ICCV 2019 论文标题:Dynamic Graph Attention for Referring Expression Comprehension 论文地址:https://arxiv.org/abs/1909.08164v1

简介
Referring Expression Comprehension任务是指在图像上将自然语言描述的目标定位出来。本文针对此任务提出了一种语言文本处理驱动的图像内容理解模型Dynamic Graph Attention Network (DGA)。具体方法为:
1.对图像中的目标构建dynamic graph
2.利用multi-step的自然语言处理过程,生成动态的graph attention
3.利用attention在graph上进行multi-step的信息聚合与更新
4.分别计算目标feature与语言描述的match score,得到最佳的匹配结果
总的来说,这是一篇CV+NLP交叉的文章,模型较为复杂,也有值得借鉴的思路。
Dynamic Graph Attention Network
本文的核心内容是DGA网络,而DGA网络的关键又在于Dynamic。作者通过复杂的步骤和子模型实现了在expression解析的基础上生成dynamic graph attention,从而让expression指导graph的信息聚合和更新过程,达到了文本信息和图像信息综合利用的效果,这也是符合人类的认知过程的。作者给出这样一个例子:当我们看到一句话”the umbrella held by the person in the pink hat”和对应的一张图(图1),我们要在图中找出语句所描述的内容。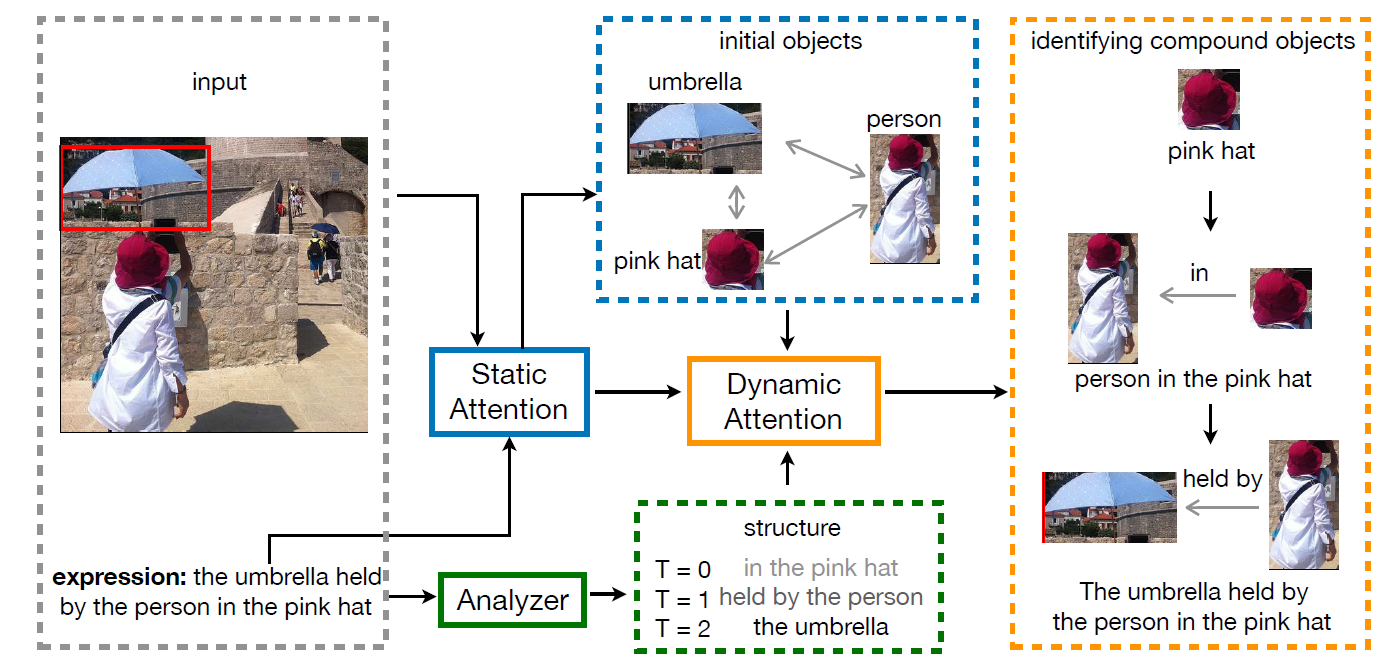
首先,我们注意到的是”the pink hat”,然后再找到pink hat下对应的” the person”,最后找到这个person拿着的”the umbrella”,从而确定了语句描述的目标就是这个umbrella。可以看到,人在处理这个任务的时候其实也是dynamic attention和multi-step的,并且是文本信息和图像信息综合使用的,这也就是本文的灵感来源吧。
图二展示了DGA网络的整体结构,图中反映的最有用的信息就是这个模型是multi-step的,并且是graph的处理和expression的处理并行的,它们之间存在信息的交互。下面分模块介绍DGA网络:
Language-Guided Visual Reasoning Process
