给出2个文件,能口喷一段代码完成模块打包和执行的核心逻辑 模块加载器的实现(与闭包有什么关系,如何实现找文件的 动态加载的,如何避免多次加载,如何缓存的) 描述异步模块加载实现原理,amd/cmd中的实现方案,webpack中的实现方案
- 67. requireJS 的核心原理是什么?(如何动态加载的?如何避免多次加载的?如何 缓存的?)
- AMD加载器分析与实现
- webpack打包原理 ? 看完这篇你就懂了 !
- 68. JS 模块加载器的轮子怎么造,也就是如何实现一个模块加载器?
打包不过是,从入口文件开始,将所有模块及依赖的模块输出到包文件中,并且可以在浏览器中运行。
那么它就分为四步:
- 获取入口文件内容,及其所有依赖
- 依次获取所有的依赖模块内容,及其依赖的依赖,…,获取整个依赖图
- 将依赖图包装进一个能够在所有浏览器运行的立即执行函数
- 输出到./dist/bundle.js
模块规范:
- AMD(Asynchronous Module Definition异步模块定义):被定义为用于浏览器中模块的异步模型,RequireJS 是 AMD 最受欢迎的实现;
- CMD(Common Module Definition通用模块定义):它本质上一段 JavaScript 代码,放置在库的顶部,可让任何加载程序、任何环境加载它们;
- ES2015(ES6):定义了异步导入和导出模块的语义,会编译成
require/exports来执行的,这也是我们现今最常用的模块定义;
模块化**与捆绑是打包器需要实现的两个最主要功能:**
模块化:html载入多个js文件,需要注意引用的顺序不然会报错。所以,我们需要将每个依赖项模块化,让打包器帮助我们管理这些依赖项,让每个依赖项能够在正确的时间、正确的地点被正确的引用。
捆绑:多个文件合并成一个文件,http请求一次即可
minipack
BUILD YOUR OWN WEBPACK by Ronen Amiel
下面提出问题:如果我要实现这样的模块打包器,面临的问题及解决的思路
1、从哪里入手分析依赖 => 多入口麻烦,单入口开始 依次构造出依赖图
2、当分析到这个文件需要某个依赖之后,怎么记录及怎么深入
==》 图的遍历算法,当读到这个文件有依赖另一个文件时,
深度优先
3、怎么保证代码不重复加载的,被需要的模块即使被引用了多次,最后打包的时候也只打包了一次
==》 去重,用hash key
4、怎么控制加载顺序的? 依赖顺序是a->b ->c, 可以让c先加载然后b然后a,如果是html写js文件的思路可能是
但是在一个bundlejs文件里,是怎么决定的 c载入完全后 a载入的呢
5、分包等控制
1、依赖关系图的结构设计
一个模块的信息,需要下面四个东西:
- 文件名字和文件标识
- 在文件系统中文件的位置
- 文件中的代码
- 该文件需要哪些依赖
问题:
1、怎么解析app.js文件里的require(‘./utils/request.js’)的相对路径找到 ‘user/yxy/src/utils/request.js’的?
2、不同的组件引用同一个文件,写法区别require(‘./utils/index’); require(‘../utils/index’) 怎么定位到是一个文件的 key 不一样
即业务代码你写的时候可以直接在某文件里写相对路径引入隔壁的文件 比如require(‘./utils’), 但是站在整个模块打包系统的角度,当模块解析器执行到require(‘./utils’)这一行时,打包器是怎么知道./utils文件在哪里的?
3、文件里的代码 和 抛出的代码的存放
文件里引用代码资源的:先引用,然后执行(相当于把源代码拿进来)
文件里直接的代码:直接运行
文件里抛出的代码:调用权交给别人
下面引入模块图的概念
如上app.js所示,每个模块会有单独的id标记,每当解析到一个module时就给这个module一个id,id=>sourcecode
比如同样引用一个printf模块,引用时各自使用的相对路径,那么最简单的解决办法就是重复引多次即使指向的是一个文件(因为key不一样)
app.js写的是 import print from ‘./utils/printf.js’;
utils/requet.js里写的是 import print from ‘./printf.js’;
每当模块加载器读到当前文件时,根据from指定的路径,就去把那个文件的源代码拿进来,modules里存放
问题:(我是杠精)如果在app.js 隔壁有个printjs,解析module1的时候隔壁也有个printjs但是他们是不一样的printf,不过引用时的key一样,会影响吗?
