by joining two copies of the stops table we can refer to stops by name rather than by number
sql通配符
在搜索数据库中的数据时,SQL 通配符可以替代一个或多个字符。
SQL 通配符必须与 LIKE 运算符一起使用。
在 SQL 中,可使用以下通配符:
| 通配符 | 描述 |
|---|---|
| % | 替代一个或多个字符 |
| _ | 仅替代一个字符 |
| [charlist] | 字符列中的任何单一字符 |
| [^charlist]或者[!charlist] | 不在字符列中的任何单一字符 |
concat函数 ,连接多个字符串,好处在于 concat里面的数是变量,变量可以是select 的字段 也可以是 通配符

select name from worldwhere name like "C%ia"

 注意city前面的空格
注意city前面的空格

ROUND: ROUND(column_name,要保留的位数)
round 为负数达到四舍五入的效果:
round(num,0)=>整数
round(num,-1)=> 153.4=>150 (看个位数3进行四舍五入
round(num,-2)=> 153.4=>200 (看十位数5进行四舍五入
子查询与分组
子查询
https://sqlzoo.net/wiki/SELECT_within_SELECT_Tutorial
有些國家的人口是同洲份的所有其他國的3倍或以上。列出 國家名字name 和 洲份 continent。
SELECT name, continent FROM world xWHERE population >= ALL(SELECT population*3FROM world yWHERE x.continent = y.continentand y.name != x.name)
對於每一個洲份,顯示洲份和國家的數量。
SELECT continent, COUNT(name) FROM worldGROUP BY continent
join
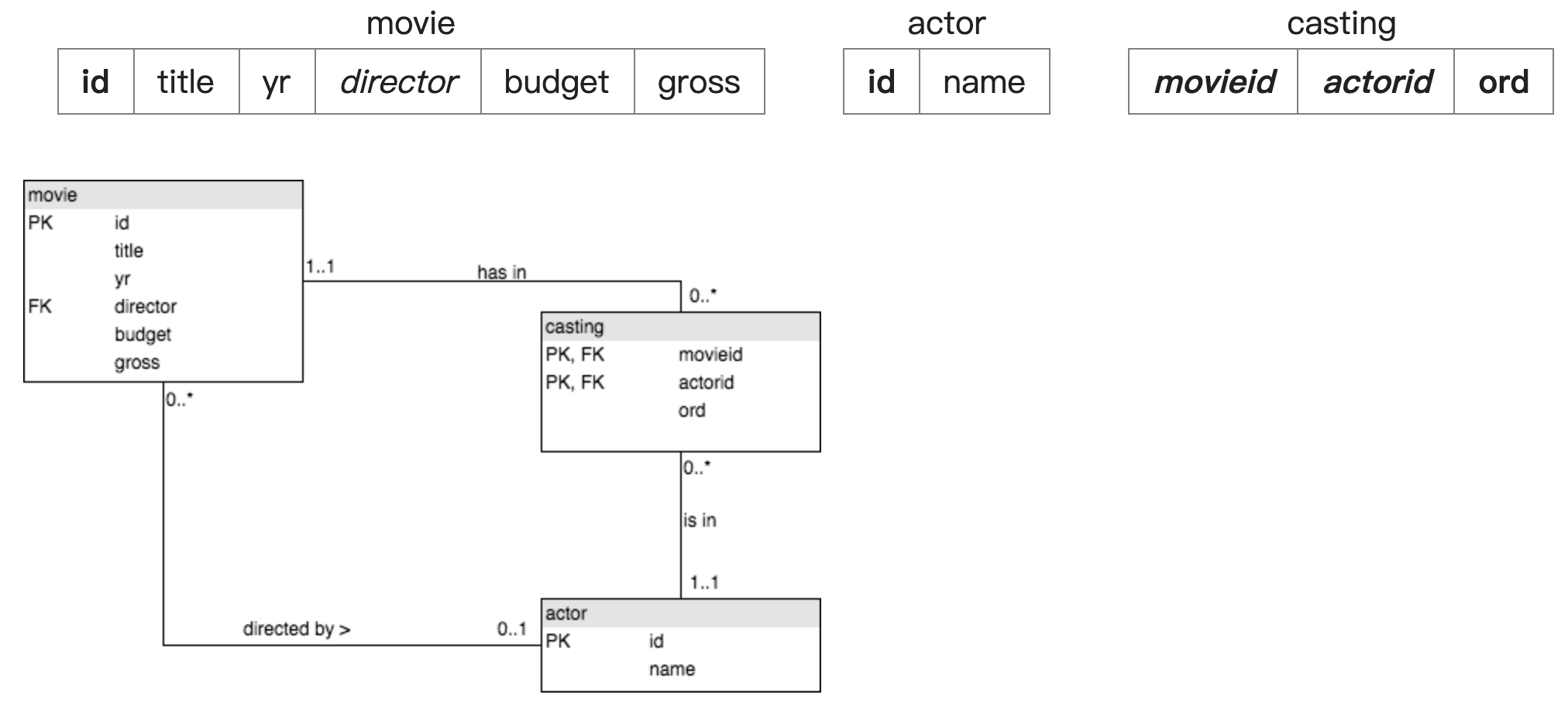

SELECT name FROM casting (居然是casting 从连接表开始查询
JOIN actor ON (actor.id=actorid)
JOIN movie ON (movie.id=movieid) WHERE title = ‘Alien’
—- 思考:1、在movie里找到最具象的 然后不必纠结选哪个列属性 ,一般这种都是由内向外;
2、然后向外搜索其他的表,看能根据====哪个的‘’、=
