参考文章
单页应用的数据流方案探索
前端应用开发:从数据流到真实应用之间,隔了些什么东西?
echarts antv 区别比较?
单页应用的数据流管理方案
- 组件化
- MDV(Model Driven View)
对很多低级DOM操作的简化,把对DOM的手动修改屏蔽了,通过从数据到视图的一个映射关系,达到了只要操作数据,就能改变视图的效果
V = f(M),当数据模型产生变化的时候,其对应的视图也会随之变化V + ΔV = f(M + ΔM)
从变更的角度去解读Model,数据模型不是无缘无故变化的,它是由某个操作引起的ΔM = perform(action)
把每次的变更综合起来,可以得到对整个应用状态的表达:
state := actions.reduce(reducer, initState)在初始状态上,依次叠加后续的变更,所得的就是当前状态 // redux的核心理念使用Redux,相当于把整个应用都实现为命令模式,一切变动都由命令驱动
Reactive Programming 库简介
在传统的编程实践中,我们可以:
- 复用一种数据
- 复用一个函数
- 复用一组数据和函数的集合
但是,很难做到:提供一种会持续变化的数据让其他模块复用
基于Reactive Programming的库可以提供一种能力,把数据包装成可持续变更、可观测的类型,供后续使用,这种库包括:RxJS,xstream,most.js等等
// a$、arr$、interval$都是一种可观测的数据包装// 可以对他们进行订阅,收到所有产生的变更const a$ = xs.of(1)const arr$ = xs.from([1, 2, 3])const interval$ = xs.periodic(1000)interval$.subscribe(console.log)// 可以把这种封装结构视为数据管道,// 在这种管道上,可以添加统一的处理规则,这种规则会作用在管道中的每个数据上,并且形成新的管道const interval$ = xs.periodic(1000)const result$ = interval$.filter(num => num % 3).map(num => num * 2)
管道规则:
- 管道是懒执行的。一个拼接起来的数据管道,只有最末端被订阅的时候,附加在管道上的所有逻辑才会被执行。
- 一般情况下,管道的执行过程可以被共享,比如b$和c$两个管道,都从a$变形得出,它们就共享了a$之前的所有执行过程。(git 分支)
- 也可以把多个管道合并成一个管道
新的抽象思想——数据流的思想
统一处理了一个普通请求过程中的三种状态:请求前、成功、异常,并且把它们的数据:loading、正常数据、异常数据都统一成一种,视图直接订阅处理就行了const data$ = xs.fromPromise(service(params)).map(data => ({ loading: false, data })).replaceError(error => xs.of({ loading: false, error })).startWith({loading: true,error: null,})
既然是数据流的思考,那么必须归纳出当前应用的所有数据流,之前我们基于过程式的开发,是一种比较低层次的抽象维度上,在低层抽象上,存在着太多的冗余过程。
数据的来源和去向有哪些呢?
从实体的角度,很可能一份数据初始状态有多个来源:(注意哦,初始值都可以对应多种变化)
- 应用的默认配置
- HTTP请求
- 本地存储
- …等等
也很可能有多个事件都是在修改同一个东西:
- 用户从视图发起的操作
- 来自WebSocket的推送消息
- 来自Worker的处理消息
- 来自其它窗体的postMessage调用
- …等等
比如业务开发里,我们被流程控制,追各个流程和事件,蓦然回首会发现,若干个类似的操作,在过滤掉额外信息之后,可能都是一样的。但是从状态的角度思考问题,我们可以得到新的侧重点:
我们不会需要关心一个数据究竟是从哪里来的,也不会需要关心是通过什么东西发起的修改
**
比如传统的redux开发,
// 根据分发 type区分事件,以及事件下对应的具体操作是什么(传参)// 分开器其实就是一个转发过程,是各个公共函数的调用入口const changeTodo = todo => {dispatch({type: 'updateTodo', payload: todo})}const changefromDOMEvent = () => {const todo = formStatechangeTodo(todo)}const changefromWebSocket = () => {const todo = fromWSchangeTodo(todo)
但是这样的一张翻译对照表,并不能很好地展示一份数据的生命周期,
- 它可能有哪些来源?
- 可能被什么修改?
