我们如何面对和理解机器学习,博文
数据科学学习网站,练数成金
机器学习简单介绍
什么是机器学习?首先我们要注意到的是,机器学习是一种区别于传统算法的一种机器的学习方式,它的运作原理类似于人类大脑的学习方式。当你喂给一个机器(算法)大量的数据样本的后,机器根据大量的样本从中学习到经验与特征。然后在内部建立一个模型,此时当你输入另外一个样本的时候,就可以预测出这个样本的其他数据。
人工智能 包含 机器学习 包含 深度学习(神经网络是深度学习的基础 )
机器学习别名:
模式识别,推理/估计(统计学)
机器学习系统的流程
原始数据——》数据预处理——》特征工程(变成向量,矩阵)——》建模——》预测
CRISP-DM模型 (跨行业数据挖掘标准流程)
商业理解,数据理解,数据准备,建立模型,模型评估,模型实施
数据的概述
from sklearn.datasets import load_irisimport pandas as pdimport numpy as npiris = load_iris()X = iris.dataX = np.append(X, iris.target).reshape(-1, 5) # 一维750行,变成二维,150行5列y = iris.feature_names # numpy没有append方法和insert方法,只有append函数y = np.append(y, 'target')df = pd.DataFrame(data=X, columns=y)df
输出结果如下: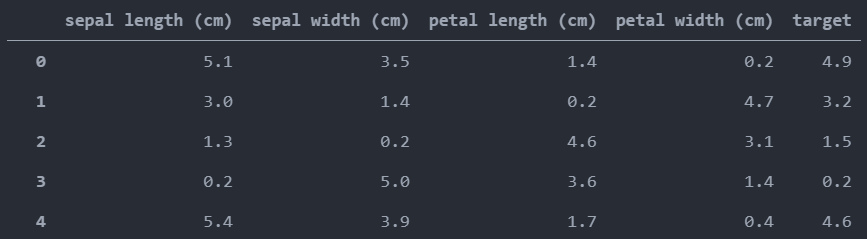
我们用鸢尾花实现一个数据集合的输出,数据整体被叫做数据集(data set),每一行数据称为一个样本(sample),除去最后一列的每一列可以称之为特征(feature),最后一列是标记/标签列(label)
顺便提一下矩阵和向量的关系,这个数据集就是一个矩阵,而向量可以是横的,也可以是竖的,通常我们都默认向量是竖的。
此时我们把除去标签列之后的得到的特征矩阵称之为 ,则
,则 的每一行可以称之为特征向量,用
的每一行可以称之为特征向量,用 表示,右上角的
表示,右上角的  表示第几个特征向量,比如 等于1时则是第1个特征向量,同理
表示第几个特征向量,比如 等于1时则是第1个特征向量,同理 则表示第
则表示第 个特征向量的第
