1. 网络收集电影数据-爬虫
电影天堂网爬取分析
网站: https://www.ttdytt.net/
无反爬虫限制,如下图:
分为如下:
- 动作电影 https://www.ttdytt.net/dongzuodianying/
- 科幻电影 https://www.ttdytt.net/kehuandianying/
- 恐怖电影 https://www.ttdytt.net/kongbudianying/
- 喜剧电影 https://www.ttdytt.net/xijudianying/
- 爱情电影 https://www.ttdytt.net/aiqingdianying/
- 剧情电影 https://www.ttdytt.net/juqingdianying/
- 战争电影 https://www.ttdytt.net/zhanzhengdianying/
- 动画片 https://www.ttdytt.net/donghuapian/
- 纪录片 https://www.ttdytt.net/jilupian/
以上每类电影都是一样的页面结构,按人气排序抓取比较方便。
动作电影-按人气:https://www.ttdytt.net/dongzuodianying/top/1.html
按人气页面分析:
分为两部分,上边是页面详情,下边是分页。然后页面详情取一个item。
先爬取总页数,然后分页爬取详情即可。
29视频网站爬取分析
网站:http://www.29spc.com
网站午
分为以下几个模块,每个模块都是一样的页面结构:
- 动作 http://www.29spc.com/dongzuo/
- 喜剧 http://www.29spc.com/xiju/
- 爱情 http://www.29spc.com/aiqing/
- 科幻 http://www.29spc.com/kehuan/
- 恐怖 http://www.29spc.com/kongbu/
- 战争 http://www.29spc.com/zhanzheng/
- 剧情 http://www.29spc.com/juqing/

上边是分页,下边是总页数,点击item打开是详情页,可以在线播放
在线播放是一个iframe
爬取思路:
先爬取总分页,然后分页爬取每个页面,然后每个页面的每个详情页,记录电影播放的iframe
电影天堂网站爬取分析
网站:https://www.ygdy8.net/
无反爬虫限制
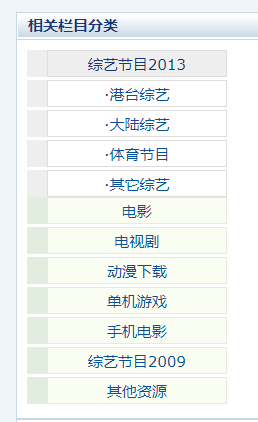
网站分为以下模块:
- 电影
- 电视剧
- 综艺
- 动漫资源 https://www.ygdy8.net/html/dongman/index.html
页面结构分析: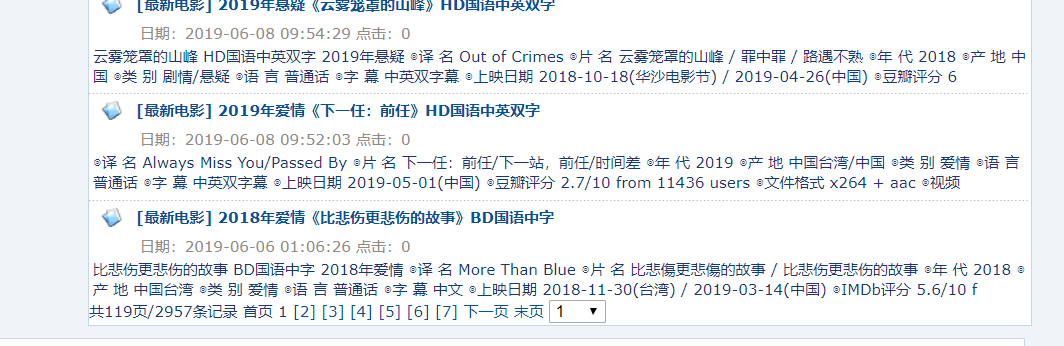
分页模式,上边是页面详情,下边是分页。先获得总页数,然后分页爬取即可。
电影,电视类别的都可以《》中获得电影名称如下图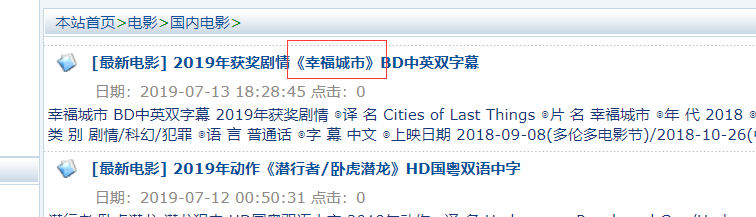
综艺和动漫需要去掉[]中的文字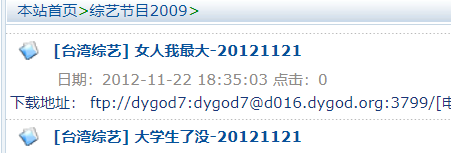
2. 存储
暂存MySQL,数据大了再优化。
3.界面展示,方便搜索

若有收获,就点个赞吧
0 人点赞
