准备测试数据库
准备一个数据库做测试
- 创建一个用户表做测试。这里遵循阿里巴巴开发规范,每个表创建都至少有id,create_time,update_time,deleted 四个字段,且命名方式使用下划线格式。
**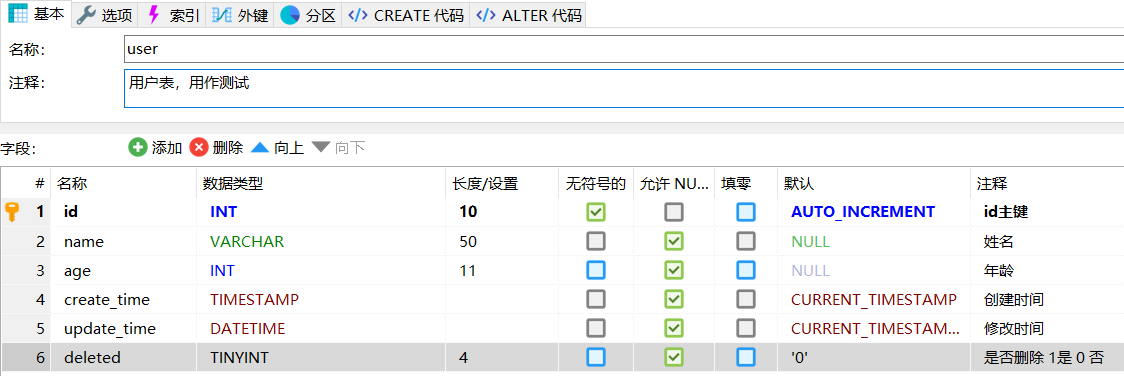
-- ---------------------------------------------------------- 主机: 127.0.0.1-- 服务器版本: 8.0.17 - MySQL Community Server - GPL-- 服务器操作系统: Win64-- 默认字符集: utf8mb4(由于历史原因,这个才是mysql真正的utf-8字符集)DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci-- ---------------------------------------------------------- test 的数据库结构CREATE DATABASE IF NOT EXISTS `test`-- 表 test.user 结构CREATE TABLE IF NOT EXISTS `user` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id主键',`name` varchar(50) DEFAULT NULL COMMENT '姓名',`age` int(11) DEFAULT NULL COMMENT '年龄',`create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',`deleted` tinyint(4) DEFAULT '0' COMMENT '是否删除 1是 0 否',PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户表,用作测试';
- 创建一个JavaBean,与数据库表对应。
//类名对应数据库表名,表示类和表绑定//类命名方式使用驼峰命名,表命名使用下划线命名,工具类会自动把驼峰命名转下划线命名,这里注意。// 如果数据库表名和类名不一致,使用注解来标识:@Table(value = "表名称",dataSource = "数据源名称"),//@Table("user")@Data //lombok插件的注解,帮你生成get,set等方法,推荐使用public class User implements DataBase {private Integer id;private String name;private Integer age;private LocalDate createTime;private LocalDate createTime1;private LocalDate createTime2;private LocalDate updateTime;private Boolean deleted;}
- 这里使用lombok插件,方便省略get,set方法,建议使用
- JDK8+以上版本,推荐使用LocalDate时间类型。
- 类名对应数据库表名,表示类和表绑定,类命名方式使用驼峰命名,表命名使用下划线命名,工具类会自动把驼峰命名转下划线命名,这里注意。如果数据库表名和类名不一致,使用注解来标识:@Table(value = “表名称”,dataSource = “数据源名称”)
- 实现DataBase接口即可,代表赋予User操作DataBase的能力。
只要你的Bean类implements DataBase就可以了,无其他操作,就可以使用我的工具类了,就这么简单,接下来开始使用吧。
执行SQL,复杂SQL,动态SQL
需求:我就想自己写个SQL,然后直接执行就行了。
执行修改操作的SQL
- Sql.sql(sql).execute(); //创建一个sql语句并执行,执行返回影响的数据行数
//执行修改操作的sql语句String sql = "INSERT INTO `test`.`user` (`name`, `age`) VALUES ('张三', '18')";int result = Sql.sql(sql).execute();assert result == 1;//执行带参数的sql//变量用${}或#{}表示//${} 为预编译sql,可以有效的防止sql注入//#{} 直接拼接参数,无法防止sql注入User user = new User();user.setName("张三");user.setAge(18);String sql = "INSERT INTO `test`.`user` (`name`, `age`) VALUES (${name},${age})";int result = Sql.sql(sql).setParams(user).execute();assert result == 1;Entity user = Entity.create().set("name", "张三").set("age", 16);String sql = "INSERT INTO `test`.`user` (`name`, `age`) VALUES (${name},${age})";int result = Sql.sql(sql).setParams(user).execute();assert result == 1;
注意:
- 变量用${}或#{}表示
- #{} 为预编译sql,可以有效的防止sql注入
- ${} 直接拼接参数,无法防止sql注入
execute()方法会根据sql只能判断是执行查询操作还是修改操作,当然你也可以手工指定查询操作executeQuery()或修改操作executeUpdate()
执行查询
Sql.sql(sql).setParams(user)execute(); //创建sql,然后设置查询参数,然后执行,执行返回查询的数据列表
//多条件查询参数,orm方式// 这个在开发中会由mvc框架反射前端传来的json自动生成User user = new User();user.setName("张三" + "%");user.setAge(18);List<User> list = Sql.sql("SELECT * FROM `user` WHERE `name` LIKE #{name} AND age >${age}").setParams(user).execute(); // execute方法会智能判断是查询sql还是修改sql//当然你也可以手动指定 调用查询sql 如下方式//.executeQuery();//输出[SQL] : SELECT * FROM `user` WHERE `name` LIKE '张三%' AND age >18//多条件查询参数,activeRecord方式// 这个在开发中会由mvc框架反射前端传来的json自动生成Entity params = Entity.create().set("name", "张三" + "%") //%表示模糊查询.set("age", 16);List<Entity> list = Sql.sql("SELECT * FROM `user` WHERE `name` LIKE #{name} AND age >${age}").setParams(params).execute(); // execute方法会智能判断是查询sql还是修改sql//当然你也可以手动指定 调用查询sql 如下方式//.executeQuery();//[SQL] : SELECT * FROM `user` WHERE `name` LIKE '张三%' AND age >16