因为他的思考就是基于方法调用的逻辑。我们在追踪一个个事件,触发数据改变的事件
但当数据流思考的时候,我们会关注生命周期,某个周期下他对应什么状态,一个状态从初始到终点是经过了哪些阶段。我们关心的重点不在于,一个个事件。(比如一个胚胎长大成人,你会关心她在每个阶段是怎么吃饭的吗,最先关心的应该是 要把他培养成人,每个阶段对应的什么吧,比如婴幼儿时期,孩童时期,青少年时期,虽然他每个阶段都会因为吃饭而长大,但我们追踪的不是吃饭这件事)
【初始状态来源】const fromInitState$ = xs.of(todo)const fromLocalStorage$ = xs.of(getTodoFromLS())// initStateconst init$ = xs.merge(fromInitState$,fromLocalStorage$).filter(todo => !todo).startWith({})【变更过程】const changeFromHTTP$ = xs.fromPromise(getTodo()).map(result => result.data)const changeFromDOMEvent$ = xs.fromEvent($('.btn', 'click')).map(evt => evt.data)const changeFromWebSocket$ = xs.fromEvent(ws, 'message').map(evt => evt.data)// 合并所有变更来源const changes$ = xs.merge(changeFromHTTP$,changeFromDOMEvent$,changeFromWebSocket$)
在这样的机制里,我们可以很清楚地看到一块数据的来龙去脉,它最初是哪里来的,后来可能会被谁修改过。所有这样的数据都放置在管道中,除了指定的入口,不会有其他东西能够修改这些数据,视图可以很安全地订阅他们
changes$.subscribe(({ payload }) => {xxx.setState({ todo: payload })})const updateActions$ = changes$.map(todo => ({type: 'updateTodo', payload: todo}))const todo$ = changeActions$.fold((state, action) => {const { payload } = actionreturn {...state, ...payload}}, initState)
组件与外置状态
组件树是一个树形结构。理想中的组件化,是所有视图状态全部内置在组件中,一级一级传递。只有这样,才能达到组件的最佳可复用状态,并且,组件可以放心把自己该做的事情都做了
但事实上,组件树的层级可能很多,这会导致传递层级很多,很繁琐,而且,存在一个经典问题,那就是兄弟组件,或者是位于组件树的不同树枝上的组件之间的通信很麻烦,必须通过共同的最近的祖先节点去转发
redux是如何解决的呢
Redux这样的机制,把状态的持有和更新外置,然后通过connect这样的方法,去把特定组件所需的外部状态从props设置进去,但它不仅仅是一个转发器
- 转发器在组件树之外
- 部分数据在组件树之外
- 对这部分数据的修改过程在组件树之外
- 修改完数据之后,通知组件树更新
归纳可得:
- 组件可以通过中转器修改其他组件的状态
- 组件可以通过中转器修改自身的状态
- 组件可以通过中转器修改全局的其他状态
即通知中心其实可以转发修改应用中的一切状态。
那么会思考,什么数据应该放在store里,什么数据放在组件里,或者说应用抽离UI木偶组件和带数据的组件的界限和标准在哪里
当然是能剥离的尽量剥离呀,利于组件测试,数据剥离外置离开特定环境便于形成纯函数啊什么的。
所有数据几乎都可以放在全局中更新,组件发送命令让store去更新,但是这里要考虑一个成本问题。比如一旦这个组件复杂起来,自带交互,可能就需要在事件、生命周期上做文章,免不了会需要一些中间状态来表达组件自身的形态。而此时数据强行剥离的问题
- 这样的状态只跟某组件自己有关,放出去到全局Store,会增加Store的不必要的复杂度
- 组件的自身形态状态被外置,将导致组件与状态的距离变远,从而对这些状态的读写变得比原先繁琐
- 带交互的组件,无法独立、完整地描述自身的行为,必须借助外部管理器
一个引起思考的demo
constructor(props) {super(props)this.state = { a: 1 }}render(props) {// 结果值由合并state和props的数据而得// 但是在这里做这个事情,是破坏了render函数的纯洁性的const c = this.state.a + props.b;return (<div>{c}</div>)}
可是,除了这里,别的地方也不太适合做这种合并,怎么办呢?
