一些俺摸不着头脑的词语:
ts设计原则、
依赖注入、
slate设计:插件机制,历史记录机制
一言以蔽之:
在传统面向对象的编码过程中,当类与类之间存在依赖关系时,通常会直接在类的内部创建依赖对象
IoC 则是专门提供一个容器进行依赖对象的创建和查找,将对依赖对象的控制权由类内部交到容器这里,
这样就实现了类与类的解耦,保证所有的类都是可以灵活修改。
问题引入
假设我们有 A、B 两个类,它们之间存在的依赖关系是 A 依赖 B
什么叫A依赖于B,通常是A需要调用B.xxx()方法,所以直接把B整个类在A初始化的时候,在A内部实例
如果需要的是B的实例方法,那么就需要在new A(b) 传入B的实例b
// b.tsclass B {constructor() {}}// a.tsclass A {b:B;constructor() {this.b = new B();}}// main.tsconst a = new A();
突然接到了新需求,处于最底层的 B 在初始化对象的时候需要传递一个参数 p
// b.tsclass B {p: number;constructor(p: number) {this.p = p;}}// 对应A也要修改// a.tsclass A {b:B;constructor(p: number) { # 由于B实例化需要接受参数p,所以只能让A也开放一个参数this.b = new B(p);}}// main.tsconst a = new A(10);console.log(a); // => A { b: B { p: 10 } }
即只要当B入参有改动,那么A对应的new的地方也要修改
这就是耦合所带来的问题,明明是修改底层类的一项参数,却需要修改其依赖链路上的所有文件
当应用程序的依赖关系复杂到一定程度时,很容易形成牵一发而动全身的现象
loc容器
如何解耦?
事实上,我们可以发现,在上述例子中,真正需要参数 p 的仅仅只有 B,而 A 完全只是因为内部依赖的对象在实例化时需要 p,才不得不定义这个参数,实际上它对 p 是什么根本不关心
考虑将类所依赖对象的实例化从类本身剥离出来
===> new A(b) 将实例化好的B传入
虽然我们实现了解耦,但我们仍需要自己初始化所有的类,并以构造函数参数的形式进行传递
如果存在一个全局的容器,里面预先注册好了我们所需对象的类定义以及初始化参数,每个对象有一个唯一的 key。那么当我们需要用到某个对象时,我们只需要告诉容器它对应的 key,就可以直接从容器中取出实例化好的对象,
开发者就不用再关心对象的实例化过程,也不需要将依赖对象作为构造函数的参数在依赖链路上传递。
我们的容器必须具体两个功能,实例的注册和获取
// b.tsclass B {constructor(p: number) {this.p = p;}}// a.tsclass A {b:B;constructor() {this.b = container.get('b');}}// main.tsconst container = new Container();container.bind('a', A);container.bind('b', B, [10]);// 从容器中取出aconst a = container.get('a');console.log(a); // A => { b: B { p: 10 } }
代码改造demo
业务场景:
现有订单类,现在新增两个需求:订单可以评价 & 订单可以分享
常规思路:订单类 依赖 评价类、分享类
所以:
class Order{constructor(){this.rate = new Rate(); # 评分类this.share = new Share(); # 分享类}// 省去模块其余部分 ...}const order = new Order();order.share.shareTo('wxposts'); // 分享order.getInfo();order.rate.star(5); // 评价
使用IoC的思想改造模块:
上述示例中我们将Order称为高层模块,将Rate和Share称为低层模块;高层模块中依赖低层模块
IoC则将这种依赖关系倒置:高层模块定义接口,低层模块实现接口;
这样当我们修改或新增低层模块时就不会破坏开闭原则。
其实现方式通常是依赖注入:也就是将所依赖的低层模块注入到高层模块中。
简单版loc
class Order {// 用于维护依赖关系的Mapstatic modules = new Map(); # 在高层模块中定义静态属性来维护依赖关系:constructor(){for (let module of Order.modules.values()) {// 调用模块init方法module.init(this); # 依赖类 实例,并将高层的order实例 放入依赖类里}}// 向依赖关系Map中注入模块static inject(module) {Order.modules.set(module.constructor.name, module);}/** 其余部分略 */}class Rate{init(order) { # line7调用的order.rate = this;}star(stars){console.log('您对订单的评价为%s星',stars);}}const prate = new Rate();const porder = new Order();// 注入依赖Order.inject(prate); // Order这里做为了容器porder.rate.star(4);// order.rate = Rate类, 以此实现order上调用依赖类上的方法
通过在Order类中维护自己的依赖模块,
同时模块中实现init方法供Order在构造函数初始化时调用。
此时Order即可称之为容器,他将依赖关系收于囊中。
这样改的好处?