执行复杂SQL或动态SQL
- append(String sql)方法表示追加sql
- append(boolean isnull,String sql) 表示isnull为true时,拼接sql ```java //多条件查询参数 // 这个在开发中会由mvc框架反射前端传来的json自动生成 Entity params = Entity.create() .set(“name”, “张三” + “%”) //%表示模糊查询 .set(“age”, 16) //时间格式支持LocalDateTime JDK8以上推荐使用这个 .set(“createTime1”, LocalDateTime.parse(“2019-11-22T15:11:45”)) .set(“createTime2”, LocalDateTime.parse(“2019-12-23T20:30:29”));
//时间格式支持字符串 // .set(“createTime1”, “2019-11-22T15:11:45”) // .set(“createTime2”,”2019-11-22T15:11:45”);
//时间格式支持Date对象 // .set(“createTime1”, new Date()) // .set(“createTime2”, new Date());
Listuser WHERE”)
.append(StrUtil.isNotEmpty(params.getStr(“name”)), “and name LIKE #{name}”)
.append(params.getInt(“age”) > 0, “AND age >${age}”)
.append(StrUtil.isNotEmpty(params.getStr(“createTime1”))
&& StrUtil.isNotEmpty(params.getStr(“createTime2”)),
“AND create_time BETWEEN ${createTime1} AND ${createTime2}”)
.setParams(params)
.execute(); // execute方法会智能判断是查询sql还是修改sql
//当然你也可以手动指定 调用查询sql 如下方式
// .executeQuery();
//输出[SQL] : SELECT FROM user WHERE name LIKE ‘张三%’ AND age >16
AND create_time BETWEEN ‘2019-11-22T15:11:45’ AND ‘2019-12-23T20:30:29’
<a name="WwPjs"></a>## 分页查询```java// 查询参数,这个在开发中会由mvc框架反射前端传来的json自动生成Entity params = Entity.create().set("name", "张三" + "%") //%表示模糊查询.set("age", 16);//分页参数 第一页,页面数据10条 排序字段: order by name asc,age descPage page = new Page(1, 10, "name asc,age desc");Page result = Sql.sql("SELECT * FROM `user` WHERE").append(StrUtil.isNotEmpty(params.getStr("name")), "and `name` LIKE #{name}").append(params.getInt("age") > 0, "AND age >${age}").append(StrUtil.isNotEmpty(params.getStr("createTime1"))&& StrUtil.isNotEmpty(params.getStr("createTime2")),"AND create_time BETWEEN ${createTime1} AND ${createTime2}").setParams(params)// .page(page);//或者直接传分页参数 等同于 page(page)方法.page(1, 10, "name asc,age desc");// [SQL] : SELECT COUNT(*) FROM (SELECT * FROM `user` WHERE `name` LIKE '张三%' AND age >16 ) temp//[SQL] : SELECT * FROM `user` WHERE `name` LIKE '张三%' AND age >16 ORDER BY name asc,age desc LIMIT 0,10System.out.println(JSONUtil.toJsonStr(result));
单表增删改查操作
需求:开发中90%以上时间都是对单笔进行curd操作,必须简化这部分代码。
添加并返回自增主键
- user.insert();
- Sql.sql().insert(entity); ```java //模拟数据 User user = new User(); user.setName(“张三”); user.setAge(20);
Boolean insert = user.insert();
assert insert;
//数据库设置自增主键的,插入成功会自动把id字段设置为主键值
//[执行SQL] : INSERT INTO user (name, age) VALUES (‘张三’, 20)
System.out.println(JSONUtil.toJsonStr(user)); //{“name”:”张三”,”id”:27,”age”:20}
```java//模拟数据Entity entity = Entity.create("user").set("name", "张三").set("age", 20);Boolean insert = Sql.sql().insert(entity);assert insert;//数据库设置自增主键的,插入成功会自动把id字段设置为主键值//[执行SQL] : INSERT INTO `user` (`name`, `age`) VALUES ('张三', 20)System.out.println(entity);//{tableName=`user`, fieldNames=null, fields={name=张三, age=20, id=28}}
批量插入数据
- Sql.sql().insertBatch(List
); - Sql.sql().insertBatch(List
); - Sql.sql**().insert(List
)**; - Sql.**sql().insert(List
**); - insertBatch()方法:批量提交插入,速度快,但是不返回主键
- insert()方法:一条一条循环插入,速度慢,会返回自增主键
- 都是原子性操作,要么都插入成功,要么都插入失败。 ```java //模拟数据 User u1 = new User(); u1.setName(“张三001”); u1.setAge(20);
User u2 = new User(); u2.setName(“张三002”); u2.setAge(22);
List
//批次插入,快速
Boolean insert = Sql.sql().insertBatch(list);
assert insert;
//[Batch SQL] -> INSERT INTO user (name, age) VALUES (?, ?)
