ICCV 2019 论文标题:Relation Parsing Neural Network for Human-Object Interaction Detection 论文地址:http://openaccess.thecvf.com/content_ICCV_2019

简介
本文提出了一种解决human-object interactions (HOI)任务的神经网络,名为Relation Parsing Neural Network (RPNN),其本质是改进的GCN结构。相比于ECCV2018的GPNN,本文的GCN将graph的node拓展到了人身体的不同part (head, hand, hip, leg),也就是说将body parts与objects一起构建graph,使graph获得更强的信息表示能力。另外,RPNN结构中包含两个相互配合的GCN:Object-Bodypart Graph和Human-Bodypart Graph。后者通过action passing利用前者refine之后的Bodypart特征对自身的Bodypart特征做初始化,从而更好地学习human的action。但同时,本文的RPNN结构和信息聚合更新规则是比GPNN简单许多的。最后,在数据集HICO-DET和V-COCO上,该结构取得了SOTA的效果。
Mask R-CNN与human parts检测
本文核心的RPNN结构用到了human的不同parts,也就是需要提前得到human的key points,不能只是简单地做目标检测。目前的Keypoint Estimation分为top-down methods和bottom-up methods,作者选择了用Mask R-CNN检测人体key points,应该算是一种top-down method(对于Keypoint Estimation任务我还不是很了解,作者使用的Mask R-CNN主要目的还是目标检测,但也能完成key points检测的任务,可能还是出于效率考虑)。下面简单介绍一下Mask R-CNN,具体请看这篇博客。
Mask R-CNN是在Faster R-CNN上的改进,在原本的两个分支上(分类+坐标回归)增加了一个分支进行语义分割(或key points检测),网络结构如下: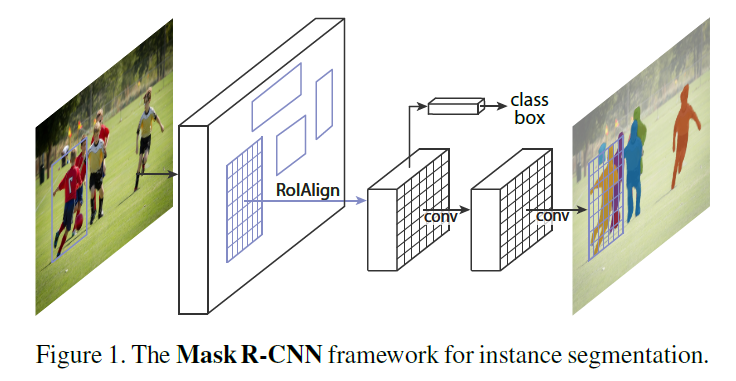
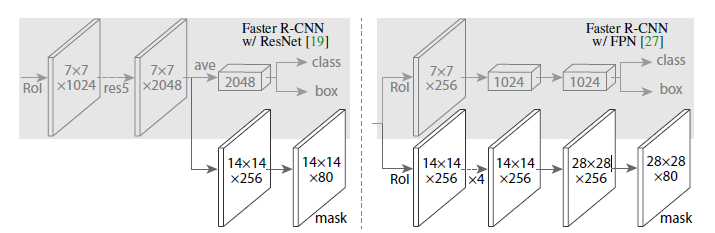
Mask R-CNN的主要贡献点在于多任务网络结构的设计、多任务loss的设计和ROI Align方法。可以在目标检测的同时,利用共享的feature完成其他任务。本文利用Mask R-CNN进行目标检测和人体key points检测。但获得了key points之后,也仅是获得了关键点的坐标位置,如何提取human parts的feature,作者采用如下方法。
作者将human parts分为四个部分:head, hand, hip和leg。其中head包括鼻子、左右眼和耳朵;hand包括了左右手、关节和胳膊;hip包括了左右臀部和膝盖;leg包括了左右脚踝。每一个parts的bounding box用以下公式计算:
其中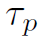 是经验上人体不同parts占人体的比例,文中采用0.2,0.2,0.25,0.25分别对应head, hand, hip和leg。
是经验上人体不同parts占人体的比例,文中采用0.2,0.2,0.25,0.25分别对应head, hand, hip和leg。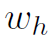 和
和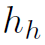 是人体的总宽高。这样就确定了不同parts的bounding box,以便在feature map上找到相应的区域提取特征。
是人体的总宽高。这样就确定了不同parts的bounding box,以便在feature map上找到相应的区域提取特征。
这种方法对parts的定位其实是非常粗略的。但在HOI任务中,可能并不需要精确定位。因为提取出的human parts特征还要进入GCN进一步refine。同时,粗略的bounding box也可能包含更多有用的信息。