我们需要一种机制,能够把本地状态和props在render之外统一起来,这可能就是很多实践者倾向于把本地状态也外置的最重要原因。
在React + Redux的实践中,通常会使用connect对视图组件包装一层,变成一种叫做容器组件的东西,这个connect所做的事情就是把全局状态映射到组件的props中
const mapStateToProps = (state: { a }) => {return { a }}// const localState = { b: 1 }// const mapLocalStateToProps = localState => localStateconst ComponentA = (props) => {const { a, b } = propsconst c = a + breturn (<div>{ c }</div>)}return connect(mapStateToProps/*, mapLocalStateToProps*/)(ComponentA)
我们是否可以把一个组件的内部状态外置到被注释掉的这个位置,然后也connect进来呢?这段代码其实是不起作用的,因为对localState的改变不会被检测到,所以组件不会刷新。
MVI架构
一组理念:
- 一切都是事件源
- 使用Reactive的理念构建程序的骨架
- 使用sink来定义应用的逻辑
- 使用driver来隔离有副作用的行为(网络请求、DOM渲染)
基于这套理念,编写代码的方式可以变得很简洁流畅
- 从driver中获取action
- 把action映射成数据流
- 处理数据流,并且渲染成界面
- 从界面的事件中,派发action去进行后续事项的处理
在CycleJS的理念中,这种模式叫做MVI(Model View Intent)。在这套理念中,我们的应用可以分为三个部分:
- Intent,负责从外部的输入中,提取出所需信息
- Model,负责从Intent生成视图展示所需的数据
- View,负责根据视图数据渲染视图
App := View(Model(Intent({ DOM, Http, WebSocket })))
对比Redux这样的机制,它的差异在于:
- Intent实际上做的是action执行过程的高级抽象,提取了必要的信息
- Model做的是reducer的事情,把action的信息转换之后合并为状态对象
- View跟其他框架没什么区别,从状态对象渲染成视图。
在CycleJS中,View是纯展示,连事件监听也不做,这部分监听的工作放在Intent中去做。
- View还是纯渲染,接受的唯一参数就是一个表达视图状态的数据流
- Model的返回结果就是上面那个流,不分内外状态,全部合并起来
- Model所合并的东西的来源,是从Intent中来的
所有东西的输入输出都是数据流,甚至连视图接受的参数、还有它的渲染结果也是一个流!奥秘就在这里。
我们只需在把待传入视图的props与视图的state以流的方式合并,直接把合并之后的流的结果传入视图组件,就能达到我们在上一节中提出的需求
组件与分形
当组件树上的某一块越来越复杂,我们就把它再拆开,延伸出新的树枝和叶子,这个过程,与分形有异曲同工之妙
但是 因为全局状态和本地状态的分离,导致每一次分形,我们都要兼顾本组件、下级组件、全局状态、本地状态,在它们之间作一些权衡,这是一个很麻烦的过程。在React的主流实践中,一般可以利用connect这样的高阶函数,把全局状态映射进组件的props,转化为本地状态
上一节提及的MVI结构,不仅仅能够描述一个应用的执行过程,还可以单独描述一个组件的执行过程。
APP [ View <-- Model <-- Intent ]|------------------------------------------------| |ComponentA [ ViewA <-- ModelA <-- IntentA ] ComponentB
分形下去,每一级组件都可以拥有自己的View、Model、Intent
状态的变更过程
在模型驱动视图这个理念下,视图始终会是调用链的最后一段,它的职责就是消费已经计算好的数据,渲染出来。所以,从这个角度看,我们的重点工作在于怎么管理状态,包括结构的定义和变更的流转过程
基于标准Flux/Redux的实践有一个共同点:繁琐。产生这种繁琐的最主要原因是,它们都是以自定义事件为核心的,自定义事件本身就是繁琐的。由于收发事件通常位于两个以上不相同的模块中,不得不以封装的事件对象为通信载体,并且必须显式定义事件的key,否则接收方无法指定自己的响应
Redux这类东西出现的初衷只是为了提供一种单向数据流的思路,防止状态修改的混乱.在Redux体系中,我们在修改全局状态的时候,使用指定的action去修改状态,原因是要区分那个哪个action修改state的什么部分,怎样修改.而对于颗粒度低的组件,处理相关交互时反映的只是组件内部的数据变化,一般而言,其结构复杂程度远远低于全局状态
整个应用都是以“事件”为基石
基于Reactive理念的这几个库天然就是为了处理对事件机制的抽象而出现的,所以用在这种场景下有奇效,能把action的派发与处理过程描述得优雅精妙
const updateActions$ = changes$.map(todo => ({type: 'updateTodo', payload: todo}))const todo$ = updateActions$.fold((state, action) => {//fold操作,实际上就是直接在reduceconst { payload } = actionreturn {...state, ...payload}}, initState)
核心:写出反映若干种数据变更的合集了,这个时候,可以根据不同的action去选择不同的reducer操作
// 我们可以先把这些action全部merge之后再fold,跟Redux的理念类似const actions = xs.merge(addActions$,updateActions$,deleteActions$)const localState$ = actions.fold((state, action) => {switch(action.type) {case 'addTodo':return addTodo(state, action)case 'updateTodo':return updateTodo(state, action)case 'deleteTodo':return deleteTodo(state, action)}}, initState)
有没有可能各自fold之后再merge呢?
