ElasticJob 是面向互联网生态和海量任务的分布式调度解决方案,由两个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成。 它通过弹性调度、资源管控、以及作业治理的功能,打造一个适用于互联网场景的分布式调度解决方案,并通过开放的架构设计,提供多元化的作业生态。 它的各个产品使用统一的作业 API,开发者仅需一次开发,即可随意部署。
ElasticJob 已于 2020 年 5 月 28 日成为 Apache ShardingSphere 的子项目。 欢迎通过邮件列表参与讨论。
- 官网:https://shardingsphere.apache.org/elasticjob/index_zh.html
- 源码:https://github.com/apache/shardingsphere-elasticjob
简介
使用 ElasticJob 能够让开发工程师不再担心任务的线性吞吐量提升等非功能需求,使他们能够更加专注于面向业务编码设计; 同时,它也能够解放运维工程师,使他们不必再担心任务的可用性和相关管理需求,只通过轻松的增加服务节点即可达到自动化运维的目的。ElasticJob-Lite
定位为轻量级无中心化解决方案,使用 jar 的形式提供分布式任务的协调服务。
ElasticJob-Cloud
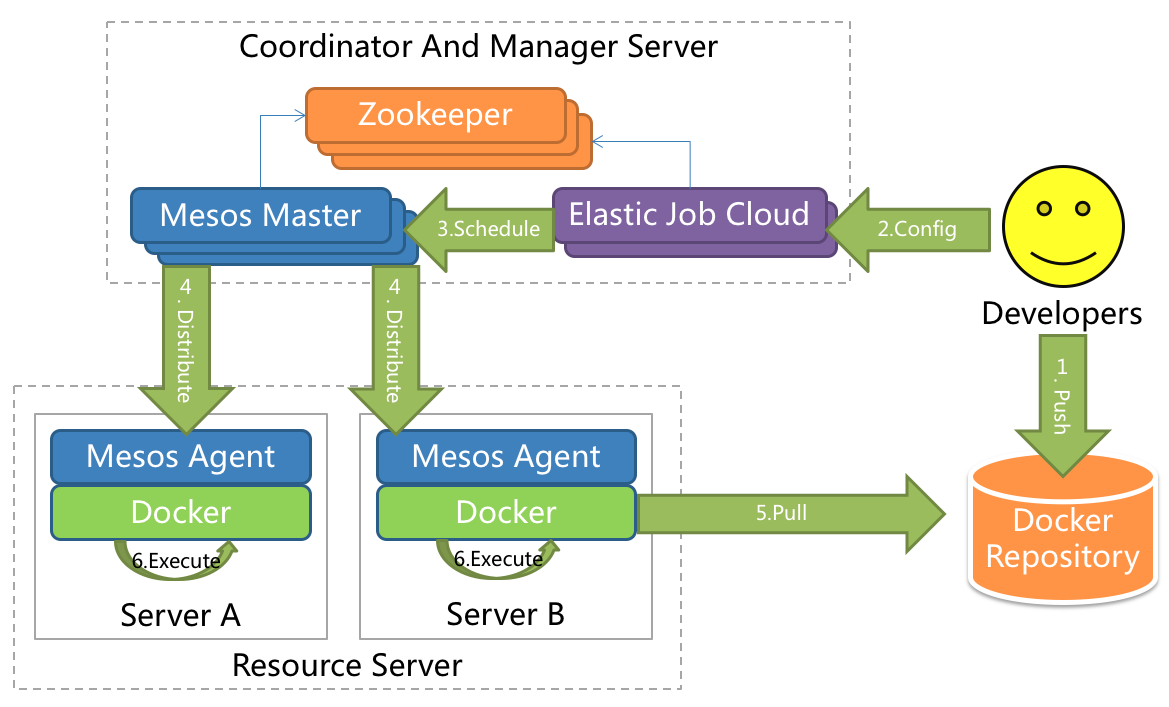
采用自研 Mesos Framework 的解决方案,额外提供资源治理、应用分发以及进程隔离等功能。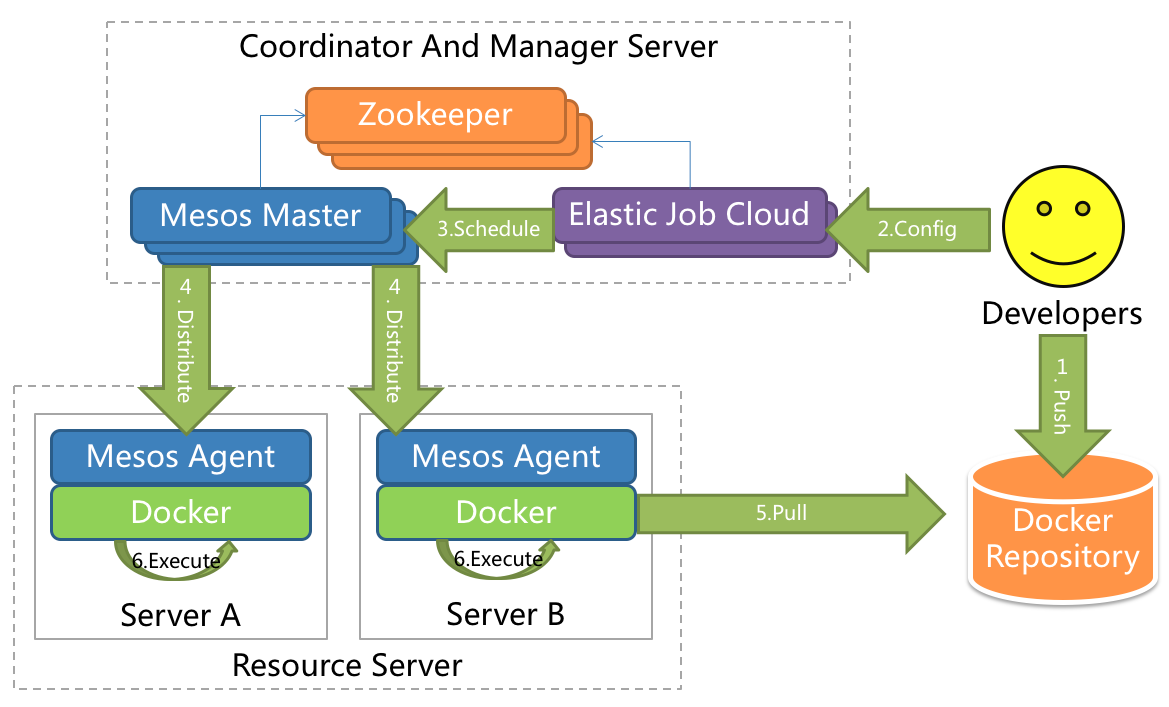
| ElasticJob-Lite | ElasticJob-Cloud | |
|---|---|---|
| 无中心化 | 是 | 否 |
| 资源分配 | 不支持 | 支持 |
| 作业模式 | 常驻 | 常驻 + 瞬时 |
| 部署依赖 | ZooKeeper | ZooKeeper + Mesos |
功能列表
- 弹性调度
- 支持任务在分布式场景下的分片和高可用
- 能够水平扩展任务的吞吐量和执行效率
- 任务处理能力随资源配备弹性伸缩
- 资源分配
- 在适合的时间将适合的资源分配给任务并使其生效