以上就是本文的基础部分,利用Mask R-CNN检测出object和human,以及human parts之后,提取出相应的feature,为RPNN做准备。最后注意一点,Mask R-CNN检测key points是在目标检测的基础上的,也就是针对每一个human个体(ROI)都会计算一次mask,检测key points,所以可以适用于图像中有很多人的情况。
Relation Parsing Neural Network (RPNN)
下面介绍核心网络RPNN,结构图如下:
从图中可以看出,RPNN有两条线路:第一条(下)是ObjectBodypart Graph,第二条(上)是HumanBodypart Graph,两个GCN都由2 layers组成。其中HumanBodypart第一层中输入的parts feature来自于ObjectBodypart第二层,即refine后的parts feature。
ObjectBodypart Graph
ObjectBodypart Graph的node包括了图像中的object和human的所有parts。既然是graph,那必然少不了邻接矩阵。在ECCV2018的GPNN中,邻接矩阵完全从features提取而来,得到的是一个完全图。但在本文RPNN中,实际上对邻接矩阵作出了更强的约束。对于object和bodyparts,连通的node就只有object和所有的bodyparts,也就对应了网络结构图上ObjectBodypart Graph的结构,所有的parts (head, hand, …)都与object (Frisbee)连接,但parts之间无连接。
那么连接的权重如何计算呢?作者给出了Object-Bodypart Attention公式,本质为GCN的Link Function: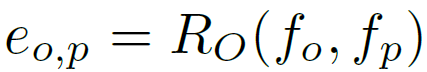

其中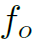 和
和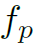 分别为object和part的feature。
分别为object和part的feature。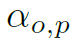 为邻接矩阵在(o,p)处的值,即某一个object和某一个part之间的连通权重,作者称之为Attention。
为邻接矩阵在(o,p)处的值,即某一个object和某一个part之间的连通权重,作者称之为Attention。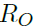 是多层感知机(MLP),结构是全连接+leakyReLU激活(FC(4096 × 256)-FC(256 × 1))。用以上公式,就可以得到ObjectBodypart Graph的邻接矩阵,也就是GCN上信息的传播规则,下面来看信息的聚合和更新规则。
是多层感知机(MLP),结构是全连接+leakyReLU激活(FC(4096 × 256)-FC(256 × 1))。用以上公式,就可以得到ObjectBodypart Graph的邻接矩阵,也就是GCN上信息的传播规则,下面来看信息的聚合和更新规则。
RPNN中node信息的聚合和更新规则实际上是非常原始和简单的,公式如下: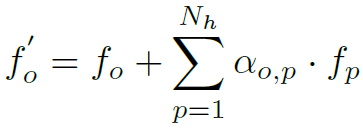
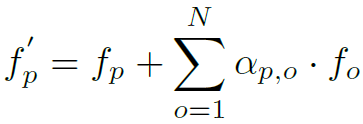
就是node本身加上邻接nodes的加权和,甚至连归一化和非线性激活都没有,大道至简。
HumanBodypart Graph
HumanBodypart Graph的node包括了整个human、整个图像(scene)和单个human的所有parts。其中human和scene的feature都来源于图像提取出的feature map,而parts的feature来源于refine后的ObjectBodypart Graph。个人理解:第一,这样做可以避免human的feature和parts的feature产生重复。第二,refine后的parts feature聚合了objects的信息,相当于把objects的高层特征也拿来使用了,对预测action肯定是有帮助的。HumanBodypart Graph的邻接矩阵计算公式如下: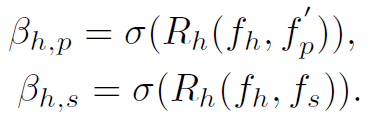
