二叉树
性质
【二叉树】是有序树(有左右之分);一颗二叉树的度可以小于2
【完全二叉树】层次遍历,中间没有NULL结点
【满二叉树】
- 判断是否为完全二叉树,并获得总结点数n
- 结点的总数n和高度h关系:
—> 判断n+1是不是2的次方 | 性质 | 说明 | | —- | —- | |
|

[推广] 度为m的树*nm#card=math&code=n_0%3D1%2B1%2An_2%2B2%2An_3%2B…%2B%28m-1%29%2An_m&id=En0n6) | |
| 第i层上最多
(i≥1)个结点 | |
| 高度(深度)为k,最多有
个结点
(即满二叉树前k层结点个数) | | 结点编号 | |
| #card=math&code=C_%7B2n%7D%5En%2F%28n%2B1%29&id=Wtlks) | n个结点的二叉树一共有h(n)种可能 |
| 完全二叉树高度深度h |
|
| #card=math&code=C_%7B2n%7D%5En%2F%28n%2B1%29&id=Wtlks) | n个结点的二叉树一共有h(n)种可能 |
| 完全二叉树高度深度h | %7D%5Crceil#card=math&code=h%3D%5Clfloor%7Blog_2n%7D%5Crfloor%2B1%3D%5Clceil%7Blog_2%28n%2B1%29%7D%5Crceil&id=WgCix) |
存储结构
| 存储结构 | 图解 | 定义 |
|---|---|---|
| 顺序存储结构 | 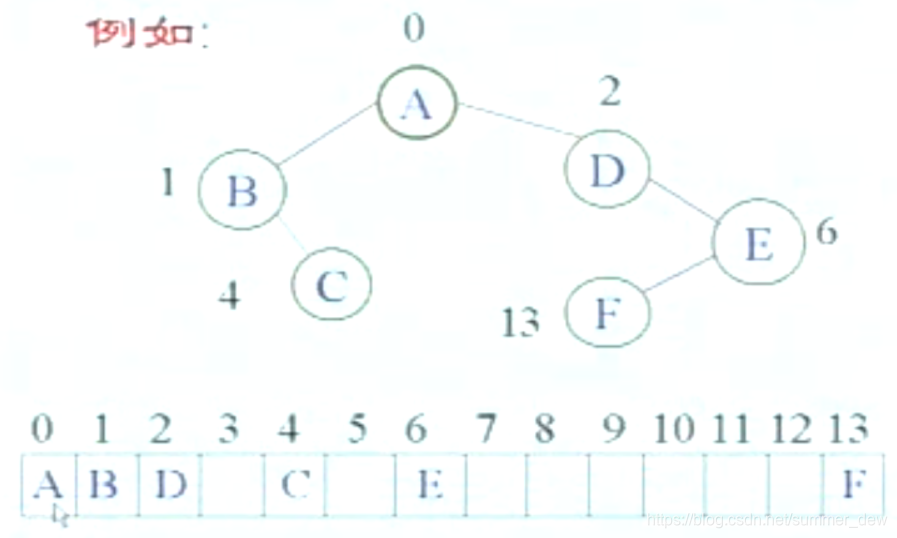 |
char BTree[]; |
| 二叉链表 | 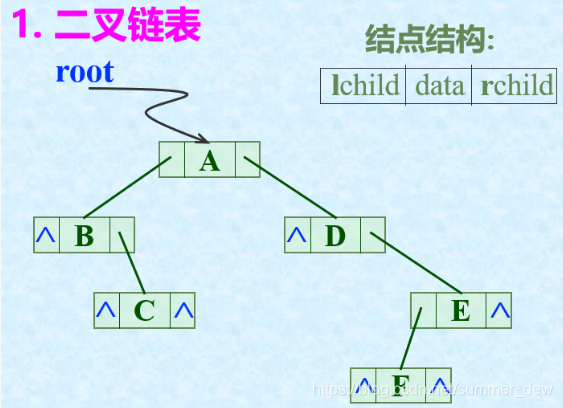 |
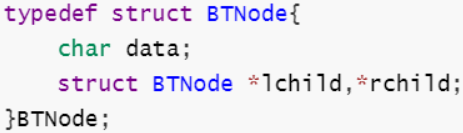 |
| 三叉链表 | 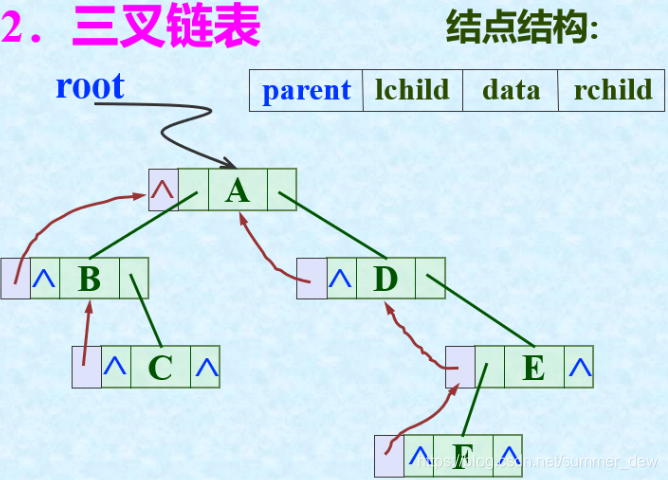 |
 |
