ECCV 2018 论文标题:Videos as Space-Time Region Graphs 论文地址:https://arxiv.org/abs/1806.01810v2

简介
本文提出了一种将视频空间域信息和时间域信息统一构建为Graph结构的方法,并利用改进的GCN提取视频特征。针对人体动作识别任务,作者指出其有两个关键线索:1.时序上目标的形状变化;2.人物的交互关系。因此作者以视频帧中的目标为node,构造了两种relation为edge:1.similarity relations;2.spatial-temporal relations,以此用Graph结构对视频统一建模。与以往的用RNN提取时序特征的方式不同,本文最重要的特点就是将时序特征也统一表示在了Graph中。最后,作者在Charades和Something-Something数据集上做了实验,该模型都取得了SOTA结果。
Space-Time Region Graphs
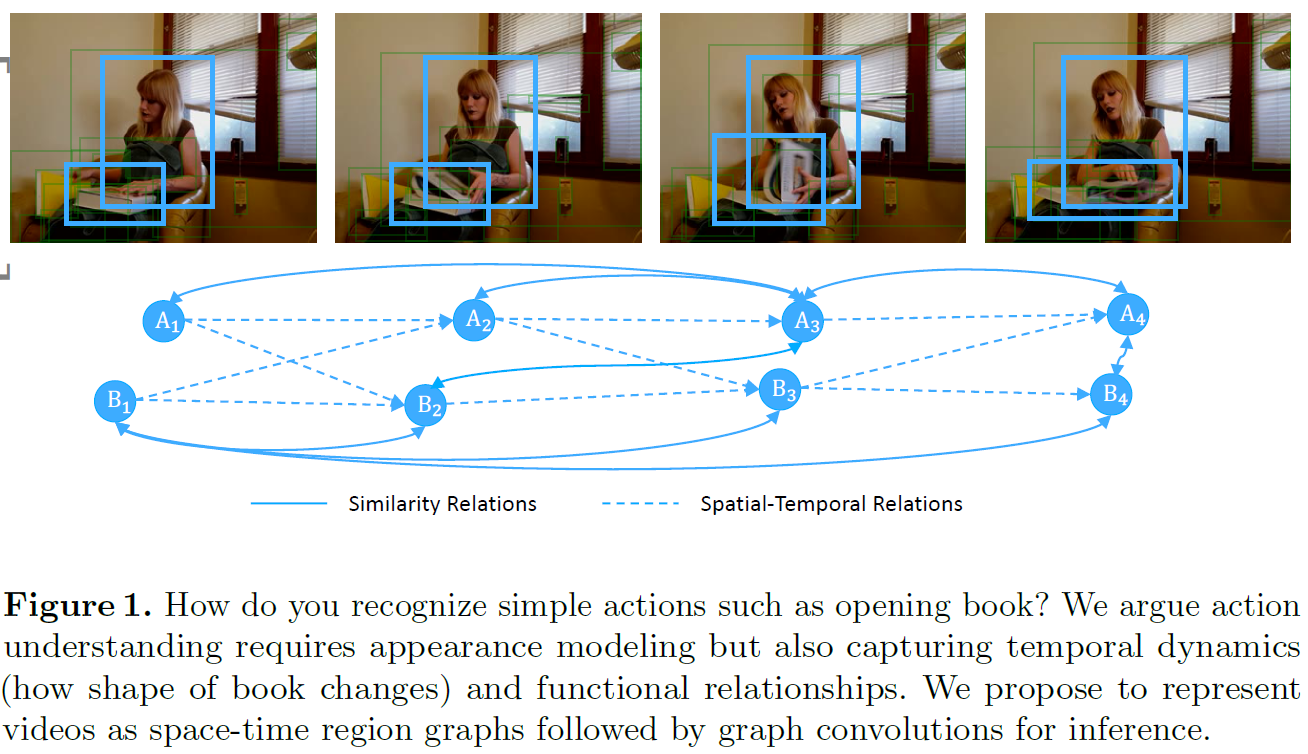
图1展示了本文的motivation:视频人体动作识别需要对appearance特征建模,同时也需要考虑目标的时序变化和目标间的关系。作者在CNN提取appearance特征的基础上,对后两者用Space-Time Region Graphs统一建模。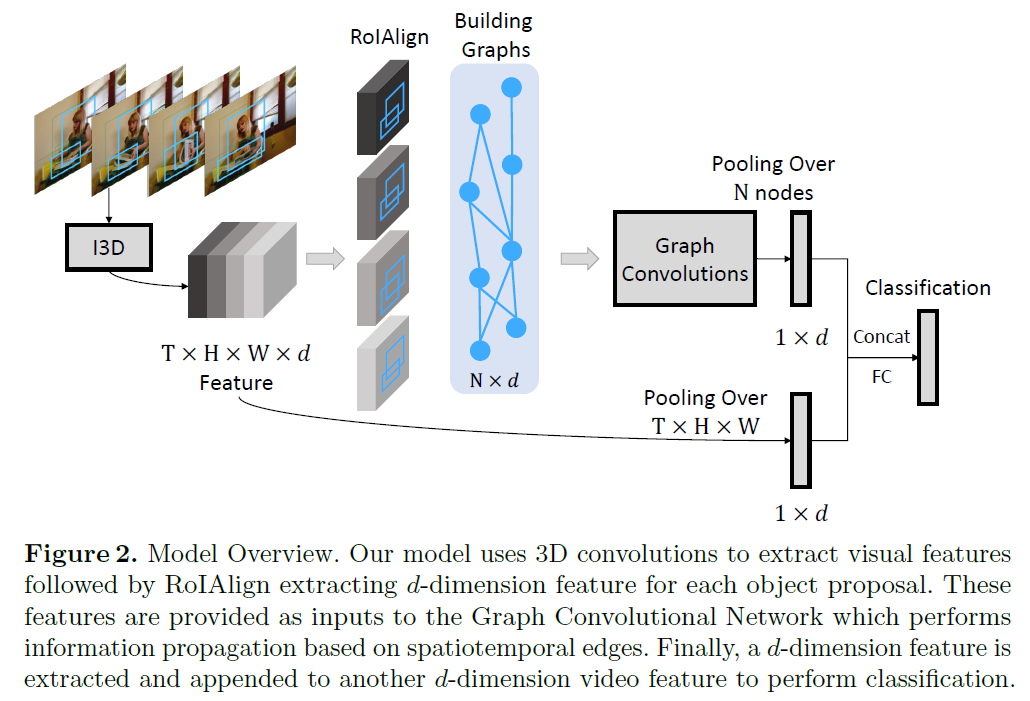