依赖注入就是把高层模块的所依赖的低层次模块以参数的方式注入高模块中,
这种方式可以修改低层次依赖而不影响高层次依赖。
解了什么耦?
1、注入的是实例,所以不需要多处new的时候修改
即只要当B入参有改动,那么A对应的new的地方也要修改这就是耦合所带来的问题, 明明是修改底层类的一项参数,却需要修改其依赖链路上的所有文件
2、抽象了容器管理,直接从容器里拿实例,而不需要传来传去
(在容器里保证了实例会对应唯一的key,代码复用了,内存空间也复用了(没有重复实例类
虽然我们实现了解耦,但我们仍需要自己初始化所有的类,并以构造函数参数的形式进行传递 如果存在一个全局的容器,里面预先注册好了我们所需对象的类定义以及初始化参数,每个对象有一个唯一的 key。那么当我们需要用到某个对象时,我们只需要告诉容器它对应的 key,就可以直接从容器中取出实例化好的对象, 开发者就不用再关心对象的实例化过程,也不需要将依赖对象作为构造函数的参数在依赖链路上传递。
我们的容器必须具体两个功能,实例的注册和获取
3、欠缺: 依赖可以声明自己需要的
DI,自动分论别类的注入
现在的实现是 默认 底层都是注入高层Order
整个结构是树状的,由root自上而下
而更复杂的存在 各自依赖的情况,网状
再重复一下:
依赖注入就是把高层模块的所依赖的低层次模块以参数的方式注入高模块中,
这种方式可以修改低层次依赖而不影响高层次依赖。
注入的方式要注意一下:
因为我们不可能在高层次模块中预先知道所有被依赖的低层次模块,
也不应该在高层次模块中依赖低层次模块的具体实现。
因此注入需要分成两部分:
1、高层次模块中通过加载器机制解耦对低层次模块的依赖,转而依赖于低层次模块的抽象;
2、低层次模块的实现依照约定的抽象实现,并通过注入器将依赖注入高层次模块
如何理解「控制反转:通过注入依赖将控制权交给被依赖的低层级模块」
高层次模块就脱离了业务逻辑转而成为了低层次模块的容器 低层次模块则面向接口编程:满足对高层次模块初始化的接口的约定即可
基于类修饰器注入版loc
上述示例中IoC的实现仍略显繁琐:模块需要显式的声明init方法,容器需要显示的注入依赖并且初始化。
这些业务无关的内容我们可以通过封装进入基类、子类进行继承的方式来优化,也可以通过修饰器方法来进行简化。
实现一个类修饰器,用于实例化所依赖的低层模块,并将其注入到容器内
function Inject(modules: any) {return function(target: any) {modules.forEach((module:any) => {target.prototype[module.name] = new module();});};}
最后在容器类上使用这个修饰器:
# 这些类保持自己的业务写法即可 无需实现额外的init等方法@Inject([Aftermarket,Share,Rate]) # 依赖们class Order {constructor() {}/** 其它实现略 */}const order:any = new Order();order.Share.shareTo('facebook'); // 好家伙 把依赖的实例挂在 容器上了
DI依赖注入
基于容器可以完成了类与类的解耦==>loc
大概思路是,容器即是维护一个map
上面的代码,看上去似乎并没有简洁多少,关键问题在于容器的初始化以及类的注册仍然让我们觉得繁琐
如果这部分代码能被封装到框架里面:
1、所有类的注册都能够自动进行
2、所有类在实例化的时候可以直接拿到依赖对象的实例,而不用在构造函数中手动指定
这样就可以彻底解放开发者的双手,专注编写类内部的逻辑
而这也就是所谓的 DI(Dependency Injection)依赖注入。
IoC 只是一种设计原则,而 DI 则是实现 IoC 的一种实现技术
简单来说就是:如果调用方对某模块有依赖,那么实现这种依赖关系的方式的转变:
before:调用方来主动获取依赖
after:将依赖注入给调用方,调用方只管声明所依赖的依赖接口,实现依赖接口的实例类,有DI去注入
依赖注入实现的思路:
利用 TypeScript 具备的装饰器特性,
识别依赖:通过对元数据的修饰来识别出需要进行注册以及注入的依赖,从而完成依赖的注入。
实现了DI后的代码是这样的效果:
# a 依赖 b// b.ts@Proivder('b', [10]) // p=10class B {constructor(p: number) {this.p = p;}}// a.ts@Proivder('a')class A {@Inject()private b:B;}// main.tsconst container = new Container(); # import { PROPS_KEY } from './inject';load(container); # load:import { CLASS_KEY } from './provider';console.log(container.get('a')); // => A { b: B { p: 10 } }
代码中不会再有手动进行实例化的情况,无论要注册多少个类,框架层都可以自动处理好一切,并在这些类实例化的时候注入需要的属性。所有类可提供的实例都由类自身来维护,即使存在修改也不需要改动其他文件。
那么要达到这样的写法,要实现哪些东西呢?
