参考资料
廖雪峰sql教程
sqlzoo在线教程:sqlzoo/参考答案
更多练习题:
概览
1、sql对关键字不区分大小写
2、别名
-- as 作为别名FROM name as student_name from student;-- as 也可以省掉FROM name student_name from student;-- 表别名SELECT e.id,e.name FROM Employee e;
3、语法用法简单记录:
条件&限制:where , order by, case...when...分组:group by ...having,模糊查询:like关键字与通配符子查询:union、all、表连接查询:join、left (outer) join、 right (outer) join、cross join
—case when
[case ... when (condition)then xxxelse xxxend]select id,#对字段a进行赋值,如果当前满足when的条件 则a为1 否则a为0case when array_contains(id_courses, courses[0]) then 1 else 0 end as a,case when array_contains(id_courses, courses[1]) then 1 else 0 end as b,case when array_contains(id_courses, courses[2]) then 1 else 0 end as c,case when array_contains(id_courses, courses[3]) then 1 else 0 end as d,case when array_contains(id_courses, courses[4]) then 1 else 0 end as e,case when array_contains(id_courses, courses[5]) then 1 else 0 end as ffrom id_courses;
查询
查询可有:基本查询、条件查询、投影查询、聚合查询、多表查询、连接查询;
语法是:
select [all | distinct] select_expr, select_expr, ...from table_reference[where where_condition][group by col_list][order by col_list][cluster by col_list| [distribute by col_list] [sort by col_list]][limit [offset,] rows]
大致思路是从xx表里对表格的数据进行筛选、缩减、或者扩充连接,形成新的“表”,再在新的表上select我们关心的列出来形成结果表。
以下面两个表(部门表、员工表)为例子说明常见的查询:
基本查询:
SELECT * FROM Employee; 展示员工表所有列
条件查询
SELECT * FROM students WHERE sal >= 80;
条件查询灵魂在于条件判断表达式:
语法是where 条件; 多条条件通过and、or关联;表达式:=、>、<、<>、like等;
where .. between … and …; is null / is not null ; in/not in;exp: t.name in (‘haha’,’hehe’);
p.s.
having 针对分组数据进行筛选 Group By … Having ;exp:select e.deptno,avg(e.sal) avgsal from emp e group by e.deptno having avgsal>2000;
like 与 rlike
(1)like的内容 不是正则 ,而是通配符。
(2)rlike的内容可以是正则。
like即对应模糊查询,类似于开启字符串匹配;
| 通配符 | 描述 |
|---|---|
| % | 替代一个或多个字符 |
| _ | 仅替代一个字符 |
| [charlist] | 字符列中的任何单一字符 |
| [^charlist]或者[!charlist] | 不在字符列中的任何单一字符 |
把u_name为“张三”,“张猫三”、“三脚猫”,“唐三藏”等等有“三”的记录全找出来。SELECT * FROM [user] WHERE u_name LIKE '%三%'既有“三”又有“猫”的记录SELECT * FROM [user] WHERE u_name LIKE '%三%' AND u_name LIKE '%猫%'SELECT * FROM [user] WHERE u_name LIKE '_三_'只找出“唐三藏”这样u_name为三个字且中间一个字是“三”的;SELECT * FROM [user] WHERE u_name LIKE '[张李王]三'将找出“张三”、“李三”、“王三”(而不是“张李王三”);SELECT * FROM [user] WHERE u_name LIKE '[^张李王]三'将找出不姓“张”、“李”、“王”的“赵三”、“孙三”等;