列出電影北非諜影 ‘Casablanca’的演員名單(即是電影中各演員的真實姓名清單)使用 movieid=11768
select name from actorwhere id in(select actorid from casting where movieid= 11768)
显示 演员x 演的电影
SELECT name FROM castingJOIN actor ON (actor.id=actorid)JOIN movie ON (movie.id=movieid)WHERE title = 'Alien'
--Which were the busiest years for 'Rock Hudson',--show the year and the number of movies he made each year for any year--in which he made more than 2 movies.找到演员Rock Hudson忙碌的年 ,(以年为小组划分 ,忙碌的定义:那一年他至少拍了2部电影show year and 电影数量关键技术点:在全部拍的电影里过滤为 该演员拍的 (连接两个表)以年yr为小组划分 having count(movie)>2===》 join 之后会得到 yr、count写的顺序:1、因为要找到某个演员演的所有电影,所以三个表都需要连接起来再加点筛选条件 WHERE name = 'Rock Hudson'2、现在我们知道了该演员的所有电影,一个二维数组然后要统计出忙碌年份group by yr having count(title)>23、精简列属性select yr,count(title) from castingJOIN actor ON (actor.id=actorid)JOIN movie ON (movie.id=movieid)WHERE name = 'Rock Hudson'group by yr having count(title)>2
找出演员xxx最忙碌的一年,显示年份和拍的电影数
-- 演员xx拍的电影-- group by yr-- 找出最多的那一年 ===> 这个怎么排select yr, count(*) from castingjoin actor on (actor.id = actorid)join movie on (movie.id = movieid)where name='John Travolta'group by yr order by count(*) desc
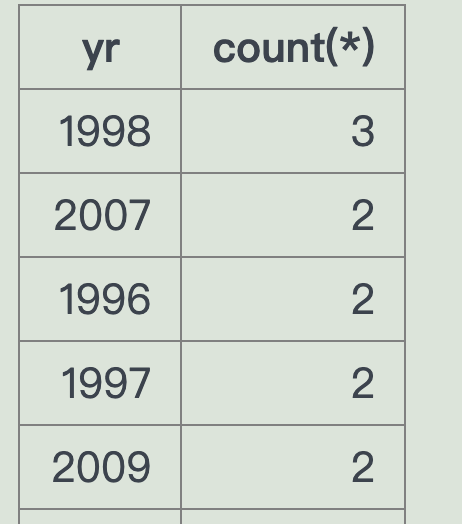
怎么求最大?
