AAAI 2018 论文标题:Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition 论文地址:https://arxiv.org/abs/1801.07455 代码地址:https://github.com/yysijie/st-gcn

简介
本文针对Skeleton-Based Action Recognition任务提出了一种基于GCN的模型:ST-GCN,实现了人体骨架节点之间空间关联和时序关联的统一处理。ST-GCN所构建的Graph结构可以视为一种3D的Graph,其在空间维的操作和传统GCN类似,但时间维的操作以及实现方式令人耳目一新。本文第一个将skeleton序列理解为一个整体的时空图,这使得用一个统一的模型来进行Skeleton-Based的动作识别成为可能。作者在Kinetics和NTU-RGBD数据集上做了实验,效果都有实质性的进步。
Spatial Temporal Graph ConvNet
本文是第一篇利用GCN相关模型解决Skeleton-Based Action Recognition任务的文章,同时本文提出的ST-GCN的适用范围应该也远不止骨架动作识别,因此能被AAAI2018接受。将GCN应用于skeleton序列,一种典型的思路是只在空间维上构建graph结构,用GCN进行特征提取,之后用RNN相关模型处理时间维信息。但本文试图将时空维度统一构建在graph结构中,形成一种3D Graph的既视感,可以说contribution是很足的,实验也证明了其十分有效。ST-GCN的整体结构如图2: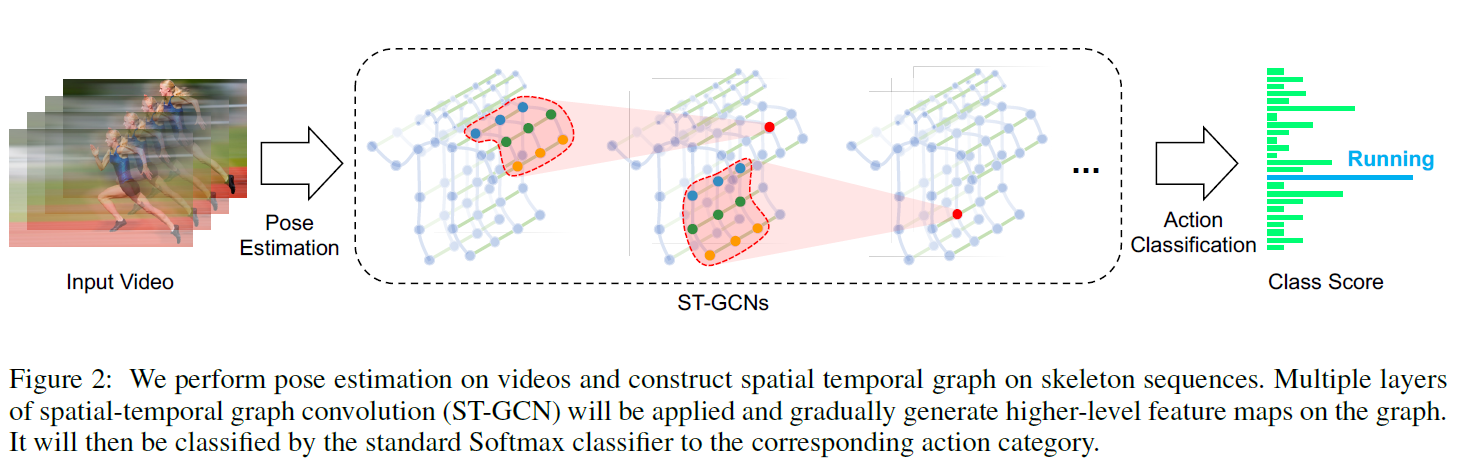
类比于3D CNN的思想,ST-GCN其实是在graph上也实现了3D卷积。其卷积核包括了空间维和时间维。空间维就是人体骨骼节点间的自然连接,而时间维是同一节点在时序上的表示,如图1: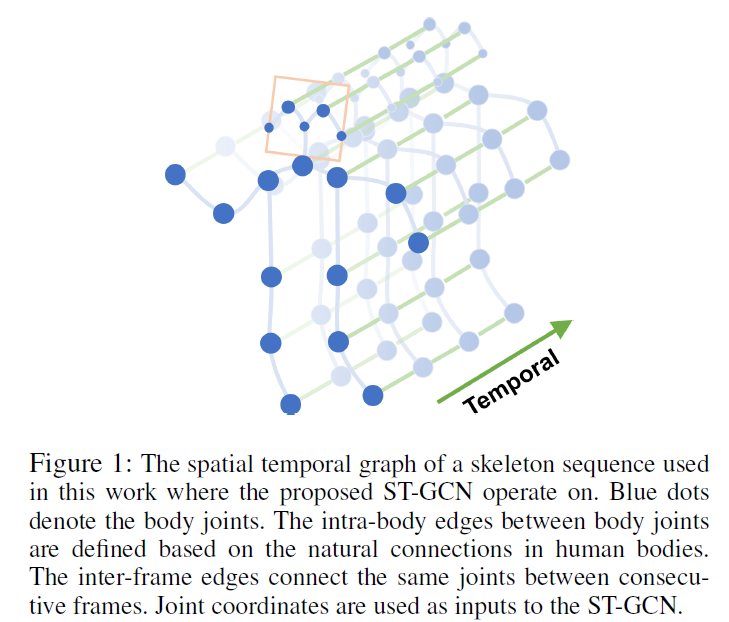
卷积操作的方式也和3D CNN类似,某一个结点的特征等于其在空间和时间维邻接结点特征的加权和。这样抽象地理解很容易,但用公式表示这个过程并不容易,编程实现更是需要技巧。
Skeleton Graph Construction