1、前置知识装饰器
2、provider实现
3、inject实现
前置知识:装饰器
要使用装饰器解决上述提到的两个问题,我们需要先简单了解下Reflect Metadata
Reflect Metadata 是 ES7 的一个提案,它主要用来在声明的时候添加和读取元数据
根据 Reflect.defineMetadata 和 Reflect.getMetadata 进行元数据的定义和获取
import 'reflect-metadata';const CLASS_KEY = 'ioc:key';function ClassDecorator() {return function (target: any) {Reflect.defineMetadata(CLASS_KEY, {metaData: 'metaData',}, target);return target;};}@ClassDecorator()class D {constructor(){}}console.log(Reflect.getMetadata(CLASS_KEY, D)); // => { metaData: 'metaData' }
有了 Reflect,我们就可以对任意类进行标记,并对标记的类进行特殊的处理
npm i reflect-metadata --save在 tsconfig.json 里,emitDecoratorMetadata 需要配置为 true。
Provider
https://juejin.cn/post/6898882861277904910#heading-7
inject
https://juejin.cn/post/6898882861277904910#heading-8
一些有用的话
加深理解
依赖注入:DI, 控制反转:IoC
什么是依赖?
当 class A 使用 class B 的某些功能时,则表示 class A 具有 class B 依赖。
一些tips:
- 依赖注入是实现控制反转的方式之一
控制反转IoC
不是什么技术,而是一种设计思想
Ioc意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制
理解好Ioc的关键是要明确“谁控制谁,控制什么,为何是反转(有反转就应该有正转了),哪些方面反转了”
谁控制谁,控制什么:
传统Java SE程序设计,我们直接在对象A内部通过new进行创建对象B,是程序主动去创建依赖对象
而IoC是有专门一个容器来创建这些对象,即由Ioc容器来控制对象的创建;
谁控制谁?当然是IoC容器控制了对象;
控制什么?那就是主要控制了外部资源获取(不只是对象包括比如文件等)。
为何是反转,哪些方面反转了:有反转就有正转,
传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;
而反转则是由容器来帮忙创建及注入依赖对象;
为何是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取被反转了。
传统程序设计如图2-1,都是主动去创建相关对象然后再组合起来: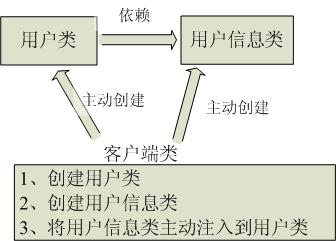
当有了IoC/DI的容器后,在客户端类中不再主动去创建这些对象了: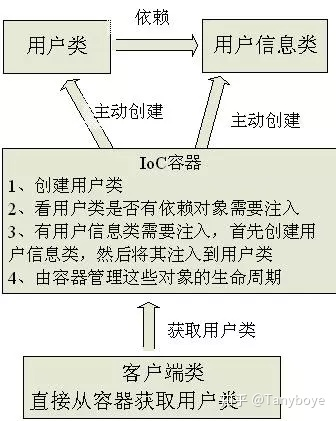
所以依赖注入实现需要:
1、容器injector
2、定义依赖
3、依赖对应的消费者
多层级 injector 系统. 也就是说, 每一个 injector 生成子 injectors. 如果子 injector 找不到依赖时,可以通过 parent injector 获取依赖
依赖注入的三个主要概念:
- 依赖RenderService: 一般某个类被别人需要了,就叫做是某个类的依赖,一般也称为服务service
- 容器injector: 用于向消费者注入依赖,“注入”是指将“依赖”传递给调用方的过程