-- 演员xx拍的电影-- group by yr-- 找出最多的那一年 ===> 这个怎么排select yr, count(*) from castingjoin actor on (actor.id = actorid)join movie on (movie.id = movieid)where name='John Travolta'group by yr having count(*) =(select max(c) from(select yr, count(title) c from castingjoin actor on (actor.id = actorid)join movie on (movie.id = movieid)where name='John Travolta'group by yr) as t -- 必须别名一下)
-- List the film title and the leading actor-- for all of the films 'Julie Andrews' played in.列出演员xx参演的电影及电影的第一主角注意电影的title并不是唯一标示应该以movieid区分,建议create a table of IDs in your subquery关键点:1、找到演员演的电影=>id2、在电影里过滤 她是主演3、精简列属性select name,title from castingjoin actor on (actior.id = actorid)join movie on (movie.id = movieid)WHERE ord = 1 and movieid in (===> 因为要在movie里找name、title等(SELECT movie.id FROM movieJOIN casting ON movie.id = movieidJOIN actor ON actor.id = actoridWHERE actor.name = 'Julie Andrews')为什么这样不对?SELECT title, name,ord FROM castingjoin actor on (actior.id = actorid)join movie on (movie.id = movieid)WHERE actor.name = 'Julie Andrews' and ord=1她於1980再參與此電影Little Miss Marker. 原作於1934年,她也有參與
列出按字母順序,列出哪一演員曾作30次第1主角。关键点:1、做30次第1主角SELECT actorid FROM castingWHERE ord = 1GROUP BY actoridHAVING COUNT(actorid) >= 30然后再在演员表里查演员的nameselect name from actorwhere id in(SELECT actorid FROM castingWHERE ord = 1GROUP BY actoridHAVING COUNT(actorid) >= 30)order by name
way2
select name from(select actorid from castingwhere ord= 1group by actorid having count(*)>=30) as ajoin actor b on (a.actorid = b.id)
====> 由此可以总结出两种思路
1、使用查询得到的半结果为临时表 join 额外表得到信息;
2、将查询得到的半结果的关键信息提出,然后select xx where xx in (半结果)
$列出1978年首影的電影名稱及角色數目,按此數目由多至少排列。
select title,count(actorid) from castingjoin movie on (movie.id = movieid)where yr = 1978group by movieid ,titleorder by count(actorid) desc
为啥不对呢
===》 可能是因为 groupbytitle压缩了一些数据?实际上有id不同 title相同的数据?
因为需要 title所以我把title放入了group by里
