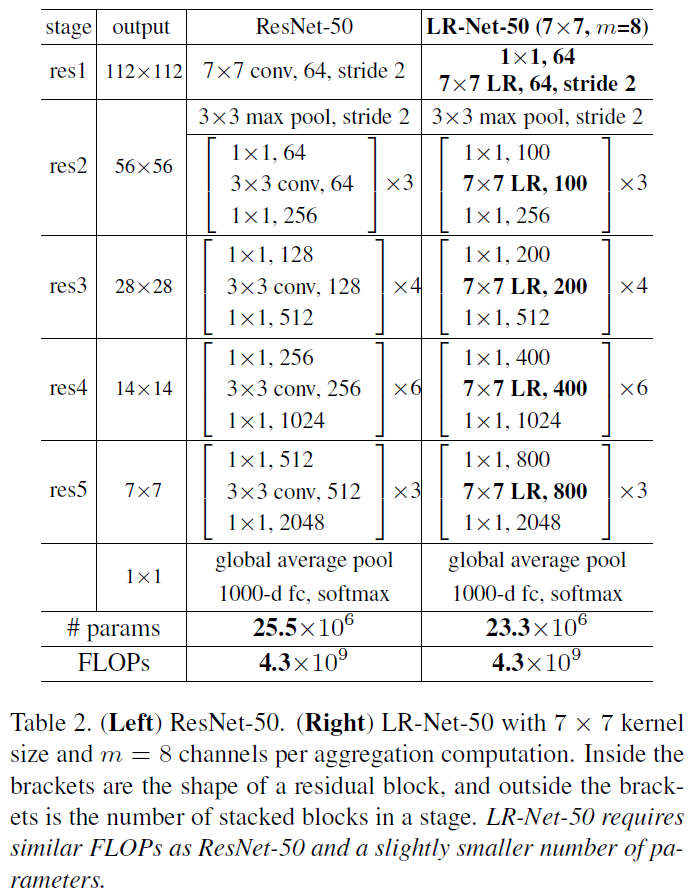
Experiments
作者做了许多Ablation Study分别验证locality、large kernel、geometric prior、channel sharing和softmax normalization等方法的有效性,也和其他方法做了对比。详细的Experiments见原文。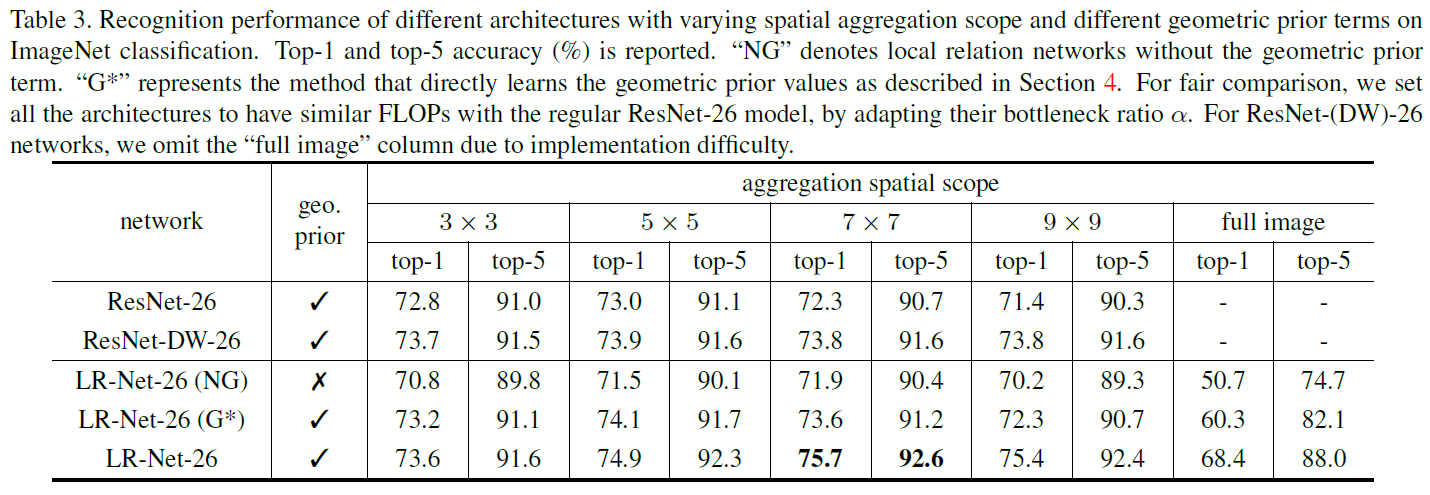
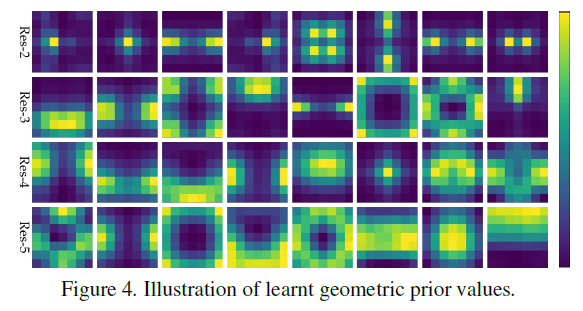

总结
这是一项非常有趣的工作,也比较难理解,让我从不同的角度认识了图像特征提取的本质。这方面的文章看得比较少,我的解读非常肤浅,甚至可能有错误的地方,欢迎大家指正。作者没有开源代码,目前还存在一些疑问,比如Position是如何计算的。
再回顾一下作者所谓的bottom-up结构,其实和Attention非常像,只不过这个Attention的计算非常复杂。如果把Local Relation Layer中的conv1*1看作普通的卷积层,其余的操作均看作Attention,好像也不是不行?

若有收获,就点个赞吧
0 人点赞