| 双亲链表 | 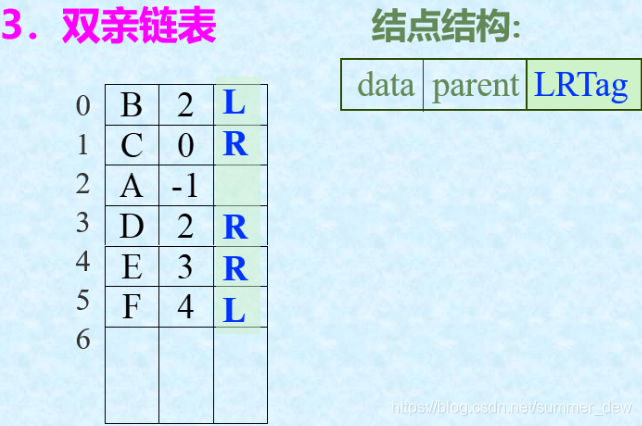 |
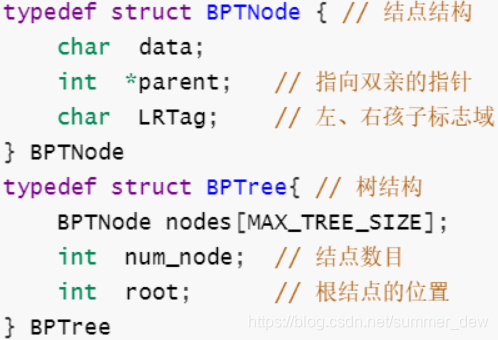 |
遍历
【遍历】实质上是对一个非线性结构线性化操作,使每个结点(除第一个和最后一个外)在这些线性序列中有且仅有一个直接前驱和直接后继
遍历方法对比
| 方法对比 | 递归遍历 | 非递归遍历 | 线索二叉树 |
|---|---|---|---|
| 介绍 | 使用系统栈 | 使用用户定义的栈 | 充分利用空链域(n+1个),但添加了ltag和rtag(空间的开销对比要看具体的情况) |
| 对比 | 系统栈是一个所有递归函数都通用的栈除了记录访问过的结点信息之外,还有其他信息需要记录 | 仅保存了遍历所需的结点信息,是专业用在二叉树遍历的场景中的 | 二叉树被线索化后近似于一个线性结构,分支结构的遍历操作就转化为了近似于线性结构的遍历操作,通过线索的辅助使得寻找当前结点前驱或者后继的平均效率大大提高 |
递归与非递归
- 【时间复杂度】O(n)
遍历二叉树的算法中的基本操作是访问结点,则不论按哪一种次序进行遍历,对含n个结点的二叉树,其时间复杂度:O(n) - 【空间复杂度】
所需辅助空间为遍历过程中栈的最大容量,即树的深度,最坏情况下为n,则空间复杂度:O(n)
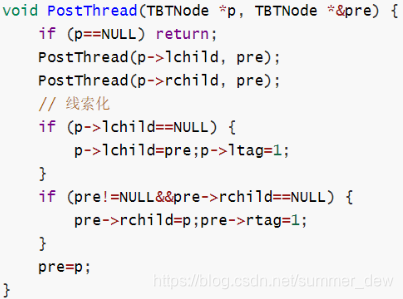
【理解遍历】将二叉树线索化时,一个节点会遇到三次
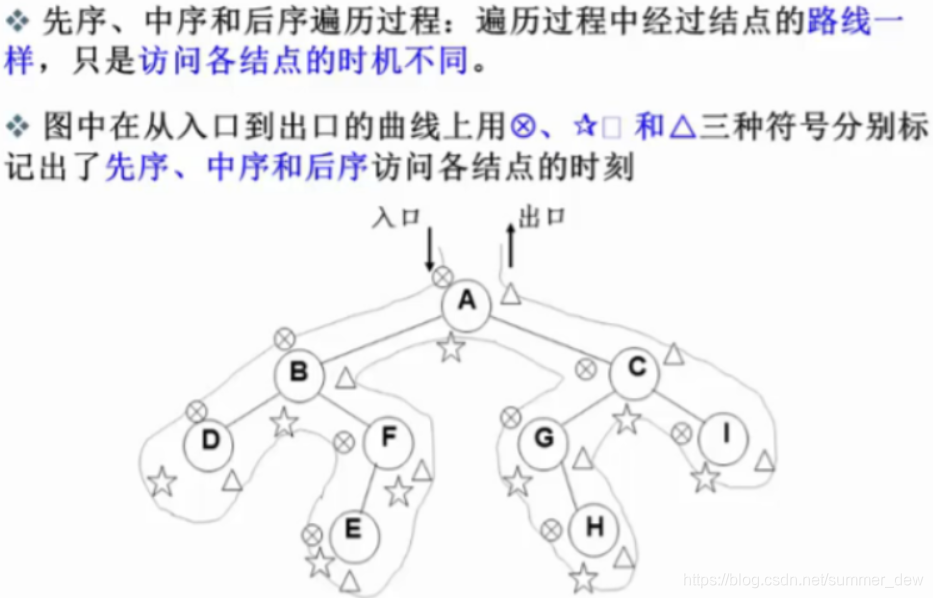
| 遍历 | 递归 | 非递归 |
|---|---|---|
| 先序(根左右) |  |
 |
| 中序(左根右) |  |
 |
| 后序(左右根) |  |
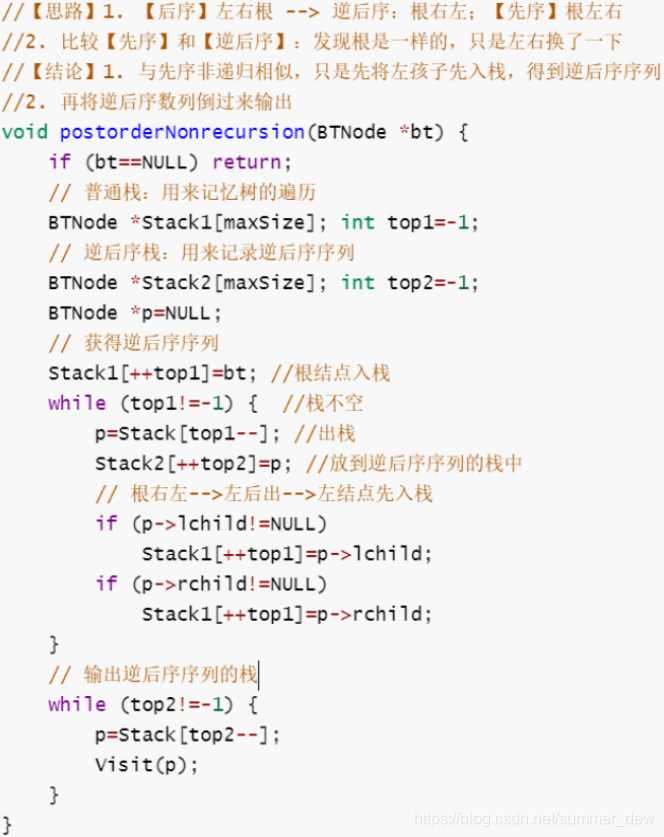 |
| 层次遍历 |  |
线索二叉树
【线索化】对一颗二叉树中所有结点的空指针域按照某种遍历方式加线索的过程
【线索二叉树】被线索化了的二叉树为线索二叉树
