CVPR 2019 论文标题:Learning Actor Relation Graphs for Group Activity Recognition 论文地址:https://arxiv.org/abs/1904.10117 代码地址:https://github.com/wjchaoGit/Group-Activity-Recognition

简介
本文针对Group Activity Recognition任务提出了Actor Relation Graphs (ARG)模型。ARG从appearance和position两个角度提取actors间的关系特征构建Multi-GCN,并在时域上进行随机帧采样构建temporal graphs,以充分考虑时序信息。最终模型会输出individual action和group activity的分类结果。作者在Volleyball和Collective Activity数据集上做了实验,都达到了state-of-the-art结果。
Actor Relation Graphs
在构建ARG模型之前,需要用object detection模型检测出视频帧上的所有actors。同时,需要利用CNN backbone (如Inception-v3)和RoIAlign提取各个bounding box的feature,得到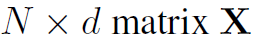 为N个actor的d维特征。这是目前CNN+GCN应用于CV的主要方式:即CNN提取特征,GCN优化特征。下面是ARG的整体结构:
为N个actor的d维特征。这是目前CNN+GCN应用于CV的主要方式:即CNN提取特征,GCN优化特征。下面是ARG的整体结构: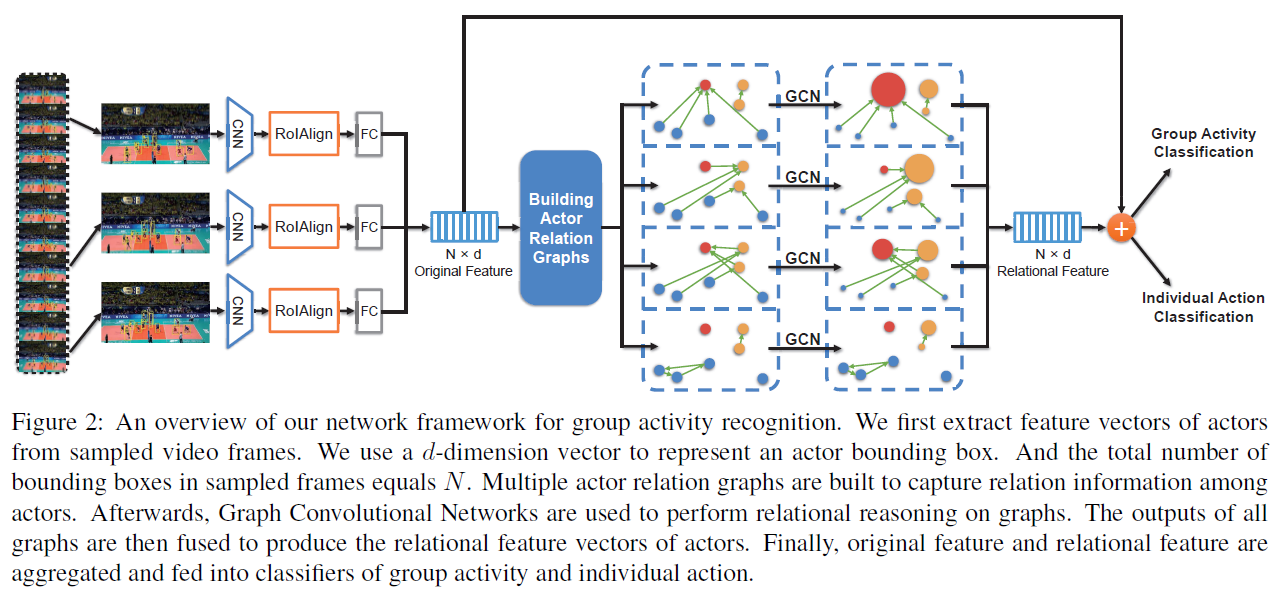
图2将ARG的思路展示地非常清晰,首先对视频帧随机采样(3帧),接着提取特征。然后利用Multi-GCN进行特征的聚合与优化,最后和初始特征融合,用于分类任务。下面来介绍细节。
Graph definition
ARG中的node是一帧视频里所有的actor。邻接矩阵的定义比较特殊: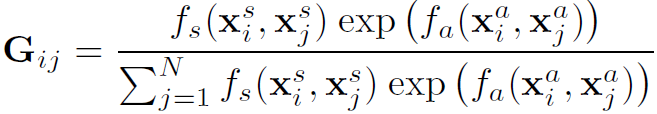
其中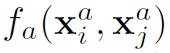 表示actor之间的appearance relation,
表示actor之间的appearance relation,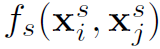 表示actor之间的position relation。