其实是有可能的,我们只要能够确保action导致的reducer粒度足够小,比如只修改state的同一个部分,是可以按照这种维度去组织action的。
const a$ = actionsA$.fold(reducerA, initA)const b$ = actionsB$.fold(reducerB, initB)const c$ = actionsC$.fold(reducerC, initC)const state$ = xs.combine(a$, b$, c$).map(([a, b, c]) => ({a, b, c}))
如果我们一个组件的内部状态足够简单,甚至连action的类型都可以不需要,直接从操作映射到状态结果
const state$ = xs.fromEvent($('.btn'), click).map(e => e.data)
这样,我们可以在组件内运行这种简化版的Redux机制,而在全局状态上运行比较完善的。这两种都是基于数据管道的,然后在容器组件中可以把它们合并,传入视图组件。
---------------------↑ ↓|-- LocalStateView <-- ||-- GlobalState↓ ↑Action --> Reducer
状态的分组与管理
基于redux-saga的封装库dva提供了一种分类机制,可以把一类业务的东西进行分组:
export const project = {namespace: 'project',state: {},reducers: {},effects: {},subscriptions: {}}
它定义了:
- 它是面向的什么业务模型
- 需要在全局存储什么样的数据结构
- 经过哪些操作去变更数据
面向同一种业务实体的数据结构、业务逻辑可以组织到一起,这样,对业务代码的维护是比较有利的。对一个大型应用来说,可以根据业务来划分model。Vue技术栈的Vuex也是用类似的结构来进行业务归类的,它们都是受elm的启发而创建,因此会有类似结构。(怪不得我觉得 vuex 和 dva那么像
改进的点:如果若干个reducer修改的是state的不同位置,可以分别收敛之后,再进行合并。采用这种机制来分别收敛。这样,单个model内部就形成了一个闭环。
// mobx 的store就是这样的形式
class TodoStore {authorStore@observable todos = []@observable isLoading = trueconstructor(authorStore) {this.authorStore = authorStorethis.loadTodos()}loadTodos() {}updateTodoFromServer(json) {}createTodo() {}removeTodo(todo) {}}
所谓的model其实就是一个合并之后生成state结构的数据管道,因为我们的管道是可以组合的,所以没有特别的必要去按照上面那种结构定义
在整个应用的最上层,是否还有必要去做combineReducer这种操作呢?
整个React-Redux体系,都是倾向于让使用者尽可能去从整体的角度关注变化,比如说,Redux的输入输出结果是整个应用变更前后的完整状态,React接受的是整个组件的完整状态,然后,内部再去做diff
为什么不是直接把Redux接在React上,而是通过一个叫做react-redux的库呢?因为它需要借助这个库,去从整体的state结构上检出变化的部分,拿给对应的组件去重绘
- 在触发reducer的时候,我们是精确知道要修改state的什么位置的
- 合并完reducer之后,输出结果是个完整state对象,已经不知道state的什么位置被修改过了(viewData
- 视图组件必须精确地拿到变更的部分,才能排除无效的渲染
变更信息经历了过程:拥有——>丢失——>重新拥有
如果我们的数据流是按照业务模型去分别建立的,我们可以不需要去做这个全合并的操作,而是根据需要,选择合并其中一部分去进行运算。整个变更过程都是精确的,减少了不必要的diff和缓存。
model的结构
我们从宏观上对业务模型作了分类的组织,接下来就需要关注每种业务模型的数据管道上,数据格式应当如何管理了。
我们思考,在store中,应当以什么样的形式存放数据?