==> 不会,因为modules map是 每个模块自有一个的。而modules模块图才是全局的,依靠id维护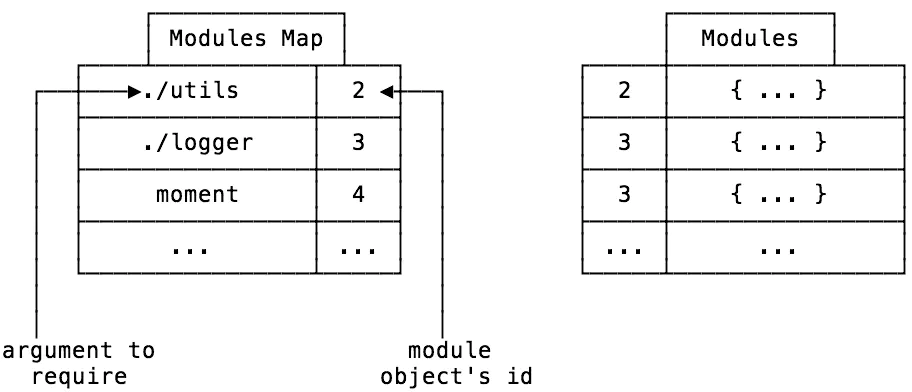
3、遍历graph构建出bundle
小总结:
拿到了graph依赖图之后,生成bundle的过程:
1、确定bundle的代码结构
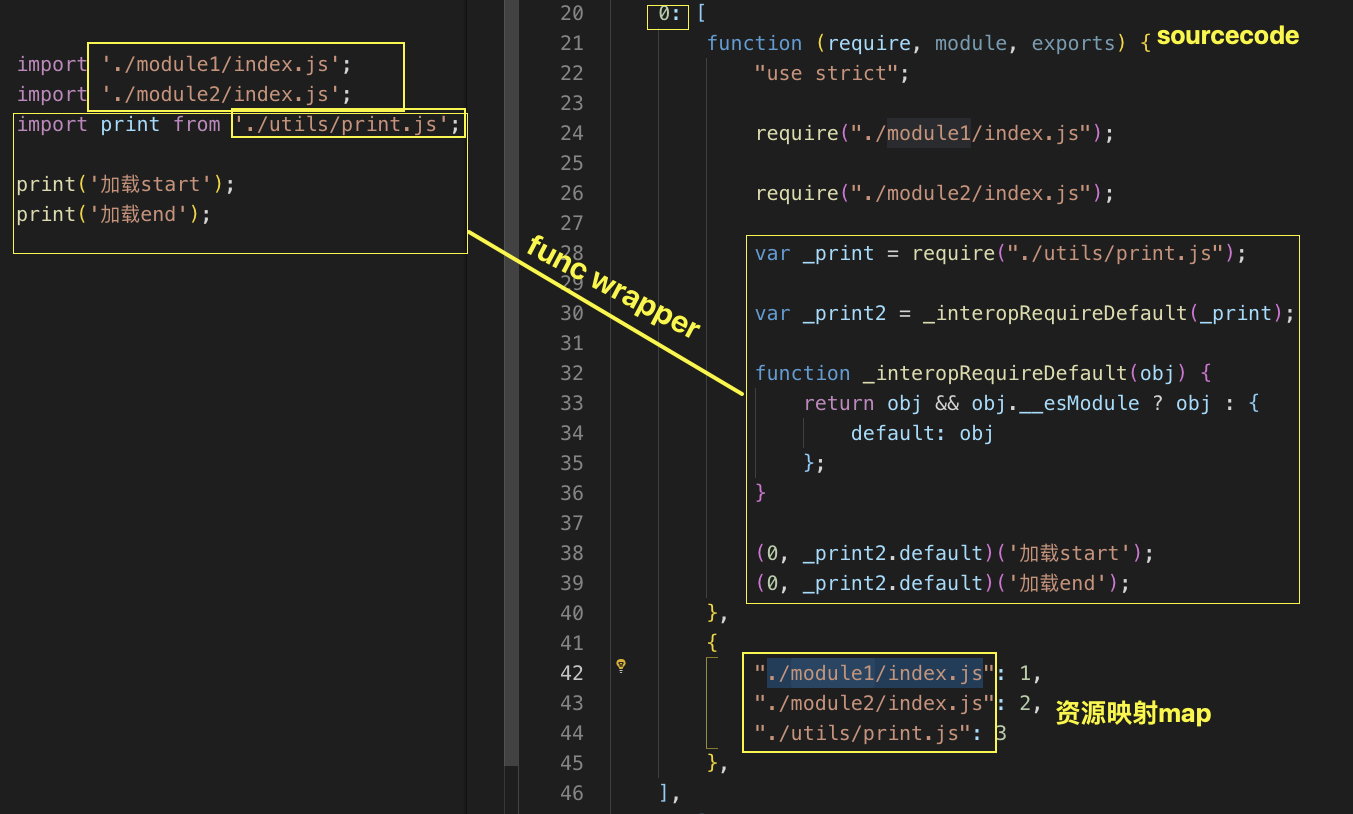
const modulemap = {0: [func, dependencies],// entry 文件1: [func, dependencies],2: [func, dependencies],}(function(modules){function require(id) {const [fn, mapping] = modules[id]; # 拿到id对应的源代码和就近维护的本地依赖图const localRequire = name => require(mapping[name]);# 包装后的require函数fn(localRequire, module, module.exports); # 执行id对应的源代码}require(0) // 从entry开始 不断递归执行})(modulemap)
2、具体的设计:
const modulemap = {0: [function (require, module, exports) {// require, module, exports 采用commonjs规范// require是框架里的全局调用者 注入到当前业务代码的一个调用能力// 使用者可以 require('./utils/print.js') 就能拿到在全局备份的那个代码},{// 就近维护的 本地 => 全国的 映射"./module1/index.js": 1,"./module2/index.js": 2,"./utils/print.js": 3}]}# modulemap如何构造生成的?let modules = '';graph.forEach(mod => {modules += `${mod.id}: [function (require, module, exports) { ${mod.code} },${JSON.stringify(mod.mapping)},],`;});
