参考
Immutable.js 以及在 react+redux 项目中的实践
Immutable 操作在 React 中的实践
结合 Immutable.JS 使用 Redux
问题引入
const data = {list: [{name: 'aaa',sex: 'man'},{name: 'bbb',sex: 'woman'}],status: true,}
data 数据是一个引用类型,当更改了其中的某一字段,并期望在改变之后组件可以重新渲染的时候,发现使用 PureComponent 的时候,发现组件并没有重新渲染,因为更改后的数据和修改前的数据使用的同一个内存,所有比较的结果永远都是 false, 导致组件并没有重新渲染。
要解决上面这个问题,就要考虑怎么实现更新后的引用数据和原数据指向的内存不一致
通常这类问题的解决方案是通过浅拷贝或者深拷贝复制一个新对象,从而使得新对象与旧对象引用地址不同。
常规解决办法
1、深拷贝,然后修改复杂类型,再用拷贝后的数据render,这样就是不同的内存。
弊端是 耗费内存
2、stringfy黑魔法
它的缺点除了和上面那种一样之外,还有两点就是如果你的对象里有函数,函数无法被拷贝下来,同时也无法拷贝copyObj对象原型链上的属性和方法
3、使用es6的解构浅复制
const data = {list: [{name: 'aaa',sex: 'man'}, {name: 'bbb',sex: 'woman'}],status: true,}const newData = {...data};newData.status = false;newData.list[0].name = 'test';console.log(data.status) // trueconsole.log(newData.list[0].name)// test
问题:当修改数据中的简单类型的变量的时候,使用解构是可以解决问题的,但是当修改其中的复杂类型的时候就不能检测到
新的解决办法:
在js中,引用类型的数据,优点在于频繁的操作数据都是在原对象的基础上修改,不会创建新对象,从而可以有效的利用内存,不会浪费内存,这种特性称为mutable(可变),但恰恰它的优点也是它的缺点,太过于灵活多变在复杂数据的场景下也造成了它的不可控性,假设一个对象在多处用到,在某一处不小心修改了数据,其他地方很难预见到数据是如何改变的,针对这种问题的解决方法,一般就像刚才的例子,会想复制一个新对象,再在新对象上做修改,这无疑会造成更多的性能问题以及内存浪费。
为了解决这种问题,出现了immutable对象,每次修改immutable对象都会创建一个新的不可变对象,而老的对象不会改变。
介绍
Immutable.js出自Facebook,是最流行的不可变数据结构的实现之一。它从头开始实现了完全的持久化数据结构
immutable.js主要有三大特性:
- Persistent data structure (持久化数据结构)
- structural sharing (结构共享)
- support lazy operation (惰性操作)
持久化
持久化用来描述一种数据结构,一般函数式编程中非常常见,指一个数据,在被修改时,仍然能够保持修改前的状态,从本质来说,这种数据类型就是不可变类型,也就是immutable immutable.js提供了十余种不可变的类型(List,Map,Set,Seq,Collection,Range等)
但是,这并不是基于这个不可变类型进行深拷贝然后再进行修改的一个库(哪有那么简单,肯定是对暴力深拷贝进行了优化呀~~
共享结构
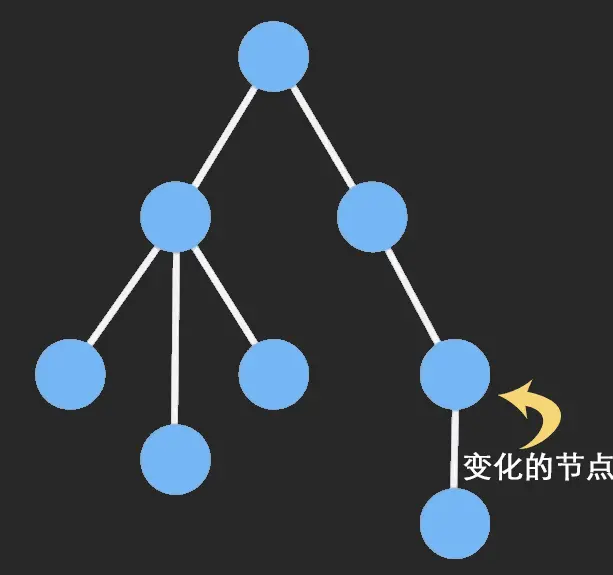
immutable使用先进的tries(字典树)技术实现结构共享来解决性能问题,当我们对一个Immutable对象进行操作的时候,ImmutableJS会只clone该节点以及它的祖先节点,其他保持不变,这样可以共享相同的部分,大大提高性能。
由于采用了字典树,比较两个对象时,只要他们的hashcode是相同的,他们的值就是一样的,这样可以避免深度遍历
惰性操作
api
//Map() 原生object转Map对象 (只会转换第一层,注意和fromJS区别)immutable.Map({name:'danny', age:18})//List() 原生array转List对象 (只会转换第一层,注意和fromJS区别)immutable.List([1,2,3,4,5])//fromJS() 原生js转immutable对象 (深度转换,会将内部嵌套的对象和数组全部转成immutable)immutable.fromJS([1,2,3,4,5]) //将原生array --> Listimmutable.fromJS({name:'danny', age:18}) //将原生object --> Map//toJS() immutable对象转原生js (深度转换,会将内部嵌套的Map和List全部转换成原生js)immutableData.toJS();//查看List或者map大小immutableData.size 或者 immutableData.count()// is() 判断两个immutable对象是否相等immutable.is(imA, imB);//merge() 对象合并var imA = immutable.fromJS({a:1,b:2});var imA = immutable.fromJS({c:3});var imC = imA.merge(imB);console.log(imC.toJS()) //{a:1,b:2,c:3}//增删改查(所有操作都会返回新的值,不会修改原来值)var immutableData = immutable.fromJS({a:1,b:2,c:{d:3}});var data1 = immutableData.get('a') // data1 = 1var data2 = immutableData.getIn(['c', 'd']) // data2 = 3 getIn用于深层结构访问var data3 = immutableData.set('a' , 2); // data3中的 a = 2var data4 = immutableData.setIn(['c', 'd'], 4); //data4中的 d = 4var data5 = immutableData.update('a',function(x){return x+4}) //data5中的 a = 5var data6 = immutableData.updateIn(['c', 'd'],function(x){return x+4}) //data6中的 d = 7var data7 = immutableData.delete('a') //data7中的 a 不存在var data8 = immutableData.deleteIn(['c', 'd']) //data8中的 d 不存在
优缺点
优点:
- 降低mutable带来的复杂度
- 节省内存
- 历史追溯性(时间旅行):时间旅行指的是,每时每刻的值都被保留了,想回退到哪一步只要简单的将数据取出就行,想一下如果现在页面有个撤销的操作,撤销前的数据被保留了,只需要取出就行,这个特性在redux或者flux中特别有用**(**啊啊啊啊啊好激动,,原来我的excel死的那一步可以这样解决orz
- 拥抱函数式编程:immutable本来就是函数式编程的概念,纯函数式编程的特点就是,只要输入一致,输出必然一致,相比于面向对象,这样开发组件和调试更方便 (对函数式更感兴趣了。。
缺点:
- 需要重新学习api
- 资源包大小增加(源码5000行左右)
- 容易与原生对象混淆:由于api与原生不同,混用的话容易出错

若有收获,就点个赞吧
0 人点赞