ST-GCN中graph的结点就是骨架的节点,其初始的特征向量是2D或3D坐标以及一个置信度。graph的边有两种,分别是intra-skeleton edges和inter-frame edges,分别代表空间上骨架节点的自然连接和时间上相同节点的时序连接,用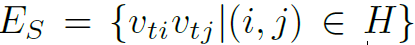 和
和 表示。
表示。
Spatial Graph Convolutional Neural Network
这部分的公式较难理解,但本质就是在讲ST-GCN的操作方式:某一个结点的特征等于其在空间和时间维邻接结点特征的加权和: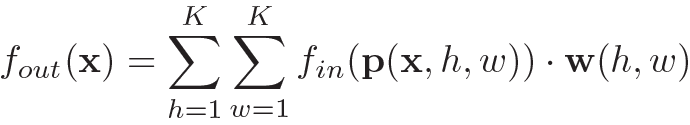
那么就有两个关键问题:1.如何定义时空维的邻接,即如何采样。2.如何计算权重。上式中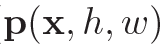 就是采样函数,x表示输入节点的位置。
就是采样函数,x表示输入节点的位置。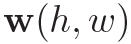 是权重函数。
是权重函数。
空间上采样的方式和GCN一样,只取一阶的邻接结点。而时间上采样的方式是固定了一个kernel size为 。因为骨架序列在时间维上本身是有先后顺序的,可以理解为一幅2D图像的channel,处理方式和普通的CNN一样,可以用固定大小的kernel作为权重参数,其是在训练过程中learnable的。而空间维不同,拿某一帧来看,单个的人体骨架graph每个结点邻接的一阶结点个数是不定的,也没有顺序的定义,就不能用固定大小的kernel处理。
。因为骨架序列在时间维上本身是有先后顺序的,可以理解为一幅2D图像的channel,处理方式和普通的CNN一样,可以用固定大小的kernel作为权重参数,其是在训练过程中learnable的。而空间维不同,拿某一帧来看,单个的人体骨架graph每个结点邻接的一阶结点个数是不定的,也没有顺序的定义,就不能用固定大小的kernel处理。
实际上经典的GCN已经解决了这个问题,只是其处理方式比较简单:用邻接矩阵,相邻的结点都一视同仁。本文在此基础上,将相邻结点划分为不同的part,每个part内的结点单独卷积(个人理解这里本质是对不同part赋予了不同的权重)。文中有三种划分方法,如图3:
1.Uni-labeling,图3(b),就是经典GCN的方式。某个结点本身和其一阶相邻结点具有相同的权重。
