String是 JavaScript 的原生对象,同时也是一个构造函数,可以用它生成新的字符串。
静态方法
就是直接定义在String对象的方法。
直接定义在构造函数上的方法和属性是静态的, 定义在构造函数的原型和实例上的方法和属性是非静态的(实例方法)。
String.print = function (o) { console.log(o) };//创建静态方法String.print("hello world"); //String原生对象直接使用静态方法
实例方法
所谓实例方法就是定义在String的原型对象String.prototype上的方法。它可以被String实例直接使用。
String.prototype.print = function () {console.log("hello world");};//创建实例方法var obj = new String();//新建实例obj.print() //obj实例直接使用实例方法
操作方法
toString() 『转换为字符串』
const a = 12console.log(a.toString()) // '12'
concat()『合并字符串』
concat() ,用于将一个 或多个字符串拼接成一个新字符串。
且多数情况下,对于拼接多个字符串来说, 使用加号更方便。
ECMAScript提供了3个从字符串中提取子字符串的方法: slice() 、 substr() 和 substring() 。
slice() 提取子字符串
slice() 方法可提取字符串的某个部分,并以新的字符串返回被提取的部分
slice() 比 substring() 要灵活一些,因为它允许使用负数作为参数。
slice() 可接收两个参数
- 字符串开始的位置
- 字符串结束的位置 ```javascript const a = ‘hello world’ console.log(a.slice(2)) // llo world console.log(a.slice(2, 5)) // llo
<a name="w5iOa"></a>### substr() 提取子字符串substr() 方法可在字符串中抽取从 start 下标开始的指定数目的字符。(不建议使用)substr()可接收两个参数- 字符串开始的位置- 截取长度```javascriptconst a = 'hello world'console.log(a.substr(3)) // hello worldconsole.log(a.substr(3, 7)) // lo worl
substring() 提取子字符串
substring() 方法用于提取字符串中介于两个指定下标之间的字符。
substring() 可接收两个参数
- 字符串开始的位置
- 字符串结束的位置
const a = 'hello world'console.log(a.substring(2)) // llo worldconsole.log(a.substring(2, 5)) // llo
replace()『替换操作』
为简化子字符串替换操作,ECMAScript提供了 replace() 方法。这 个方法接收两个参数,第一个参数可以是一个 RegExp 对象或一个字 符串(这个字符串不会转换为正则表达式),第二个参数可以是一个字 符串或一个函数。如果第一个参数是字符串,那么只会替换第一个子字 符串。要想替换所有子字符串,第一个参数必须为正则表达式并且带全 局标记
在这个例子中,字符串 “at” 先传给 replace() 函数,而替换文本 是 “ond” 。结果是 “cat” 被修改为 “cond” ,而字符串的剩余部分 保持不变。通过将第一个参数改为带全局标记的正则表达式,字符串中 的所有 “at” 都被替换成了 “ond” 。 第二个参数是字符串的情况下,有几个特殊的字符序列,可以用来插入 正则表达式操作的值。ECMA-262中规定了下表中的值。let text = "cat, bat, sat, fat";let result = text.replace("at","ond");console.log(result); // "cond, bat, sat, fat"result = text.replace(/at/g,"ond");console.log(result); // "cond, bond, sond, fond"
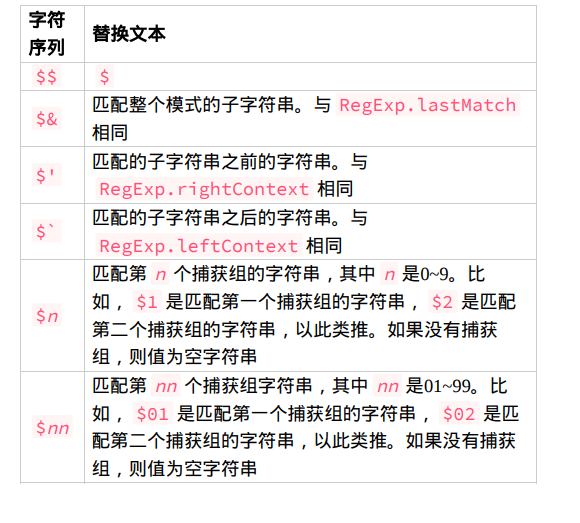
使用这些特殊的序列,可以在替换文本中使用之前匹配的内容,如下面 的例子所示:
let text = "cat, bat, sat, fat";result = text.replace(/(.at)/g,"word ($1)");console.log(result); // word (cat), word (bat),word (sat), word (fat)