【效率】在中序线索二叉树上遍历二叉树,虽然时间复杂度亦为O(n),但常数因子要比上节讨论的算法小
【类别】
- 按遍历顺序分:先序、中序、后序
- 按lchild、rchild谁用来作为线索:全线索化、左线索化、右线索化
| | 中序线索二叉树 | 前序线索二叉树 | 后序线索二叉树 | | —- | —- | —- | —- | | 线索化 |typedef struct TBTNode{char data;int ltag,rtag; //线索标记:是否为线索(1是,0不是)struct TBTNode *lchild,*rchild;}TBTNode;
 |
|  |
|  |
| 创建 |
|
| 创建 |  | | |
| 第一个 |
| | |
| 第一个 | 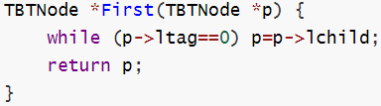 | | |
| 最后一个 |
| | |
| 最后一个 | 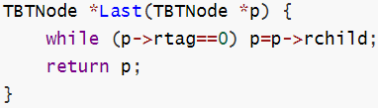 | | |
| 前一个 |
| | |
| 前一个 |  | | |
| 后一个 |
| | |
| 后一个 |  | | 1. 结点x是二叉树的根,则其后继为空
| | 1. 结点x是二叉树的根,则其后继为空
2. 结点x是其爸爸的右孩子,或是其双亲的左孩子且其双亲没有右子树,则其后继即为双亲结点
3. 若结点x是其双亲的左孩子,且其双亲有右子树,则其后继为双亲右子树上按后序遍历列出的第一个结点 | | 遍历 | |
|  | |
| |
树
性质
【树的分类】有序树;无序树
【丰满树】即理想平衡树,要求除最底层外,其他层都是满的(完全二叉树的扩展)
【性质】度为m的树:*n_m#card=math&code=n_0%3D1%2B1%2An_2%2B2%2An_3%2B…%2B%28m-1%29%2An_m&id=UzHM9)
存储结构
| 存储结构 | 图解 | 定义 | 评价 |
|---|---|---|---|
| 双亲表示法 | 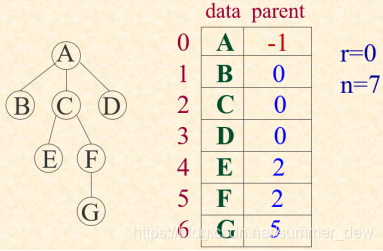 |
