解决问题?
海量的结构化数据存储
本文档来自 阿里云 表格存储 Tablestore ,思想是一样的,这里摘抄一下,开源版对标hbase
宽表模式
宽表整体架构来自于Google的BigTable,在开源领域的实现有HBase等,非开源领域,一般由云厂商提供Serverless付费版。如下阿里云的:TableStore
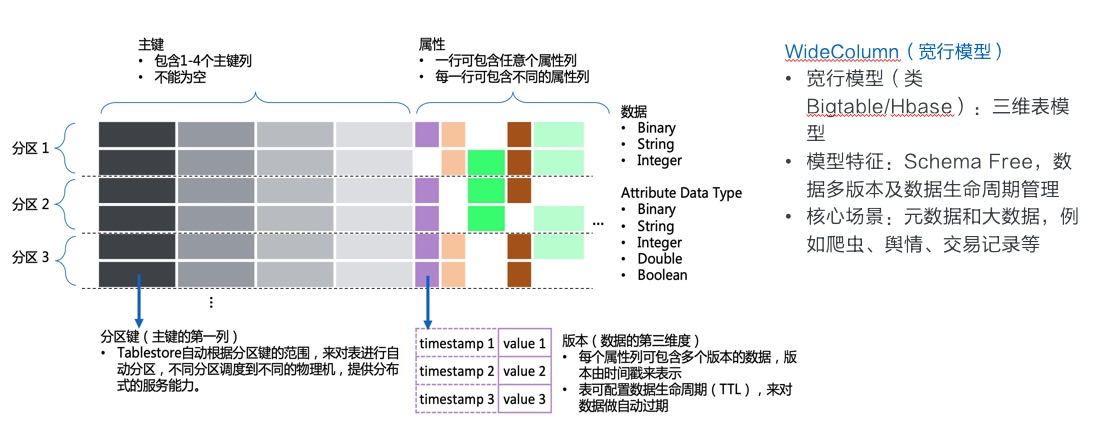
数据模型可以定义为宽行模型,如下图所示。其中不同的分区可以加载到不同的机器上,实现水平扩展:
- 宽表结构还是遵循基本的表结构,即由行和列组成,关系型数据库的表结构列是固定的,行是可变的,宽表结构,行和列都是可变的。
- 每条数据必须提供主键,根据主键计算散列分布到不同的机器上,达到分布式存储的目的,主键可以是多个属性的拼接,阿里的TablesStore之间设置了4个列,一定程度上方便业务主键堆叠。
- 根据主键划分分区,本质就是哈希函数计算指纹,分布到不同的机器。
- 每行可以有不同个属性列,类json存储,方便压缩,每一个列可以设置多个时间版本。
优点:
- 海量数据存储,无上限
- 超高并发,横向分布式扩展,只要机器够,并发可以认为无上限
缺点:
1.肯定不支持事务
2.查询只支持简单的k-v查询,和部分主键扫描方式查询
加速查询:
- 全局二级索引
- 多元索引
Timeline模型
Timeline模型是针对消息数据场景所设计的,能够满足消息数据场景对消息保序、海量消息存储、实时同步的特殊需求,同时支持全文检索与多维度组合查询。可以同时应用在IM、Feed流等消息场景的实现上。模型结构
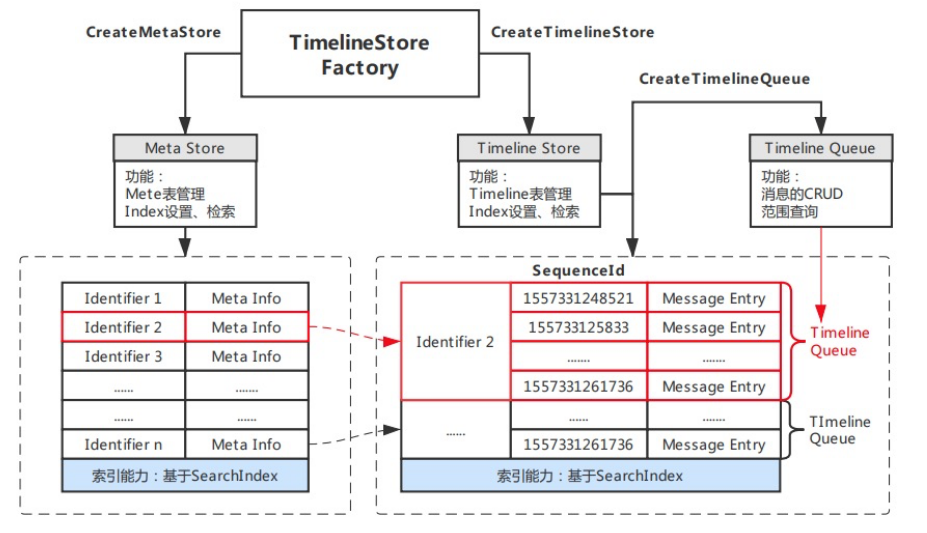
Timeline模型以简单为设计目标,核心模块构成比较清晰明了。模型尽量提升使用的自由度,让您能够根据自身场景需求选择更为合适的实现。模型的架构主要包括:
- Store:Timeline存储库,类似数据库的表的概念。
- Identifier:用于区分Timeline的唯一标识。
- Meta:用于描述Timeline的元数据,元数据描述采用free-schema结构,可自由包含任意列。
- Queue:一个Timeline内所有Message存储在Queue内。
