ICCV 2019 论文标题:AttPool: Towards Hierarchical Feature Representation in Graph Convolutional Networks via Attention Mechanism 论文地址:http://openaccess.thecvf.com/content_ICCV_2019/papers/ 视频报告:https://www.ihub.org.cn/html/jiangtang/2019/1102/22.html

简介
本文提出了一种基于attention机制的、可端到端训练的图池化模块AttPool ,用于挖掘图卷积过程中,不同层次的结点表征和图表征。大致思路是先对node feature进行self-attention,并按缩放因子筛选出k个attention weight最高的结点。之后利用GCN进行结点特征的聚合更新,并且只将筛选出的结点保留。因此,在每一个GCN layer上,只有相对重要的结点被保留,其余结点被忽略,但被忽略的结点特征以聚合的形式合并到关键节点上,由此在减少结点个数的同时增强graph的抽象能力。最后作者在图分类 (graph classification) 任务上对AttPool的效果进行了验证。
Graph Convolutional Network with Attentionbased Pooling
GCN在解决graph结构数据的node classification和link prediction任务时表现出色。但由于其缺少较好的pooling strategy,从而无法得到多层次的图表征,因此很难处理graph classification任务。现有研究中通常的做法是对graph的所有node feature相加或取平均来表征graph feature,进一步进行graph classification。但这样粗糙的方法没有考虑各个node的重要性,会引入大量的冗余信息与噪音。这就是作者提出本文图池化模块AttPool的motivation。
