我们在回归问题中最常使用的是R2的评价标准,而在分类问题中,最直观的就是准确度评分(accuracy score)
准确度评分的问题
假设现在有一个癌症预测系统,输入体检信息就可以判断是否有癌症,这个系统的预测准确度可以达到99.9%,试问这个系统怎么样?
如果这种癌症产生的概率只有0.1%,我们的系统甚至都不需要任何训练,只要预测所有的人都是健康的,正确率就能达到99.9%了。
上述情况属于极度偏斜的数据集(Skewed Data),所以光使用准确度评分是远远不够的。因此我们一个引入混淆矩阵的概念。
混淆矩阵 Confusion Maxtrix
二分类混淆矩阵(10000个样本)
negative:消极的,阴性(也就是不患病)
positive:积极的,阳性(也就是患病)
| 真实值 / 预测值 | 0(阴性:negative) | 1(阳性:positive) |
|---|---|---|
| 0(阴性:negative) | TN(TrueNegative)= 9978 | FP(FalsePositive)= 12 |
| 1(阳性:positive) | FN(FalsePositive)= 2 | TP(TruePositive)= 8 |
精准率和召回率的概念
精准率: ,带入上面的数据
,带入上面的数据 ,预测正确的1和所有预测为1的比例。分类为真,实际为假的越小越好。
,预测正确的1和所有预测为1的比例。分类为真,实际为假的越小越好。
召回率: ,带入上面的数据
,带入上面的数据 ,预测正确的1与真实存在的1的比例。分类为假实际为真的越小越好。
,预测正确的1与真实存在的1的比例。分类为假实际为真的越小越好。
自己实现混淆矩阵和精准召回率
sklearn实现混淆矩阵和精准召回率
'''混淆矩阵'''from sklearn.metrics import confusion_matrixconfusion_matrix(y_test,y_predict)'''精准率和召回率'''from sklearn.metrics import precision_scoreprecision_score(y_test,y_predict)from sklearn.metrics import recall_scorerecall_score(y_test,y_predict)
精准率与召回率的使用场景
预测股票的涨跌时(垃圾邮件),更多关注精准率。也就是预测上升的股票里上升了的比例,宁可漏掉上升的股票,不可买错上升的股票。
癌症的诊断上(信用违约),更多关注召回率。也就是真的有病的人有多少被预测到,宁可判断有病,不可判断没病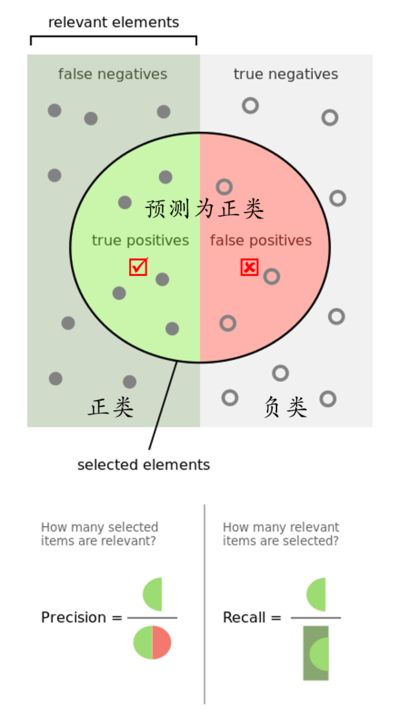
f1_score
兼顾精准率与召回率的指标
上述式子描述的是精准率和召回率的调和平均值,调和平均值描述的是数值的平衡程度,比如当precision和recall一个很大一个很小的时候,F1就会很小,当两个都很大的时候,F1才会大。F1_score的值域是[0,1]
sklearn实现f1_score
from sklearn.metrics import f1_scoref1_score(y_test, y_predict)
精准率和召回率提升及绘图
两者可能是矛盾的,用逻辑回归举例子,比如想要预测1的正确率提高,就得把概率更高的样本分类为1,而不是50%以上的就分类成1,这样有些真实的1就会被排除;想要召回率提高,就得把更低概率的癌症病人纳入样本1,但这样就会预测错误好多。
p10-5,使用desicision_score这个接口,改变判断分类标准的阈值,影响精准率和召回率,并且使用画图方式来得到进准率和召回率的关系。
### 10-6,快去复制
画图比较不同模型或不同参数相同模型的分类优秀度。
【图片待补充】
ROC曲线(Receiver Operation characteristic Curve)
统计学上常用的术语,描述的是TPR和FPR之间的关系
TPR(true positive rate) = Recall  ,预测为1,并且预测对了的数量占真实1值的rate
,预测为1,并且预测对了的数量占真实1值的rate
FPR (false positive rate) ,预测为1,并且预测错了的数量占真实0值的rate
,预测为1,并且预测错了的数量占真实0值的rate
### 10-7 绘制roc
roc曲线我们看的是曲线下面的面积的大小,面积越大越好(围成的面积叫做AUC),也就是说,在FPR越小的时候,TPR能够达到更高的值。

若有收获,就点个赞吧
0 人点赞