 |
找双亲O(1);找根O(h);找孩子O(n) |
| 孩子表示法 | 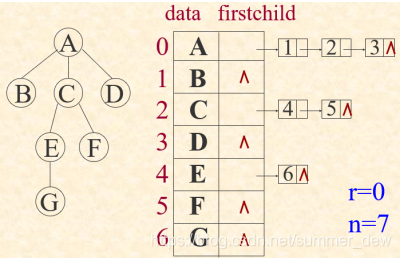 |
 |
|
| 双亲孩子表示法 | 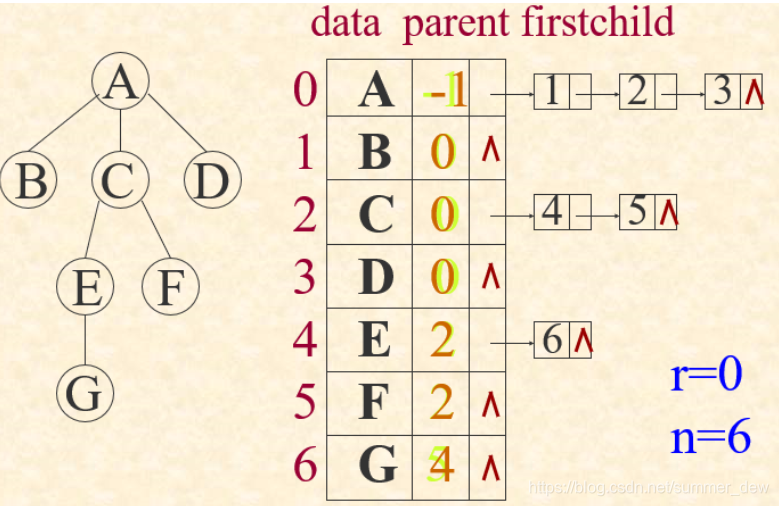 |
||
| 孩子兄弟表示法(二叉链表) | 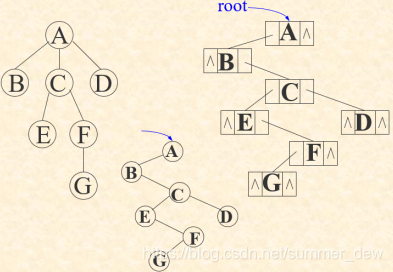 |
 |
父亲牵老大;老大左手牵第一个孩子,右手牵自己的兄弟 |
树和森林遍历问题
| 树 | 森林 | 用二叉链表表示法存储时,对应其二叉树的遍历方式 |
|---|---|---|
| 先根遍历 | 先序遍历 | 先序遍历 |
| 后根遍历 | 中序遍历 | 后序遍历 | 中序遍历 |
【树的中序遍历问题】第二次经过该结点时进行访问
哈夫曼树(最优树)
【哈夫曼树】WPL最小的树称为哈夫曼树或最优树(哈夫曼树就是最优树)
相关概念
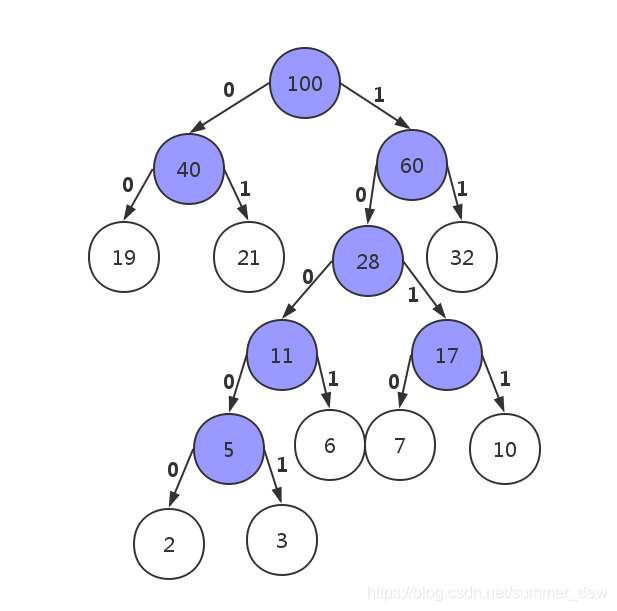
| 概念 | 说明 | 举例 |
|---|---|---|
| 路径 | 两结点的路 | [60->5] 60->28->11->5 |
| 路径长度 | 两结点之间线的数量 | [60->5] 3条 |
| 树的路径长度 | 【根】到每个结点的线之和 | |
| 带权路径长度WPL | 结点到【根】线数量*权重 | [5] 4*5=20 |
| 树的带权路径长度WPL | 叶子结点的WPL之和 | 19*2 + 21*2 + 32*2 + 6*4 + 7*4 + 10*4 + 2*5 + 3*5 = =(19+21+32)*2 + (6+7+10)*4 + (2+3)*5 |
哈夫曼二叉树
特点
| 特点 | 说明 |
|---|---|
| 【重点】哈夫曼二叉树中没有 |
【推广】哈夫曼m叉中只有 【就有公式】 |
| 权值越大的结点,距离根结点越近 | |
| 树的带权路径长度最短 | |
