关联规则挖掘可以让我们从数据集中发现项与项(item 与 item)之间的关系,它在我们的生活中有很多应用场景,“购物篮分析”就是一个常见的场景,这个场景可以从消费者交易记录中发掘商品与商品之间的关联关系,进而通过商品捆绑销售或者相关推荐的方式带来更多的销售量。所以说,关联规则挖掘是个非常有用的技术。
搞懂关联规则中的几个概念

支持度(Support)
支持度是个百分比,它指的是某个商品组合出现的次数与总次数之间的比例。
在这个例子中,我们能看到“牛奶”出现了 4 次,那么这 5 笔订单中“牛奶”的支持度就是:
同样“牛奶 + 面包”出现了 3 次,那么这 5 笔订单中“牛奶 + 面包”的支持度就是:
置信度(Confidience)
它指的就是当你购买了商品 A,会有多大的概率购买商品 B
置信度(牛奶→啤酒)=  ,代表如果你购买了牛奶,有多大的概率会购买啤酒?
,代表如果你购买了牛奶,有多大的概率会购买啤酒?
置信度(啤酒→牛奶)=  ,代表如果你购买了啤酒,有多大的概率会购买牛奶?
,代表如果你购买了啤酒,有多大的概率会购买牛奶?
置信度是个条件概念,就是说在 A 发生的情况下,B 发生的概率是多少。
提升度(lift)
我们在做商品推荐的时候,重点考虑的是提升度,因为提升度代表的是“商品 A 的出现,对商品 B 的出现概率提升的”程度。
就是买A的同时买B的概率比上B在总交易集合中出现的次数: 
这个公式是用来衡量 A 出现的情况下,是否会对 B 出现的概率有所提升。
所以提升度有三种可能:
提升度 (A→B)>1:代表有提升;
提升度 (A→B)=1:代表有没有提升,也没有下降;
提升度 (A→B)<1:代表有下降。
Apriori 的工作原理
美[əpriˈɔri]
因为过于消耗资源一般不在生产环境中使用,直接考虑FP-tree
首先我们把上面案例中的商品用 ID 来代表,牛奶、面包、尿布、可乐、啤酒、鸡蛋的商品 ID 分别设置为 1-6,上面的数据表可以变为:
Apriori 算法其实就是查找频繁项集 (frequent itemset) 的过程,所以首先我们需要定义什么是频繁项集。
频繁项集就是支持度大于等于最小支持度 (Min Support) 阈值的项集,所以小于最小值支持度的项目就是非频繁项集。
项集(itemset)这个概念,它可以是单个的商品,也可以是商品的组合。
我们再来看下这个例子,假设我随机指定最小支持度是 50%,也就是 0.5。
我们来看下 Apriori 算法是如何运算的:
超参数k:k=项数
首先,我们先计算单个商品的支持度,也就是得到 K=1 的支持度:
因为最小支持度是 0.5,所以你能看到商品 4、6 是不符合最小支持度的,不属于频繁项集,于是经过筛选商品的频繁项集就变成: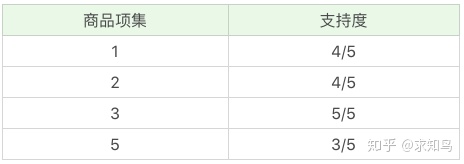
在这个基础上,我们将商品两两组合,得到 k=2 项的支持度:
我们再筛掉小于最小值支持度的商品组合,可以得到:
我们再将商品进行 K=3 项的商品组合,可以得到: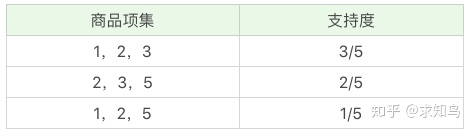
再筛掉小于最小值支持度的商品组合,可以得到:
通过上面这个过程,我们可以得到  项的频繁项集
项的频繁项集 ,也就是
,也就是 的组合。
的组合。
Apriori 算法的递归流程:
1、K=1,计算 K 项集的支持度;
2、筛选掉小于最小支持度的项集;
3、如果项集为空,则对应 K-1 项集的结果为最终结果。
否则 K=K+1,重复 1-3 步。
Apriori 的改进算法:FP-Growth 算法
Apriori 在计算的过程中有以下几个缺点:
1、可能产生大量的候选集。因为采用排列组合的方式,把可能的项集都组合出来了;
2、每次计算都需要重新扫描数据集,来计算每个项集的支持度。
图片体现该算法运算复杂度
五个item
所以 Apriori 算法会浪费很多计算空间和计算时间,为此人们提出了 FP-Growth 算法:
1、创建了一棵 FP 树来存储频繁项集。在创建前对不满足最小支持度的项进行删除,减少了存储空间。
2、整个生成过程只遍历数据集 2 次,大大减少了计算量。