System.out.println(JSONUtil.toJsonStr(list));
//[{“name”:”张三001”,”age”:20},{“name”:”张三002”,”age”:22}]
//循环插入,慢速
Boolean insert = Sql.sql().insert(list);
assert insert;
//[SQL] : INSERT INTO user (name, age) VALUES (‘张三001’, 20)
//[SQL] : INSERT INTO user (name, age) VALUES (‘张三002’, 22)
System.out.println(JSONUtil.toJsonStr(list));
//[{“name”:”张三001”,”id”:61,”age”:20},{“name”:”张三002”,”id”:62,”age”:22}]
```java//模拟数据Entity e1 = Entity.create("user").set("name", "张三001").set("age", 20);Entity e2 = new Entity("user").set("name", "张三002").set("age", 22);List<Entity> list = new ArrayList<>();list.add(e1);list.add(e2);//批次插入,快速Boolean insert = Sql.sql().insertBatch(list);assert insert;//[Batch SQL] -> INSERT INTO `user` (`name`, `age`) VALUES (?, ?)System.out.println(JSONUtil.toJsonStr(list));//[{"name":"张三001","age":20},{"name":"张三002","age":22}]//循环插入,慢速Boolean insert = Sql.sql().insert(list);assert insert;//[SQL] : INSERT INTO `user` (`name`, `age`) VALUES ('张三001', 20)//[SQL] : INSERT INTO `user` (`name`, `age`) VALUES ('张三002', 22)System.out.println(JSONUtil.toJsonStr(list));//[{"name":"张三001","id":55,"age":20},{"name":"张三002","id":56,"age":22}]
删除数据
//通过主键id删除Boolean delete = Sql.sql().deleteById("user", 2);//[执行SQL] : DELETE FROM user WHERE id =2User user = new User();user.setId(1);user.deleteById();//[执行SQL] : DELETE FROM user WHERE id =1//批量删除Boolean delete = Sql.sql().deleteByIds("user", 1, 2, 3);//[SQL] : DELETE FROM user WHERE id =?Boolean delete = new User().deleteByIds(4,5,6,7);//[SQL] : DELETE FROM user WHERE id =?//执行where条件删除User user = new User();user.setId(10);user.setAge(60);Sql where = Sql.sql("delete from user where id<${id} and age <${age}").setParams(user);Boolean delete = Sql.sql().delete( where);//[SQL] : delete from user WHERE id<10 and age <60
修改数据
////通过id修改数据,为空的字段不修改,只修改不为空的字段User user = new User();user.setId(11);user.setName("测试");Boolean update = user.updateById();assert update;//[SQL] : UPDATE `user` SET `name` = '测试' WHERE `id` = 11Entity entity = Entity.create("user").set("id", 11).set("name", "测试");Boolean update = Sql.sql().updateById(entity);assert update;//[SQL] : UPDATE `user` SET `name` = '测试' WHERE `id` = 11////批量修改,循环一条一条执行修改,效率慢User u1 = new User();u1.setId(11);u1.setName("测试");User u2 = new User();u2.setId(12);u2.setName("测试");List<User> list = new ArrayList<>();list.add(u1);list.add(u2);Boolean update = Sql.sql().update(list);//[SQL] : UPDATE `user` SET `name` = '测试' WHERE `id` = 11//[SQL] : UPDATE `user` SET `name` = '测试' WHERE `id` = 12Entity e1 = Entity.create("user").set("id", 11).set("name", "测试");Entity e2 = Entity.create("user").set("id", 12).set("name", "测试");List<Entity> list = new ArrayList<>();list.add(e1);list.add(e2);Boolean update = Sql.sql().update(list);//[SQL] : UPDATE `user` SET `name` = '测试' WHERE `id` = 11//[SQL] : UPDATE `user` SET `name` = '测试' WHERE `id` = 12
插入或更新数据
根据id查询,数据存在则更新,不存在则插入。
Entity entity = Entity.create("user").set("id", 86).set("name", "测试001").set("age", 45);Boolean result = Sql.sql().insertOrUpdate(entity);assert result;//第一次执行 不存在则执行插入//[SQL] : SELECT COUNT(*) FROM user WHERE id =86//[SQL] : INSERT INTO `user` (`id`, `name`, `age`) VALUES (86, '测试001', 45)//第二次执行 存在则修改//[SQL] : SELECT COUNT(*) FROM user WHERE id =86//[SQL] : UPDATE `user` SET `name` = '测试001' , `age` = 45 WHERE `id` = 86Entity entity = Entity.create("user").set("name", "测试001").set("age", 45);Boolean result = Sql.sql().insertOrUpdate(entity);assert result;//[SQL] : INSERT INTO `user` (`name`, `age`) VALUES ('测试001', 45)System.out.println(JSONUtil.toJsonStr(entity));//{"name":"测试001","age":45,"id":89}User user = new User();user.setId(100);user.setName("测试");user.setAge(56);Boolean result = user.insertOrUpdate();assert result;System.out.println(JSONUtil.toJsonStr(user));//第一次执行 不存在则执行插入//[SQL] : SELECT COUNT(*) FROM `user` WHERE id =100//[SQL] : INSERT INTO `user` (`id`, `name`, `age`) VALUES (100, '测试', 56)//第二次执行 存在则修改//[SQL] : SELECT COUNT(*) FROM `user` WHERE id =100//[SQL] : UPDATE `user` SET `name` = '测试' , `age` = 56 WHERE `id` = 100//{"name":"测试","id":100,"age":56}