select title,count(*) from movie ===> 报错where movie.id in( select movieid from castingjoin movie on (movie.id = movieid)where yr = 1978group by movieidorder by count(actorid) desc)
Mixing of GROUP columns (MIN(),MAX(),COUNT(),…) with no GROUP columns is illegal if there is no GROUP BY clause
===> 如果需要count计算就必须group by;所以这里不适合select in 的方式 还是join比较适合
select title,count from(select movieid,count(*) count from castingjoin movie on (movie.id = movieid)where yr = 1978group by movieid) t join movie on(movie.id = t.movieid)order by count desc
结果还是错的 我哭了
我不管 答案也是给的这个。我不改了口亨
-- 列出曾與演員亞特·葛芬柯'Art Garfunkel'合作過的演員姓名。找到演员xx演出的所有电影==>movieid在movieid里 演职表里找到actorid(distinc一下actorid=>idselect distinct name from castingjoin actor on (actorid = actor.id)where movieid in (-- 找到拍过的所有movie,根据movieid在casting里找 找到的演员可能还是重复的(1、distinc、2、怎么排除演员本身的重复?(不知道演员id啊select movieid from actorjoin casting on (actorid = actor.id)join movie on (movie.id = movieid)where actor.name = 'Art Garfunkel')==>select distinct name from castingjoin actor on (actorid = actor.id)wherename != 'Art Garfunkel' -- 排除和自己一样的and movieid in (-- 找到拍过的所有movie,根据movieid在casting里找 找到的演员可能还是重复的select movieid from actorjoin casting on (actorid = actor.id)join movie on (movie.id = movieid)where actor.name = 'Art Garfunkel')
using null
COALESCE can be useful when you want to replace a NULL value with some other value
COALESCE(party,’None’) AS aff // party这个字段的娄底方案 如果这个字段的数值为空那么 aff
inner join
内连接:
内连接就是关联的两张或多张表中,根据关联条件,显示所有匹配的记录,匹配不上的,不显示
内连接是将 只连接双方都存在的情况
排除了没有部门的老师和没有老师的部门
SELECT name, CASE WHEN dept IN (1,2) THEN 'Sci'WHEN dept = 3 THEN 'Art'ELSE 'None'ENDFROM teacher===>这个栗子就是对表格数据的列渲染的筛选 (突然一个脑洞,excel数据也应该开一个这样的接口(像vue的template那样)
left join
外连接,分为:
LEFT OUTER JOIN/LEFT JOIN:显示左表的所有项,右表没有匹配的项,则以null显示。
2) RIGHT OUTER JOIN/RIGHT JOIN:显示右表的所有项,左表没有匹配的项,则以null显示。
3) FULL OUTER JOIN/FULL JOIN:显示所有匹配和不匹配的项,左右两张表没有匹配的,都以null显示。