这一部分是DGA网络的NLP模块,输入是长度为L的referring expression的单词序列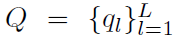 ,输出是当前step下words的soft distribution
,输出是当前step下words的soft distribution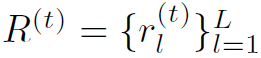 ,和当前step下referring expression的综合特征
,和当前step下referring expression的综合特征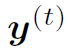 。其中
。其中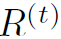 表示t step时,不同words的权重,可以看做words的attention。例如前面的例子,第一步时”hat”权重很高,第二步时”person”权重很高。是t+1 step输入的一部分。整个的处理过程如下:
表示t step时,不同words的权重,可以看做words的attention。例如前面的例子,第一步时”hat”权重很高,第二步时”person”权重很高。是t+1 step输入的一部分。整个的处理过程如下:
1.将单词序列转换为词嵌入序列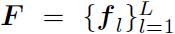 。
。
2.用bi-directional LSTM模型处理,得到encode后的序列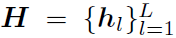 ,其中
,其中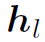 是正向和反向output的concat。同时,将正反向的最后一个hidden state进行concat,得到expression序列的整体表达
是正向和反向output的concat。同时,将正反向的最后一个hidden state进行concat,得到expression序列的整体表达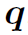 。
。
3.通过以下公式计算multi-step的和: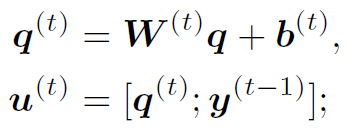
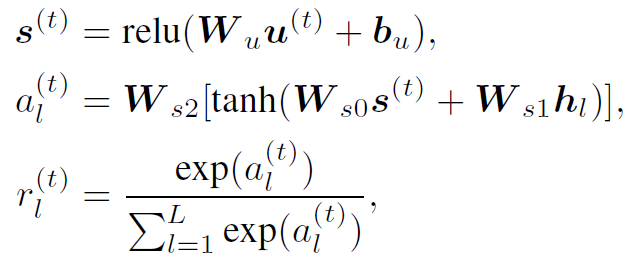
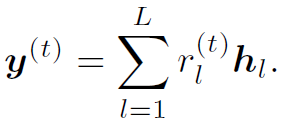
大概可以这样理解:通过expression的整体表达和局部表达的某种关系生成words的权重,再加权求和得,进入下一个step。这里的step需要注意一下,是指reasoning的step,每个step都是图像和文本交互处理的。
Static Graph Attention