| 由同一组结点得到的哈夫曼树可能不唯一 | 【两种情况】①结点有相同的权重—>【注意】为避免评卷老师误判,一般从左到右选; ②左右子树位置互换 —> 【注意】为避免评卷老师误判,做题时尽量保证: 左子树根权重<右子树根权重 |
哈夫曼编码
【等长码】权重相同时,效率最高;定长使得翻译很方便
| 问题 | 解决 | 哈夫曼编码产生的是最短前缀码 |
|---|---|---|
| 不定长编码的解码结果不唯一(二义性) | 【前缀码】任一字符的编码串都不是另一个字符编码串的前缀—>解码结果唯一 | 被编码的字符都处于叶子结点上,而根通往任一叶子结点的路径都不可能是通往其余叶子结点路径的子路径 —> 任一编码串不可能是其他编码串的子串 |
| 所有的二叉树都是前缀码 | 哈夫曼树的带权路径长度是最短的 | 每个字符的权值是在字符串中出现的次数,路径长度即每个字符编码的长度,出现次数越多的字符编码长度越短 —> 这使得整个字符串被编码后的前缀码长度最短 |
代码
typedef struct node{int w;struct node *lchild,*rchild;}BiTNode, *BiTree;BiTree CreateHufferman(int num[], int n) {BiTree *tmp,p;int k1,k2;int i,j;//创建一个BiTree数组来存结点tmp = (BiTree *)malloc(sizeof(BiTree) * n);for (i=0; i<n; i++) {//创建新的结点tmp[i] = (BiTNode *)malloc(sizeof(BiTNode)); if (!tmp[i]) exit(0);tmp[i]->w = num[i];tmp[i]->lchild = tmp[i]->rchild = NULL;}for (i=1; i<n; i++) { //循环n-1次,构造哈夫曼树//选出前两个k1 = -1;for (j=0; j<n; j++) {if (tmp[j]!=NULL && k1==-1) { //找到了第一个k1 = j;continue; //找k2}if (tmp[j]!