表示actor之间的position relation。
appearance relation的定义作者给了三种不同的形式,分别是:
(1)Dot-Product,d为标准化的因子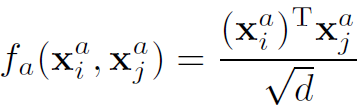
(2)Embedded Dot-Product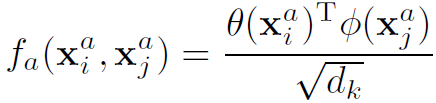
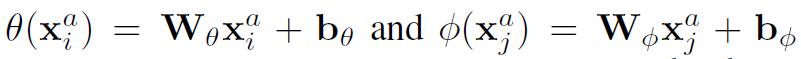
(3)Relation Network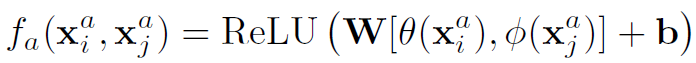
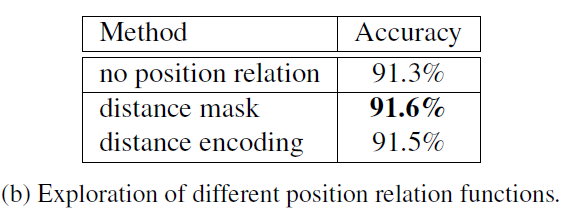
position relation的定义作者给了两种形式:
(1)Distance Mask, 为指示函数(具体形式文中好像没提),
为指示函数(具体形式文中好像没提),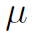 为阈值超参数,
为阈值超参数,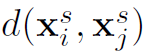 表示欧氏距离
表示欧氏距离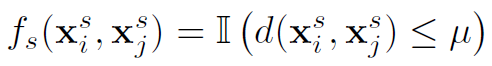
(2)Distance Encoding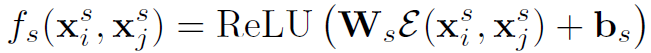
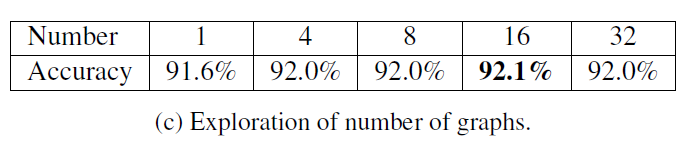
Multiple graphs
Multiple graphs是本文ARG模型的一个特点。作者提到单个GCN只聚焦于actor之间的特定关系,忽略了很多context信息,因此ARG用多个不共享权重的GCN来对actor间的多种关系建模。这种方式本质上还是模型平均的思想。
Temporal modeling
时序信息是视频动作识别任务的关键线索,ARG采用STN中的sparse temporal sampling strategy,对视频帧进行随机采样,从而对时序信息建模。这里作者说到利用采样的3帧图像构建temporal graphs,应该是指在时域上做Multi-GCN模型平均。另外作者提到,随机采样的方式间接扩充了训练数据,相当于做了数据增强,对模型训练结果有着较大提升。
Reasoning and Training on Graphs
ARG中一个layer的定义如下,和经典GCN类似: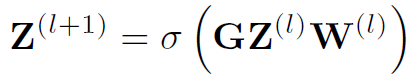