**通常,会有两种选择:
- 打平了的数据,尽可能以id这样的key去索引
- 贴近视图的数据,比如树形结构
前者有利于查询和更新,而后者能够直接给视图使用。
面临取舍,我们需要思考一个问题:将处理过后的视图状态存放在store中是否合理?
**
徐飞认为不存太偏向视图结构的数据,理由:
某一种业务数据,很可能被不同的视图使用,它们的结构未必一致,如果按照视图的格式存储,就要在store中存放不同形式的多份,它们之间的同步是个大问题,也会导致store严重膨胀,随着应用规模的扩大,这个问题更加严重
(这个道理其实还是好理解,比如数据库就不是按照视图存储数据结构的吧
当然,直接存视图数据会简单很多,但是我们一定要警惕一切表面看似简单的解决方案。因为后期,会涉及到很多重复的,微小的变化,然后我们要因为这个微小的变化在之间设置的数据结构下 重复劳动。
那么我们思考,这个更难一点的解决方案的突破入口,首先面临要解决的问题:
从这种数据到视图所需数据的关联关系,这个处理过程放在哪里合适呢?
在Redux和Vuex中:
为了数据的变更受控,应当在reducer或者mutation中去做状态变更,但这两者修改的又是store,这又绕回去了:为了视图渲染方便而计算出来的数据,如果在reducer或者mutation中做,还是得放在store里
从原始数据到视图数据的处理过程不应当放在reducer或mutation中,那很显然==>应当放在视图组件的内部去做
// 方括号的部分是视图组件,它内部包含了从原始state到view所需数据的变动[ View <-- VM ] <-- State↓ ↑Action --> Reducer
render(props) {const { flatternData } = propsconst viewData = formatData(flatternData)// ...render viewData}
store中的结构更加简单清晰,reducer的职责也更少了,视图有更大的自主权,去从原始数据组装成自己要的样子。
结论:
在大型业务开发中,store的结构应当尽早稳定,避免因为视图的变化而不停调整
===》 存放相对原始一些的数据是更合理的,这样也会避免视图组件在理解数据上的歧义。在store中存储更偏向于更扁平化的原始数据
btw: 对于从后端返回的层级数据,也可以借助normalizr这样的辅助库去展开
| 展开前 | 展开后 |
|---|---|
 |
 |
这样的结构对我们的后续操作是比较便利的。因为我们手里有数据管道这样的利器,所以不担心数据是比较原始的、离散的,因为对它们作聚合处理是比较容易的,所以可以放心地把这些数据打成比较原始的形态
前端的数据建模
store里面存放的是扁平化的原始数据,但是需要注意到,同样是扁平化,可能有像map那样基于id作索引的,也可能有基于数组形式存放的,很多时候,我们是两种都要的
更复杂的情况下,还会需要有对象关系的关联,一对一,一对多,多对多,这就导致视图在需要使用store中的数据进行组合的时候,不管是store的结构定义还是组合操作都比较麻烦
实际情况下,都会比这个复杂,业务模型之间会存在关联关系,在一个模型变更的时候,可能需要自动触发所关联到的模型的更新
如果联动关系非常复杂,可以考虑对数据按照实体、关系进行建模,甚至加入一个迷你版的类似ORM的库来定义这种关系
比如
- 组织可以有下层组织
- 组织下可以有人员
- 组织和人员是一对多的关系
上层视图可以根据自己的需要,选择从不同的数据流订阅不同复杂度的信息。在这种情况下,可以把整个ORM模块整体视为一个外部的数据源