- SequenceId:Queue中消息体的序列号,需保证递增、唯一。模型支持自增列、自定义两种实现模式。
- Message:Timeline内传递的消息体,是一个free-schema的结构,可自由包含任意列。
- Index:包含Meta Index和Message Index,可对Meta或Message内的任意列自定义索引,提供灵活的多条件组合查询和搜索。
Timestream模型
Timestream是针对时序场景设计的模型,本文主要为您介绍Timestream模型及其应用。
抽象模型
您可以通过Timestream的抽象模型对Timestream进行初步了解。
| 组成部分 | 描述 |
|---|---|
| 个体或群体(WHO) | 描述产生数据的物体,可以是人、监控指标或者物体。个体或群体会有多维的属性,某一类唯一ID可以定位到个体,例如身份ID定位到人、设备ID定位到设备。维属性可以定位到个体,例如通过集群、机器ID、进程名来定位到某个进程。 |
| 时间(WHEN) | 时间是时序数据最重要的特征,是区别于其他数据的关键属性。 |
| 时空(WHERE) | 时空通常是通过纬度二维坐标定位到地点。科学计算领域(例如气象)通过经纬度和高度三维坐标来定位。 |
| 状态(WHAT) | 用于描述特定个体在某一刻的状态,监控类时序数据通常是数值类型描述状态,轨迹数据是通过事件表述状态,不同场景有不同的表述方式。 |
完整模型
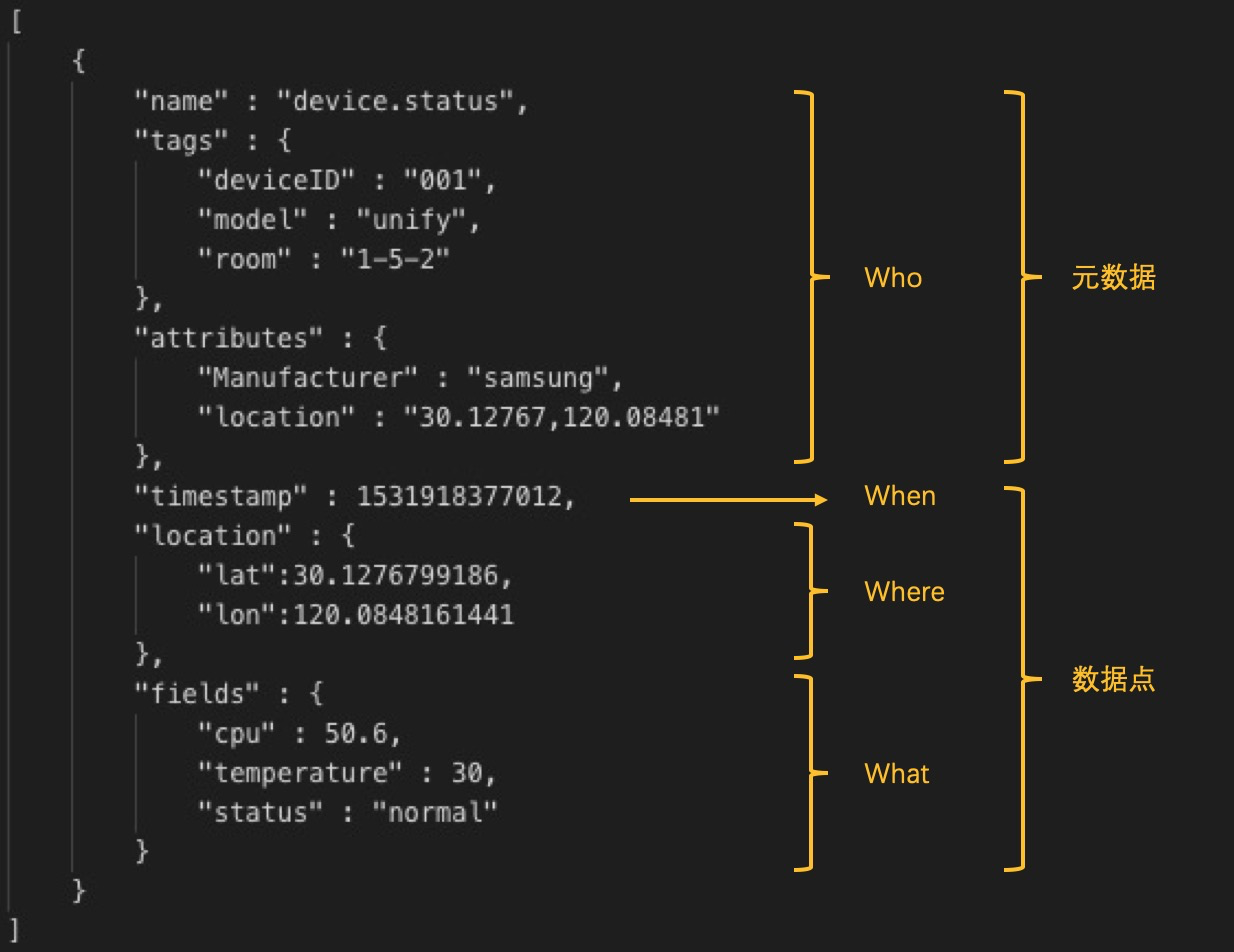
时序数据包含元数据和数据点两个部分。
- 元数据:由Name、Tags以及Attributes组成。Name+Tags可以唯一确定某个元数据。
- 数据点:由Timestamp、Location以及Fields组成。 | 元素 | 描述 | | :—- | :—- | | Name | 定义数据的类别 | | Tags | 唯一标识个体的元数据 | | Attributes | 个体的可变属性 | | Timestamp | 数据产生的时间戳 | | Location | 数据产生的空间信息 | | Fields | 数据对应的值或状态,可提供多个值或状态,非一定是数值类型 |
应用案例