- 相同任务聚合至相同的执行器统一处理
- 动态调配追加资源至新分配的任务
- 作业治理
- 失效转移
- 错过作业重新执行
- 自诊断修复
- 作业依赖(TODO)
- 基于有向无环图(DAG)的作业间依赖
- 基于有向无环图(DAG)的作业分片间依赖
- 作业开放生态
- 可扩展的作业类型统一接口
- 丰富的作业类型库,如数据流、脚本、HTTP、文件、大数据等
- 易于对接业务作业,能够与 Spring 依赖注入无缝整合
可视化管控端
- 作业管控端
- 作业执行历史数据追踪
-
环境要求
Java
Maven
ZooKeeper
请使用 ZooKeeper 3.6.0 及其以上版本。详情参见
Mesos(仅 ElasticJob-Cloud 使用)
请使用 Mesos 1.1.0 及其兼容版本。详情参见
ElasticJob-Lite快速入门
引入 Maven 依赖
<dependency><groupId>org.apache.shardingsphere.elasticjob</groupId><artifactId>elasticjob-lite-core</artifactId><version>${latest.release.version}</version></dependency>
作业开发
public class MyJob implements SimpleJob {@Overridepublic void execute(ShardingContext context) {switch (context.getShardingItem()) {case 0:// do something by sharding item 0break;case 1:// do something by sharding item 1break;case 2:// do something by sharding item 2break;// case n: ...}}}
作业配置
JobConfiguration jobConfig = JobConfiguration.newBuilder("MyJob", 3).cron("0/5 * * * * ?").build();
作业调度