[ View <-- VM ] <-- [State <-- ORM]↓ ↑Action --> Reducer
- 一个action实际上还是对应到一个reducer,然后发起对state的更改,但因为state已经不是简单结构了,所以我们不能直接改,而是通过这层类似ORM的关系去改。
- 对ORM的一次修改,可能会产生对state的若干处改动,比如说,改了一个数据,可能会推导出业务上与之有关系的一块关联数据的变更。
- 如果是基于react-redux这样基于diff的机制,同时修改state的多个位置是可以的,但在我们这套机制里,因为没有了先合并修改再diff的过程,所以很可能多个位置的修改需要通过ORM的关联,延伸出不同的管道来。
- 视图订阅的state变更,只能组合运算,不应当再干别的事情了
在这么一种体系下,实际上前端存在着一个类似数据库的机制,我们可以把每种数据的变动原子化,一次提交只更新单一类型的实体
我们相当于在前端部分做了一个读写分离,读取的部分是被实时更新的,可以包含一种类似游标的机制,供视图组件订阅。
小结
1、最理想的组件化开发方式是依托组件树的结构,每个组件完成自己内部事务的处理
2、==》由于兄弟组件通信麻烦,不得不借助于Redux之类的库来做转发
3、===》但是Redux的理念,又不仅仅是只定位于做转发,它更是期望能管理整个应用的状态
反过来对组件的实现,甚至应用的整体架构造成了较大的影响
4、====》期望有一种机制,能够像分形那样进行开发,但又希望能够避免状态管理的混乱
MVI这样的模式某种程度上能够满足这种需求,并且达到逻辑上的自洽
MVI的理念:一个组件其实是:数据模型、动作、视图三者的集合,这么一个MVI组件相当于React-Redux体系中,connect了store之后的高阶组件
需把传统的组件作一些处理:
- 视图隔离,纯化为展示组件
- 内部状态的定义清晰化
- 描述出内部状态的来源关系:state := actions.reduce(reducer, initState)
- 将内部的动作以action的方式输出到上面那个表达式关系中
此时组件不关注外面是不是Redux,有没有全局的store,每个组件自己内部运行着一个类似Redux的东西,这样的一个组件可以更加容易与其他组件进行配合
与Redux相比,这套机制的特点是:
- 不需要显式定义整个应用的state结构
- 全局状态和本地状态可以良好地统一起来
- 可以存在非显式的action,并且action可以不集中解析,而是分散执行
- 可以存在非显式的reducer,它附着在数据管道的运算中
- 异步操作先映射为数据,然后通过单向联动关系组合计算出视图状态
流程:
- 数据的写入部分,都是通过类似Redux的action去做
- 数据的读取部分,都是通过数据管道的组合订阅去做
RxJS、xstream所提供的数据流组合功能非常强大,天然提供了一切异步操作的统一抽象,因为拥有下面这些特性,很适合做数据流控制:
- 对事件的高度抽象
- 同步和异步的统一化处理
- 数据变更的持续订阅(订阅模式)
- 数据的连续变更(管道拼接)
- 数据变更的的组合运算(管道组合)
- 懒执行(无订阅者,则不执行)
- 缓存的中间结果
- 可重放的历史记录
……等等
感悟:
1、数据流真的随着业务的繁重 就越复杂。数据领域的概念很重要、比如数据流这个是我之前学react或者看源码的主要流程,就是跟着数据走。繁琐的地方在于很多交互的地方都会对数据进行修改。需要自己整理副作用和因为一个数据的修改去维护副作用。