concat函数 ,连接多个字符串,好处在于 concat里面的数是变量,变量可以是select 的字段 也可以是 通配符


==
投影查询
如果我们只希望返回某些列的数据,而不是所有列的数据,我们可以用SELECT 列1, 列2, 列3 FROM ...,让结果集仅包含指定列。这种操作称为投影查询。
SELECT id, score, name FROM students;
聚合查询
如果我们要统计一张表的数据量,例如,想查询students表一共有多少条记录,难道必须用SELECT * FROM students查出来然后再数一数有多少行吗?
对于统计总数、平均数这类计算,SQL提供了专门的聚合函数,使用聚合函数进行查询,就是聚合查询
SELECT COUNT() FROM students; `COUNT()`表示查询所有列的行数; count(*)=count(id)
除count外还提供 sum、avg、min、max等函数
聚合查询还有个重要的知识点—分组:
如果我们要统计一班的学生数量,我们知道,可以用SELECT COUNT(*) num FROM students WHERE class_id = 1;。如果要继续统计二班、三班的学生数量,难道必须不断修改WHERE条件来执行SELECT语句吗?
对于聚合查询,SQL还提供了“分组聚合”的功能
SELECT * FROM students;
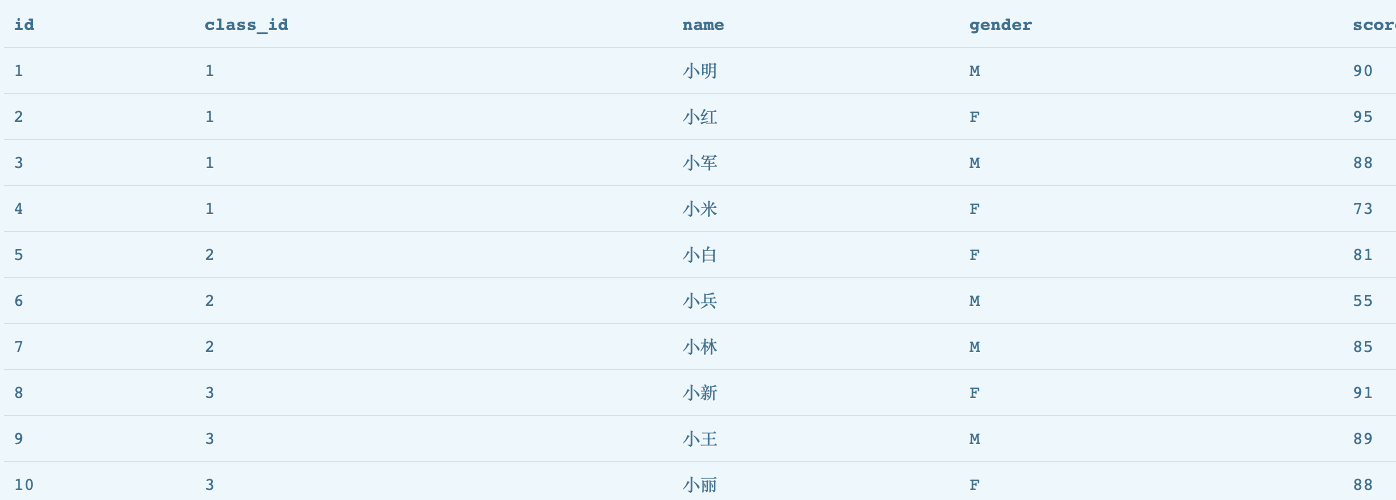
按照班级划分,每班多少人
SELECT class_id,count(class_id) FROM students group by class_id;

按照性别划分,统计男女各有多少人
SELECT gender,count(gender) FROM students group by gender;

分组group by的作用是对某个属性进行“桶计数的感觉”,找出该属性下有多少种类,显示出来,然后一般搭配聚合函数算出个数;
所以即使当我们 select * group by class_id; 展示的列也仅有 class_id;