public class MyJobDemo {public static void main(String[] args) {new ScheduleJobBootstrap(createRegistryCenter(), new MyJob(), createJobConfiguration()).schedule();}private static CoordinatorRegistryCenter createRegistryCenter() {CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(new ZookeeperConfiguration("zk_host:2181", "my-job"));regCenter.init();return regCenter;}private static JobConfiguration createJobConfiguration() {// 创建作业配置// ...}}
ElasticJob-Cloud 快速入门
引入 Maven 依赖
<dependency><groupId>org.apache.shardingsphere.elasticjob</groupId><artifactId>elasticjob-cloud-executor</artifactId><version>${latest.release.version}</version></dependency>
作业开发
public class MyJob implements SimpleJob {@Overridepublic void execute(ShardingContext context) {switch (context.getShardingItem()) {case 0:// do something by sharding item 0break;case 1:// do something by sharding item 1break;case 2:// do something by sharding item 2break;// case n: ...}}}
作业启动
需定义
main方法并调用JobBootstrap.execute(),例子如下:public class MyJobDemo {public static void main(final String[] args) {JobBootstrap.execute(new MyJob());}}
作业打包
tar -cvf my-job.tar.gz my-job
API 鉴权
curl -H "Content-Type: application/json" -X POST http://elasticjob_cloud_host:8899/api/login -d '{"username": "root", "password": "pwd"}'
响应体:
{"accessToken":"some_token"}
作业发布
curl -l -H "Content-type: application/json" -H "accessToken: some_token" -X POST -d '{"appName":"my_app","appURL":"http://app_host:8080/my-job.tar.gz","cpuCount":0.1,"memoryMB":64.0,"bootstrapScript":"bin/start.sh","appCacheEnable":true,"eventTraceSamplingCount":0}' http://elasticjob_cloud_host:8899/api/app
作业调度
curl -l -H "Content-type: application/json" -H "accessToken: some_token" -X POST -d '{"jobName":"my_job","appName":"my_app","jobExecutionType":"TRANSIENT","cron":"0/5 * * * * ?","shardingTotalCount":3,"cpuCount":0.1,"memoryMB":64.0}' http://elasticjob_cloud_host:8899/api/job/register
概念 & 功能
调度模型
