BMVC 2018 论文标题:iCAN: Instance-Centric Attention Network for Human-Object Interaction Detection 论文地址:https://arxiv.org/abs/1808.10437 代码地址:https://gaochen315.github.io/iCAN/

简介
这是一篇经典的解决human-object interaction (HOI)任务的文章。作者提出了Instance-Centric Attention Network (iCAN),其核心模块Instance-centric attention module可以动态地根据不同的human和object生成不同的attention map,从而使human和object的特征与context信息融合,提升HOI detection精度。作者在V-COCO和HICO-DET数据集上做了实验,iCAN的精度相比于以前的SOTA模型有着显著提升。
Instance-Centric Attention Network (iCAN)
iCAN模型结构优雅,清晰易懂,作者的描述也是十分详细,应该算是HOI的经典模型之一。图3是模型的整体结构: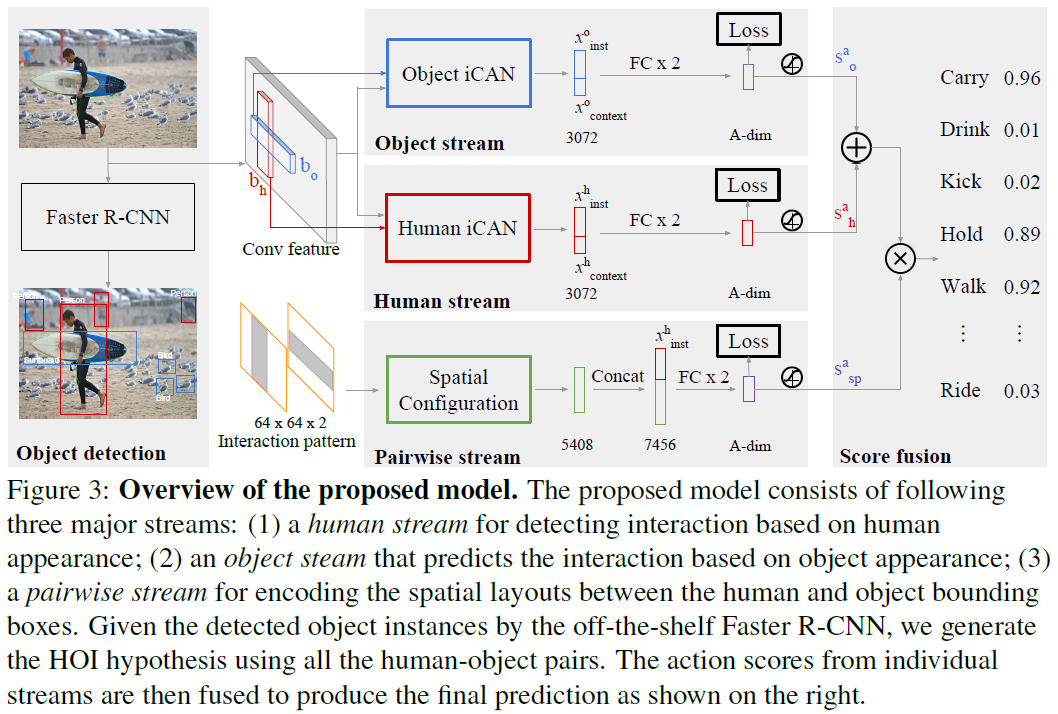
可以看到,整个模型包括三个stream,分别是object stream、human stream和pairwise stream。其中object和human stream结构相同,都以Instance-centric attention module为核心,用于提取human和object的appearance feature,同时融合context信息。pairwise stream用于提取human和object的空间位置关系特征。
iCAN以Faster R-CNN目标检测网络为基础,先检测出图像中的所有human和object,再检测其interaction,这是解决HOI任务普遍的形式。对于一个human-object pair,iCAN的三个stream都会输出interaction score,最终的score由以下公式得出: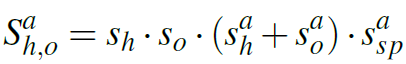
