ICCV 2019 论文标题:Deep Contextual Attention for Human-Object Interaction Detection 论文地址:https://arxiv.org/abs/1910.07721

简介
现有的human-object interaction detection模型在提取human和object特征的时候,往往只关注其appearance信息,而忽略了context信息。为解决这一弊端,本文提出了Contextual Attention模型。Contextual Attention模型可以自适应地学习图像中实体的context信息,让网络聚焦于重要的语义区域。作者在V-COCO、HICO-DET和HCVRD数据集上进行测试,Contextual Attention的表现优于其他SOTA模型。
Overall Framework
本文中的HOI detection模型整体是two stage的,即先进行object detection,再进行interaction recognition。这种two stage结构也是目前解决HOI任务的主流结构。对于object detection,本文采用了FPN网络(简单介绍),这里就不详细介绍了。另外,本文的模型用到了WACV2018的这篇文章中的Parwise Stream,需要先简单了解一下。
下面是网络整体的结构图: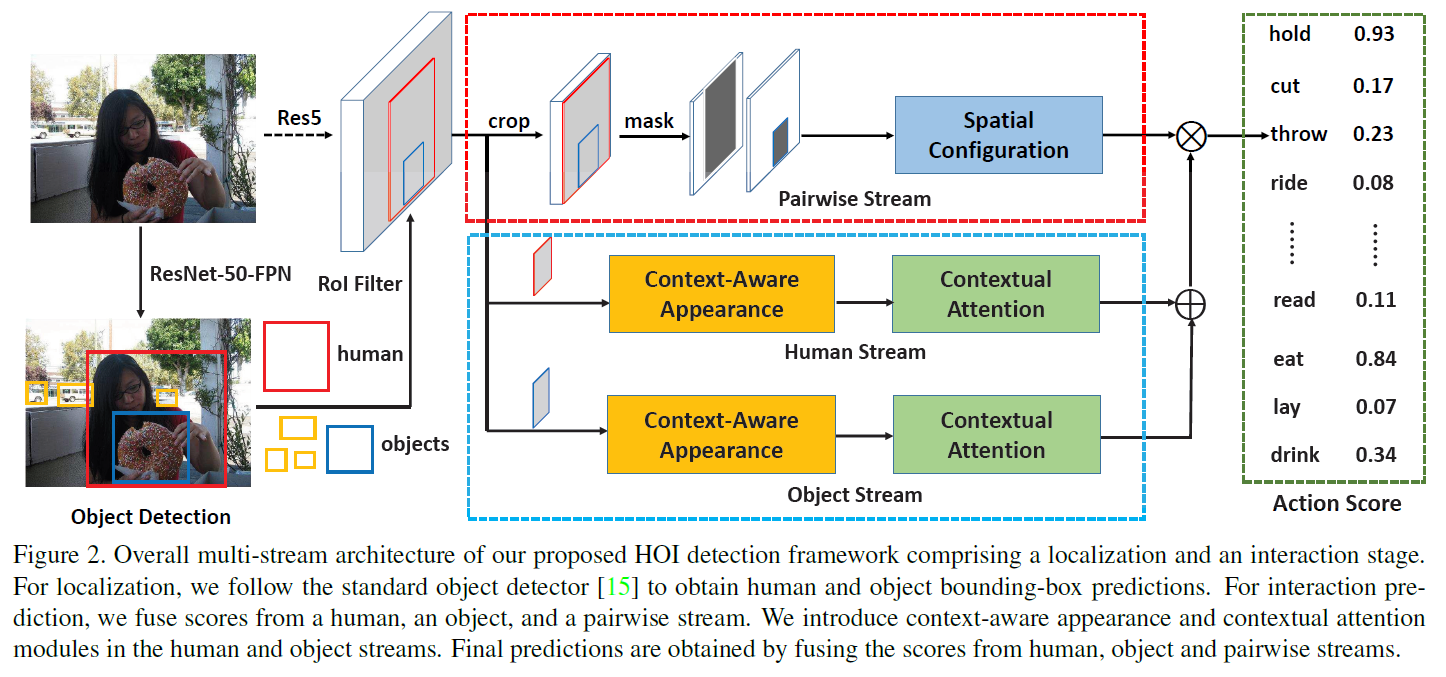
可以看到,在ResNet50-FPN目标检测和特征提取的基础上,作者设计了Contextual Attention模型。Contextual Attention模型有三个stream,分别是Pariwise Stream、Human Stream和Object Stream。其中Pariwise Stream与WACV2018那篇文章完全相同,作者在文中没有详细介绍。我大概补充一句:Pariwise Stream模型用于对HOI中human和object的相对位置关系建模(例如划船,人在上船在下)。大致思想是用一个2 channel的mask分别表示human和object的位置,mask中1表示前景,0表示背景。再对这个mask进行conv、pooling等操作提取特征并得到一个action分类的score。