left join / right join / inner join /
left outer join /
之间的差别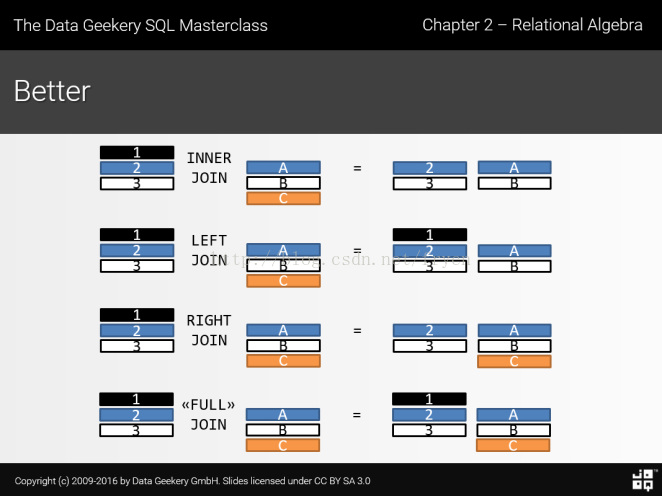
self join
我们只有一张表。你也许说我们现在在建一张表,把同样的数据拷贝过去不就可以了吗?是的,这样可以,但我们不会采用,因为这样就会很麻烦,而且数据严重冗余等等很多弊端。
这里有更好的方法,那就是自连接。
自连接,就是把一张表取两个别名,当做两张表来使用,自己和自己关联。
自己连接自己
什么情况下会用自己连接自己呢~
栗子:
表:
stops(id, name) name:车站名,一个片区的站台至少会有一辆bus经过
This is a list of areas served by buses —
id:数据库id
name:站台名
route(num, company, pos, stop)
num:车牌号
company:这个路线的负责公司
stop:该条路线的某个站台 通过route.stop = stops.id 连接两个表
This references the stops table
pos:该站台是这个路线上的第几个,次序
This indicates the order of the stop within the route. Some routes may revisit a stop. Most buses go in both directions.
select * from stops join route on (stops.id = route.stop)
| id | name | num | company | pos | stop |
|---|---|---|---|---|---|
| 6 | ASDA | 142 | SMJ | 1 | 6 |
| 6 | ASDA | 63 | LRT | 1 | 6 |
表明。一个站台可能对应两个公交车,而且他们的路线是一样的,在路线上的次序也是一样的;
栗1:单表-同时经过某两站的车辆
栗1:我们想要找到同时经过了某站到某站的车牌号(这里某站与某站之间是在一个路线上的,不需要经过换乘)
答案如下试试读的懂么~(提示:这里利用了单表查询 简化了多表联查
SELECT company, num, COUNT(*)FROM route WHERE stop=149 OR stop=53GROUP BY company, num having count(*)=2
解析:
1、
SELECT * FROM route WHERE stop=149 OR stop=53
经过了149或者 53站台的所有车辆信息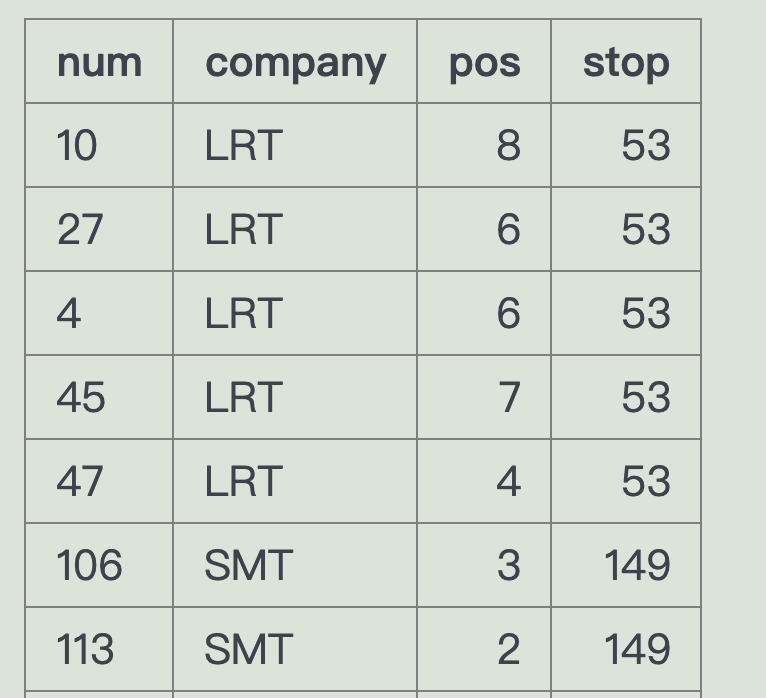
2、以公司为分组,公司旗下有几个车辆经过了该两站点
SELECT company ,count(*)FROM route WHERE stop=149 OR stop=53group by company
 以group为分组,就只能筛选出 group列 和以基于分组的聚合函数 比如count
以group为分组,就只能筛选出 group列 和以基于分组的聚合函数 比如count
3、以车牌为分组,得到同时经过了两个站点的车
SELECT num ,count(*)FROM route WHERE stop=149 OR stop=53group by num having count(*) =2
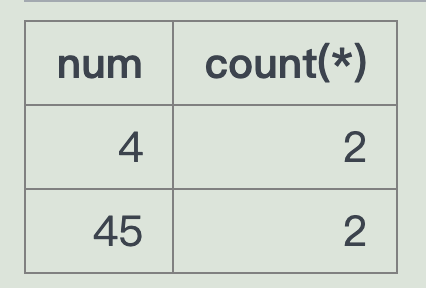
所以按理论上来说,按照车牌号统计就能得到既能车经过149和经过53并存的车站;
(好聪明 使用 stop or连接然后根据分组判断count 来得到一个车经过了两个车站。。。
因为不能单表查询里使用 stop = 149 and stop = 53来得到同时经过两个车站的车;
4、结合company得到该车辆的公司信息
然后,在此基础上我们还想知道 这个车的公司是啥。
所以gourp的时候使用多个值
总结:这种方法省空间(数据表空间)因为是单表查询
但是,信息有限,因为并不包含车的name等等
如果要包含name 那么需要join stops表
===》但是并不行啊。因为stops作为了筛选条件,肯定不能group;
然后,stop又是表之间连接的桥梁是必须字段、
那么肿么办呢?