通过id查询
Entity entity = Sql.sql().selectById("user", 30);System.out.println(JSONUtil.toJsonStr(entity));//[SQL] : SELECT * FROM user WHERE `id`=30User user = new User().selectById(30);System.out.println(JSONUtil.toJsonStr(user));//[SQL] : SELECT * FROM user WHERE `id`=30
事务
@Testvoid transaction() {Sql.sql().transaction(parameter -> {User user = new User();user.setId(100);user.setName("测试xxxxxxxxx");user.updateById();throw new RuntimeException("测试事务异常");//[SQL] : UPDATE `user` SET `name` = '测试xxxxxxxxx' WHERE `id` = 100//java.sql.SQLException: java.lang.RuntimeException: 测试事务异常});}//等同于上边写法 适合jdk8一下使用@Testvoid transaction1() {Sql.sql().transaction(new VoidFunc1<Db>() {@Overridepublic void call(Db parameter) throws Exception {User user = new User();user.setId(100);user.setName("测试xxxxxxxxx");user.updateById();throw new RuntimeException("测试事务异常");//[SQL] : UPDATE `user` SET `name` = '测试xxxxxxxxx' WHERE `id` = 100//java.sql.SQLException: java.lang.RuntimeException: 测试事务异常}});}//指定事务级别@Testvoid transactionLevel() {Sql.sql().transaction(READ_UNCOMMITTED, parameter -> {User user = new User();user.setId(100);user.setName("测试xxxxxxxxx");user.updateById();throw new RuntimeException("测试事务异常");//[SQL] : UPDATE `user` SET `name` = '测试xxxxxxxxx' WHERE `id` = 100//java.sql.SQLException: java.lang.RuntimeException: 测试事务异常});}
说明:
- 跟Spring集成,可以使用Spring的数据源,进而事务操作交给Spring处理即可(@Transactional )
- 事务级别如下
/*** 事务级别枚举** <p>* <b>脏读(Dirty Read)</b>:<br>* 一个事务会读到另一个事务更新后但未提交的数据,如果另一个事务回滚,那么当前事务读到的数据就是脏数据* <p>* <b>不可重复读(Non Repeatable Read)</b>:<br>* 在一个事务内,多次读同一数据,在这个事务还没有结束时,如果另一个事务恰好修改了这个数据,那么,在第一个事务中,两次读取的数据就可能不一致* <p>* <b>幻读(Phantom Read)</b>:<br>* 在一个事务中,第一次查询某条记录,发现没有,但是,当试图更新这条不存在的记录时,竟然能成功,且可以再次读取同一条记录。** @see Connection#TRANSACTION_NONE* @see Connection#TRANSACTION_READ_UNCOMMITTED* @see Connection#TRANSACTION_READ_COMMITTED* @see Connection#TRANSACTION_REPEATABLE_READ* @see Connection#TRANSACTION_SERIALIZABLE* @author looly* @since 4.1.2*/public enum TransactionLevel {/** 驱动不支持事务 */NONE(Connection.TRANSACTION_NONE),/*** 允许脏读、不可重复读和幻读* <p>* 在这种隔离级别下,一个事务会读到另一个事务更新后但未提交的数据,如果另一个事务回滚,那么当前事务读到的数据就是脏数据,这就是脏读(Dirty Read)*/READ_UNCOMMITTED(Connection.TRANSACTION_READ_UNCOMMITTED),/*** 禁止脏读,但允许不可重复读和幻读* <p>* 此级别下,一个事务可能会遇到不可重复读(Non Repeatable Read)的问题。<br>* 不可重复读是指,在一个事务内,多次读同一数据,在这个事务还没有结束时,如果另一个事务恰好修改了这个数据,那么,在第一个事务中,两次读取的数据就可能不一致。*/READ_COMMITTED(Connection.TRANSACTION_READ_COMMITTED),/*** 禁止脏读和不可重复读,但允许幻读,MySQL的InnoDB引擎默认使用此隔离级别。* <p>* 此级别下,一个事务可能会遇到幻读(Phantom Read)的问题。<br>* 幻读是指,在一个事务中,第一次查询某条记录,发现没有,但是,当试图更新这条不存在的记录时,可以成功,且可以再次读取同一条记录。*/REPEATABLE_READ(Connection.TRANSACTION_REPEATABLE_READ),/*** 禁止脏读、不可重复读和幻读* <p>* 虽然Serializable隔离级别下的事务具有最高的安全性,但是,由于事务是串行执行,所以效率会大大下降,应用程序的性能会急剧降低。*/SERIALIZABLE(Connection.TRANSACTION_SERIALIZABLE);/** 事务级别,对应Connection中的常量值 */private int level;TransactionLevel(int level) {this.level = level;}/*** 获取数据库事务级别int值** @return 数据库事务级别int值*/public int getLevel() {return this.level;}}
多数据源和适配各种数据库连接池
多数据源