本案例通过事件类的物流轨迹场景展示Timestream数据模型是如何使用的。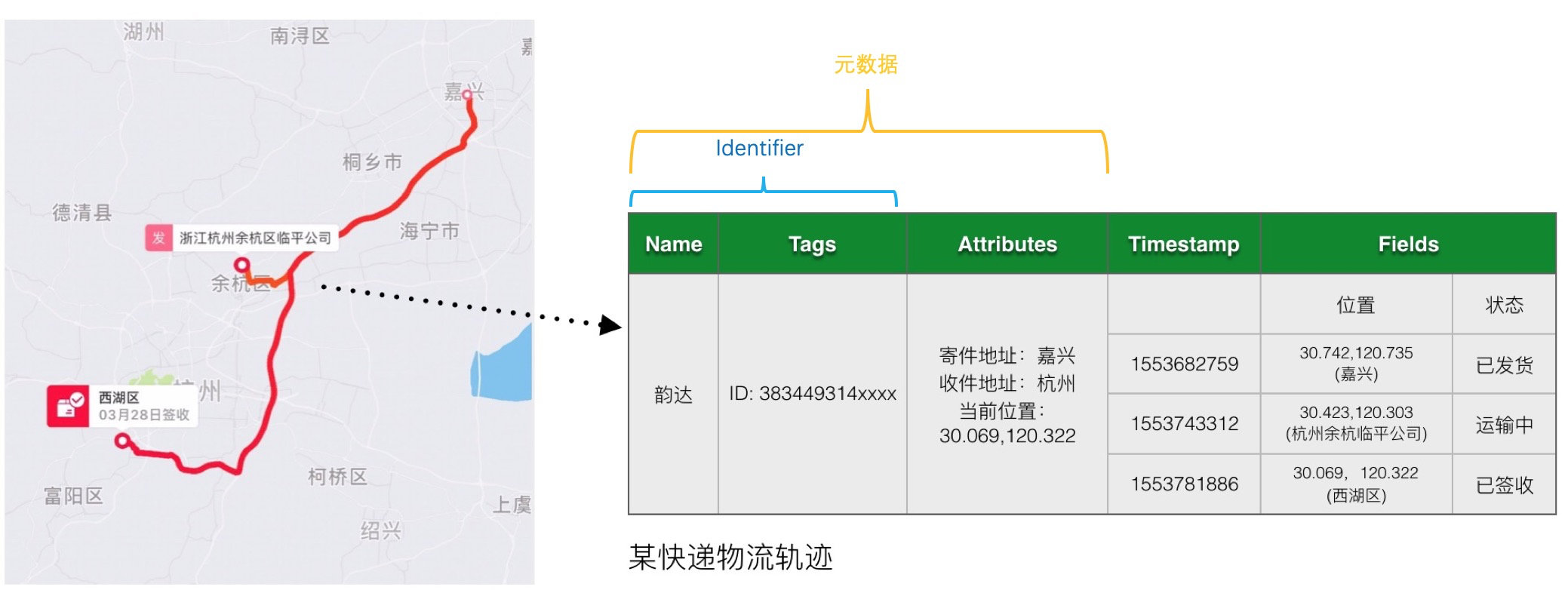
上图是一个快递的物流轨迹数据,记录的是快递在不同时间点的状态变化。该轨迹数据的元数据是快递本身,包含了单号、物流平台、快递当前位置信息以及快递寄件/收件等元信息,其中单号以及物流平台的组合(Identifier)唯一确定这个快递。
数据存储方式分析
- 将物流平台作为Name进行存储,一个快递平台的数据属于同一类数据,对数据检索性能有一定的提升。
- 将快递单号作为Tags存储,唯一确定一个快递。
- 快递的其他元信息存储在Attributes中,避免Tags过长导致的性能问题,同时能够支持这些信息的修改。
- 将快递的当前位置也存在在Attributes中,可以实现根据某个位置检索当前时间附近的快递。
快递的轨迹时序数据(位置/状态)放在Fields中,可以查询某个快递在某个时间范围内的轨迹。
Grid模型
Grid模型(网格模型)是表格存储针对多维网格数据设计的模型。表格存储的Grid模型可以帮助您方便地实现多维网格数据的存储、查询和管理。
背景
什么是多维网格数据
多维网格数据是一种科学大数据,在地球科学领域(气象、海洋、地质、地形等)应用非常广泛,且数据规模也越来越大。多维网格数据一般包含以下五个维度。物理量(或者称为要素,例如温度、湿度、风向、风速等)
- 时间(例如气象中的预报时效,未来3小时、6小时、9小时等)
- 高度
- 经度
- 纬度
多维网格数据的挑战
- 挑战一:数据规模大假设一个三维格点空间包含10个不同高度的平面,每个平面为一个2880 x 570的格点,每个格点保存一个4字节数据,那么这三维的数据量为2880 x 570 x 4 x 10,大约64MB。再加上物理量和时间维度,一个数据集的规模可以在几百MB到几GB的规模,而这样的数据集是每天不断产生,所以总数据量可以到百TB以上规模。
挑战二:查询种类丰富、延迟要求高相关的科学工作者会有快速浏览数据的需求,例如对于气象预报员会快速的浏览各种相关的数据来进行气象预报,于是对这些数据有着在线查询的需求。在对数据进行查询时,因为一个数据集数据较多,一般不会一次全部查出,而是会按照几种不同的方式来查看其中一部分数据,例如:
优势
- 数据存储量无上限,解决了海量格点数据的规模问题。
- 根据多维格点数据的特点,对数据进行了恰当的切分,大大提升了通过各种不同维度条件来查询数据的性能,解决了从海量格点数据进行快速检索的需求。
- 利用了表格存储的多元索引,增加了数据集的元数据管理功能,可以通过多种组合条件筛选数据集,解决了海量格点数据集的管理问题。
元素在Grid模型设计中,一个五维网格数据为一个网格的数据集(GridDataSet)。按照维度顺序,五维分别为: | 维度 | 描述 | | :—- | :—- | | variable | 变量,例如如各种物理量 | | time | 时间维度 | | z | z轴,一般表示空间高度 | | x | x轴,一般表示经度或纬度 | | y | y轴,一般表示经度或纬度 |
一个GridDataSet除了包含五维数据,还包含描述这些数据的元数据,例如各个维度的长度等,此外还包含GridDataSetId以及用户自定义的一些属性。 | 名称 | 说明 | | :—- | :—- | | GridDataSetId | 唯一标记这个GridDataSet的ID。 | | Attributes | 自定义属性信息,例如该数据的产生时间、数据来源、预报类型等等。您可以自定义属性,也可以给某些属性建立索引,建立索引后就可以通过各种组合条件来查询符合条件的数据集。 |
- 数据存储方案表格存储设计了两张表分别存储数据集的meta和data。
- meta表示这个数据集的元数据,例如GridDataSetId、各维度长度、自定义属性等。
- data表示这个数据集里实际的网格数据。data相比meta在数据大小上要大很多。
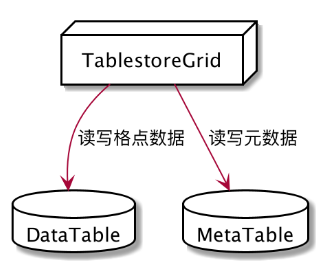
实现
具体参见基于TableStore的海量气象格点数据解决方案。
索引
全局二级索引
全局二级索引采用的仍然是表引擎,给主表建立了全局二级索引后,相当于多了一张索引表。这张索引表相当于给主表提供了另外一种排序的方式,即针对查询条件预先设计了一种数据分布,来加快数据查询的效率。索引的使用方式与主表类似,主要的查询方式仍然是上面讲的主键点查,主键范围查,主键前缀范围查。常见的关系型数据库的二级索引也是类似的原理。