与ObjectBodypart Graph差不多,只是添加了sigmoid激活,取消了softmax操作。也是用全连接操作去计算邻接矩阵相应位置的权重。
聚合和更新规则也和ObjectBodypart Graph一样,只是在HumanBodypart Graph中更新human的特征,而在ObjectBodypart Graph中更新的是objects和parts的特征: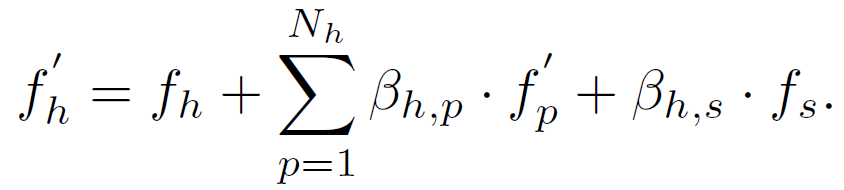
两路Graph都只有2层layer,最后ObjectBodypart Graph是用refine后的human feature经过全连接输出human action和与这个action相对应的target object的location。HumanBodypart Graph是用refine后的object feature经过全连接输出该object与human进行interaction的score。
Outputs
在以上的RPNN中,可能存在多个object nodes,也就是图像上可能检测到很多objects。但我们认为对于一个确定的human h与action a只与一个object进行interaction。最终如何筛选出最好的object呢?作者用以下公式: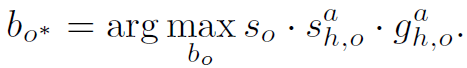
其中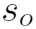 是目标检测时object的score,
是目标检测时object的score, 是ObjectBodypart Graph输出的interaction的score,
是ObjectBodypart Graph输出的interaction的score,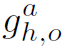 是object的目标检测框
是object的目标检测框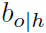 和HumanBodypart Graph预测框
和HumanBodypart Graph预测框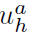 的相似度,计算公式如下,文中σ取0.3:
的相似度,计算公式如下,文中σ取0.3: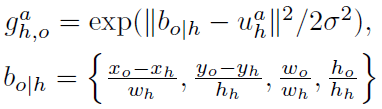
通过以下公式计算针对一个human h,action a和object o的HOI score: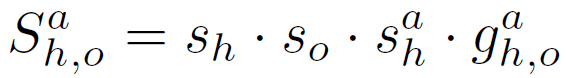
总结一下:RPNN的所有输出中,只有
是用于HOI分类的softmax输出,而只是一个score衡量这个object是否与human交互,并没有HOI分类作用。
上述总结是错误的,第一次看论文时理解有误,很抱歉。一般来讲,图像中一个human可能与多个object有多种action,例如人坐在沙发上用手机打电话就包含两个和在InteractNet中是同等地位的action score,是对的改进,而本文处理的有点混乱。
Experiments
作者在HICO-DET和V-COCO数据集上进行了实验: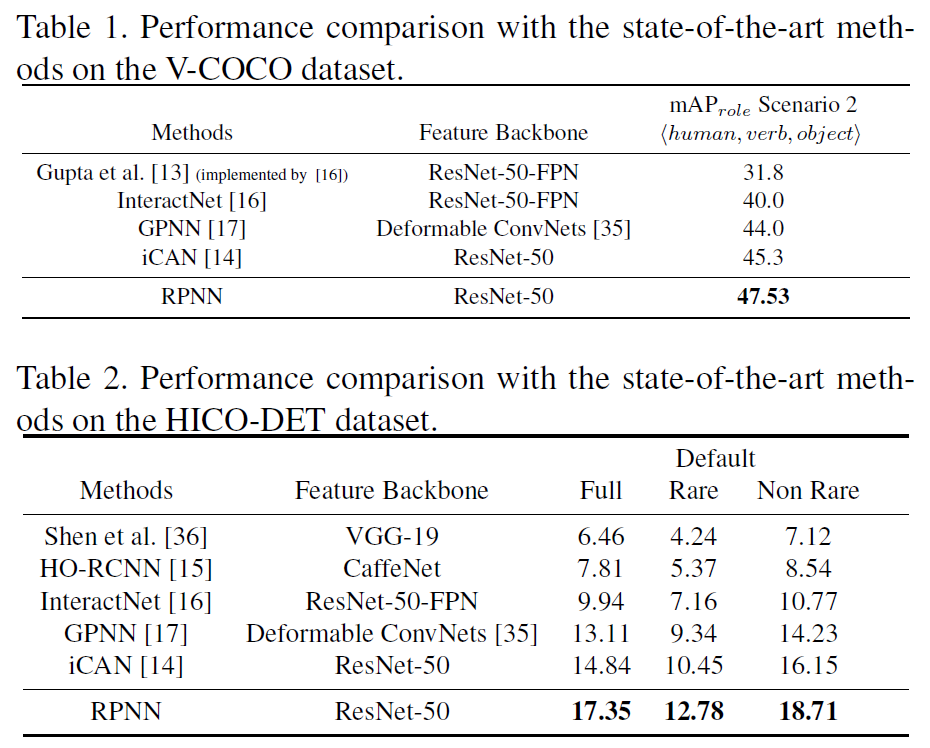

从图3和图4中可以看出,ObjectBodypart Graph和HumanBodypart Graph确实能起到Attention的作用:图3展示了与object相关的human part被赋予更高的邻接权重;图4展示了在HOI中越重要的part,被赋予更高的权重。这也是RPNN中最为重要的contribution!
总结
本文提出的RPNN的巧妙之处在于将human拆分成不同的parts,并利用GCN实现了一个part attention的效果。从直观上去理解,在HOI任务中,人与物的交互确实是存在attention的,例如用手和头吃饭,用脚踢球,不同的交互会用到不同的parts,这也是识别HOI的关键特征。文中RPNN里的两个GCN的结构都非常简单,或许还有一定的改进空间,如加深layer,构造更复杂的聚合和更新函数等。

若有收获,就点个赞吧
0 人点赞