不是基于事件的数据流管理方式非常耳目一新,就像是excel的函数一样,一旦订阅后数据是联动的
(基于事件的管理方式,一般是因为修改某个单元格然后重新渲染整个excel。规避方式就是来个dom-diff
(而数据流是真的数据流,是一种联动。很期待这方面的学习和使用
2、一些概念过于抽象了,如果有精巧的demo就好了。徐叔对数据流的研究真的让人很舒畅,跟他到底。他的思考方式也很理性和具有逻辑性,粉了
3、对于应用到本excel有什么启发吗。
1、我没有引入数据管理方式,尽管有很多组件,但是组件之间的数据交互方式都是通过最原始的,回调传递
虽然应用抽象了model,model也不算是view的映射,是相当于扁平的数据。但是存在很多很多不一样的交互入口对数据进行修改,这个数据是被暴露在广场上的,并没有在一个管道里进行有理 的控制。
这也是我目前写到这个地步感觉有点麻烦的地方,的确存在很多交互操作经过过滤之后,发现达到的其实是一个修改目的。而且因为这个修改,会去维护好多同一个到达。(我现在的解决方式是:设置了一个拦截器)
扩展阅读:
- 对于V + ΔV = f(M + ΔM)这个模式 ,一个更普遍的理论来解释:可逆计算:下一代软件构造理论
从数据流到真实应用,隔了啥
数据驱动与事件驱动
驱动讨论的是model驱动view渲染这个环节
数据:状态
事件:行为
数据导致状态:render参数入口是model数据,调用时机是数据改变的时候,能做的事是——
- 告诉系统下一个时刻的界面状态,即新modeldata
数据驱动的renderer,有可能是纯函数(function),返回下一时刻界面长什么样即可
数据驱动的renderer,一定不能做的两件事是
- 修改数据本身,很显然,这会造成死循环。
- 任何有精确时机要求的行为(比如动画),因为renderer调用时机不可控
事件导致行为:render参数入口是一个事件,调用时机是事件发生时,那么可以做任何事——
- 把模型中的数据在界面上渲染出来
- 根据事件的类别,在界面上开启任何动画
然而所有这些行为,统统是有副作用的
事件驱动的renderer,一定是个过程(procedure),要亲自去改动自己想改动的东西。
怎么定义对象
一个用户界面(UI)程序,总是由一个个对象构成的,那么对象应该是个什么样子呢?或者说你的class应该定义成什么样呢
==》 很可靠的对象模型,叫做PME
PME就是property,method,以及event的缩写,是指一个对象,由属性,方法,以及事件构成。属性用来记录对象的状态,方法用来规定对象的行为,事件用来想外部传递对象内部发生了些什么事儿(接口
import { Eventable, Event} from '...'class Foobar extends Eventable {property1: numbermethod1 () : void {// ...}}const fb = new Foobar()fb.on('its-time-to-do-xxx', (event: Event) => {doXXX()})
个稍具复杂性的应用,都应该有一套完善的事件订阅机制
**
单页应用的结构
单页应用,无非是数据流、前端框架、路由框架三件套
一些写的比较烂的前端应用代码,一般有的问题:
- 组件里面夹杂了各种本不该属于组件的代码
- 数据流里面夹杂了各种本不该属于数据流的代码
==》 没有做好模块划分导致的
前端项目脚手架的主要作用之一,就是给应用开发者一个既定的编程范式,使得前端项目的技术选型和总体结构保持统一,这是目前大多数前端团队都采用的方式。