本文的核心contribution全部在Human Stream和Object Stream上,后文详细说明。这里还需要注意一点,Contextual Attention模型的三个stream各自都会得到一个score,用于分类action。最终的action score是将Human Stream和Object Stream的score相加,再与Pariwise Stream的score相乘得到的。
Human/Object Stream
Human/Object Stream结构是相同的,只是部分输入不同。显然Human Stream以human的feature为输入,Object Stream以object的feature为输入,两者还有个共同的输入是global feature。下面是其结构图: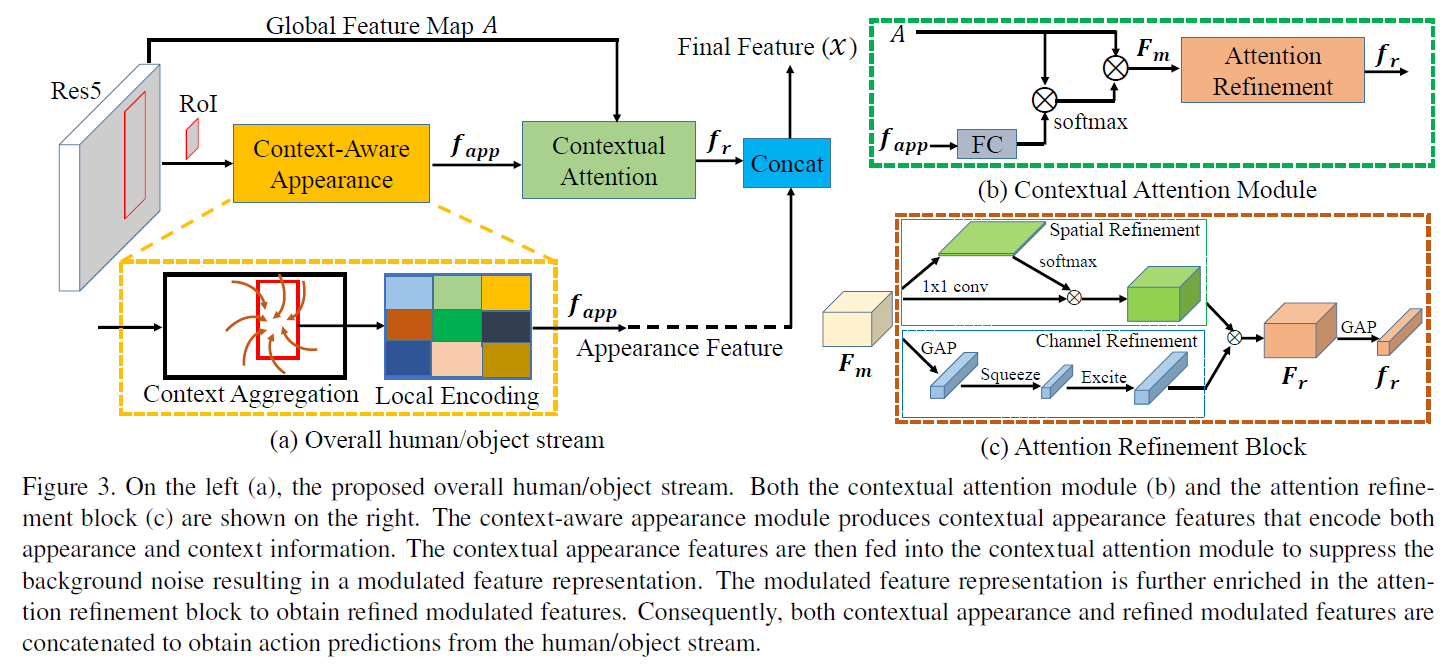
左边(a)是Stream的整体结构。可以看到,这个Stream在ROI的基础上,先对region feature进行Context Aggregation,再进行Local Encoding得到聚合了context信息的特征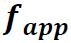 。然后将
。然后将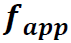 与global feature一起输入Contextual Attention结构,得到attention后的特征
与global feature一起输入Contextual Attention结构,得到attention后的特征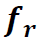 。最后将与concat起来,作为这个human或object最终的feature x。x就可以直接用于分类action了。分开来说:
。最后将与concat起来,作为这个human或object最终的feature x。x就可以直接用于分类action了。分开来说:
Context Aggregation的目的是让region feature融合其周围区域的特征,以获得更大的感受野和更多的context信息。作者这里用到了large convolutional kerne (LK) 方法,参考这篇CVPR2017论文。
Local Encoding的目的是让模型在提取特征的同时,保持位置的敏感性。作者这里用到了R-FCN中的position sensitive conv和position sensitive pooling,参考NIPS2016 R-FCN论文。