其中 是Faster R-CNN得到的human和object的目标检测score,
是Faster R-CNN得到的human和object的目标检测score, ,
, 和
和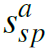 分别是human,object和pairwise stream输出的interaction score。这是一个multi-class的分类问题,每一个action都有独立的score。
分别是human,object和pairwise stream输出的interaction score。这是一个multi-class的分类问题,每一个action都有独立的score。
Instance-centric attention module
本文最主要的contribution就是这个模块,图4是其结构图: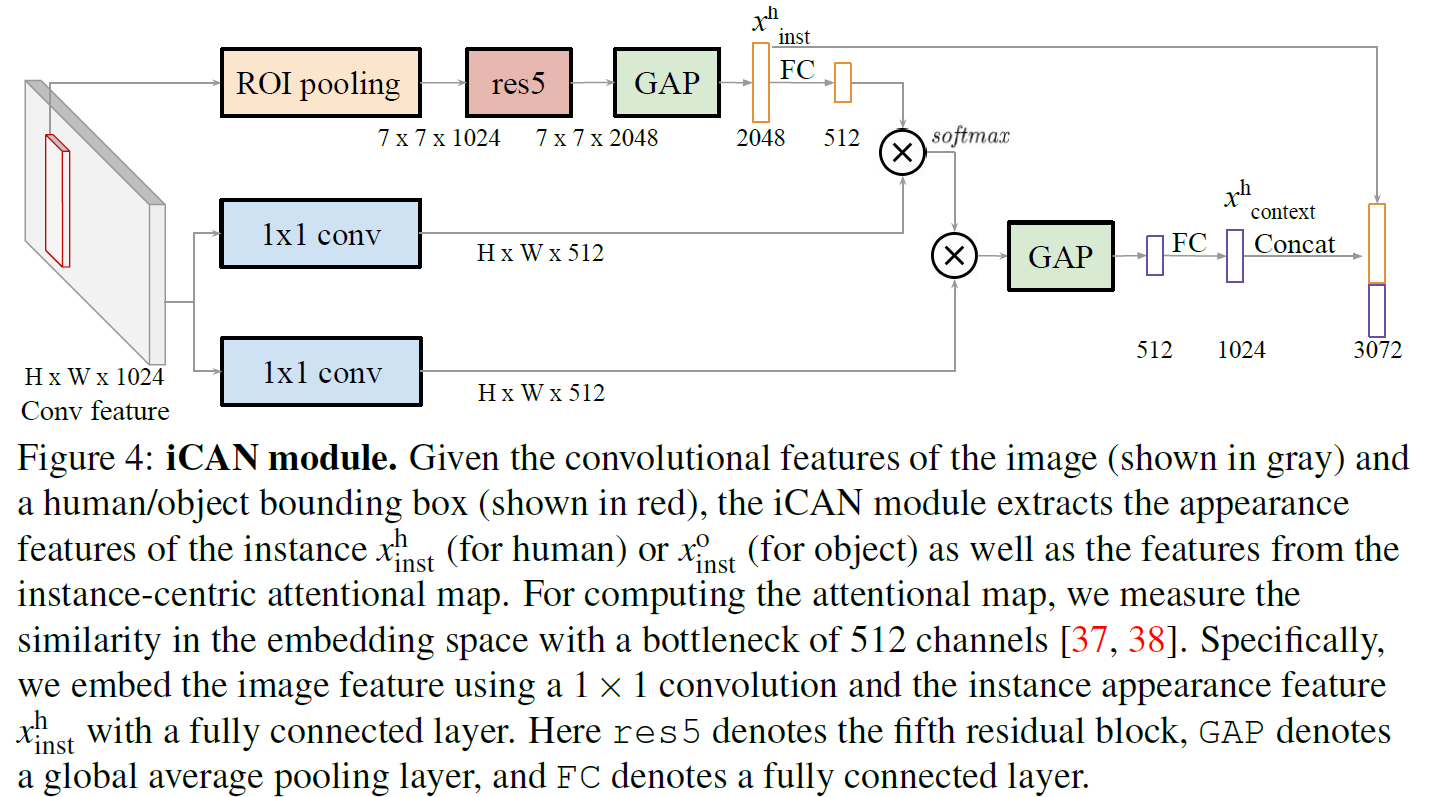
以human为例,将bounding box内的feature经过ROI pooling + res block + global average pooling之后,得到2048维的特征向量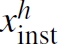 ,再经过全连接层降维到512维。同时,利用11 conv将全局的feature map也转换成HW512维的feature map。之后对二者进行pointwise的向量点积运算,再经过softmax得到WH1的attention map。将attention map作用于HW*512维的全局feature map,再global average pooling + FC得到1024维的context特征向量
,再经过全连接层降维到512维。同时,利用11 conv将全局的feature map也转换成HW512维的feature map。之后对二者进行pointwise的向量点积运算,再经过softmax得到WH1的attention map。将attention map作用于HW*512维的全局feature map,再global average pooling + FC得到1024维的context特征向量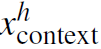 。最后将与concat起来,得到对于这个human最终的3072维feature。对于object亦是如此。