# suppress inspection "Annotator" for whole file#===================================================================# 数据库配置文件样例# DsFactory默认读取的配置文件是config/db.setting# db.setting的配置包括两部分:基本连接信息和连接池配置信息。# 基本连接信息所有连接池都支持,连接池配置信息根据不同的连接池,连接池配置是根据连接池相应的配置项移植而来#===================================================================## 打印SQL的配置# 是否在日志中显示执行的SQL,默认falseshowSql = true# 是否格式化显示的SQL,默认falseformatSql = true# 是否显示SQL参数,默认falseshowParams = true# 打印SQL的日志等级,默认debugsqlLevel = debug# 默认数据源url = jdbc:sqlite:test.db# 测试数据源[test]url = jdbc:sqlite:test.db# 测试用HSQLDB数据库[hsqldb]url = jdbc:hsqldb:mem:mem_hutooluser = SApass =# 测试用Oracle数据库[orcl]url = jdbc:oracle:thin:@//looly.centos:1521/XEuser = loolypass = 123456[mysql]url = jdbc:mysql://looly.centos:3306/test_hutool?useSSL=falseuser = rootpass = 123456[postgre]url = jdbc:postgresql://looly.centos:5432/test_hutooluser = postgrespass = 123456[sqlserver]url = jdbc:sqlserver://looly.database.chinacloudapi.cn:1433;database=test;encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.chinacloudapi.cn;loginTimeout=30;user = looly@loolypass = 123
各种常见数据库连接池配置
基本配置样例
#------------------------------------------------------------------------------------------## 基本配置信息# JDBC URL,根据不同的数据库,使用相应的JDBC连接字符串url = jdbc:mysql://<host>:<port>/<database_name># 用户名,此处也可以使用 user 代替username = 用户名# 密码,此处也可以使用 pass 代替password = 密码# JDBC驱动名,可选(Hutool会自动识别)driver = com.mysql.jdbc.Driver## 可选配置# 是否在日志中显示执行的SQLshowSql = true# 是否格式化显示的SQLformatSql = false# 是否显示SQL参数showParams = true# 打印SQL的日志等级,默认debugsqlLevel = debug#------------------------------------------------------------------------------------------Copy to clipboardErrorCopied
HikariCP
## 连接池配置项# 自动提交autoCommit = true# 等待连接池分配连接的最大时长(毫秒),超过这个时长还没可用的连接则发生SQLException, 缺省:30秒connectionTimeout = 30000# 一个连接idle状态的最大时长(毫秒),超时则被释放(retired),缺省:10分钟idleTimeout = 600000# 一个连接的生命时长(毫秒),超时而且没被使用则被释放(retired),缺省:30分钟,建议设置比数据库超时时长少30秒,参考MySQL wait_timeout参数(show variables like '%timeout%';)maxLifetime = 1800000# 获取连接前的测试SQLconnectionTestQuery = SELECT 1# 最小闲置连接数minimumIdle = 10# 连接池中允许的最大连接数。缺省值:10;推荐的公式:((core_count * 2) + effective_spindle_count)maximumPoolSize = 10# 连接只读数据库时配置为true, 保证安全readOnly = falseCopy to clipboardErrorCopied
Druid
# 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时initialSize = 0# 最大连接池数量maxActive = 8# 最小连接池数量minIdle = 0# 获取连接时最大等待时间,单位毫秒。配置了maxWait之后, 缺省启用公平锁,并发效率会有所下降, 如果需要可以通过配置useUnfairLock属性为true使用非公平锁。maxWait = 0# 是否缓存preparedStatement,也就是PSCache。 PSCache对支持游标的数据库性能提升巨大,比如说oracle。 在mysql5.5以下的版本中没有PSCache功能,建议关闭掉。作者在5.5版本中使用PSCache,通过监控界面发现PSCache有缓存命中率记录, 该应该是支持PSCache。poolPreparedStatements = false# 要启用PSCache,必须配置大于0,当大于0时, poolPreparedStatements自动触发修改为true。 在Druid中,不会存在Oracle下PSCache占用内存过多的问题, 可以把这个数值配置大一些,比如说100maxOpenPreparedStatements = -1# 用来检测连接是否有效的sql,要求是一个查询语句。 如果validationQuery为null,testOnBorrow、testOnReturn、 testWhileIdle都不会其作用。validationQuery = SELECT 1# 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。testOnBorrow = true# 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能testOnReturn = false# 建议配置为true,不影响性能,并且保证安全性。 申请连接的时候检测,如果空闲时间大于 timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。testWhileIdle = false# 有两个含义: 1) Destroy线程会检测连接的间隔时间 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明timeBetweenEvictionRunsMillis = 60000# 物理连接初始化的时候执行的sqlconnectionInitSqls = SELECT 1# 属性类型是字符串,通过别名的方式配置扩展插件, 常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wallfilters = stat# 类型是List<com.alibaba.druid.filter.Filter>, 如果同时配置了filters和proxyFilters, 是组合关系,并非替换关系proxyFilters = Copy to clipboardErrorCopied
Tomcat JDBC Pool