栗2:self join-从某站到某站
我们试试自表连接~
找到经过53站到”London Road“站的车
select a.company, a.num, a.stop, b.stop-- join on的条件相当于 是约束了同一辆车 而且还会显示公司from route a join route b on (a.company=b.company and a.num=b.num)where a.stop = 53 and b.stop =(select id from stops where name = 'London Road')
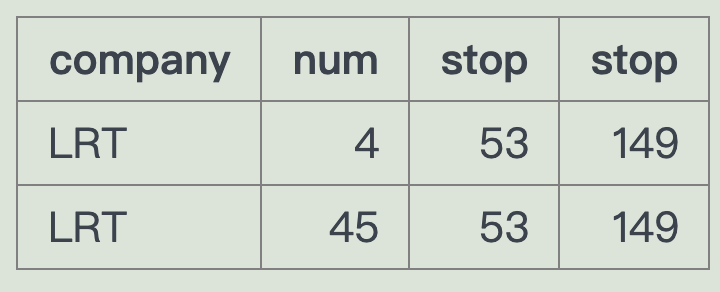
进阶:如果是两个都是name匹配呢~
-- 上个栗子我们知道了通过d找两个站点之间的路线,下面我们尝试通过name来查找;-- (提示:通过拷贝两个一样的表 来实现name的转换-- Craiglockhart London Roadselect a.company, a.num, a.stop, b.stopfrom route a join route b on (a.company = b.company and a.num = b.num)where a.stop = (select id from stops where name = 'Craiglockhart')and b.stop = (select id from stops where name = 'London Road')
现在需要显示 name。而不是简单的在内查询里使用下name那么怎么弄呢
即怎么把这个变为这个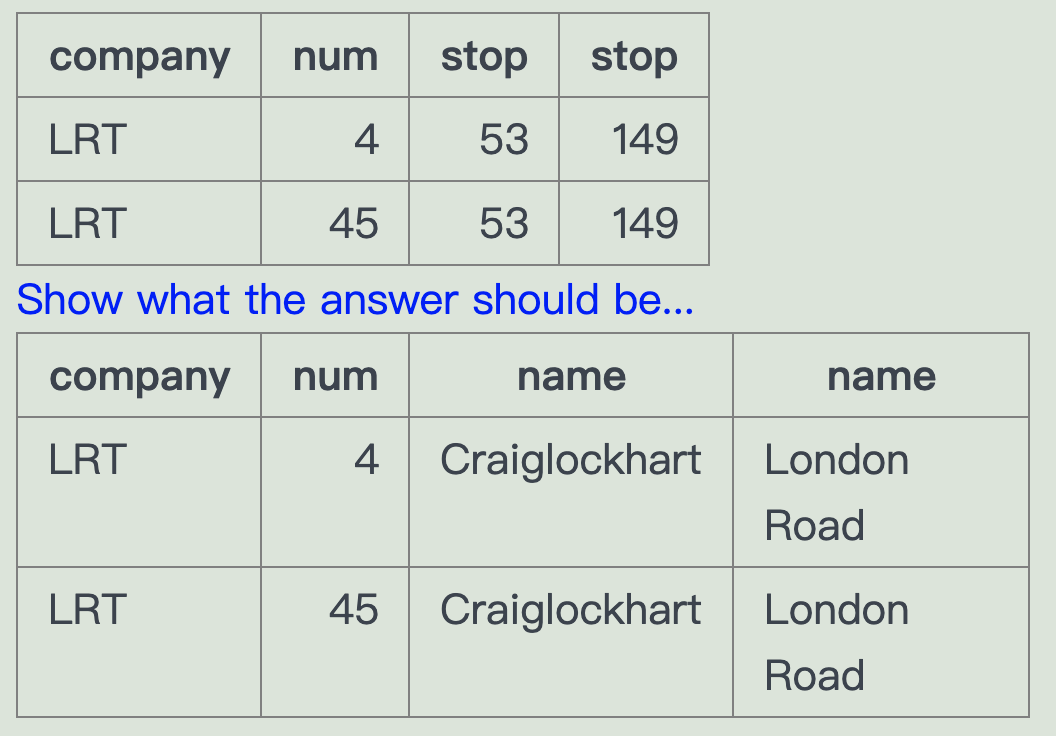
// 写不下去。而且也报错
select c.company c.num(select a.company,a.num,a.stop,b.stopfrom route a join route b on (a.company = b.company and a.num = b.num)where a.stop = (select id from stops where name = 'Craiglockhart')and b.stop = (select id from stops where name = 'London Road')) c join stops s on (stops.id = s.num)
因为需要两个转换 ,两个id转换为name
by joining two copies of the stops table we can refer to stops by name rather than by number
select a.company,a.num,stopa.name,stopb.namefrom route a join route b on (a.company = b.company and a.num = b.num)join stops stopa on a.stop = stopa.idjoin stops stopb on b.stop = stopb.idwhere stopa.name = 'Craiglockhart' and stopb.name = 'London Road'--where a.stop = (select id from stops where name = 'Craiglockhart')--and b.stop = (select id from stops where name = 'London Road')
栗3:求某车经过115 和 137
提示:使用self join
-- 连接115站和137站 route 与route连接select a.company,a.num from route a join route bon (a.num = b.num)where (a.stop = 115 and b.stop=137)