这里的require和modulemap的配合设计十分巧妙:
1、从require函数角度
一个资源调用者:
输入当前执行的模块所在的全局唯一标识id,拿着依赖关系图根据id找到id所在模块信息(源代码及依赖); 包装了一个localRequire函数 给业务者使用: localRequire: path => require(mapping[path]) 使得业务方可以传入 相对路径的模块,就能找到全局对应的那个模块;赋予了本地以全局的能力 (闭包 与 装束的 强大之处)
2、从整个系统角度
(相对路径就能找到资源的解决)
1、每发现依赖一个模块,就用id标记这个模块,记录备份源代码到全局的map里 (id自增记录模块
(从入口entry不断深入每个依赖)
entry的id为0,require(id);
每个模块自维护 dependies,这样就能 在每个文件以相对路径 引入模块,但是相对路径 找 文件时仍能准确定位到文件;
3、开放api层面
业务方:不想管那么多,只想就近取源码,import relativepath;
框架方:好,满足!
维护一个大map,管理全局的所有文件,relativepath你就地维护一个map,从当地到全国的映relativepath:id
然后解决下残余问题:
- 1、graph的由来,如何搜集到这些信息的,graph的结构设计
2、commonjs的 module, exports 这两个变量,
import {name} from ‘./utils’ 怎么按需拿到指定的export的?==>babel转译
const module = {exports: {}};fn(localRequire, module, module.exports);# 这样设计的有意义 吗
2、graph的构建
graph的设计,每个模块包含的信息:
- 文件标识id
- 在文件系统中文件的位置filename //当前文件的名字,用于和dependencies的relativepath构建生成为唯一路径
- 文件中的代码code