这里,每个以 “at” 结尾的词都会被替换成 “word” 后跟一对小括 号,其中包含捕获组匹配的内容 $1 。 replace() 的第二个参数可以是一个函数。在只有一个匹配项时, 这个函数会收到3个参数:与整个模式匹配的字符串、匹配项在字符串 中的开始位置,以及整个字符串。在有多个捕获组的情况下,每个匹配 捕获组的字符串也会作为参数传给这个函数,但最后两个参数还是与整 个模式匹配的开始位置和原始字符串。这个函数应该返回一个字符串, 表示应该把匹配项替换成什么。使用函数作为第二个参数可以更细致地 控制替换过程,如下所示:
function htmlEscape(text) {return text.replace(/[<>"&]/g, function(match,pos, originalText) {switch (match) {case "<":return "<";case ">":return ">";case "&":return "&";case "\"":return """;}});}console.log(htmlEscape("<p class=\"greeting\">Hello world!</p>"));// "<p class="greeting">Helloworld!</p>"
这里,函数 htmlEscape() 用于将一段HTML中的4个字符替换成对 应的实体:小于号、大于号、和号,还有双引号(都必须经过转义)。 实现这个任务最简单的办法就是用一个正则表达式查找这些字符,然后 定义一个函数,根据匹配的每个字符分别返回特定的HTML实体。 最后一个与模式匹配相关的字符串方法是 split() 。这个方法会根据 传入的分隔符将字符串拆分成数组。作为分隔符的参数可以是字符串, 也可以是 RegExp 对象。(字符串分隔符不会被这个方法当成正则表 达式。)还可以传入第二个参数,即数组大小,确保返回的数组不会超 过指定大小。来看下面的例子:
在这里,字符串 colorText 是一个逗号分隔的颜色名称符串。调用 split(“ , “) 会得到包含这些颜色名的数组,基于逗号进行拆分。要 把数组元素限制为2个,传入第二个参数2即可。最后,使用正则表达式 可以得到一个包含逗号的数组。注意在最后一次调用 split() 时,返 回的数组前后包含两个空字符串。这是因为正则表达式指定的分隔符出 现在了字符串开头( “red” )和末尾( “yellow” )。
replaceAll 『替换全部操作』
看到replaceAll这个词,相比很容易联想到replace。在JavaScript中,replace方法只能是替换字符串中匹配到的第一个实例字符,而不能进行全局多项匹配替换,唯一的办法是通过正则表达式进行相关规则匹配替换
而replaceAll则是返回一个全新的字符串,所有符合匹配规则的字符都将被替换掉,替换规则可以是字符串或者正则表达式。
let string = 'I like 前端,I like 前端公虾米'//使用replacelet replaceStr = string.replace('like','love')console.log(replaceStr) // 'I love 前端,I like 前端公虾米'//replace使用正则匹配所有console.log(string.replace(/like/g,'love')) // 'I love 前端,I love 前端公虾米'//使用replaceAlllet replaceAllStr = string.replaceAll('like','love')console.log(replaceAllStr) // 'I love 前端,I love 前端公虾米'
需要注意的是,replaceAll在使用正则表达式的时候,如果非全局匹配(/g),则replaceAll()会抛出一个异常
let string = 'I like 前端,I like 前端公虾米'console.log(string.replaceAll(/like/,'love')) //TypeError
split()『字符串分割为数组』
trim()『去除空白符』
ECMAScript在所有字符串上都提供了 trim() 方法。这个方法会创建 字符串的一个副本,删除前、后所有空格符,再返回结果。
由于 trim() 返回的是字符串的副本,因此原始字符串不受影响,即 原本的前、后空格符都会保留。 另外, trimeLeft() 和 trimRight() 方法分别用于从字符串开始 和末尾清理空格符。
trimStart() 『去除前面空白』
trimEnd() 『去除后面空白』
位置方法『查询字符串』
charAt() 返回指定位置的字符
charAt() 方法可返回指定位置的字符。
示例:获取今天是星期几
var date="今天是星期"+"天一二三四五六".charAt(new Date().getDay());console.log(date)
有两个方法用于在字符串中定位子字符串: indexOf() 和 lastIndexOf() 。这两个方法从字符串中搜索传入的字符串,并返 回位置(如果没找到,则返回 -1 )。两者的区别在于, indexOf() 方法从字符串开头开始查找子字符串,而 lastIndexOf() 方法从字符串末尾开始查找子字符串。