本文的GNN结构基础就是经典的GCN,但AttPool是独立于GCN的,其可以被直接嵌入到其他GNN结构中。经典的GCN公式表达如下,这里不做过多解释: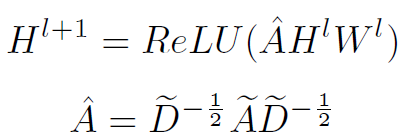
所谓多层次的图表证,其实就是要在GCN过程中不断对graph进行降采样,以减少结点个数。AttPool的实质就是这个降采样过程,其分为两步: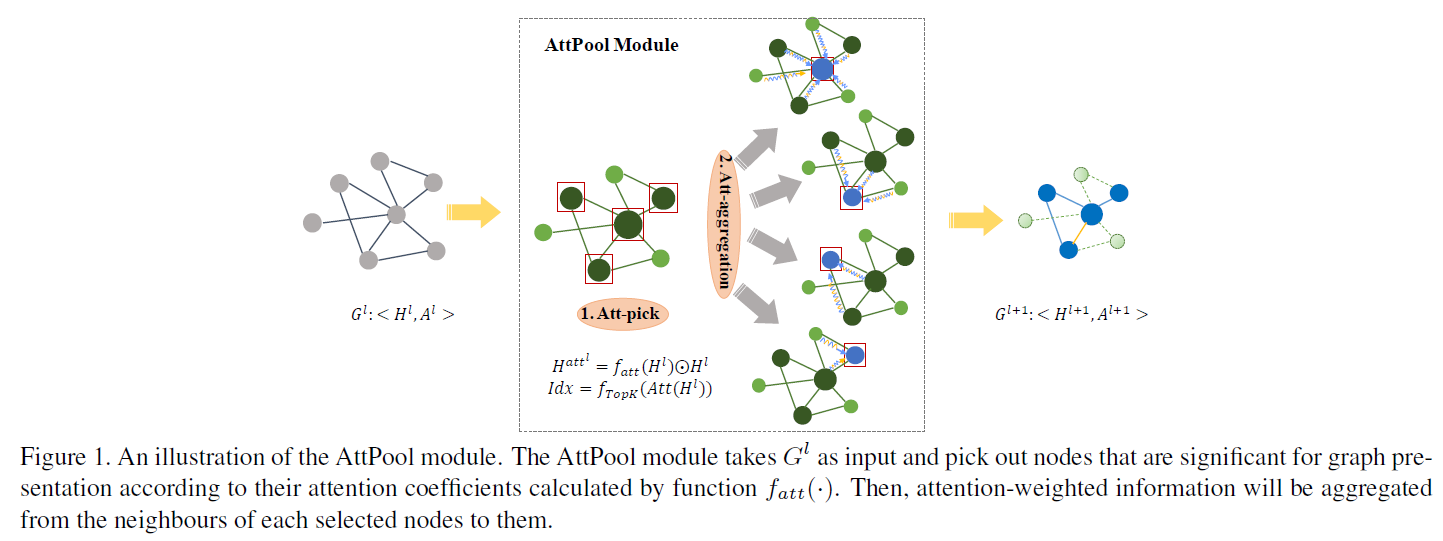
step1:计算graph中每个node的self-attention,得到的attention weight就表示这个node在graph中的重要程度。依据重要程度筛选出前k个结点,再结合attention weight对node feature进行聚合更新: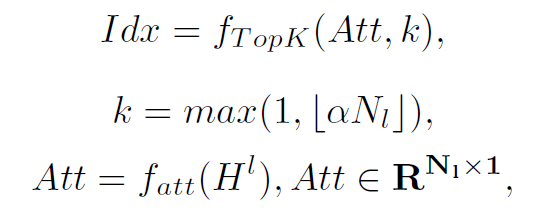
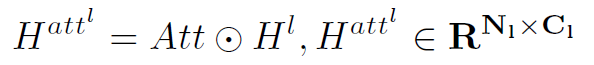
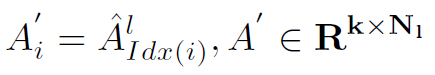
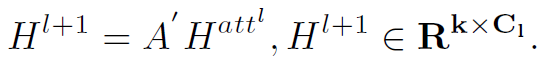
以上几个公式就是step1的所有步骤,需要仔细理解。其中Att表示attention weights,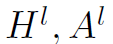 表示第l层的node feature和adj matrix。在得到了Att之后,将node feature与Att相乘,就得到了加权之后的node feature
表示第l层的node feature和adj matrix。在得到了Att之后,将node feature与Att相乘,就得到了加权之后的node feature 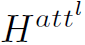 。接着根据筛选出的node index对adj matrix也进行筛选,只保留前k个结点的邻接矩阵:
。接着根据筛选出的node index对adj matrix也进行筛选,只保留前k个结点的邻接矩阵: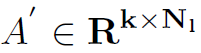 。最后根据邻接矩阵和加权node feature
。最后根据邻接矩阵和加权node feature  得到聚合更新之后的l+1层的node feature
得到聚合更新之后的l+1层的node feature 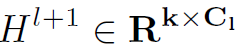 。这里一定要注意矩阵的维度变化,有助于理解整个过程。
。这里一定要注意矩阵的维度变化,有助于理解整个过程。
可以看到,graph的结点个数由l层的N1个,降至l+1层的k个,但node feature的维度不变,始终是C1维。
strp2:因为结点个数降至k个,因此要对adj matrix也进行更新,以确保进行下一个layer: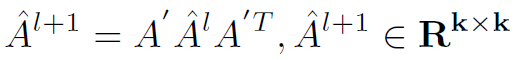
其中 会进入下一个GCN layer的计算。
会进入下一个GCN layer的计算。
以上就是AttPool的全部操作流程,思路还是很简单的。下面介绍其核心的函数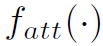 ,这个函数定义了如何计算attention weight。作者考虑了两种
,这个函数定义了如何计算attention weight。作者考虑了两种 的形式:Global Attention和Local Attention
的形式:Global Attention和Local Attention
Global Attention
Global Attention就是对所有结点一视同仁,求每个结点在全局的重要程度:
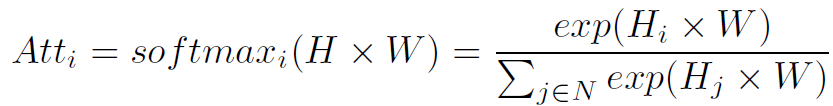
但作者提到,Global Attention有一个致命的缺点:权重高的结点会聚集在graph的一个狭小区域,而忽略了远离这个区域,但依旧很重要的结点。为此,必须考虑筛选结点的分散性,以充分表征整个graph的特征,防止筛选出的k个结点都聚集在一起。作者设计了更合理的Local Attention。