但是这样是错的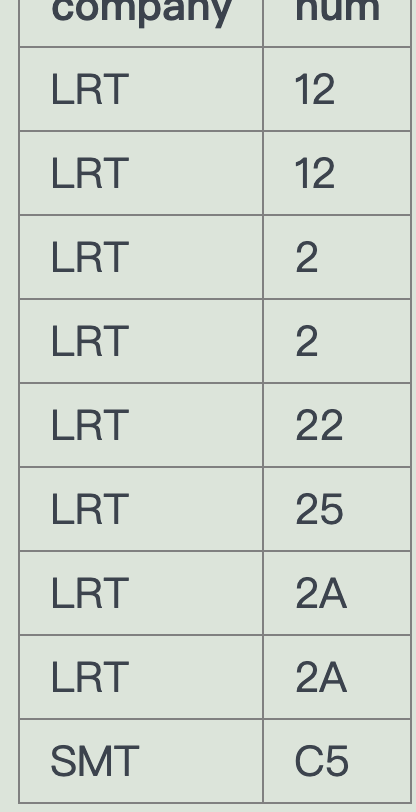
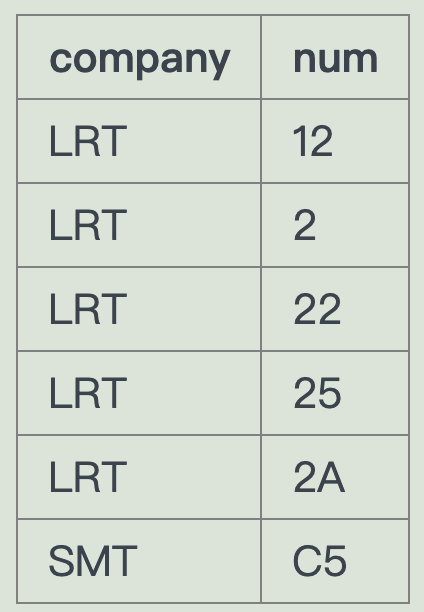 正确的是右边的数据
正确的是右边的数据
左边有重复的
===> 分组一下 定向去重
select a.company,a.num from route a join route bon (a.num = b.num)where (a.stop = 115 and b.stop=137)group by a.company ,a.num
其他解法
SELECT a.company, a.numFROM route a, route bWHERE a.num = b.num AND (a.stop = 115 AND b.stop = 137)GROUP BY num;
==>还可以 直接from两个表?
所以这题的关键是:
1、route表连查
2、num相等==》某车
3、group by去重
栗4:求某车经过某name和某name
select a.company , a.num from route ajoin route b on a.num = b.num --补充 on(a.num = b.num and a.company = b.company)join stops stopa on stopa.id = a.stopjoin stops stopb on stopb.id = b.stopwhere stopa.name = 'Craiglockhart' and stopb.name = 'Tollcross'
栗5:
Find the routes involving two buses that can go from Craiglockhart to Lochend. Show the bus no. and company for the first bus, the name of the stop for the transfer, and the bus no. and company for the second bus. Hint Self-join twice to find buses that visit Craiglockhart and Lochend, then join those on matching stops.
SELECT a.num, a.company, stopb.name, c.num, c.companyFROM route aJOIN route b ON (a.company = b.company AND a.num = b.num)JOIN (route c JOIN route d ON (c.company = d.company AND c.num = d.num))JOIN stops stopa ON a.stop = stopa.idJOIN stops stopb ON b.stop = stopb.idJOIN stops stopc ON c.stop = stopc.idJOIN stops stopd ON d.stop = stopd.idWHERE stopa.name = 'Craiglockhart'AND stopd.name = 'Lochend'AND stopb.name = stopc.nameORDER BY LENGTH(a.num), b.num, stopb.name, LENGTH(c.num), d.num;
这个答案是错的
cross join
CROSS JOIN连接用于生成两张表的笛卡尔集。
1、返回的记录数为两个表的记录数乘积。比如,A表有n条记录,B表有m条记录,则返回n*m条记录。
2、将A表的所有行分别与B表的所有行进行连接。
其实所有的连接都是从 cross join演化而来的

若有收获,就点个赞吧
0 人点赞