其中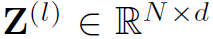 是第l层的结点特征,
是第l层的结点特征,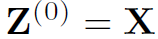 ,
,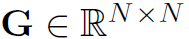 是邻接矩阵。
是邻接矩阵。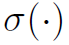 是激活函数,本文用Relu。ARG中作者仅构建了2层layer,即仅做了一次结点特征的融合和更新。
是激活函数,本文用Relu。ARG中作者仅构建了2层layer,即仅做了一次结点特征的融合和更新。
对于Multi-GCN结果融合的问题,作者采用late fusion的方式,直接将最后一层各结点相应的特征向量累加起来: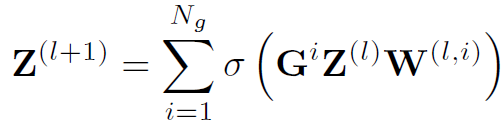
同时作者也在实验中测试了几种其他的融合方式。
最后是loss函数: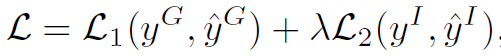
其中 表示cross-entropy loss,
表示cross-entropy loss,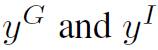 分别是group activity和individual action的标签,
分别是group activity和individual action的标签,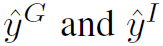 分别是二者的预测值。
分别是二者的预测值。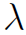 是一个权重超参数。
是一个权重超参数。
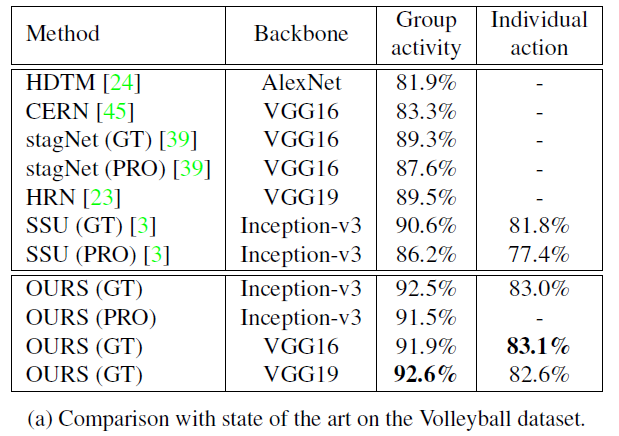
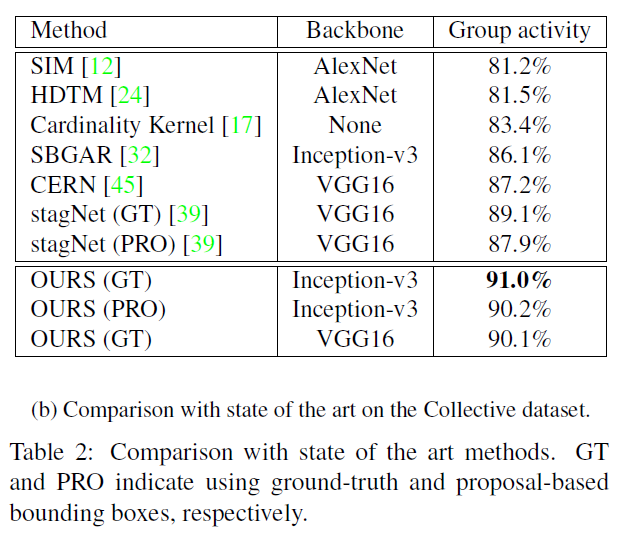
Experiments
作者在Volleyball和Collective Activity数据集上做了实验,这部分也说明了实现细节,具体见原文: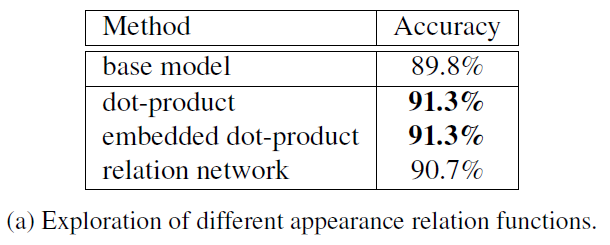




总结
ARG结构很简单,但利用模型平均把效果刷的很好,Multiple graphs也算是一种刷分的思路吧。另外,文中对temporal graphs的处理方式,以及实验中early fusion的融合方式描述的并不清楚,需要在代码中来看实现细节。

若有收获,就点个赞吧
0 人点赞