Local Attention
Local Attention在局部求每个结点的attention weights: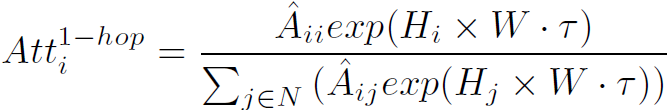
可以看到,这里Local指的就是与当前结点相邻接的所有结点,这在graph上是一个小区域。因为每个结点的邻接结点个数不定,因此还要做一次标准化,才能使结点之间的weights可比较: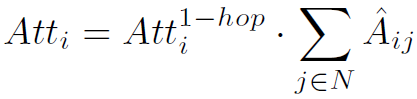
个人认为Local Attention的设计是全文的亮点所在,在实验中也起到很好的效果。
Hierarchical Prediction Architecture with AttPool
最后作者将AttPool与GCN结合,构建了pyramid形式的AttGCN,用于graph classification: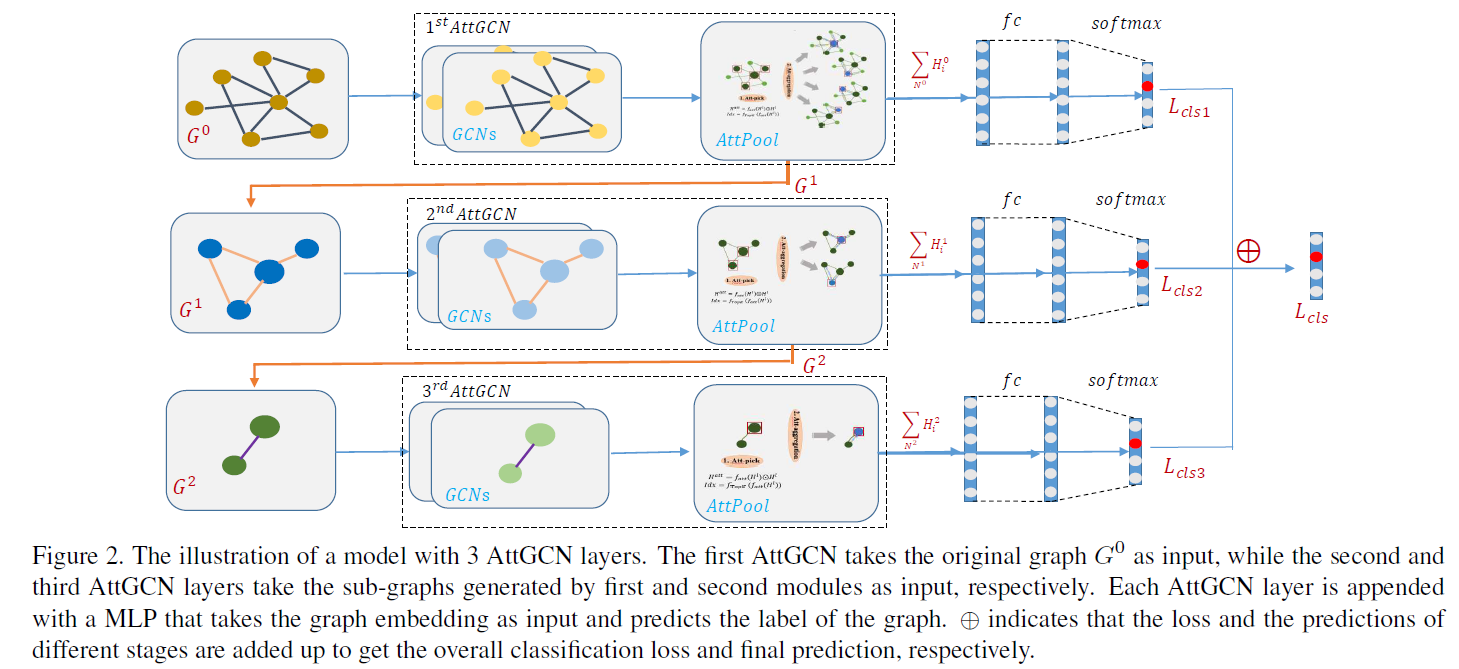
可以看到AttPool是嵌入GCN,与GCN一起训练的。同时,pyramid结构使网络每一个layer都产生一个分类loss,加速了网络的训练。
Experiments
作者在三种规模的graph classification数据集上做了测试:small (NCI1, PROTEINS),medium (COLLAB, D&D ),large (REDDITBINARY, REDDIT-MULTI-12K)。从图4可以看到,Local Attention可以显著解决采样node聚集在一起的问题,使降采样分布更加均匀。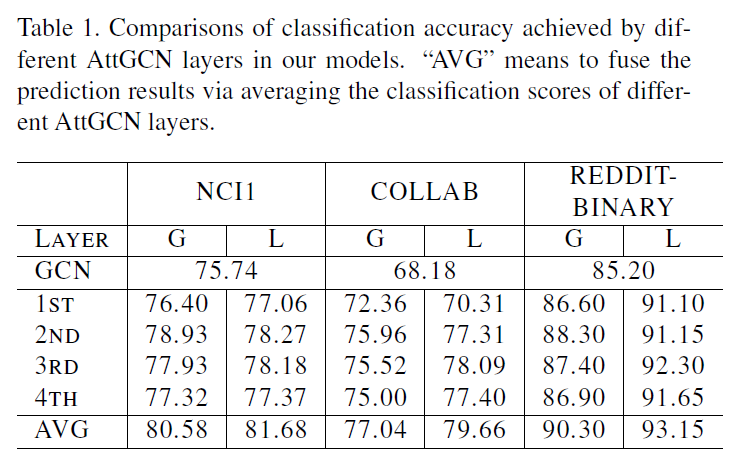
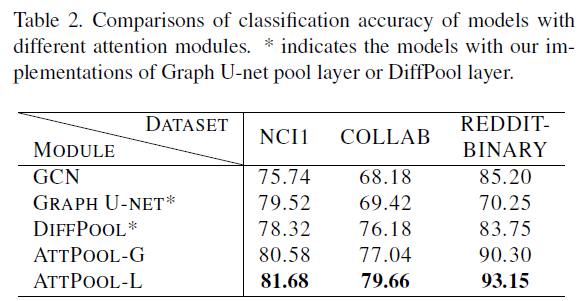
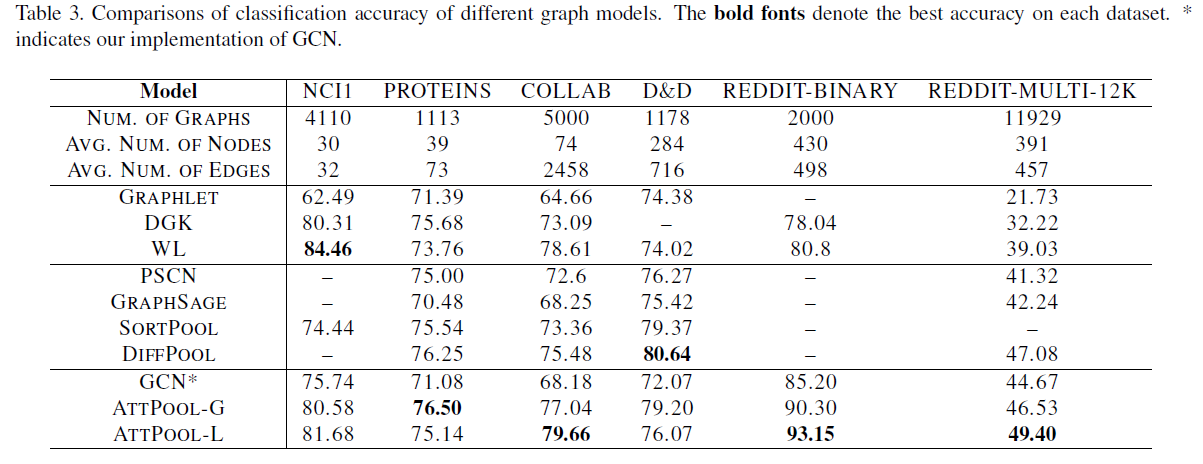

总结
graph pooling module的应用场景非常多,本文提出的AttPool不仅在效果上很好,在形式上也可以与GCN自然结合。

若有收获,就点个赞吧
0 人点赞