=NULL) { //找到了第二个k2 = j;break; //退出}}//找出最小的、次小的for (j=k2; j<n; j++) {if (tmp[j]!=NULL) {if (tmp[j]->w < tmp[k1]->w) { //j < k1k2 = k1; //△k1 = j;} else if (tmp[j]->w < tmp[k2]->w) { //k1 < j < k2k2 = j;}}}//合并k1,k2p = (BiTNode *)malloc(sizeof(BiTNode)); if (!p) exit(0);p->w = tmp[k1]->w + tmp[k2]->w;p->lchild = tmp[k1];p->rchild = tmp[k2];tmp[k1] = p; // 新结点的放到k1的位置tmp[k2] = NULL; // k2位置为空}free(tmp); //删除动态建立的数组tmpreturn p; //返回哈夫曼树的根结点}int GetWPL(BiTree T, int pathLen) {// 叶子结点if (T->lchild==NULL && T->rchild==NULL) return T->w * pathLen;return GetWPL(T->lchild, pathLen+1) + GetWPL(T->rchild, pathLen+1);}void GetCode(BiTree T, int pathLen) {static char tmp[2*MAX-1];int i;if (T->lchild==NULL && T->rchild==NULL) {printf("\n%d\t", T->w);for (i=0; i<pathLen; i++) {printf("%c", tmp[i]);}return ;}//往左走tmp[pathLen] = '0';GetCode(T->lchild, pathLen+1);//往右走tmp[pathLen] = '1';GetCode(T->rchild, pathLen+1);}