- 该文件需要哪些依赖dependencies
解析出这些信息不难,大致就是引用读取文件后生成ast,从ast里读取到需要的信息;
而mapping的构建 是 根据文件信息解析完善后,生成mapping,同时dfs
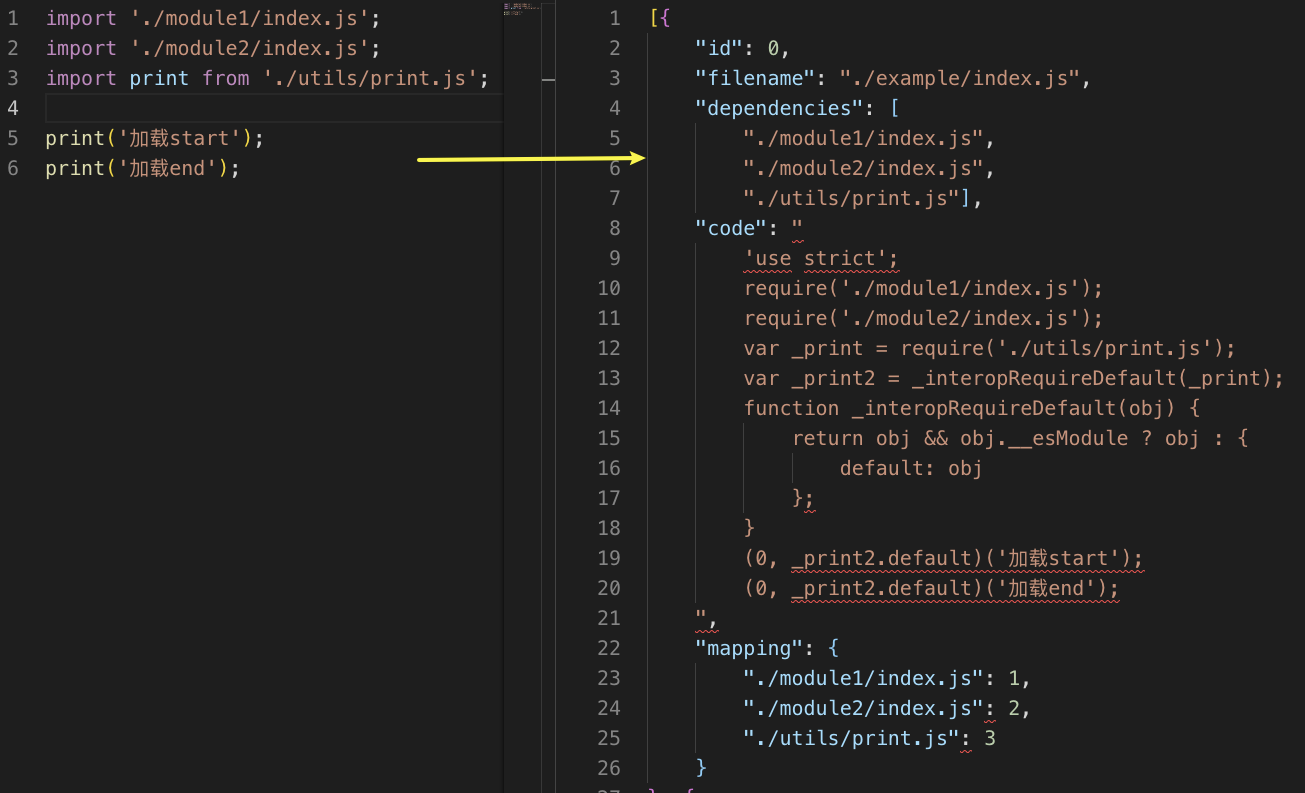
[{"id": 0,"filename": "./example/index.js","dependencies": ["./module1/index.js","./module2/index.js","./utils/print.js"],"code": "'use strict';require('./module1/index.js');require('./module2/index.js');var _print = require('./utils/print.js');var _print2 = _interopRequireDefault(_print);function _interopRequireDefault(obj) {return obj && obj.__esModule ? obj : {default: obj};}(0, _print2.default)('加载start');(0, _print2.default)('加载end');",# mapping是拿到单个文件信息后 解析dependencies得到的mapping"mapping": {"./module1/index.js": 1,"./module2/index.js": 2,"./utils/print.js": 3}}]
构建出这样的图之后,我们只会取code、mapping字段,生成最终的modulesmap
modules += `${mod.id}: [function (require, module, exports) { ${mod.code} },${JSON.stringify(mod.mapping)},],`;
疑问:modules的注入
commonjs的 module, exports 这两个变量,import {name} from ‘./utils’ 怎么按需拿到指定的export的?