个特征向量的第 个特征值。标记向量则可以用y表示,同理
个特征值。标记向量则可以用y表示,同理 表示第个标记值。
表示第个标记值。
如那么如上所述,为什么我们要把有由特征向量组成的数据集即称之为X,而标记向量称为y。
在数学上,为为了方便区分,我们通常把矩阵用大写字母表示,而向量用小写字母表示。同时我们知道,在数学中我们经常使用到自变量和因变量的概念,而自变量经常对应着x,因变量经常对应着y。如此而已。
- 特征空间是什么
由特征组成的空间,分类任务的本质就是在特征空间做切分,在理解分类问题的原理时我们是优先使用二维空间来进行可视化的绘图,随后可以推广至高维空间。
下图所示是一个二维的特征空间。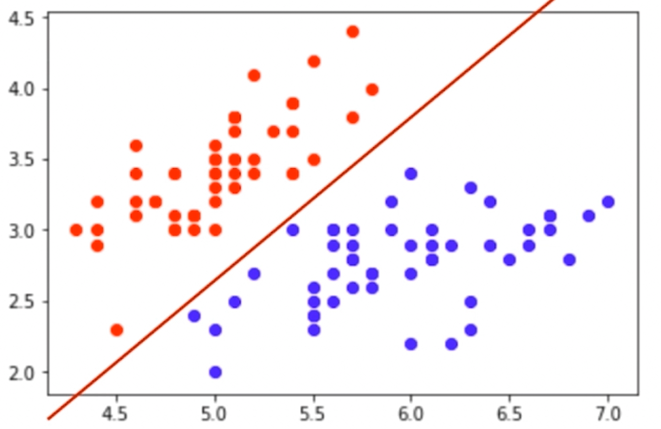
上图所示是一个二维的特征空间。
机器学习的分类
监督学习
- 监督学习(Supervised Learning)算法构建了包含输入和所需输出的一组数据的数学模型。这些数据称为训练数据,由一组训练样本组成
- 监督学习主要包括分类和回归。
- 当输出被限制为有限的一组值(离散数值)时使用分类算法;当输出可以具有范围内的任何数值(连续数值)时使用回归算法。
- 相似度学习是和回归和分类都密切相关的一类监督机器学习,它的目标是使用相似性函数从样本中学习,这个函数可以度量两个对象之间的相似度或关联度。它在排名、推荐系统、视觉识别跟踪、人脸识别等方面有很好的应用场景。
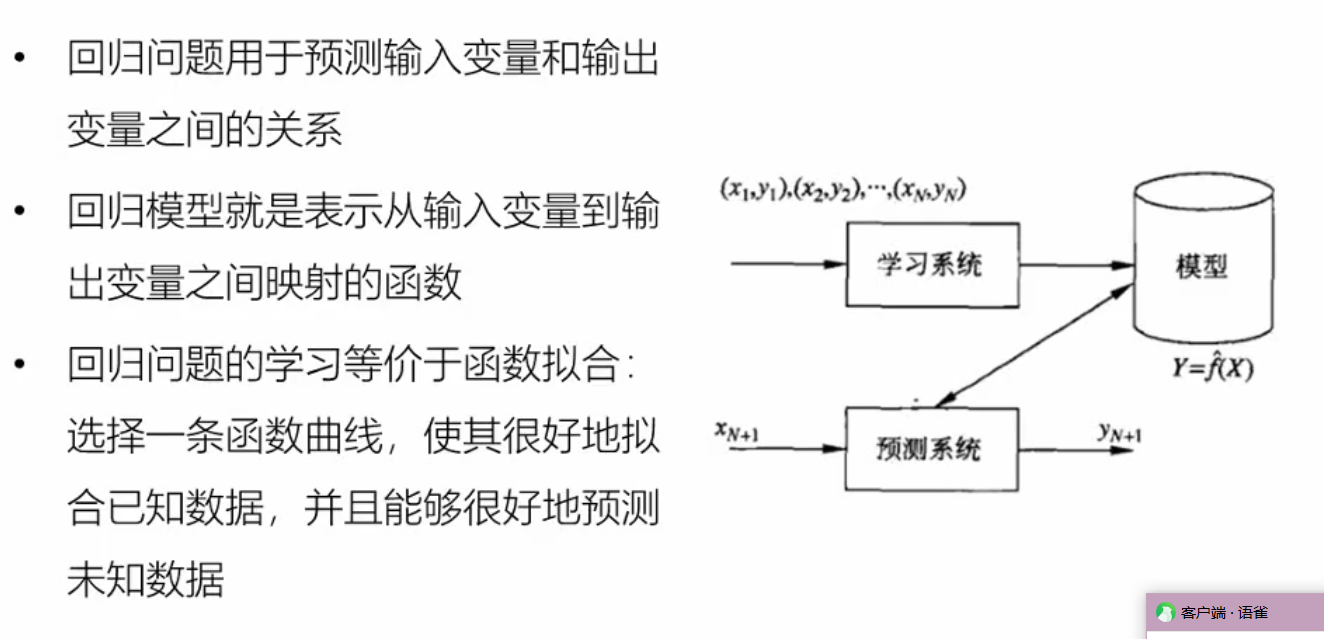
回归问题介绍·:
- 用于预测具体数值,标签是浮点数 ——即连续的
- 可以用于温度,股价,体重,身高预测
算法有线性回归、神经网络等
回归问题的分类
- 按照输入变量的个数:一元回归和多元回归
- 按照模型类型:线性回归和非线性回归
回归学习的损失函数——平方损失函数
- 如果选取平方损失函数作为损失函数,回归问题可以用著名的最小二乘法(least squares)来求解
分类问题介绍:
- 适用于预测分类的,标签是类别 ——离散的
比如男女判断,猫狗判断,垃圾邮件检测肿瘤,信用卡风险(二分类问题),人脸识别,车牌识别,语音识别,(多分类问题)
下图为房屋出售的二分类问题:
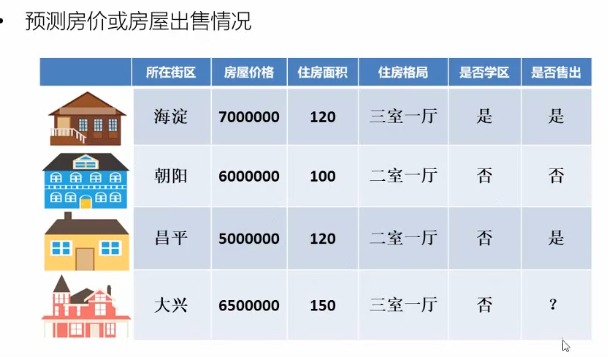
算法有逻辑回归,决策树,随机森林,神经网络,深度神经网络等