哈夫曼n叉树
【哈夫曼n叉树】每次选n个最优的来构造新的结点
【举例】哈夫曼三叉树:每次选3个最优解来构造新的结点
【举例】结点数不够时,用0来补充 —> WPL依旧是最小
例题
| 问题 | 解决 |
|---|---|
| 是否为完全二叉树 | 层次遍历,中间没有NULL结点 |
| 是否为满二叉树 | 1. 判断是否为完全二叉树,并获得总结点数n 2. 结点的总数n和高度h关系: |
| 先序、中序序列确定二叉树 | 1. 先从先序获得根 2. 带着根去中序中确定左右子树 |
| 二叉树叶子结点的个数 |  |
| 二叉树的深度 |  |
| 复制二叉树 | 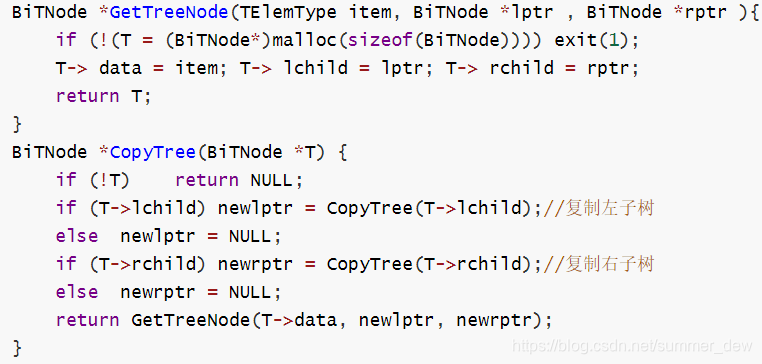 |
| 先序序列创建二叉树 | 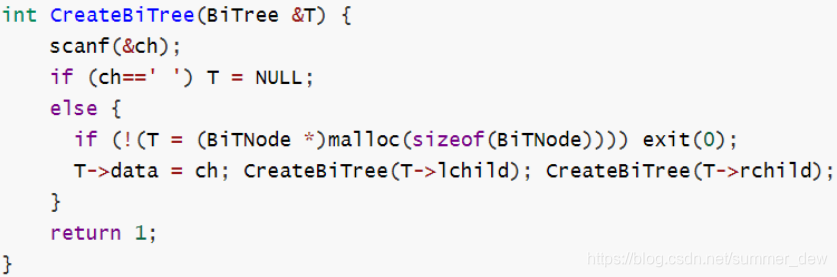 |
| 根到叶子结点的所有路径 |  |
| 中缀表达式建立二叉树 |  |
| 求树的深度(二叉链表表示) | depth=max(h1+1, h2);左子树:是下一级的深度;右子树:是同一级的深度 |
| 输出树中所有从根到叶子的路径 | 左子树根到叶子结点的路径 |
| 由二元组建树存储结构 | 博客 |
若度为m的哈夫曼树,叶子结点个数为n,则非叶子结点的个数为⌈(n-1)/(m-1)⌉ |
1. 叶子结点个数n,即为构造时的初始结点 2. 考虑构造过程,根结点的个数初始为n个 3. 第一次合并,m个结点合成一个结点,根结点减少了m-1个,根结点只剩下n-m+1个 4. 第二次合并,m个结点合成一个结点,根结点继续减少了m-1个,根结点只剩下n-2(m-1) 5. 第k次合并,m个结点合成一个结点,根结点继续减少m-1个,根结点只剩下1个 根据以上,可以得到n-k(m-1)=1 —> k=⌈(n-1)/(m-1)⌉。而k正是非叶子结点的个数,即每次构造新生成的结点 |

若有收获,就点个赞吧
0 人点赞