分组更强大的地方在于,我们使用多列进行分组;
比如我们想统计各班男女人数
SELECT class_id, gender, COUNT(*) FROM students GROUP BY class_id, gender;
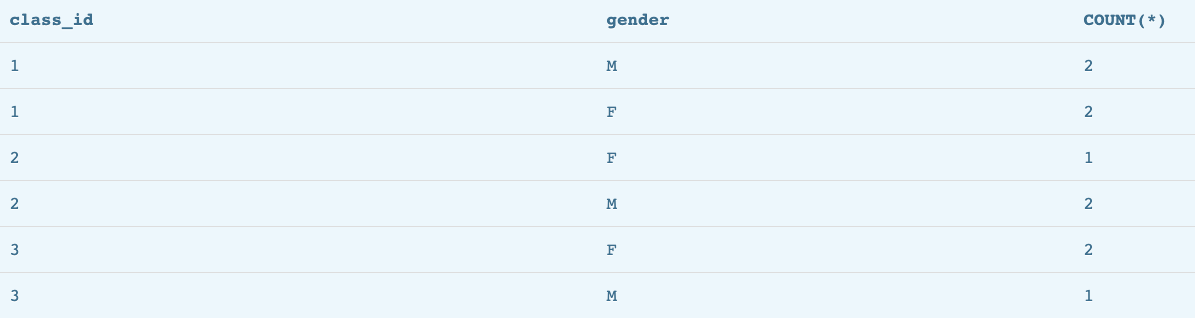
能展示的列还是遵循group by 什么属性就一定可以显示什么属性,同时再在显示的属性上进行聚合计算即可;
连接查询
连接查询是另一种类型的多表查询。连接查询对多个表进行JOIN运算,简单地说,就是先确定一个主表作为结果集,然后,把其他表的行有选择性地“连接”在主表结果集上。
从语法角度join分为
| join | 区别 |
|---|---|
| (inner) join | 内连接就是关联的两张或多张表中,根据关联条件,显示所有匹配的记录,匹配不上的,不显示 只连接双方都存在的情况 |
| left (outer) join | 显示左表的所有项,右表没有匹配的项,则以null显示 |
| right (outer) join | 显示右表的所有项,左表没有匹配的项,则以null显示 |
| full (outer) join | 显示所有匹配和不匹配的项,左右两张表没有匹配的,都以null显示 |
一图胜千言: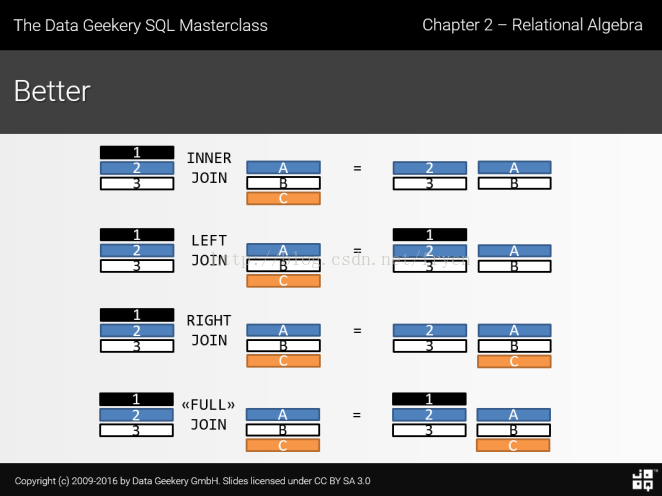
一般join是为了表的信息扩充,比如学生表(studenid,name)和成绩表(studenid,score)
他们通过studentid相连接,可以得到xxname的学生的考试成绩是多少;此类为不同表之间的连接
select * from student S left join score Cwhere S.studentid = C.studentid
此外也可以 自身连接,即自连接;
以外还有cross join用于生成两张表的笛卡尔集。
1、返回的记录数为两个表的记录数乘积。比如,A表有n条记录,B表有m条记录,则返回n*m条记录。
2、将A表的所有行分别与B表的所有行进行连接。
其实所有的连接都是从 cross join演化而来的;但是目前用的比较少这里不再细究;
子查询
对于支持子查询的数据库,Hibernate 支持在查询中使用子查询。一个子查询必须被圆括号包围起来(经常是 SQL 聚集函数的圆括号)。甚至相互关联的子查询(引用到外部查询中的别名的子查询)也是允许的。
大白话就是在sql形成的暂时表里再精简查询,表现为嵌套的视觉体现
如果子查询只有一个结果:
select * from Cat as fatcatwhere fatcat.weight >(select avg(cat.weight) from DomesticCat cat)
如果是多个,使用in关键字
列出与巴西、墨西哥相同洲的每个国家的名字和洲
SELECT name, continent FROM worldWHERE continent IN(SELECT continentFROM world WHERE name='Brazil'OR name='Mexico')
除了使用 > , < , >=,<=等比较符,还可以使用all、any来筛选
找出哪个国家的人口是高于欧洲每个国家的人口
SELECT name FROM worldWHERE population > ALL(SELECT population FROM worldWHERE continent='Europe')
union
用来合并多个select的查询结果,需要保证select中字段须一致
select_statement UNION ALL select_statement UNION ALL select_statement

若有收获,就点个赞吧
0 人点赞