Local Encoding之后的feature map是hwcout的,并不是一个向量。这里作者直接将feature map进行flatten,再通过一个全连接操作得到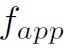 。
。
以上内容涉及两篇相关的参考文献,完全理解需要先阅读参考文献。
Contextual Attention
右边(b)是Contextual Attention结构的详细说明,其又包含了一个Attention Refinement模块。Contextual Attention是本文的核心模型,同样分开来说:
Contextual Attention的输入包括了和global feature A,整体的思想是利用和global feature A生成global feature A自身的attention,最后生成attention后的feature  。motivation在于global feature A中蕴含了很多有用的context特征,但也有很多没用的噪声会影响模型精度,因此作者用Contextual Attention模型在global feature A中提取有用的全局context信息。
。motivation在于global feature A中蕴含了很多有用的context特征,但也有很多没用的噪声会影响模型精度,因此作者用Contextual Attention模型在global feature A中提取有用的全局context信息。
第一步是将全连接之后的与A进行element wise的相乘。这里A是一个hwc的矩阵,而是一个向量,所以需要对进行expand。便于理解,可以将看作一个11的卷积核,对A进行pointwise的卷积操作,输出hw*1的feature map。得到的feature map再经过softmax函数,生成一个spatial域的attention。
第二步是将得到的spatial的attention再与A进行element wise的相乘,得到attention后的A,也就是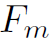 。一二两步的公式表达如下:
。一二两步的公式表达如下: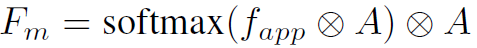
Attention Refinement
以上两步利用对A作了第一次attention。接下来还有两次,也就是Attention Refinement:
Attention Refinement分别在spatial域和channel域对进行refine。spatial域就是利用11 conv将转换为hw*1的feature map,再softmax生成attention。channel域就是将global average pooling之后,经过两个全连接,再sigmoid生成attention。其中全连接之间用Relu激活。Attention Refinement的公式如下: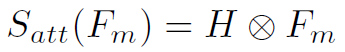
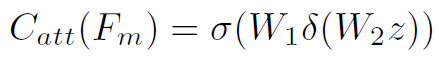
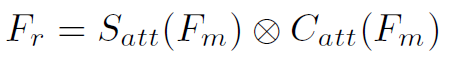
将得到的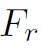 经过global average pooling后得到特征向量。这里作者称为refined modulated feature。
经过global average pooling后得到特征向量。这里作者称为refined modulated feature。
最后将与concat起来,就得到了final representation x。
Experiments
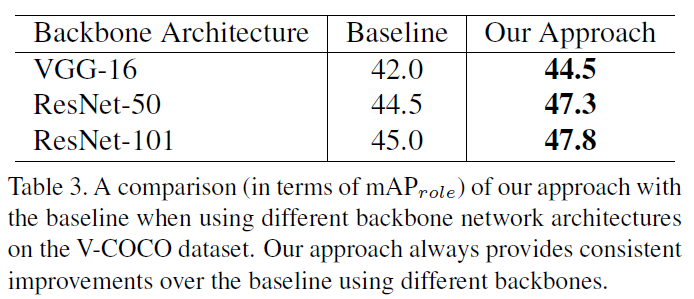
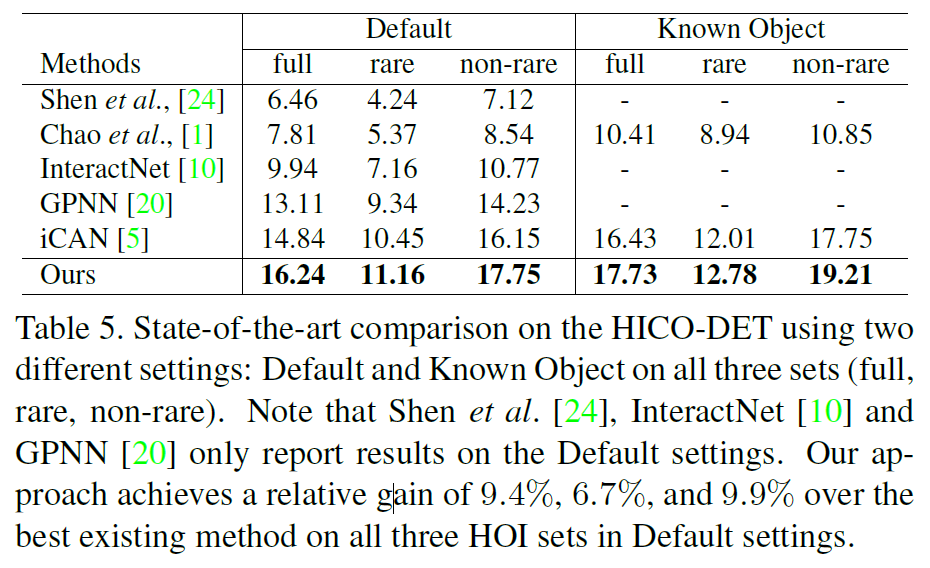
作者在HOI任务的数据集V-COCO、HICO-DET和HCVRD上做了测试,并专门与GPNN和iCAN做了对比。另外作者对attention做了可视化(图5),可以看到本文的Contextual Attention确实有一定的效果。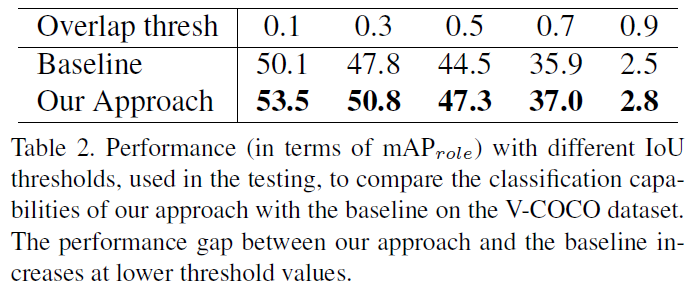



总结
又是一篇attention。
但是在attention之外,这篇文章也让我认识到global feature的重要性。回忆一下ECCV2018的GPNN,全局场景信息的缺失和context信息的缺失或许是导致其落后于本文的主要原因。
还有就是作者用到的方法真是丰富。可见想要完成一篇顶会paper,背后需要广泛阅读各种领域的文献,说不定某些奇奇怪怪的方法就能用到。但是个人质疑一下Local Encoding模块在本文模型中的作用。感觉并不需要position sensitive,如果有消融实验就更好了。可惜作者没有开源代码。

若有收获,就点个赞吧
0 人点赞