这部分包含了graph的构建以及Static Attention,先来看graph construction。
作者利用Faster R-CNN的RPN网络提取K个object proposal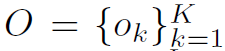 作为K个node。每个node的feature用
作为K个node。每个node的feature用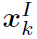 表示,由visual feature和spatial feature组成。其中visual feature就是RPN网络提取出的feature map。spatial feature定义为
表示,由visual feature和spatial feature组成。其中visual feature就是RPN网络提取出的feature map。spatial feature定义为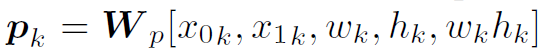 ,就是目标的中心坐标、宽高和面积。对于目标间的位置关系,作者将其定义成11类,用
,就是目标的中心坐标、宽高和面积。对于目标间的位置关系,作者将其定义成11类,用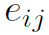 表示,每个数字代表一种位置关系(注意,这里的数字只是为了区分不同位置关系,如“左上”、“右下”等,没有数量含义。具体看原文)。这样,每两个目标间就能确定一种位置关系。
表示,每个数字代表一种位置关系(注意,这里的数字只是为了区分不同位置关系,如“左上”、“右下”等,没有数量含义。具体看原文)。这样,每两个目标间就能确定一种位置关系。
再来看Static Attention。作者先将expression的所有words分为两类:entity & relation,通过以下公式计算出每个word的类别概率: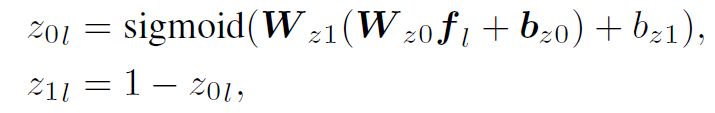
然后计算expression中每个word在不同node上的static attention: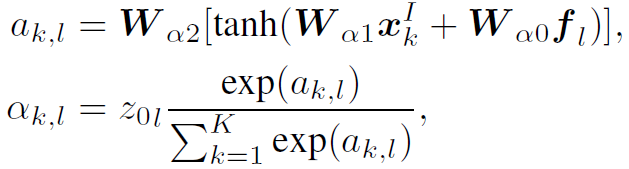
其中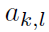 表示第l个word在第k个node上的static attention。式中
表示第l个word在第k个node上的static attention。式中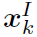 是node的feature。
是node的feature。