what is 结构:“结构”,既指文件结构(同时也就是模块划分),也只运行时各个模块之间的关系
**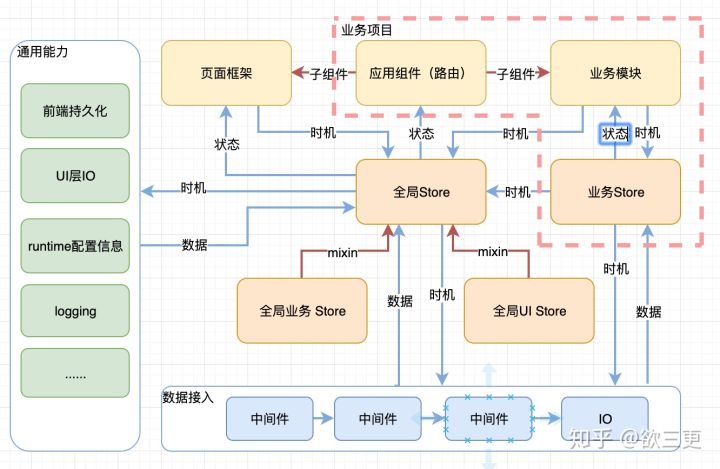
把前端模块之间的关系规约为以下四种(基本上与UML里的对象关系对应,但是侧重点不同
- 时机告知:一个模块告诉另一个模块“你该做xxx”了。代码体现为action或方法调用等
- 数据告知:一个模块将数据推送至另一模块,比如store到组件
- mixin:即两个模块在运行时会合并为一个实例,只是代码分属于不同模块
- 子组件:两个模块存在包含关系,父模块可以传递数据给子模块,子模块可以传递实际给父模块
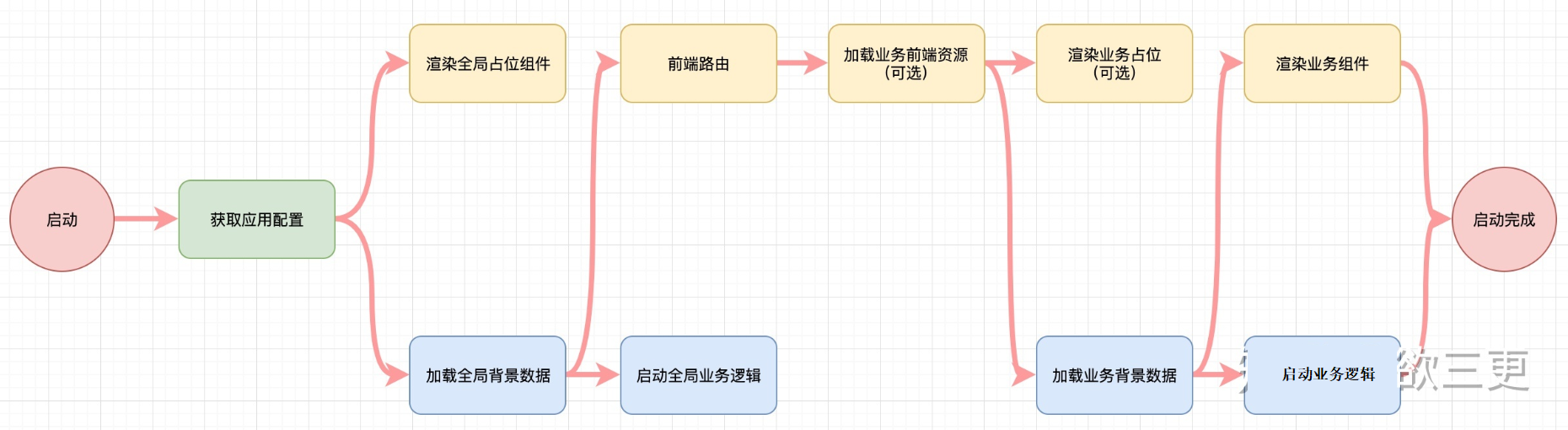
- 关键在于,要严格区分清楚,启动流程中的每一个行为,分别对应数据哪个环节,并且严格的放在那个环节里面
- 背景数据: 比如菜单导航,用户信息,这些加载一次一般就不会变的数据,我们管他们叫做“背景数据”
在背景数据加载完成之前,不建议渲染任何有实际意义的模块,也不建议开启任何业务逻辑。
- 应用配置信息:统一管理所有的配置常量,不关你是挂载window上,还是放在代码里,或者是从后端拿,总之,要把配置信息收敛在一起
总结:
基本上,当你有了搞清楚了各种驱动关系的使用场景,统一了对象/模块的写法,拥有了固化的代码结构,以及固化的启动流程,你的前端项目就有了一个下限的保证,再差也不会差到哪里了(堆砌业务代码了剩下就)
感悟:
为什么会有那么多js框架和库?其实大多数时候,这些框架和库并不是封装了一坨所有人都看不懂、写不出的“高级代码”,而是提供一个模式,让开发者按照既定的路线编写应用。框架和库的意义在于——通过代码引导行为。
阅读本文的总结:
- 数据驱动与事件驱动。(我的应用就是 数据和事件都在驱动orz,还好数据驱动的渲染 并没有改变数据。。这点自知之明还是有的)
- 对象定义分为:属性、方法、事件。属性用来记录对象的状态,方法用来规定对象的行为,事件用来想外部传递对象内部发生了些什么事儿(接口
- 稍显复杂的应用都应该有 事件订阅系统。我没有。。。(只是用了原生的事件系统)
- 因为没有做好模块划分导致的应用常见问题:
- 组件里面夹杂了各种本不该属于组件的代码——还没有。模块各司其职这块还是做的比较好
- 数据流里面夹杂了各种本不该属于数据流的代码——抽象出了data_proxy就有数据流了
- 模块之间的关系
- 时机告知:一个模块告诉另一个模块“你该做xxx”了。代码体现为action或方法调用等
- 数据告知:一个模块将数据推送至另一模块,比如store到组件(还是觉得我直接传递context的做法过于搞笑了)
- mixin:即两个模块在运行时会合并为一个实例,只是代码分属于不同模块
- 子组件:两个模块存在包含关系,父模块可以传递数据给子模块,子模块可以传递实际给父模块
- 系统的启动的整个流程
- 应用配置:组件固定配置、组件入口传入的参数配置、
- 加载背景数据、全局站位组件:比如toolbar、context、背景数据
- 启动业务逻辑——业务背景数据、业务组件、
话说回来,对我的应用有什么指导意义呢?
1、我的应用并没抽离出一个单项数据流,更别说归纳所有数据入口和过程,将其抽象为一个数据管道了
2、抽象出data_proxy。对这个数据用管道保护隔离起来。——抽象的过程就可以归纳出有哪些动作对他是什么样的修改了。
综上:没啥指导意义,不过重构的时候倒是可以看看

若有收获,就点个赞吧
0 人点赞