。最后将与concat起来,得到对于这个human最终的3072维feature。对于object亦是如此。
这个模块结构清晰简单,也很有效。其核心目的是利用attention在全局feature map中找到human或object对应的context信息,将context信息融合到human或object的特征中。
Object/human stream
以上得到了human或object的feature,再经过两个全连接层,然后sigmoid激活输出interaction score。这就是object/human stream。
Pairwise stream
Pairwise stream用于编码human和object的空间位置关系,同时提取位置关系特征。大致方法是分别对human和object的bounding box生成两个二值图像,bounding box内取1外取0,得到2 channel的mask。然后用CNN在这个mask上提取feature。最后将提取的feature和human的appearance feature concat起来,得到7456维的特征向量。然后经过两个全连接层+sigmoid激活输出interaction score。
最后说明一点,iCAN的主要框架是late fusion的,也就是说三个stream用自己的feature分别给出score之后,直接将score相加或相乘得到最终的score。这样late fusion的形式显著减小了计算量,因为对于human和object的feature,不必将其两两组合,而是各自计算各自的。作者还提出了一种early fusion的形式,即直接将3个feature融合,再进行score计算。在实验中early fusion可以提升精度,但效率比较低。
Experimental
作者在V-COCO和HICO-DET数据集上做了实验,iCAN模型的表现相比于以前的模型有着显著提升。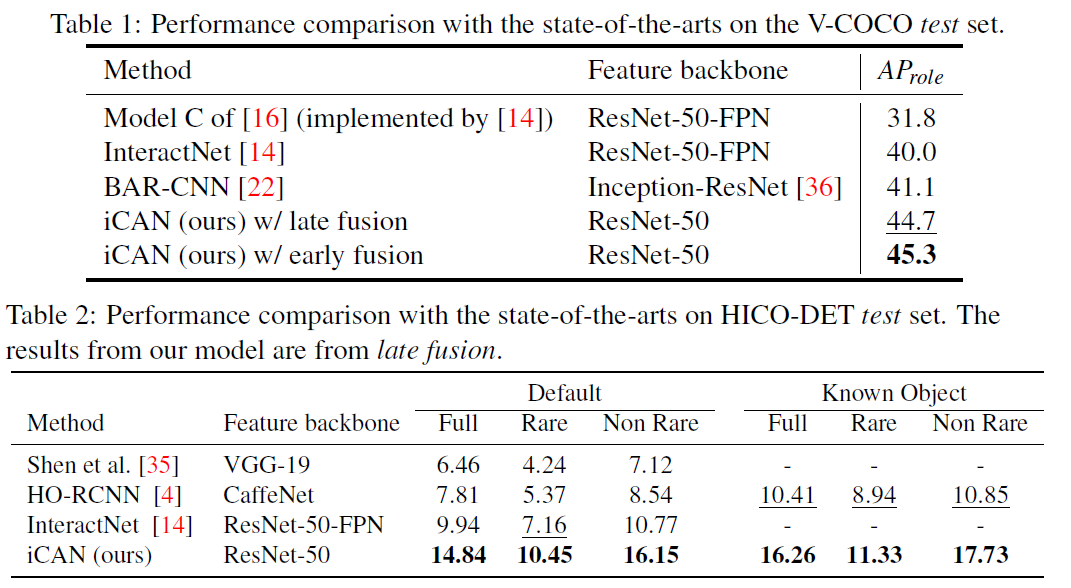



总结
简洁,高效,优雅,经典的iCAN!后续很多CNN based HOI detection工作都是在其基础上改进的。

若有收获,就点个赞吧
0 人点赞