对所有words加权和,就得到了每个node的static attention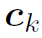 :
: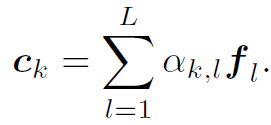
作者还定义了expression中每个word在不同位置关系上的static attention: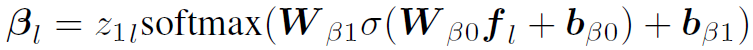
这里的softmax函数的输出为11个权重,因为node间存在11种不同的位置关系。
然后我们对node的feature进行更新,由变为 :
: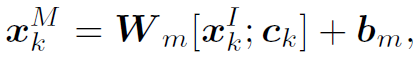
Dynamic Graph Attention
这部分本质是GCN的迭代过程,作者在这里定义了graph的信息聚合和更新函数。和传统GCN迭代不同的是,本文DGA迭代的过程中,是有NLP模块参与的,也就是作者所说的:网络对expression的逐步解析指导着对图像的理解。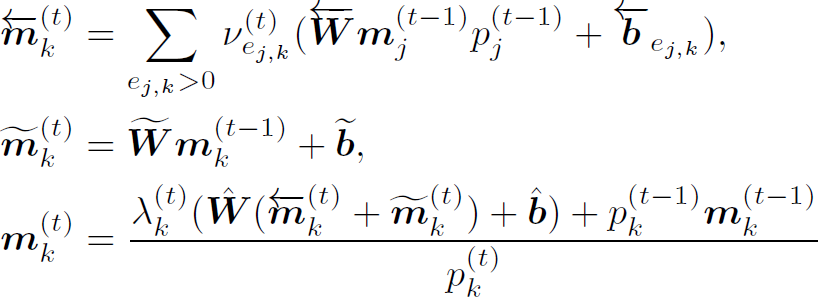
上式中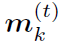 表示t step时第k个node的feature。
表示t step时第k个node的feature。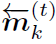 和
和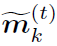 分别表示对邻接node feature的聚合(也就是message)和对自身node feature的更新。式中存在两处dynamic attention:
分别表示对邻接node feature的聚合(也就是message)和对自身node feature的更新。式中存在两处dynamic attention: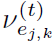 和
和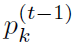 ,分别用下式计算:
,分别用下式计算: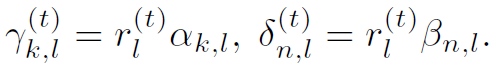
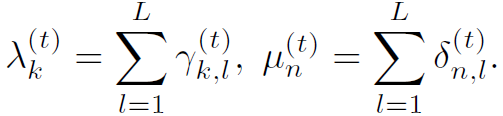
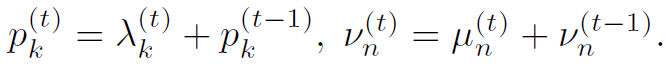
式中有很多中间变量,原文中也给出很多解释。但我感觉越解释越乱,只需要明白:表示node k的weight,表示node j和node k之间位置关系的weight,在graph中其实就是邻接权重。这两个weight在计算过程中都与NLP产生的中间变量有关,这就造成了graph的聚合更新与NLP过程有关,作者将这套规则称为Dynamic Graph Attention。