# (boolean) 连接池创建的连接的默认的auto-commit 状态defaultAutoCommit = true# (boolean) 连接池创建的连接的默认的read-only 状态。 如果没有设置则setReadOnly 方法将不会被调用。 ( 某些驱动不支持只读模式, 比如:Informix)defaultReadOnly = false# (String) 连接池创建的连接的默认的TransactionIsolation 状态。 下面列表当中的某一个: ( 参考javadoc) NONE READ_COMMITTED EAD_UNCOMMITTED REPEATABLE_READ SERIALIZABLEdefaultTransactionIsolation = NONE# (int) 初始化连接: 连接池启动时创建的初始化连接数量,1。2 版本后支持initialSize = 10# (int) 最大活动连接: 连接池在同一时间能够分配的最大活动连接的数量, 如果设置为非正数则表示不限制maxActive = 100# (int) 最大空闲连接: 连接池中容许保持空闲状态的最大连接数量, 超过的空闲连接将被释放, 如果设置为负数表示不限制 如果启用,将定期检查限制连接,如果空闲时间超过minEvictableIdleTimeMillis 则释放连接 ( 参考testWhileIdle )maxIdle = 8# (int) 最小空闲连接: 连接池中容许保持空闲状态的最小连接数量, 低于这个数量将创建新的连接, 如果设置为0 则不创建 如果连接验证失败将缩小这个值( 参考testWhileIdle )minIdle = 0# (int) 最大等待时间: 当没有可用连接时, 连接池等待连接被归还的最大时间( 以毫秒计数), 超过时间则抛出异常, 如果设置为-1 表示无限等待maxWait = 30000# (String) SQL 查询, 用来验证从连接池取出的连接, 在将连接返回给调用者之前。 如果指定, 则查询必须是一个SQL SELECT 并且必须返回至少一行记录 查询不必返回记录,但这样将不能抛出SQL异常validationQuery = SELECT 1# (boolean) 指明是否在从池中取出连接前进行检验, 如果检验失败, 则从池中去除连接并尝试取出另一个。注意: 设置为true 后如果要生效,validationQuery 参数必须设置为非空字符串 参考validationInterval以获得更有效的验证testOnBorrow = false# (boolean) 指明是否在归还到池中前进行检验 注意: 设置为true 后如果要生效,validationQuery 参数必须设置为非空字符串testOnReturn = false# (boolean) 指明连接是否被空闲连接回收器( 如果有) 进行检验。 如果检测失败, 则连接将被从池中去除。注意: 设置为true 后如果要生效,validationQuery 参数必须设置为非空字符串testWhileIdle = falseCopy to clipboardErrorCopied
C3P0(不推荐)
# 连接池中保留的最大连接数。默认值: 15maxPoolSize = 15# 连接池中保留的最小连接数,默认为:3minPoolSize = 3# 初始化连接池中的连接数,取值应在minPoolSize与maxPoolSize之间,默认为3initialPoolSize = 3# 最大空闲时间,60秒内未使用则连接被丢弃。若为0则永不丢弃。默认值: 0maxIdleTime = 0# 当连接池连接耗尽时,客户端调用getConnection()后等待获取新连接的时间,超时后将抛出SQLException,如设为0则无限期等待。单位毫秒。默认: 0checkoutTimeout = 0# 当连接池中的连接耗尽的时候c3p0一次同时获取的连接数。默认值: 3acquireIncrement = 3# 定义在从数据库获取新连接失败后重复尝试的次数。默认值: 30 ;小于等于0表示无限次acquireRetryAttempts = 0# 重新尝试的时间间隔,默认为:1000毫秒acquireRetryDelay = 1000# 关闭连接时,是否提交未提交的事务,默认为false,即关闭连接,回滚未提交的事务autoCommitOnClose = false# c3p0将建一张名为Test的空表,并使用其自带的查询语句进行测试。如果定义了这个参数那么属性preferredTestQuery将被忽略。你不能在这张Test表上进行任何操作,它将只供c3p0测试使用。默认值: nullautomaticTestTable = null# 如果为false,则获取连接失败将会引起所有等待连接池来获取连接的线程抛出异常,但是数据源仍有效保留,并在下次调用getConnection()的时候继续尝试获取连接。如果设为true,那么在尝试获取连接失败后该数据源将申明已断开并永久关闭。默认: falsebreakAfterAcquireFailure = false# 检查所有连接池中的空闲连接的检查频率。默认值: 0,不检查idleConnectionTestPeriod = 0# c3p0全局的PreparedStatements缓存的大小。如果maxStatements与maxStatementsPerConnection均为0,则缓存不生效,只要有一个不为0,则语句的缓存就能生效。如果默认值: 0maxStatements = 0# maxStatementsPerConnection定义了连接池内单个连接所拥有的最大缓存statements数。默认值: 0maxStatementsPerConnection = 0Copy to clipboardErrorCopied
DBCP(不推荐)
# (boolean) 连接池创建的连接的默认的auto-commit 状态defaultAutoCommit = true# (boolean) 连接池创建的连接的默认的read-only 状态。 如果没有设置则setReadOnly 方法将不会被调用。 ( 某些驱动不支持只读模式, 比如:Informix)defaultReadOnly = false# (String) 连接池创建的连接的默认的TransactionIsolation 状态。 下面列表当中的某一个: ( 参考javadoc) NONE READ_COMMITTED EAD_UNCOMMITTED REPEATABLE_READ SERIALIZABLEdefaultTransactionIsolation = NONE# (int) 初始化连接: 连接池启动时创建的初始化连接数量,1。2 版本后支持initialSize = 10# (int) 最大活动连接: 连接池在同一时间能够分配的最大活动连接的数量, 如果设置为非正数则表示不限制maxActive = 100# (int) 最大空闲连接: 连接池中容许保持空闲状态的最大连接数量, 超过的空闲连接将被释放, 如果设置为负数表示不限制 如果启用,将定期检查限制连接,如果空闲时间超过minEvictableIdleTimeMillis 则释放连接 ( 参考testWhileIdle )maxIdle = 8# (int) 最小空闲连接: 连接池中容许保持空闲状态的最小连接数量, 低于这个数量将创建新的连接, 如果设置为0 则不创建 如果连接验证失败将缩小这个值( 参考testWhileIdle )minIdle = 0# (int) 最大等待时间: 当没有可用连接时, 连接池等待连接被归还的最大时间( 以毫秒计数), 超过时间则抛出异常, 如果设置为-1 表示无限等待maxWait = 30000# (String) SQL 查询, 用来验证从连接池取出的连接, 在将连接返回给调用者之前。 如果指定, 则查询必须是一个SQL SELECT 并且必须返回至少一行记录 查询不必返回记录,但这样将不能抛出SQL异常validationQuery = SELECT 1# (boolean) 指明是否在从池中取出连接前进行检验, 如果检验失败, 则从池中去除连接并尝试取出另一个。注意: 设置为true 后如果要生效,validationQuery 参数必须设置为非空字符串 参考validationInterval以获得更有效的验证testOnBorrow = false# (boolean) 指明是否在归还到池中前进行检验 注意: 设置为true 后如果要生效,validationQuery 参数必须设置为非空字符串testOnReturn = false# (boolean) 指明连接是否被空闲连接回收器( 如果有) 进行检验。 如果检测失败, 则连接将被从池中去除。注意: 设置为true 后如果要生效,validationQuery 参数必须设置为非空字符串testWhileIdle = false
扩展开发