列举一个最简单的例子,比如我们有一张表存储文件的MD5和SHA1值,表结构如下:
| FilePath(主键列) | MD5(属性列) | SHA1(属性列) |
|---|---|---|
| oss://abc/files/1.txt | 0cc175b9c0f1b6a831c399e269772661 | 86f7e437faa5a7fce15d1ddcb9eaeaea377667b8 |
| oss://abc/files/2.txt | 92eb5ffee6ae2fec3ad71c777531578f | e9d71f5ee7c92d6dc9e92ffdad17b8bd49418f98 |
| oss://abc/files/3.txt | 4a8a08f09d37b73795649038408b5f33 | 84a516841ba77a5b4648de2cd0dfcb30ea46dbb4 |
通过这张表,我们可以查询文件对应的MD5和SHA1值,但是通过MD5或SHA1反查文件名却不容易。我们可以给这张表建立两张全局二级索引表,表结构分别为:
索引1:
| MD5(主键列1) | FilePath(主键列2) |
|---|---|
| 0cc175b9c0f1b6a831c399e269772661 | oss://abc/files/1.txt |
| 4a8a08f09d37b73795649038408b5f33 | oss://abc/files/3.txt |
| 92eb5ffee6ae2fec3ad71c777531578f | oss://abc/files/2.txt |
索引2:
| SHA1(主键列1) | FilePath(主键列2) |
|---|---|
| 84a516841ba77a5b4648de2cd0dfcb30ea46dbb4 | oss://abc/files/3.txt |
| 86f7e437faa5a7fce15d1ddcb9eaeaea377667b8 | oss://abc/files/1.txt |
| e9d71f5ee7c92d6dc9e92ffdad17b8bd49418f98 | oss://abc/files/2.txt |