与大部分的作业平台不同,ElasticJob 的调度模型划分为支持线程级别调度的进程内调度 ElasticJob-Lite,和进程级别调度的 ElasticJob-Cloud。
进程内调度
ElasticJob-Lite 是面向进程内的线程级调度框架。通过它,作业能够透明化的与业务应用系统相结合。 它能够方便的与 Spring 、Dubbo 等 Java 框架配合使用,在作业中可自由使用 Spring 注入的 Bean,如数据源连接池、Dubbo 远程服务等,更加方便的贴合业务开发。
进程级调度
ElasticJob-Cloud 拥有进程内调度和进程级别调度两种方式。 由于 ElasticJob-Cloud 能够对作业服务器的资源进行控制,因此其作业类型可划分为常驻任务和瞬时任务。 常驻任务类似于 ElasticJob-Lite,是进程内调度;瞬时任务则完全不同,它充分的利用了资源分配的削峰填谷能力,是进程级的调度,每次任务的会启动全新的进程处理。
弹性调度
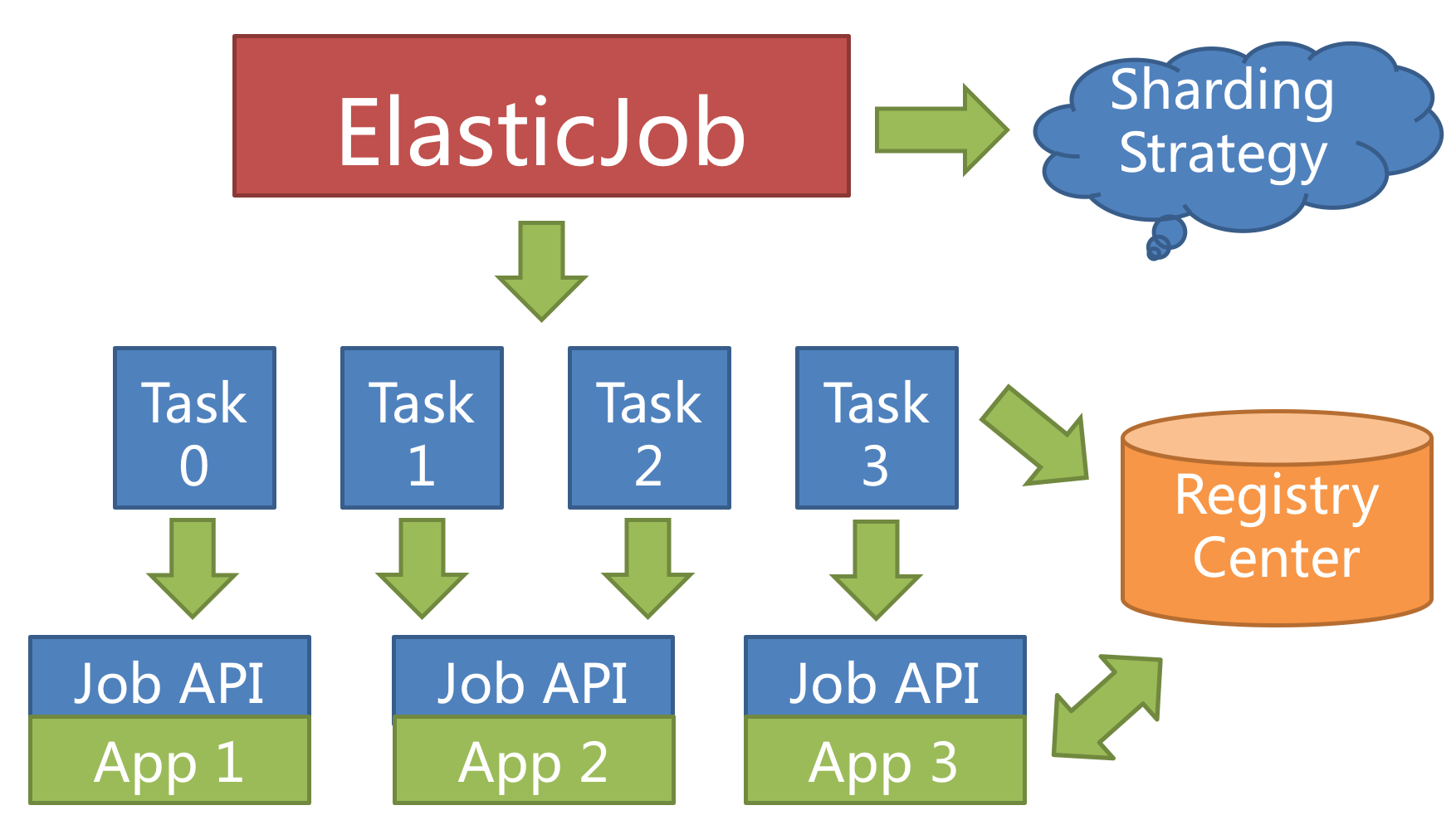
弹性调度是 ElasticJob 最重要的功能,也是这款产品名称的由来。 它是一款能够让任务通过分片进行水平扩展的任务处理系统。
分片
ElasticJob 中任务分片项的概念,使得任务可以在分布式的环境下运行,每台任务服务器只运行分配给该服务器的分片。 随着服务器的增加或宕机,ElasticJob 会近乎实时的感知服务器数量的变更,从而重新为分布式的任务服务器分配更加合理的任务分片项,使得任务可以随着资源的增加而提升效率。
任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。
举例说明,如果作业分为 4 片,用两台服务器执行,则每个服务器分到 2 片,分别负责作业的 50% 的负载,如下图所示。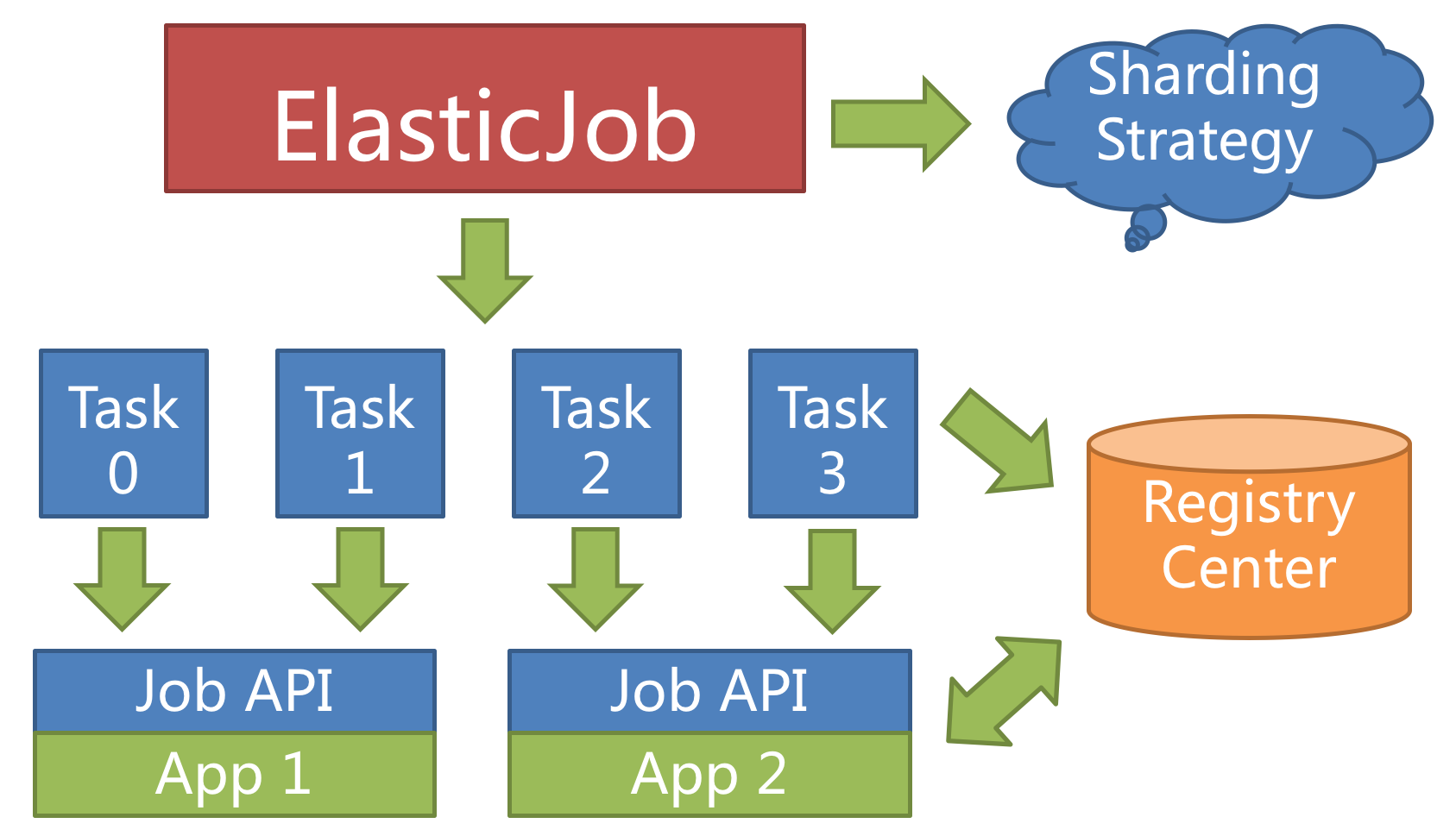
分片项
ElasticJob 并不直接提供数据处理的功能,而是将分片项分配至各个运行中的作业服务器,开发者需要自行处理分片项与业务的对应关系。 分片项为数字,始于 0 而终于分片总数减 1。
个性化分片参数
个性化参数可以和分片项匹配对应关系,用于将分片项的数字转换为更加可读的业务代码。