at() 返回指定位置的字符 ES6
ES5 对字符串对象提供charAt方法,返回字符串给定位置的字符。该方法不能识别码点大于0xFFFF的字符。
'abc'.charAt(0) // "a"'𠮷'.charAt(0) // "\uD842"
上面代码中的第二条语句,charAt方法期望返回的是用2个字节表示的字符,但汉字“𠮷”占用了4个字节,charAt(0)表示获取这4个字节中的前2个字节,很显然,这是无法正常显示的。
字符串实例的at方法,可以识别 Unicode 编号大于0xFFFF的字符,返回正确的字符。
'abc'.at(0) // "a"'𠮷'.at(0) // "𠮷"
charCodeAt() 返回指定位置的字符的 Unicode 编码。
charCodeAt() 方法可返回指定位置的字符的 Unicode 编码。
codePointAt() 返回指定位置的字符的 Unicode 编码 ES6
JavaScript 内部,字符以 UTF-16 的格式储存,每个字符固定为2个字节。对于那些需要4个字节储存的字符(Unicode 码点大于0xFFFF的字符),JavaScript 会认为它们是两个字符。
var s = "𠮷";s.length // 2s.charAt(0) // ''s.charAt(1) // ''s.charCodeAt(0) // 55362s.charCodeAt(1) // 57271
ES6 提供了codePointAt方法,能够正确处理 4 个字节储存的字符,返回一个字符的码点。
let s = '𠮷a';s.codePointAt(0) // 134071s.codePointAt(1) // 57271s.codePointAt(2) // 97
codePointAt方法的参数,是字符在字符串中的位置(从 0 开始)。上面代码中,JavaScript 将“𠮷a”视为三个字符,codePointAt 方法在第一个字符上,正确地识别了“𠮷”,返回了它的十进制码点 134071(即十六进制的20BB7)。在第二个字符(即“𠮷”的后两个字节)和第三个字符“a”上,codePointAt方法的结果与charCodeAt方法相同。
总之,codePointAt方法会正确返回 32 位的 UTF-16 字符的码点。对于那些两个字节储存的常规字符,它的返回结果与charCodeAt方法相同。
codePointAt方法返回的是码点的十进制值,如果想要十六进制的值,可以使用toString方法转换一下。
let s = '𠮷a';s.codePointAt(0).toString(16) // "20bb7"s.codePointAt(2).toString(16) // "61"
你可能注意到了,codePointAt方法的参数,仍然是不正确的。比如,上面代码中,字符a在字符串s的正确位置序号应该是 1,但是必须向codePointAt方法传入 2。解决这个问题的一个办法是使用for…of循环,因为它会正确识别 32 位的 UTF-16 字符。
let s = '𠮷a';for (let ch of s) {console.log(ch.codePointAt(0).toString(16));}// 20bb7// 61
codePointAt方法是测试一个字符由两个字节还是由四个字节组成的最简单方法。
function is32Bit(c) {return c.codePointAt(0) > 0xFFFF;}is32Bit("𠮷") // trueis32Bit("a") // false
indexOf() 『第一次出现』
indexOf()返回指定字符在字符串中首次出现的位置(从前往后搜索)如果要检索的字符串值没有出现,则该方法返回 -1。
lastIndexOf()『最后出现』
lastIndexOf() 方法可返回一个指定的字符串值最后出现的位置(在一个字符串中的指定位置从后向前搜索)如果要检索的字符串值没有出现,则该方法返回 -1。
match『正则匹配』
match() 方法可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配。该方法类似 indexOf() 和 lastIndexOf(),但是它返回指定的值,而不是字符串的位置。
match() 方法,这个方法本质上跟 RegExp 对象的 exec() 方法相同。 match() 方法接收一个参数,可以是一个正则表达式字符串,也可以是一个 RegExp 对象。
let text = "cat, bat, sat, fat";let pattern = /.at/;// 等价于pattern.exec(text)let matches = text.match(pattern); // ["cat", index: 0, input: "cat, bat, sat, fat"]console.log(matches.index); // 0console.log(matches[0]); // "cat"console.log(pattern.lastIndex); // 0