图2是模型的整体结构:1.利用RPN网络在采样的视频帧上检测目标;2.利用I3D网络提取视频feature map;3.利用ROIAlign提取目标特征,4.构建Graphs;5.利用GCN在Graphs上提取特征;6.特征融合并进行动作分类。
要注意的就是第一步RPN网络检测的目标是在所有采样到的视频帧上,不是只对一帧检测。因此目标会在时序上有重复,这也是利用Graph进行时序建模的基础。还有本文的核心内容Space-Time Region Graphs其实是多个Graph的集合,下面详细介绍。
Similarity Graph
Similarity Graph对目标间的similarity relations建模,即表达同一个目标在时序上的变化和目标间的相关性。Similarity Graph以目标特征的similarity为edge构造邻接矩阵,计算方法如下: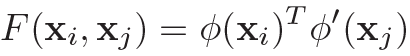
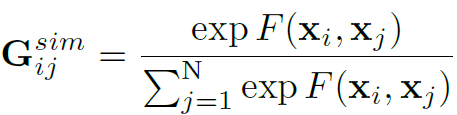
其中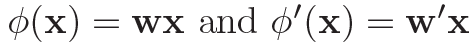 ,
,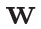 和
和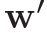 都是d*d的权重。
都是d*d的权重。
图3展示了几个具有高similarity的目标,可以看到Similarity Graph不仅表达目标的视觉相似性,也表达了部分目标间的相关性。
