Boosting思想(提升法)
参考链接:https://zhuanlan.zhihu.com/p/103120540
通过将弱学习器提升为强学习器的集成方法来提高预测精度
AdaBoost

拟合样本之后,强化未被拟合的点的样本权重,进行第二次拟合,循环往复
梯度提升(GBDT)
全称Gradient Boosting Decision Tree,是 基于决策树 的,不用指定Base Estimator
XGboost
这个算法的 Base Estimator 是基于decision tree的
Xgboost是在 GBDT 的基础上进行改进,使之更强大,适用于更大范围
sklearn实现AdaBoosting和GBDT
06-AdaBoost-and-Gradient-Boosting.ipynb
投票分类法(Voting Classifier)
通过自助采样的方法生成众多并行式的分类器,通过“少数服从多数(投票)”的原则来确定最终的结果
假设每个子模型只有51%的准确率,你有3个子模型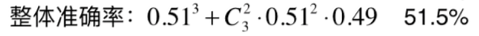
500个子模型的整体准确率: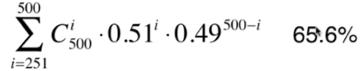
hard_voting_classifier
简单使用投票的方式
01-What-is-Ensemble-Learning.ipynb
soft_voting_classifier
计算所有分类器对不同标记种类可能预测的概率,不同分类器再把彼此相同的标记相加求平均,最后对比不同的标记的平均值。
02-Soft-Voting-Classifier.ipynb
Pasting思想
Bagging思想
参考链接:https://blog.csdn.net/weixin_41712808/article/details/109047487
放回采样,在统计学中叫做bootstrap可以生成无数个分类器,不依赖于随机。通常使用决策树,决策树子模型相对于参数学习子模型有更多的差异性,可以更多的调参。
测试数据集:OOB Out-Of-Bag
放回取样导致一部分样本很有可能没有取到,平均大约有37%的样本没有取到,所以可以不使用切分数据集,而是用这部分没有取到的样本做测试数据集
04-OOB-and-More-About-Bagging-Classifier.ipynb
随机森林(bagging实现)
一棵树是决策树,多棵树就是随机森林,随机森林解决了决策树泛化能力弱的缺点。随机森林的随机在它会随机选择样本随机选择特征,并且都是有放回的抽取过程。
bagging classifier超参数
并行计算”n_jobs=-1”
特征随机采样 “Random Subspaces”,sklearn使用:max_simple=500, max_features=1,bootstrap_features=True
特征和样本随机采样”Random Patches”,默认是样本随机采样max_simple=100, max_features=1,bootstrap_features=True
随即森林(sklearn实现)
Extra-Trees(sklearn实现)
使用随机的特征和随机阈值划分决策树的节点,而不是使用基尼系数。
非常随机,但是抑制了过拟合,增大了偏差,减小了方差。
训练速度快于普通决策树
05-Random-Forest-and-Extra-Trees.ipynb
stacking
https://www.bilibili.com/video/BV1si4y1G7Jb?from=search&seid=2891348212220691702

若有收获,就点个赞吧
0 人点赞