match() 方法返回的数组与 RegExp 对象的 exec() 方法返回的数 组是一样的:第一个元素是与整个模式匹配的字符串,其余元素则是与 表达式中的捕获组匹配的字符串(如果有的话)。
search() 『正则匹配』
search() 方法用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串。返回字符串中第一个与 regexp 相匹配的子串的起始位置,没有找到返回-1。
这个方法唯一的参数与 match() 方法一样:正则表达式字符串或 RegExp 对象。这个方法 返回模式第一个匹配的位置索引,如果没找到则返回-1。 search() 始终从字符串开头向后匹配模式。
let text = "cat, bat, sat, fat";let pos = text.search(/at/);console.log(pos); // 1
这里, search(/at/) 返回 1 ,即 “at” 的第一个字符在字符串中 的位置。
包含方法
传统上,JavaScript 有indexOf方法,可以用来确定一个字符串是否包含在另一个字符串中。ES6 又提供了三种新方法。
- includes():返回布尔值,表示是否找到了参数字符串。
- startsWith():返回布尔值,表示参数字符串是否在原字符串的头部。
- endsWith():返回布尔值,表示参数字符串是否在原字符串的尾部。
这些方法 都会从字符串中搜索传入的字符串,并返回一个表示是否包含的布尔值。它们的区别在于, startsWith() 检查开始于索引0的匹配项, endsWith() 检查开始于索引 (string.length - substring.length) 的匹配项,而 includes() 检查整个字符串:
let message = "foobarbaz";console.log(message.startsWith("foo")); // trueconsole.log(message.startsWith("bar")); // falseconsole.log(message.endsWith("baz")); // trueconsole.log(message.endsWith("bar")); // falseconsole.log(message.includes("bar")); // trueconsole.log(message.includes("qux")); // false
startsWith() 和 includes()
startsWith() 和 includes() 方法接收可选的第二个参数,表示开始搜索的位置。如果传入第二个参数,则意味着这两个方法会从指定位置向着字符串末尾搜索,忽略该位置之前的所有字符。下面是一个例 子:
let message = "foobarbaz";console.log(message.startsWith("foo")); //trueconsole.log(message.startsWith("foo", 1)); //falseconsole.log(message.includes("bar")); //trueconsole.log(message.includes("bar", 4)); //false
endsWith()
endsWith() 方法接收可选的第二个参数,表示应该当作字符串末尾的位置。如果不提供这个参数,那么默认就是字符串长度。如果提供这 个参数,那么就好像字符串只有那么多字符一样:
let message = "foobarbaz";console.log(message.endsWith("bar")); //falseconsole.log(message.endsWith("bar", 6)); // true
大小写转换
包括4个方法: toLowerCase() 、 toLocaleLowerCase() 、 toUpperCase() 和 toLocaleUpperCase() 。
复制和填充方法
repeat() 『多次复制并拼接字符串』
ECMAScript在所有字符串上都提供了 repeat() 方法。这个方法接收 一个整数参数,表示要将字符串复制多少次,然后返回拼接所有副本后 的结果。
padStart()、padEnd()『填充字符串到指定长度』
ES8提供了新的字符串填充方法,该方法可以使得字符串达到固定长度。它有两个参数,字符串目标长度和填充内容。
padStart() 和 padEnd() 方法会复制字符串,如果小于指定长 度,则在相应一边填充字符,直至满足长度条件。这两个方法的第一个 参数是长度,第二个参数是可选的填充字符串,默认为空格 (U+0020)。
'react'.padStart(10, 'm') //'mmmmmreact''react'.padEnd(10, 'm') //' reactmmmmm''react'.padStart(3, 'm') // "react"

若有收获,就点个赞吧
0 人点赞