Spatial-Temporal Graph
在空间上距离较近的目标间往往存在交互关系,Spatial-Temporal Graph就是要建立相近目标间的联系,同时表达时序上目标的变化顺序。作者利用IOU表达目标间的空间距离,并以此为邻接矩阵的权重: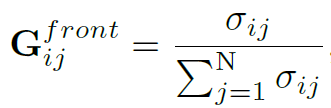
其中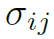 是第 t 帧上的 i 目标和第 t+1 帧上的 j 目标间的IOU。
是第 t 帧上的 i 目标和第 t+1 帧上的 j 目标间的IOU。
按照这个规则可以构建一个Spatial-Temporal Graph,但需要注意的是这是一个有向图,edge的方向永远是从 t 帧的目标到 t+1 帧的目标。因此,作者在其基础上添加了另一个完全相反的Spatial-Temporal Graph  ,表达从 t +1 帧的目标到 t 帧的目标间的关系。这样,Spatial-Temporal Graph其实是两个Graph结构:
,表达从 t +1 帧的目标到 t 帧的目标间的关系。这样,Spatial-Temporal Graph其实是两个Graph结构: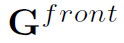 和
和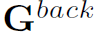 。图4是对正反向spatial-temporal relations的可视化。
。图4是对正反向spatial-temporal relations的可视化。
Convolutions on Graphs
作者并没有使用经典GCN的结构,而是参考Non-local Net和Resnet的残差结构,对其做了改进: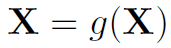

其中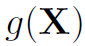 表示在第一层之前对Nd的结点特征X做一次卷积操作(这部分不是很懂,这个卷积可能是个1dConv?)
表示在第一层之前对Nd的结点特征X做一次卷积操作(这部分不是很懂,这个卷积可能是个1dConv?)
文中一共构造了三个Graph,为了统一对其进行处理,作者首先尝试了在GCN的每一层将三个Graph的结果相加: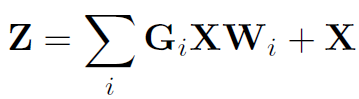
但之后作者说这样会影响最终的精度,因为邻接矩阵中只有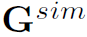 是含有learnable的参数的,
是含有learnable的参数的,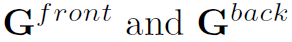 都是没有的,这样在每一层融合会影响的训练。因此作者对Similarity Graph单独使用GCN,其他两个Spatial-Temporal Graph在每一层相加结果,最后再将Similarity Graph和Spatial-Temporal Graph的结果相加,得到Nd的融合特征。本文实验中GCN都只用3个layer。