例如:按照地区水平拆分数据库,数据库 A 是北京的数据;数据库 B 是上海的数据;数据库 C 是广州的数据。 如果仅按照分片项配置,开发者需要了解 0 表示北京;1 表示上海;2 表示广州。 合理使用个性化参数可以让代码更可读,如果配置为 0=北京,1=上海,2=广州,那么代码中直接使用北京,上海,广州的枚举值即可完成分片项和业务逻辑的对应关系。资源最大限度利用
ElasticJob 提供最灵活的方式,最大限度的提高执行作业的吞吐量。 当新增加作业服务器时,ElasticJob 会通过注册中心的临时节点的变化感知到新服务器的存在,并在下次任务调度的时候重新分片,新的服务器会承载一部分作业分片,如下图所示。

将分片项设置为大于服务器的数量,最好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配分片项。
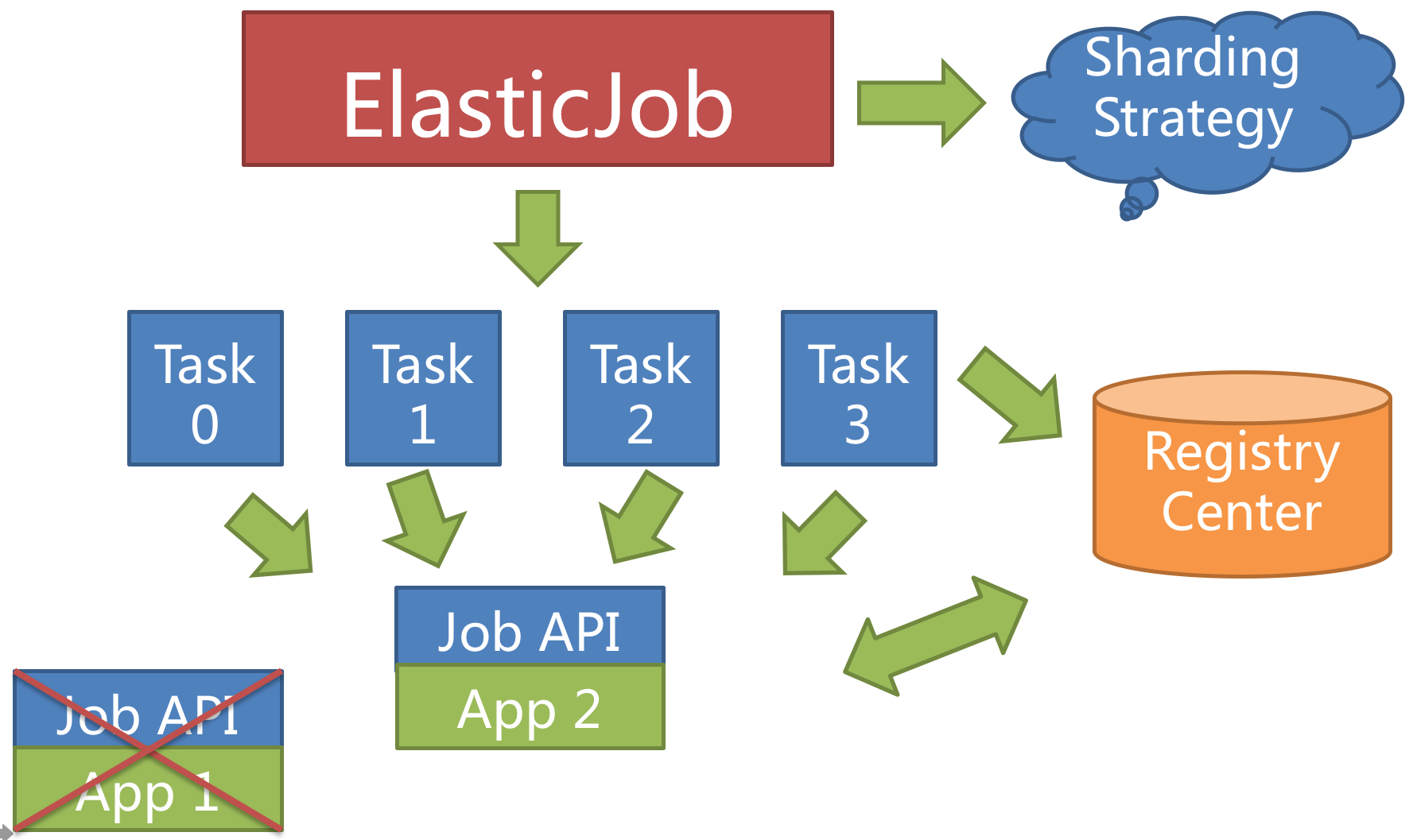
例如:3 台服务器,分成 10 片,则分片项分配结果为服务器 A = 0,1,2;服务器 B = 3,4,5;服务器 C = 6,7,8,9。 如果服务器 C 崩溃,则分片项分配结果为服务器 A = 0,1,2,3,4; 服务器 B = 5,6,7,8,9。 在不丢失分片项的情况下,最大限度的利用现有资源提高吞吐量。高可用
当作业服务器在运行中宕机时,注册中心同样会通过临时节点感知,并将在下次运行时将分片转移至仍存活的服务器,以达到作业高可用的效果。 本次由于服务器宕机而未执行完的作业,则可以通过失效转移的方式继续执行。如下图所示。

将分片总数设置为 1,并使用多于 1 台的服务器执行作业,作业将会以 1 主 n 从的方式执行。 一旦执行作业的服务器宕机,等待执行的服务器将会在下次作业启动时替补执行。开启失效转移功能效果更好,可以保证在本次作业在执行时宕机的情况下,备机立即启动替补执行。详细文档见官方文档

官网:https://shardingsphere.apache.org/elasticjob/index_zh.html
- 最新版文档:https://shardingsphere.apache.org/elasticjob/current/cn/overview/

若有收获,就点个赞吧
0 人点赞