所以在实际工作中,我们常用 FP-Growth 来做频繁项集的挖掘,下面我给你简述下 FP-Growth 的原理。
下方内容直接总结为止建议直接跳参考链接
创建项头表(item header table)
创建项头表的作用是为 FP 构建及频繁项集挖掘提供索引
这一步的流程是先扫描一遍数据集,对于满足最小支持度的单个项(K=1 项集)按照支持度从高到低进行排序,这个过程中删除了不满足最小支持度的项。(第一步遍历数据集就删除了不满足最小支持度的项,降低了时间复杂度;同时降序排列可以公用祖先节点–null点)
项头表包括了频繁一项集、一项集出现次数,以及该项在 FP 树中的链表。初始的时候链表为空。
下图支持度未除以总订单数量。只是表示一项集在商品组合中出现的次数。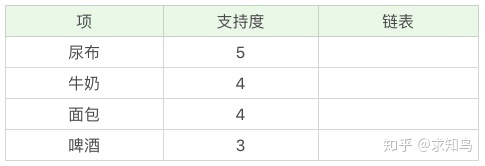
初始项头表正确形式:
| 尿布:5 | 链表 |
|---|---|
| 牛奶:4 | |
| 面包:4 | |
| 啤酒:3 |
构造 FP 树
FP 树的根节点记为 NULL 节点。
整个流程是需要再次扫描数据集,对于每一条数据,按照支持度从高到低的顺序进行创建节点(也就是第一步中项头表中的排序结果),如果有共用的祖先,则对应的公用祖先节点计数加1,如果不存在就进行创建。直到所有的数据都出现在FP树中。
同时在创建的过程中,需要更新项头表的链表
此处支持度未除以总订单数量。只是表示一项集在商品组合中出现的次数。
构建子树
1.假设已经完成创建项头表的工作,省略count+1
2.扫描数据集,按照项头表排列好的结果,一次创建节点
3.因为尿布出现在所有订单中,没有例外情况,所以这只有一个子节点
4.因为牛奶出现在尿布中的所有订单里,所以只有一个子节点
5.由表中数据可得,在出现牛奶的订单中,面包出现的情况,分为两种,
1)出现3次面包,出现在有牛奶的订单中
2)出现一次面包,出现在没有牛奶的订单中
故,生成两个子节点
6.后续内容属于迭代内容,自行体会
如果不懂,可以参考文末给的参考文献,那篇文章讲的很清楚(有点像运筹学图论,但比运筹学简单)
通过 条件模式基挖掘频繁项集
我们就得到了一个存储频繁项集的 FP 树,以及一个项头表。我们可以通过项头表来挖掘出每个频繁项集。
具体的操作会用到一个概念,叫“条件模式基”,它指的是以要挖掘的节点为叶子节点,自底向上求出 FP 子树,然后将 FP 子树的祖先节点设置为叶子节点之和。
原数据: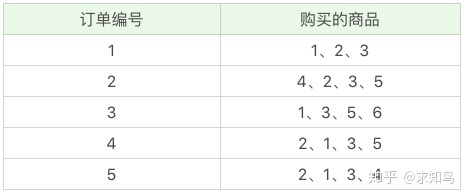
下图项头表的意思是根据支持度剔除后,种类3:后面表示总共出现了几次。
FP-Growth 算法总结:
1、构建项头表,从高到底排序(以便有共同祖节点)
2、对数据集按照项头表顺序进行排序,然后从高到低递归绘制层次图
3、按照项头表,依据第2步结果,从低到高,重新按照节点原则构建层次图,得到条件模式基。
总结
1、关联规则算法是最常用的算法,通常用于“购物篮分析”,做捆绑推荐。
2、Apriori 算法在实际工作中需要对数据集扫描多次,会消耗大量的计算时间
3、针对Apriori 算法时间复杂度高, FP-Growth 算法被提出来,通过 FP 树减少了频繁项集的存储以及计算时间。
4、原始模型往往是最接近人模拟的过程,但时间复杂度或空间复杂度高;于是人们就会提出新的方法,比如新型的数据结构,可以提高模型的计算速度。
5、FP Tree算法改进了Apriori算法的I/O瓶颈,巧妙的利用了树结构,这让我们想起了BIRCH聚类,BIRCH聚类也是巧妙的利用了树结构来提高算法运行速度。利用内存数据结构以空间换时间是常用的提高算法运行时间瓶颈的办法。
6、置信度和提升度是对频繁项集的一种验证,在筛选最优组合的时候,一般会设置最小支持度,最小置信度,这样频繁项集和关联关系都要满足这个条件。提升度 (A→B)= 置信度 (A→B)/ 支持度 (B),所以提升度是对满足前两者条件的另一种验证方式,这样避免一种情况:置信度(A->B)很高,是因为本身支持度(B)很高,实际上和A的出现关系不大。
参考文献:
数据分析实战45讲
FPTree不好理解,参考这篇文章,自己动手画画图就理解了
更多学习资料:
刘建平blog

若有收获,就点个赞吧
0 人点赞