Matching
在DGA进行了T个step的迭代之后,取第T个step各node的feature 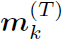 与expression的整体表达,计算其match score:
与expression的整体表达,计算其match score: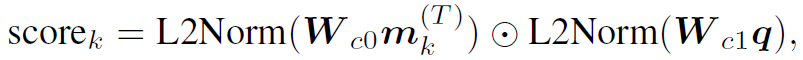
式中L2Norm表示L2归一化,其可以将向量元素转换到[0, 1]范围内。⊙表示向量内积。
match score最高的node所代表的object就是这个referring expression所描述的object,而这个object的位置已经由RPN网络得到了,这样就解决了Referring Expression Comprehension任务。
最后要补充一下DGA的loss函数。作者使用了triplet loss: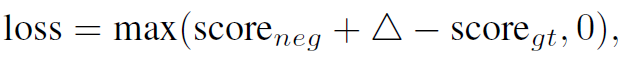
其中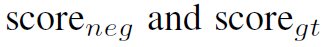 分别是负样本的score和ground truth的score,
分别是负样本的score和ground truth的score, 是一个margin参数。
是一个margin参数。
Experiments
作者在RefCOCO、RefCOCO+和RefCOCOg三个数据集上测试了算法,都取得了SOTA的效果: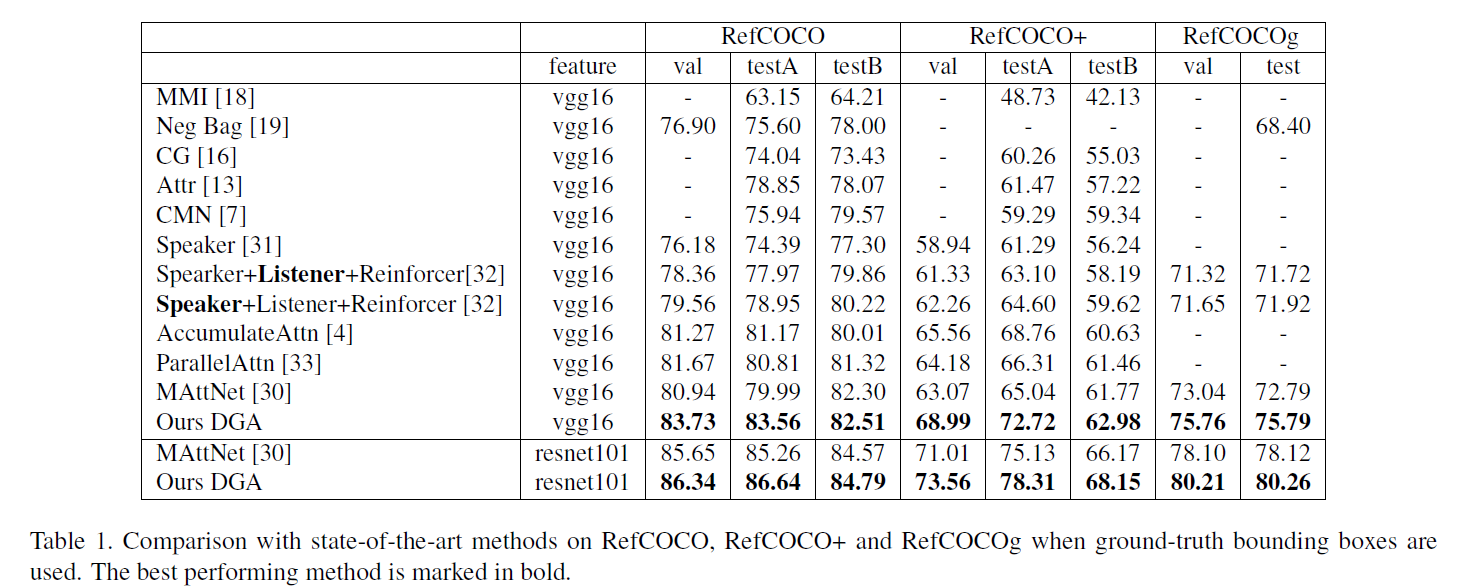
另外,模型的各种attention都是visualizable的,这也是本文的contribution之一:interpretable & visualizable。从下图我们可以看出,整个DGA网络的multi-step过程确实也是其对图像和文本深入理解的过程。作者设计的网络结构看似玄学,但起到的效果却是刚好符合设计初衷的。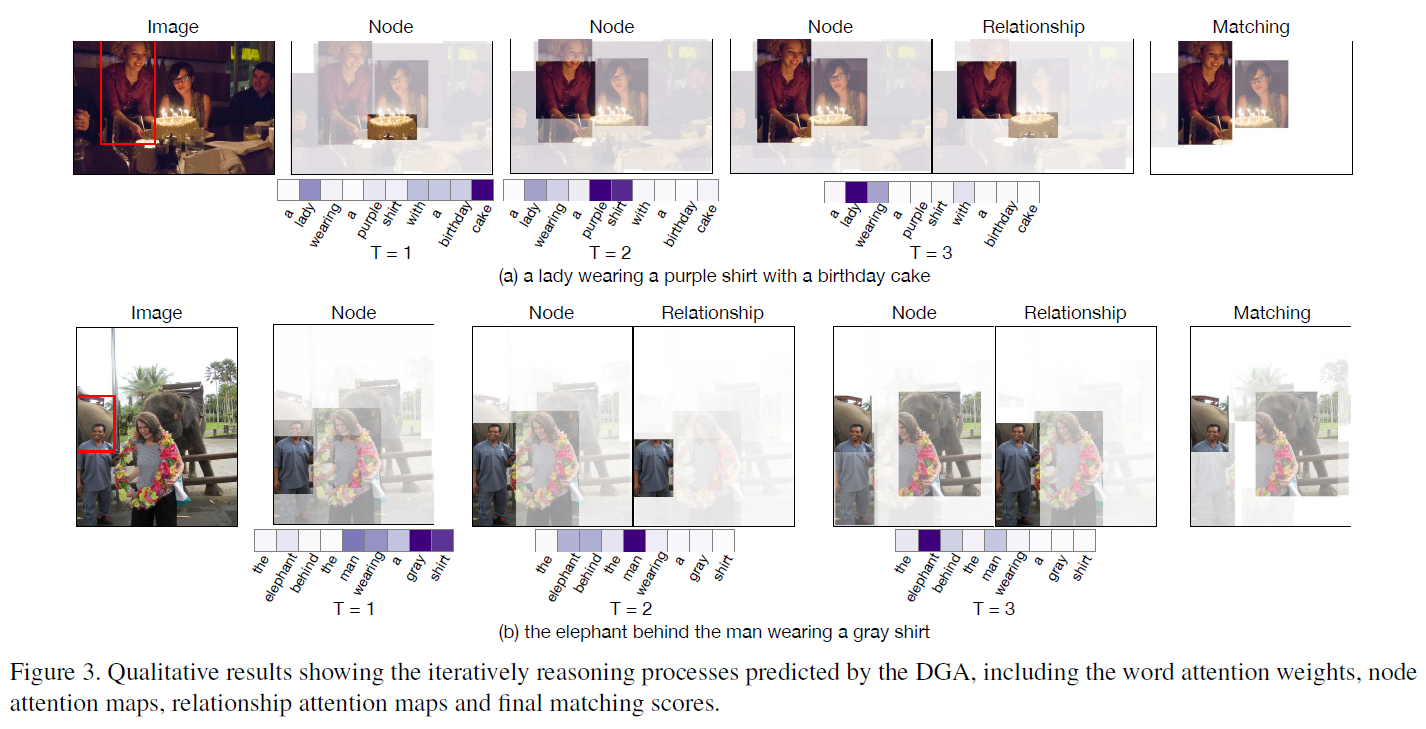
总结
别再遇事不决量子力学了,直接遇事不决attention就好了!
CV+NLP+CNN+LSTM+GCN+attention,这篇文章真是集大成,但总感觉缺少了一些简约之美,甚至在阅读的过程中我需要不断返回去找各个变量的含义。要是再对模型的局部加几张图示,或者加一个变量名的汇总表格,肯定会更方便阅读。总之GCN和attention在图像或视频内容理解方面还是大有可为的。

若有收获,就点个赞吧
0 人点赞