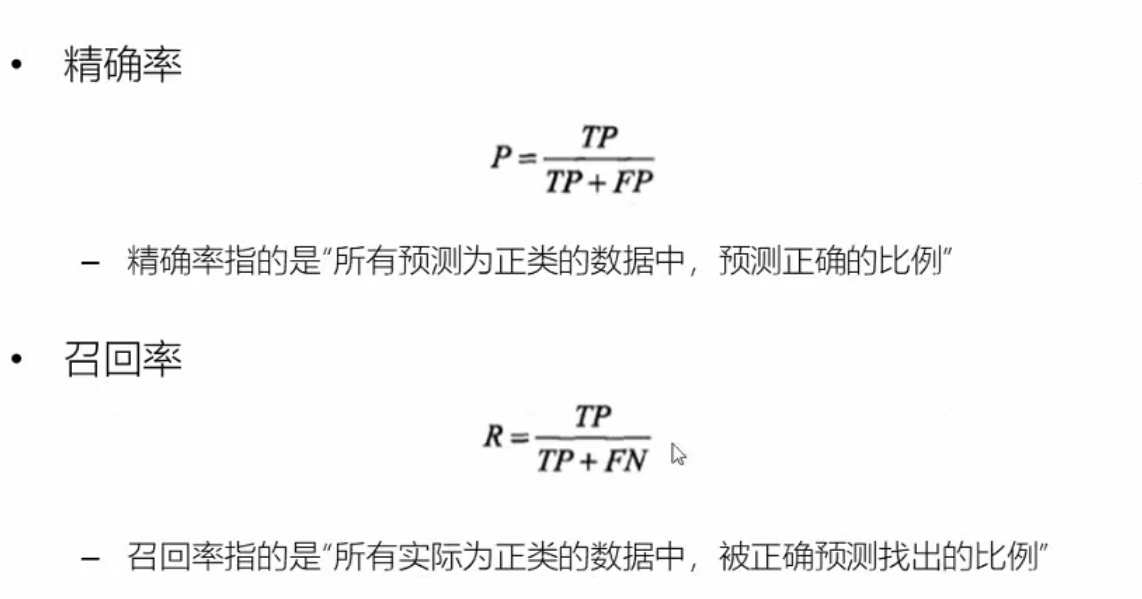
非监督学习:
- 无监督学习(Unsupervised Learning)算法采用一组仅包含输入的数据,通过寻找数据中的内在结构来进行样本点的分组或聚类。
- 算法从没有被标记或分类的测试数据中学习。
- 无监督学习算法不是响应反馈,而是要识别数据中的共性特征,对于一个新数据,可以通过判断其中是否存在这种特征,来做出相应的反馈。
- 无监督学习的核心应用是统计学中的密度估计和聚类分析。
简单来说非监督学习就是没有标记的学习 (建立模型)
应用:
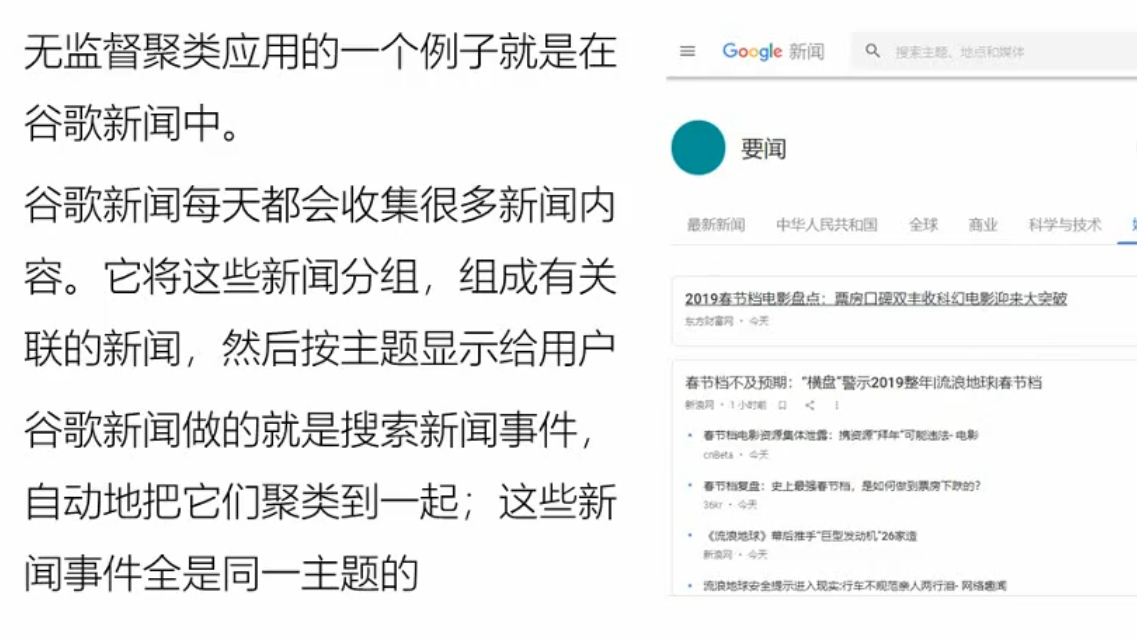
举例:
聚类分析:对没有标记的数据进行分类
降维处理:
特征提取:信用卡信用评级和人的胖瘦无关?
特征压缩:PCA(方便可视化操作)
异常检测:既找到离群点
算法:k均值(kmeans),高斯混合模型(GMM),LDA(文本模型)
半监督学习:
一部分数据有标记,一部分没有,此时我们通常都先使用无监督学习的手段,做对数据进行处理之后,用监督学习的手段做模型的训练与预测。
增强学习(强化学习):
动态模型,根据周围环境,采取行动,并就行动的结果给予惩罚或奖励(reward),但是没有确定标记
机器学习的其他分类
分类1:
- 在线学习(Onlinne Learning):再已有一个模型的情况下,此时输入一个样例并且预测出结果,因为在线学习环境变化的特殊性,所以当你预测出结果以后,你很快就能把你的结果与这个快速变化的环境产生出来的真实值进行比较,从而用来改进你原来的模型。那么缺点是你的模型,可能会因为输入错误的数据,也就是错误的真实值,而即时对模型产生影响,使之后的预测值变得不太准确。所以应对的方法就是得保证你数据的准确性。
批量学习(Batching Learning):又被叫做离线学习,攒一批样本资料,喂给机器进行学习,生成模型。然后这个模型就不变了,当进来一个新的样例的时候,它会根据这个模型来预测这个样例的标记。这种学习方式有个缺点就是环境发生改变时,你就需要跟据最新获得的一批数据,训练一个新的模型应对新的环境。而当你要重新训练这个模型的时候,它的所消耗的时间就会变得非常长。并且当环境的变化速度非常快的时候,批量学习就不适用了。
分类2:
参数学习(Parametric Learning):参数学习是喂给你的模型(函数)一堆数据去寻找这个模型的参数。在那之后你原来的数据就没有用了。
- 非参数学习(Nonparametric Learning):非参数学习不代表模型中没有参数,而是不去过多假设这个模型。你在预测时原来的数据也还是有用的。
机器学习概念
- 机器学习是什么
- 什么是学习
-从人的学习说起
-学习理论;从实践中总结经验
-在理论上推导;在实践中检验
-通过各种手段获取知识或技能的过程
- 机器怎么学习
-处理某个特定的任务,从大量的“经验”为基础
-对任务完成的好坏,给予一定的评判标准
-通过分析经验数据,任务完成的更好了
机器学习的开端