为了确保主键的唯一性,全局二级索引中,会将原主键的主键列也放到主键列中,比如上面的FilePath列。有了上面两张索引表,就可以通过主键前缀范围查的方式里精确定位某个MD5/SHA1对应的文件名了。
多元索引引擎
多元索引引擎相比于表引擎,底层增加了倒排索引,多维空间索引等,支持多条件组合查询、模糊查询、地理空间查询,以及全文索引等,还提供一些统计聚合能力(统计聚合功能待发布)。因为功能较单纯的二级索引更加丰富,而且一个索引就可以满足多种维度的查询,因此命名为多元索引。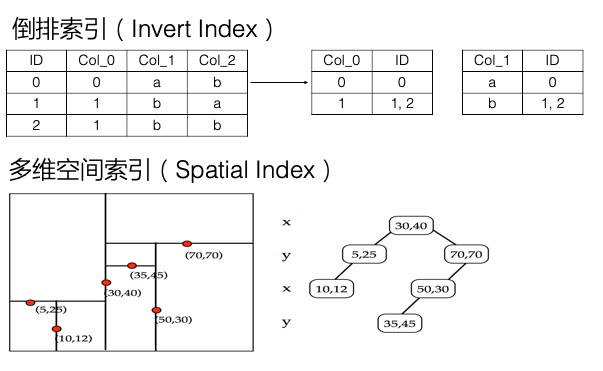
上面在讲解决Filter模式查询慢的问题时,提到倒排索引加快了数据筛选的速度,因为记录了某列的Value到符合条件的行的映射,Value -> List 。实际上,倒排索引这一方式,不仅可以解决单列值的检索问题,也可以解决多条件组合查询的问题。
我们举一个订单场景的例子,比如下表为一个订单记录:
| 订单号 | 订单(md5)(主键) | 消费者编号 | 消费者姓名 | 售货员编号 | 售货员姓名 | 产品编号 | 产品名 | 产品品牌 | 产品类型 | 下单时间 | 支付时间 | 支付状态 | 产品单价 | 数量 | 总价钱 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| o0000000000 | c49f5fd5aba33159accae0d3ecd749a7 | c0019 | 消陈九 | s0020 | 售楚十 | p0003004 | vivo x21 | vivo | 手机 | 2018-07-17 21:00:00 | 否 | 2498.99 | 2 | 4997.98 |
上面一共16个字段,我们希望按照任意多个字段组合查询,比如查询某一售货员、某一产品类型、单价在xx元之上的所有记录。可以想到,这样的排列组合会有非常多种,因此我们不太可能预先将任何一种查询条件的数据放到一起,来加快查询的效率,这需要建立很多的全局二级索引。而如果采用Filter模型,又很可能需要扫描全表,效率不高。折中的方式是,可以先对某个字段建立二级索引,缩小数据范围,再对其中数据进行Filter。那么有没有更好的方式呢?