2.Distance partitioning,图3(c),将结点本身和其一阶相邻结点区别对待。
3.Spatial configuration partitioning,图3(d),将一阶邻接结点分为向心结点和离心结点,以结点到骨架重心之间的距离衡量。若某一结点的一阶邻接结点到重心的距离小于该结点到重心的距离,则这个邻接结点为向心结点,否则离心。
Implementing ST-GCN
空间维图卷积的实现方式和经典GCN一致: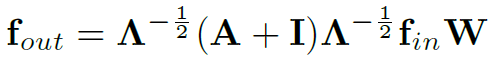
时间维卷积的实现很巧妙。ST-GCN模型的输入是一个(C, V, T)维的张量,其中C表示骨骼节点特征的维数,如2D结点维数是3(坐标和置信度)。V表示结点个数,T表示时间序列。作者用一个卷积核为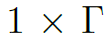 的2D Conv,将C视为2D卷积的channel,V和T视为2D图像的宽和高,实现时间维的卷积。之后再对结果张量乘上
的2D Conv,将C视为2D卷积的channel,V和T视为2D图像的宽和高,实现时间维的卷积。之后再对结果张量乘上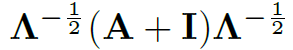 进行空间维卷积。这里是本文时空图卷积的核心之一,说明了ST-GCN在卷积过程中的张量流是怎样的,需要仔细理解。
进行空间维卷积。这里是本文时空图卷积的核心之一,说明了ST-GCN在卷积过程中的张量流是怎样的,需要仔细理解。
对于不同的结点part划分方式,其实就是将它们从邻接矩阵中分开进行卷积。如第二种Distance partitioning将结点本身和一阶邻接结点分开,在操作上就是将邻接矩阵A,与对角矩阵(自环)I 从 中分离:
中分离: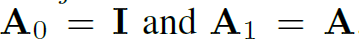 ,然后将他们的处理结果累加:
,然后将他们的处理结果累加: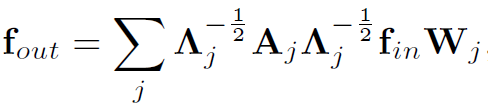
本质上就是对不同的part训练了不同的矩阵W,可以看做一种加权吧。
最后作者还单独对图卷积操作中的邻接矩阵添加了一个可训练的mask,以调整邻接矩阵内的权重: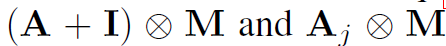