===> 好像没用 具体的抛出抛入的变量得到 是babel转译的功效
const module = {exports: {}};fn(localRequire, module, module.exports);# 这样设计的有意义 吗(function(modules){function require(id) {const [fn, mapping] = modules[id];const localRequire = name => require(mapping[name]);const module = { exports : {} };# 每个文件定义一个module,传入fn给业务使用fn(localRequire, module, module.exports);return module.exports;# 业务使用后返回module变量 将局部变量挂载在module上}require(0) // 从entry开始 不断递归执行})(modulemap)
类似于
var module = {exports: {}};(function(module, exports) {exports.multiply = function (n) { return n * 1000 };}(module, module.exports))var f = module.exports.multiply;f(5) // 5000
第一版的完整代码
const fs = require('fs');const path = require('path');const babylon = require('babylon');const traverse = require('babel-traverse').default;const {transformFromAst} = require('babel-core');let ID = 0;// 我们首先创建一个函数,该函数将接受 文件路径 ,读取内容并提取它的依赖关系.// createAsset('./example/index.js');// 传入文件路径,读取文件源码,解析import关键字// babylon解析源码生成ast,从而得到关键信息 https://astexplorer.net/**** @param {*} filename 文件路径* @returns 文件的信息 obj* 包含:* id: 当前文件对应的全局标识id(每读一个文件 全局ID自增维护* filename:文件路径(从当前文件目录出发的路径)* dependencies:文件依赖的模块集合* code:源代码*/function createAsset(filename) {// 以字符串形式读取文件的内容.const content = fs.readFileSync(filename, 'utf-8');const ast = babylon.parse(content, {sourceType: 'module',});// 保存模块依赖的模块相对路径.const dependencies = [];// 我们遍历`ast`来试着理解这个模块依赖哪些模块.// 要做到这一点,我们检查`ast`中的每个 `import` 声明. ❤️traverse(ast, {// `Ecmascript`模块相当简单,因为它们是静态的. 这意味着你不能`import`一个变量,// 或者有条件地`import`另一个模块.// 每次我们看到`import`声明时,我们都可以将其数值视为`依赖性`.ImportDeclaration: ({node}) => {// import key from value; 拿到当前文件依赖的另一个文件路径dependencies.push(node.source.value);},});// 每读取到一个文件,就自增id维护const id = ID++;// `babel-preset-env``将代码转换为浏览器可以运行的东西.const {code} = transformFromAst(ast, null, {presets: ['env'],});// 返回有关此模块的所有信息.return {id,filename,dependencies,code,};}/********* 1、传入entry文件 得到文件信息,根据entry的依赖dfs遍历得到graph* 单独文件的信息:* {id,filename,dependencies,code}* 构建过程中,不断维护 mapping字段*/function createGraph(entry) {const mainAsset = createAsset(entry);const queue = [mainAsset];for (const asset of queue) {// 我们的每一个 资产 都有它所依赖模块的相对路径列表.// 我们将重复它们,用我们的`createAsset() `函数解析它们,并跟踪此模块在此对象中的依赖关系.asset.mapping = {};// 记录filename的作用:和dependencies里的相对路径 拼凑成绝对路径const dirname = path.dirname(asset.filename);// 我们遍历其相关路径的列表asset.dependencies.forEach(relativePath => {const absolutePath = path.join(dirname, relativePath);// 每次解析dependencies读取一个文件 就产生一个模块备份// 同时维护relativePath对应的全局idconst child = createAsset(absolutePath);asset.mapping[relativePath] = child.id;// 典型的DFSqueue.push(child);});}return queue;}function bundle(graph) {let modules = '';graph.forEach(mod => {modules += `${mod.id}: [function (require, module, exports) { ${mod.code} },${JSON.stringify(mod.mapping)},],`;});const result = `(function(modules) {function require(id) { //🌟const [fn, mapping] = modules[id];function localRequire(name) { //⏰return require(mapping[name]); //🌟}const module = { exports : {} };fn(localRequire, module, module.exports);return module.exports;}require(0);})({${modules}})`;return result;// 返回字符串 写入bundlejs文件}const graph = createGraph('./example/index.js');const result = bundle(graph);function getFilePath(filename) {const processDir = process.cwd(); // 当前进程执行目录const createDir = path.resolve(processDir); // path 从右到左依次处理,直到构造出绝对路径。const filePath = path.join(createDir, filename);return filePath;}// fs.writeFileSync(getFilePath('dist/graph.json'), JSON.stringify(graph));// fs.writeFileSync(getFilePath('dist/bundle.js'), result);
优化:不重复打包
引申:ES6模块机制
优化:异步加载的支持
Amd实现原理
requiejs 异步加载(如何动态加载的?如何避免多次加载的?如何 缓存的?)
define(["./a", "./b"], function(a, b) {// 依赖必须一开始就写好a.doSomething();// 此处略去 100 行b.doSomething();// ...});
require.js 的核心原理是通过动态创建 script 脚本来异步引入模块,然后对每个脚本的 load 事件进行监听,如果每个脚本都加载完成了,再调用回调函数。

若有收获,就点个赞吧
0 人点赞