- 消费者: 服务的消费者。消费者本身也可以是依赖
传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试
理解:其实就是 在传统的类之间创建类,又多了一层,就像eventbus一样,多了一个中转站
控制反转IoC(Inversion of Control)是说创建对象的控制权进行转移,以前创建对象的主动权和创建时机是由自己把控的,而现在这种权力转移到第三方,比如转移交给了IoC容器,它就是一个专门用来创建对象的工厂,你要什么对象,它就给你什么对象,有了 IoC容器,依赖关系就变了,原先的依赖关系就没了,它们都依赖IoC容器了,通过IoC容器来建立它们之间的关系。
有了IoC容器后,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,
所以对象与对象之间是 松散耦合,这样也方便测试,利于功能复用,
更重要的是使得程序的整个体系结构变得非常灵活。
IoC对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在IoC/DI思想中,应用程序就变成被动的了,被动的等待IoC容器来创建并注入它所需要的资源了
IoC很好的体现了面向对象设计法则之一—— 好莱坞法则:“别找我们,我们找你”;即由IoC容器帮对象找相应的依赖对象并注入,而不是由对象主动去找。
我的理解:
底层的被依赖者:只管我需要实现的接口,对外提供的接口
高层调用方:只管我需要接口,哪些接口会为我办什么事,具体谁实现的我不管
容器层:我来管理各自的类,由接口来链接上 调用方与实现方,分析出依赖关系后,从而将依赖给注入到调用方,调用方得以实现 调用其他类的方法的目的
所以有两个环节:
1、声明接口,声明依赖关系:
way1:provider的方式,直接在类上声明我需要xx类
way2:接口联系
2、容器:
管理类,每个类有自己的对应key,并实例化好
通过依赖关系,将依赖注入到调用方
引入依赖注入模式主要是为了:
- 在不同的使用场景,只需要顶层切换服务,底层代码无需改动
- 可以在生成的实例中保存状态
例如:多端环境、主题切换、光标状态的管理等
依赖注入DI与Ioc
DI—Dependency Injection,即“依赖注入”:组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。
通过依赖注入机制,
对于容器来说:只需通过简单的配置就可指定目标需要的资源(无需从下层修改代码,通过上层配置即可实现切换)
而对于控制器来说:不需要关心具体的资源来自何处,由谁实现,
对于业务层来说:专注完成自身的业务逻辑
理解DI的关键是:“谁依赖谁,为什么需要依赖,谁注入谁,注入了什么”
谁依赖于谁:当然是应用程序依赖于IoC容器;
●为什么需要依赖:应用程序需要IoC容器来提供对象需要的外部资源;
●谁注入谁:很明显是IoC容器注入应用程序某个对象,应用程序依赖的对象;
●注入了什么:就是注入某个对象所需要的外部资源(包括对象、资源、常量数据)。
举个例子:
所谓IoC,对于spring框架来说,就是由spring来负责控制对象的生命周期和对象间的关系
容器做的事:
所有的类都会在spring容器中登记,告诉spring你是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。
DI:
IoC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,依赖注入)来实现的。
面向接口编程原则
依赖倒转原则
设计模式的六大原则之一,其核心是面向接口编程
- 高层模块不应该依赖低层模块。两个都应该依赖抽象
- 抽象不应该依赖细节
- 细节应该依赖抽象意思是我们编程时,对系统进行模块化,两个模块之间有依赖,例如模块A依赖模块B,那么根据依赖倒转原则,我们开发时,模块A应该依赖模块B的接口,而不是依赖模块B的实现。
参考资料

若有收获,就点个赞吧
0 人点赞