多元索引可以很好的解决这一问题,而且只需要建立一个多元索引,将所有可能查询的列加入到这个多元索引中即可,加入的顺序也没有要求。多元索引中的每一列默认都会建立倒排,倒排就记录了Value到List的映射。针对多列的多个条件,在每列的倒排表中找到对应的List,这个称为一个倒排链,而筛选符合多个条件的数据即为计算多个倒排链的交并集,这里底层有着大量的优化,可以高效的实现这一操作。因此多元索引在处理多条件组合查询方面效率很高。
此外,多元索引还支持全文索引、模糊查询、地理空间查询等,以地理空间查询为例,多元索引通过底层的BKD-Tree结构,支持高效的查询一个地理多边形内的点,也支持按照地理位置排序、聚合统计等。
索引选择
不是一定需要索引
- 如果基于主键和主键范围查询的功能已经可以满足业务需求,那么不需要建立索引。
- 如果对某个范围内进行筛选,范围内数据量不大或者查询频率不高,可以使用Filter,不需要建立索引。
如果是某种复杂查询,执行频率较低,对延迟不敏感,可以考虑通过DLA(数据湖分析)服务访问Tablestore,使用SQL进行查询。
全局二级索引还是多元索引
一个全局二级索引是一个索引表,类似于主表,其提供了另一种数据分布方式,或者认为是另一种主键排序方式。一个索引对应一种查询条件,预先将符合查询条件的数据排列在一起,查询效率很高。索引表可支撑的数据规模与主表相同,另一方面,全局二级索引的主键设计也同样需要考虑散列问题。
一个多元索引是一系列数据结构的组合,其中的每一列都支持建立倒排索引等结构,查询时可以按照其中任意一列进行排序。一个多元索引可以支持多种查询条件,不需要对不同查询条件建立多个多元索引。相比全局二级索引,也支持多条件组合查询、模糊查询、全文索引、地理位置查询等。多元索引本质上是通过各种数据结构加快了数据的筛选过程,功能非常丰富,但在数据按照某种固定顺序读取这种场景上,效率不如全局二级索引。多元索引的查询效率与倒排链长度等因素相关,即查询性能与整个表的全量数据规模有关,在数据规模达到百亿行以上时,建议使用RoutingKey对数据进行分片,查询时也通过指定RoutingKey查询来减少查询涉及到的数据量。简而言之,查询灵活度和数据规模不可兼得。
常见组合方案
丰富的查询功能当然是业务都希望具备的,但是在数据规模很大的情况下,灵活的查询意味着成本。比如万亿行数据的规模,对于表引擎来说,因为水平扩展能力很强,成本也很低,问题不大,但是建立多元索引,费用就会非常高昂。全局二级索引成本较低,但是只适合固定维度的查询。
常见的超大规模数据,都带有一些时间属性,比如大量设备产生的数据(监控数据),或者人产生的数据(消息、行为数据等),这类数据非常适合采用Tablestore存储。对这类数据建立索引,会有一些组合方案:对元数据表建立多元索引,全量数据表不建立索引或采用全局二级索引。
- 元数据表可以是产生数据的主体表,比如设备信息表,用户信息表等。在时序模型中,产生数据的主体也可以认为是一个时间线,这条线会不断的产生新的点。
- Tablestore的时序数据模型(Timestream)采用的也是类似的方式,对时序数据中的时间线建立一张表,专门用来记录时间线的元数据,每个时间线一行。时间线表建立多元索引,用来做时间线检索,而全量数据则不建立索引。在检索到时间线后,对某个时间线下的数据进行范围扫描,来读取这个时间线的数据。
- 热数据建立多元索引,老数据不建立索引或者采用全局二级索引:
- 很多情况下仅需要对非常热的数据进行多种维度查询,对冷数据采取固定维度查询即可。因此冷热分离可以给业务提供更高的性价比。
- 目前多元索引还不支持TTL(后续会支持),需要业务层区分热数据和冷数据。

若有收获,就点个赞吧
0 人点赞