机器学习的定义

机器学习的过程
- 机器学习示例
监督学习深入理解
- 监督学习三要素
模型:总结数据的内在规律
策略:选取最优模型的评价标准
算法:选取最优模型的具体方法
-
模型评估
训练集和测试集
损失函数和经验函数

01损失函数,绝对值损失函数,平方损失函数

训练误差和测试误差

模型选择
过拟合和欠拟合


正则化和交叉验证
L1 = 绝对值求和
L2 = 平方求和开根号

监督学习模型求解算法

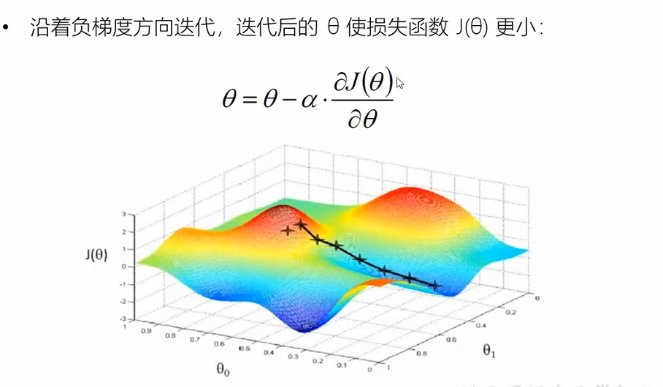
还有牛顿啥的没看
p10 24分左右

若有收获,就点个赞吧
0 人点赞