- 面向接口编程,而非面向对象编程,这样可以避免Java单继承的尴尬
- 方法大于对象,静态方式直接使用,而非new一个对象再使用方法
- 工具类大于框架,引入该工具类简单快捷,不跟任何框架冲突
- 极简设计,极致轻量,极致速度
实现方式:
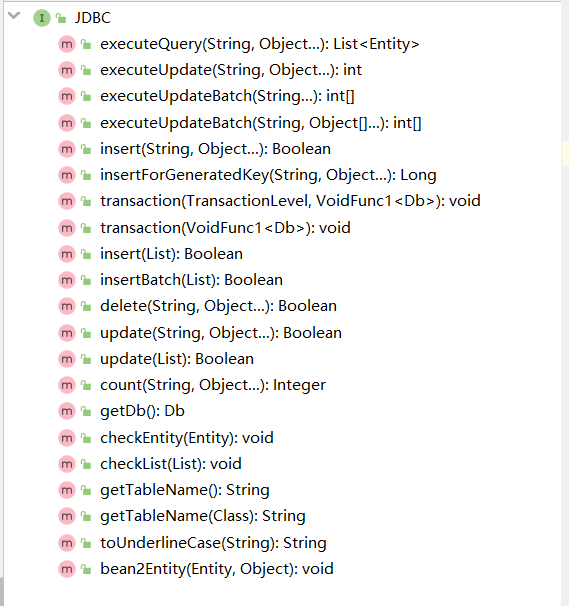
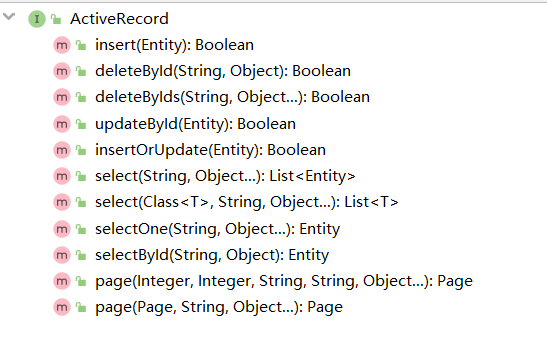
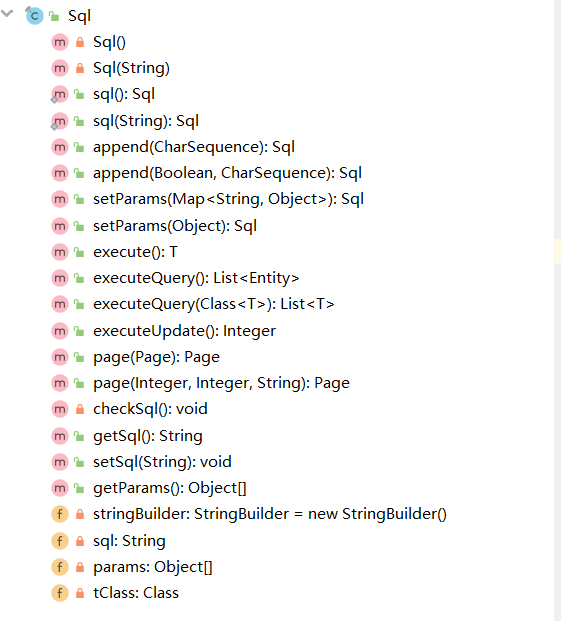
- 总共三个接口,分别代表JDBC方式,ORM方式,ActiveRecord方式
- interface JDBC:封装JDBC方式操作数据库,,实现该接口表示赋予类操作数据库的能力
- interface ORM extends JDBC:封装ORM方式操作数据库,实现该接口表示赋予类操作数据库的能力
- ORM(对象关系映射):一条数据映射为一个Bean对象,多条数据映射为List
- ORM(对象关系映射):一条数据映射为一个Bean对象,多条数据映射为List
- interface ActiveRecord extends JDBC:封装ActiveRecord方式操作数据库,实现该接口表示赋予类操作数据库的能力
- ActiveRecord(活动记录):一条数据映射为一个Map
- ActiveRecord(活动记录):一条数据映射为一个Map
- 提供一个负载SQL的实现方式:class Sql implements ActiveRecord ,封装SQL执行等操作。

该工具的缺陷
- 时间有限(前后抽空写了11天),仅实现了MySQL语法(因为现在主要用mysql),其他关系型数据库慢慢支持
- 希望大佬能实现其他数据库的语法
- 贡献代码流程:fork本代码,修改后提交,然后到github页面 pull request给我,等邮件合并通知
- QQ交流群:967073790
#------------------------------------------------------------------------------------------## 基本配置信息# JDBC URL,根据不同的数据库,使用相应的JDBC连接字符串url = jdbc:mysql://<host>:<port>/<database_name># 用户名,此处也可以使用 user 代替username = 用户名# 密码,此处也可以使用 pass 代替password = 密码# JDBC驱动名,可选(Hutool会自动识别)driver = com.mysql.jdbc.Driver## 可选配置# 是否在日志中显示执行的SQLshowSql = true# 是否格式化显示的SQLformatSql = false# 是否显示SQL参数showParams = true# 打印SQL的日志等级,默认debugsqlLevel = debug#------------------------------------------------------------------------------------------Copy to clipboardErrorCopied
## 连接池配置项# 自动提交autoCommit = true# 等待连接池分配连接的最大时长(毫秒),超过这个时长还没可用的连接则发生SQLException, 缺省:30秒connectionTimeout = 30000# 一个连接idle状态的最大时长(毫秒),超时则被释放(retired),缺省:10分钟idleTimeout = 600000# 一个连接的生命时长(毫秒),超时而且没被使用则被释放(retired),缺省:30分钟,建议设置比数据库超时时长少30秒,参考MySQL wait_timeout参数(show variables like '%timeout%';)maxLifetime = 1800000# 获取连接前的测试SQLconnectionTestQuery = SELECT 1# 最小闲置连接数minimumIdle = 10# 连接池中允许的最大连接数。缺省值:10;推荐的公式:((core_count * 2) + effective_spindle_count)maximumPoolSize = 10# 连接只读数据库时配置为true, 保证安全readOnly = falseCopy to clipboardErrorCopied
# 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时initialSize = 0# 最大连接池数量maxActive = 8# 最小连接池数量minIdle = 0# 获取连接时最大等待时间,单位毫秒。配置了maxWait之后, 缺省启用公平锁,并发效率会有所下降, 如果需要可以通过配置useUnfairLock属性为true使用非公平锁。maxWait = 0# 是否缓存preparedStatement,也就是PSCache。 PSCache对支持游标的数据库性能提升巨大,比如说oracle。 在mysql5.5以下的版本中没有PSCache功能,建议关闭掉。作者在5.5版本中使用PSCache,通过监控界面发现PSCache有缓存命中率记录, 该应该是支持PSCache。poolPreparedStatements = false# 要启用PSCache,必须配置大于0,当大于0时, poolPreparedStatements自动触发修改为true。 在Druid中,不会存在Oracle下PSCache占用内存过多的问题, 可以把这个数值配置大一些,比如说100maxOpenPreparedStatements = -1# 用来检测连接是否有效的sql,要求是一个查询语句。 如果validationQuery为null,testOnBorrow、testOnReturn、 testWhileIdle都不会其作用。validationQuery = SELECT 1# 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。testOnBorrow = true# 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能testOnReturn = false# 建议配置为true,不影响性能,并且保证安全性。 申请连接的时候检测,如果空闲时间大于 timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。testWhileIdle = false# 有两个含义: 1) Destroy线程会检测连接的间隔时间 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明timeBetweenEvictionRunsMillis = 60000# 物理连接初始化的时候执行的sqlconnectionInitSqls = SELECT 1# 属性类型是字符串,通过别名的方式配置扩展插件, 常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wallfilters = stat# 类型是List<com.alibaba.druid.filter.Filter>, 如果同时配置了filters和proxyFilters, 是组合关系,并非替换关系proxyFilters = Copy to clipboardErrorCopied
# (boolean) 连接池创建的连接的默认的auto-commit 状态defaultAutoCommit = true# (boolean) 连接池创建的连接的默认的read-only 状态。 如果没有设置则setReadOnly 方法将不会被调用。 ( 某些驱动不支持只读模式, 比如:Informix)defaultReadOnly = false# (String) 连接池创建的连接的默认的TransactionIsolation 状态。 