M代表可训练的mask, 表示element-wise相乘。
表示element-wise相乘。
Network Architecture and Training
本文实验中ST-GCN叠加了9个layer,并使用了dropout和Resnet的shortcut,算是视觉应用中很深的GCN了。时间维的卷积核为1*9。最终将所有结点的特征向量global pooling,然后用分类器进行动作分类。因为时间维卷积是用2D Conv实现的,因此在卷积核的第二位设置不同stride可以起到时间维pooling效果。同时由于最后的global pooling操作,模型输入的时间序列长度可以是任意的。还有一些具体的实现细节请参照原文。
Experiments
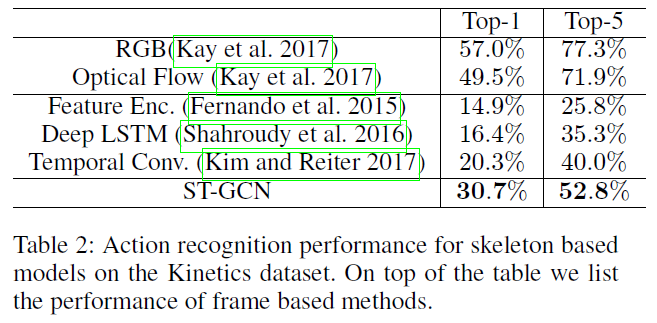
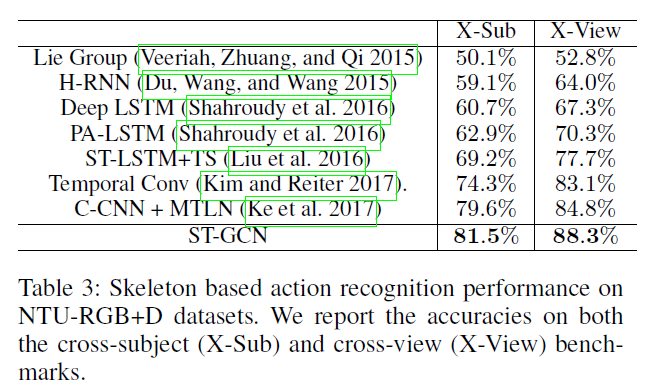
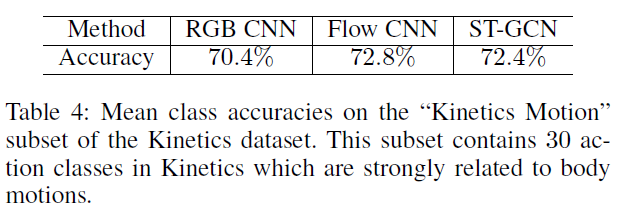
本文ST-GCN开启了GCN处理Skeleton-Based Action Recognition任务的序幕,目前这个方向已经被GCN屠榜了。在Kinetics和NTU-RGBD数据集上都进步明显。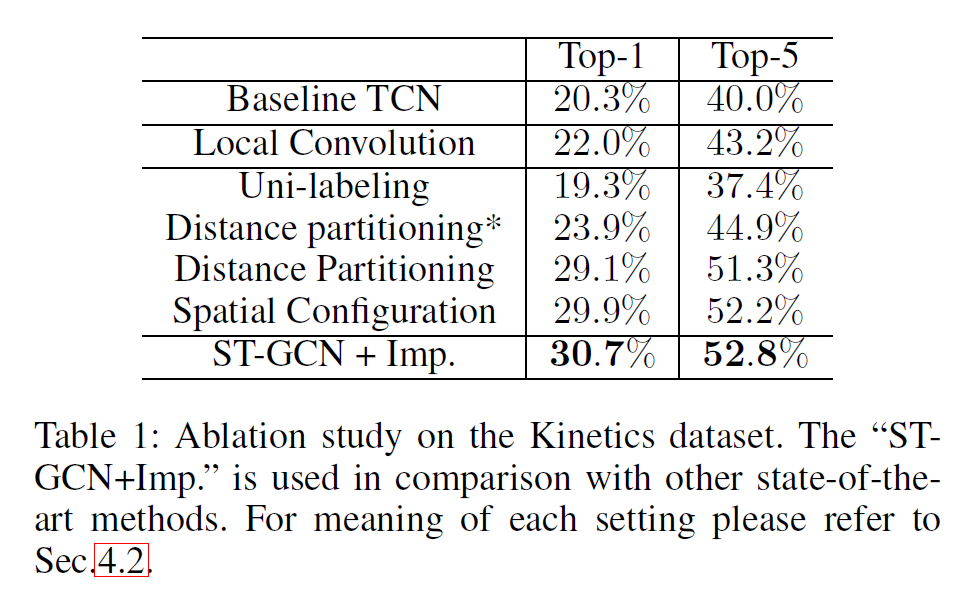
![[论文精读] Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition - 图23](/uploads/projects/deeperlearning@lwjd/b3d758232a1c39ae71da9fbfdc33c902.gif)
![[论文精读] Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition - 图24](/uploads/projects/deeperlearning@lwjd/aae89852827efc7d095d2121009a107a.gif)
总结
文章的模型构建那部分讲的很难理解,特别是作者类比传统CNN,还有一些公式和字母都没有明确定义,看得我云里雾里。好在作者提供了开源代码。总的来说本文还是让人眼前一亮的,ST-GCN是将GCN也扩展到了3D,其广泛的意义肯定远不止处理骨架序列。

若有收获,就点个赞吧
0 人点赞