都是没有的,这样在每一层融合会影响的训练。因此作者对Similarity Graph单独使用GCN,其他两个Spatial-Temporal Graph在每一层相加结果,最后再将Similarity Graph和Spatial-Temporal Graph的结果相加,得到Nd的融合特征。本文实验中GCN都只用3个layer。
Video Classification
作者对Graph模型得到的Nd的融合特征做average pooling,得到d维的特征向量。再对I3D backbone输出的THWd的特征做average pooling,也得到d维的特征向量。将二者concat起来,用于最后的分类任务。
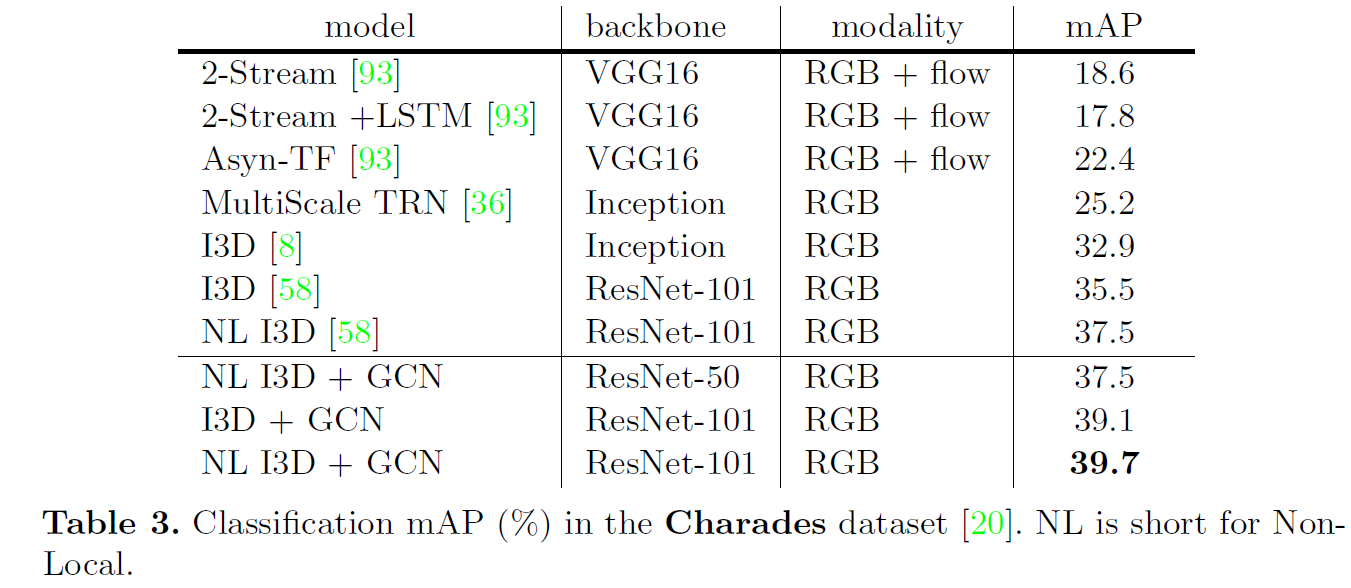
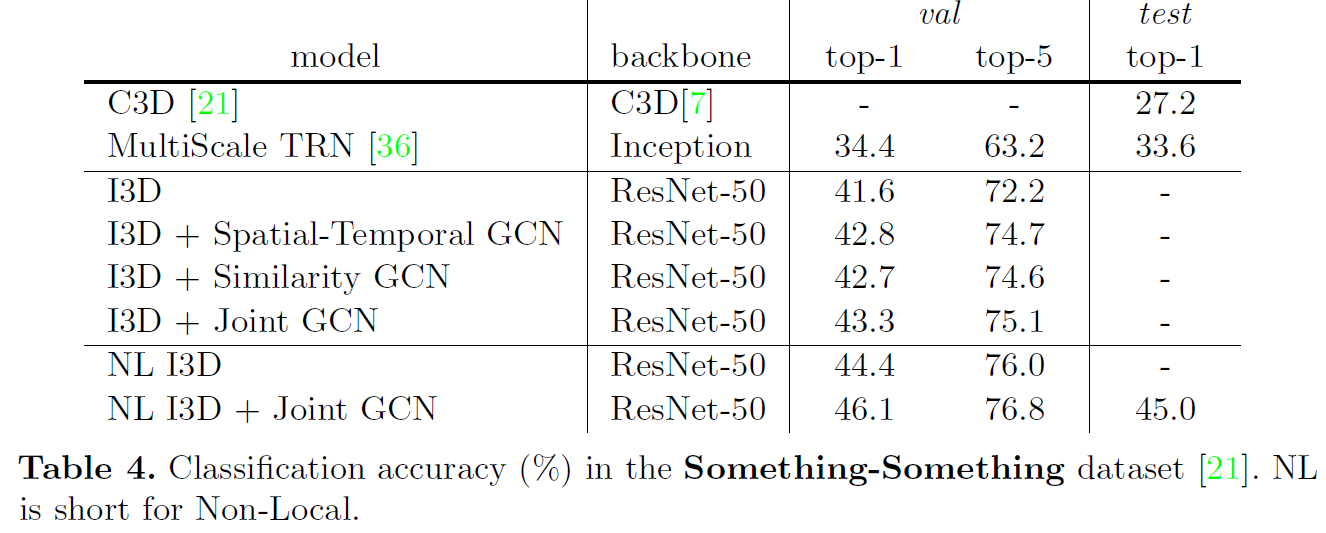
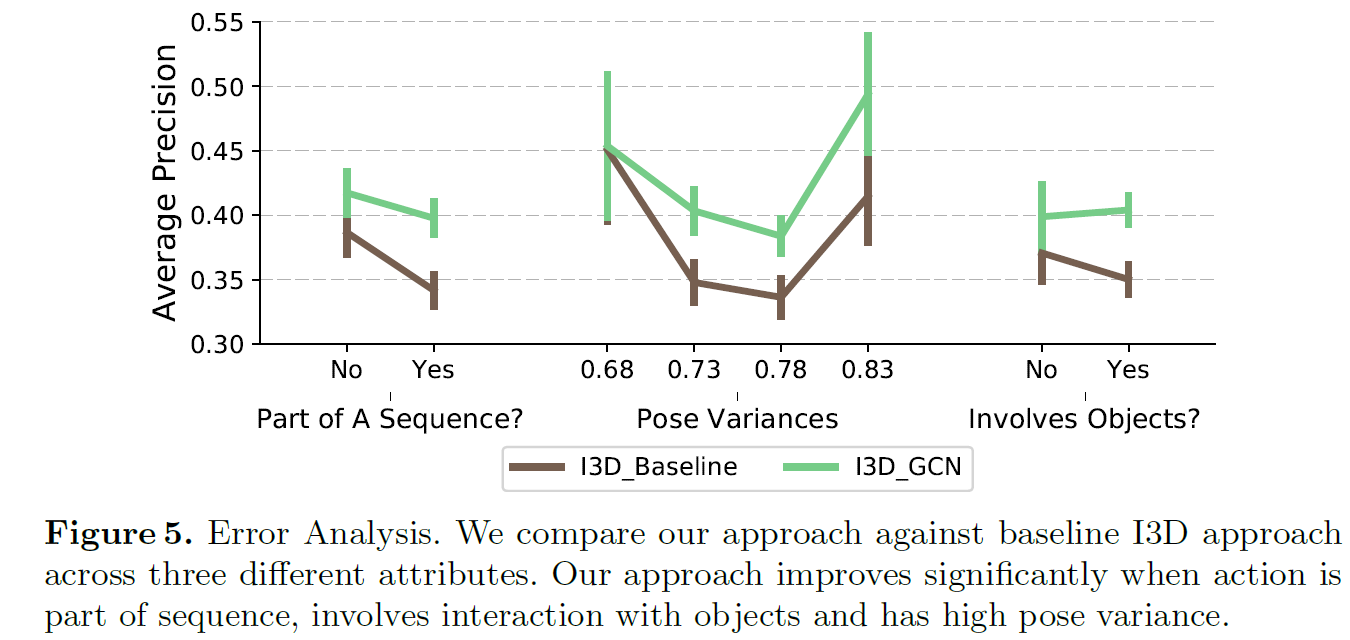
Experiments
实验部分提到了很多实现细节。
总结
Non-local Net和GCN结合的那一块还没理解透彻。但仔细想想,Non-local Net和本文是有相似之处,或者说本质上是在做同样的事情,都是将空间域和时间域信息统一建模。但Non-local Net是在像素基础上的,本文构建的Graph是在目标基础上的。

若有收获,就点个赞吧
0 人点赞