下面列表当中的某一个: ( 参考javadoc) NONE READ_COMMITTED EAD_UNCOMMITTED REPEATABLE_READ SERIALIZABLEdefaultTransactionIsolation = NONE# (int) 初始化连接: 连接池启动时创建的初始化连接数量,1。2 版本后支持initialSize = 10# (int) 最大活动连接: 连接池在同一时间能够分配的最大活动连接的数量, 如果设置为非正数则表示不限制maxActive = 100# (int) 最大空闲连接: 连接池中容许保持空闲状态的最大连接数量, 超过的空闲连接将被释放, 如果设置为负数表示不限制 如果启用,将定期检查限制连接,如果空闲时间超过minEvictableIdleTimeMillis 则释放连接 ( 参考testWhileIdle )maxIdle = 8# (int) 最小空闲连接: 连接池中容许保持空闲状态的最小连接数量, 低于这个数量将创建新的连接, 如果设置为0 则不创建 如果连接验证失败将缩小这个值( 参考testWhileIdle )minIdle = 0# (int) 最大等待时间: 当没有可用连接时, 连接池等待连接被归还的最大时间( 以毫秒计数), 超过时间则抛出异常, 如果设置为-1 表示无限等待maxWait = 30000# (String) SQL 查询, 用来验证从连接池取出的连接, 在将连接返回给调用者之前。 如果指定, 则查询必须是一个SQL SELECT 并且必须返回至少一行记录 查询不必返回记录,但这样将不能抛出SQL异常validationQuery = SELECT 1# (boolean) 指明是否在从池中取出连接前进行检验, 如果检验失败, 则从池中去除连接并尝试取出另一个。注意: 设置为true 后如果要生效,validationQuery 参数必须设置为非空字符串 参考validationInterval以获得更有效的验证testOnBorrow = false# (boolean) 指明是否在归还到池中前进行检验 注意: 设置为true 后如果要生效,validationQuery 参数必须设置为非空字符串testOnReturn = false# (boolean) 指明连接是否被空闲连接回收器( 如果有) 进行检验。 如果检测失败, 则连接将被从池中去除。注意: 设置为true 后如果要生效,validationQuery 参数必须设置为非空字符串testWhileIdle = falseCopy to clipboardErrorCopied
# 连接池中保留的最大连接数。默认值: 15maxPoolSize = 15# 连接池中保留的最小连接数,默认为:3minPoolSize = 3# 初始化连接池中的连接数,取值应在minPoolSize与maxPoolSize之间,默认为3initialPoolSize = 3# 最大空闲时间,60秒内未使用则连接被丢弃。若为0则永不丢弃。默认值: 0maxIdleTime = 0# 当连接池连接耗尽时,客户端调用getConnection()后等待获取新连接的时间,超时后将抛出SQLException,如设为0则无限期等待。单位毫秒。默认: 0checkoutTimeout = 0# 当连接池中的连接耗尽的时候c3p0一次同时获取的连接数。默认值: 3acquireIncrement = 3# 定义在从数据库获取新连接失败后重复尝试的次数。默认值: 30 ;小于等于0表示无限次acquireRetryAttempts = 0# 重新尝试的时间间隔,默认为:1000毫秒acquireRetryDelay = 1000# 关闭连接时,是否提交未提交的事务,默认为false,即关闭连接,回滚未提交的事务autoCommitOnClose = false# c3p0将建一张名为Test的空表,并使用其自带的查询语句进行测试。如果定义了这个参数那么属性preferredTestQuery将被忽略。你不能在这张Test表上进行任何操作,它将只供c3p0测试使用。默认值: nullautomaticTestTable = null# 如果为false,则获取连接失败将会引起所有等待连接池来获取连接的线程抛出异常,但是数据源仍有效保留,并在下次调用getConnection()的时候继续尝试获取连接。如果设为true,那么在尝试获取连接失败后该数据源将申明已断开并永久关闭。默认: falsebreakAfterAcquireFailure = false# 检查所有连接池中的空闲连接的检查频率。默认值: 0,不检查idleConnectionTestPeriod = 0# c3p0全局的PreparedStatements缓存的大小。如果maxStatements与maxStatementsPerConnection均为0,则缓存不生效,只要有一个不为0,则语句的缓存就能生效。如果默认值: 0maxStatements = 0# maxStatementsPerConnection定义了连接池内单个连接所拥有的最大缓存statements数。默认值: 0maxStatementsPerConnection = 0Copy to clipboardErrorCopied
# (boolean) 连接池创建的连接的默认的auto-commit 状态defaultAutoCommit = true# (boolean) 连接池创建的连接的默认的read-only 状态。 如果没有设置则setReadOnly 方法将不会被调用。 ( 某些驱动不支持只读模式, 比如:Informix)defaultReadOnly = false# (String) 连接池创建的连接的默认的TransactionIsolation 状态。 下面列表当中的某一个: ( 参考javadoc) NONE READ_COMMITTED EAD_UNCOMMITTED REPEATABLE_READ SERIALIZABLEdefaultTransactionIsolation = NONE# (int) 初始化连接: 连接池启动时创建的初始化连接数量,1。2 版本后支持initialSize = 10# (int) 最大活动连接: 连接池在同一时间能够分配的最大活动连接的数量, 如果设置为非正数则表示不限制maxActive = 100# (int) 最大空闲连接: 连接池中容许保持空闲状态的最大连接数量, 超过的空闲连接将被释放, 如果设置为负数表示不限制 如果启用,将定期检查限制连接,如果空闲时间超过minEvictableIdleTimeMillis 则释放连接 ( 参考testWhileIdle )maxIdle = 8# (int) 最小空闲连接: 连接池中容许保持空闲状态的最小连接数量, 低于这个数量将创建新的连接, 如果设置为0 则不创建 如果连接验证失败将缩小这个值( 参考testWhileIdle )minIdle = 0# (int) 最大等待时间: 当没有可用连接时, 连接池等待连接被归还的最大时间( 以毫秒计数), 超过时间则抛出异常, 如果设置为-1 表示无限等待maxWait = 30000# (String) SQL 查询, 用来验证从连接池取出的连接, 在将连接返回给调用者之前。 如果指定, 则查询必须是一个SQL SELECT 并且必须返回至少一行记录 查询不必返回记录,但这样将不能抛出SQL异常validationQuery = SELECT 1# (boolean) 指明是否在从池中取出连接前进行检验, 如果检验失败, 则从池中去除连接并尝试取出另一个。注意: 设置为true 后如果要生效,validationQuery 参数必须设置为非空字符串 参考validationInterval以获得更有效的验证testOnBorrow = false# (boolean) 指明是否在归还到池中前进行检验 注意: 设置为true 后如果要生效,validationQuery 参数必须设置为非空字符串testOnReturn = false# (boolean) 指明连接是否被空闲连接回收器( 如果有) 进行检验。 如果检测失败, 则连接将被从池中去除。注意: 设置为true 后如果要生效,validationQuery 参数必须设置为非空字符串testWhileIdle = false

若有收获,就点个赞吧
0 人点赞
