外部排序
【为什么要外部排序?】
- CPU只能操作内存,不能支持操作外存,它只能从外存中读入数据到内存中处理
- 内存相对外存来说是非常小的。如果文件中的数据量很大,大到内存无法一次性把所有数据读入到内存,这时就没有办法一次性在内存中完成排序
【外部排序是什么?】
- 对外存中的数据进行排序(相对于内部排序而言)
- 对文件中的数据进行排序
- 将内存作为工作空间来调整外存中数据的位置
【外部排序的3个要点】
- 文件在外存中组织
- 文件在内存中交换
- 文件在内外存之间交换
归并排序法
【归并排序】归并排序不需要将全部记录都读入内存即可完成排序,是外部排序中最常用的方法
| 内部排序的归并算法 | 外部排序的归并算法 | 相同点 |
|---|---|---|
| 子序列存在内存中 | 子序列在外存中(文件中) | 思想一样,都是从小单元归并到单元 |
| 外部排序 归并操作法 |
涉及 内容 |
说明 | 文件内容 |
|---|---|---|---|
| 文件中存有n个数,但内存大小只能存放m个数 | 15 19 04 83 12 27 11 25 16 34 26 07 10 90 06 |
||
| 第一阶段 | 置换-选择排序 | 将文件中的数据处理成多个有序子序列 | 【第一种结果】每个子序列长度相同:4 12 15 19 83 | 11 16 25 27 34 | 6 7 10 26 90【第二种结果】每个子序列长度不同: 4 12 15 19 25 27 34 83 | 7 10 11 16 26 90 | 6 |
| 可选步骤 | 最佳归并树(生成哈夫曼树的方法) | 计算最优的归并方案 | 文件中生成了3个有序子序列,但长度都不相同。在进行二路归并时,策略就有很多:①12先归并,再和3 ②13先归并,再和2 ③23先归并, 再和1 归并方案很多,如何取最优的归并方案呢? |
| 第二阶段 | 败者树(选择每个归并段的最小值) | 对文件中的多个有序子序列进行归并操作 | 4 6 7 10 11 12 15 16 19 25 26 27 34 83 90 |
【评价】每次归并都伴随着I/O操作
【第一阶段】初始归并段的生成(置换-选择排序方法)
【初始归并段的生成】步骤的第一个阶段,即将外存中的数据分成若干个子序列,然后分别排序,这样就得到了若干个有序子序列(称为初始归并段)
【采用什么方法生成若干个有序子序列呢?】置换排序方法
【例子】
- 文件中的记录是:
15、19、04、83、12、27、11、25、16、34、26、07、10、90、06 - 假设缓冲区大小只有4个int

【步骤】假设文件中共有n个记录,缓冲区一次只能读m个记录
- 从文件中读入m个记录,填满缓冲区
- 选出缓冲区中的最小值min,并输出到文件中,作为第一个子序列sub1的第一个元素
- 从文件中读入下一个记录newData,补充刚才最小值的位置
- 如果newData
- 如果newData>=min,则newData还能被输出到sub1中,不堵塞
- 如果newData
- 重复第二步,选出缓冲区的最小值(堵塞的值不选),输出到文件中
- 重复第三步,读入下一个记录newData,判断会不会堵塞
- 重复4、5步,只到缓冲区全部被堵塞,一个子序列就形成了;把堵塞的元素全部解禁,开始第二个子序列
- 直到缓冲区中没有了元素,文件中就形成了多个有序子序列
【总结】
- 可以看到,如果用置换排序方法,在文件中生成的有序子序列的长度(初始归并段)不一定是相同的
此例子中,文件中共形成3个有序子序列,长度都不相同 - 在此步骤结束后,即可对3个有序子序列进行归并排序,完成对文件中数据排序的工作
【可选步骤】最佳归并树的建立(哈夫曼树)
【问题】通过第一阶段中,得到了多个长度不相同的有序子序列,如何确定最佳的归并方案?
【答】可以使用哈夫曼树来确定归并的顺序:让短的初始归并段最先归并,长的初始归并段后归并,就可以使I/O次数达到最小
【I/O次数计算方法】I/O次数=带权路径长度*2
【举例】由第一步(置换-选择排序)得到9个初始归并段(有序子序列),其长度一次为9、30、12、18、3、17、2、6、24。若我们采用三路归并,请写出三路归并的最佳归并树,并计算I/O次数
- I/O次数=2*WPL=446
【第二阶段】归并阶段(用败者树选择每个归并段的最小值)
【归并阶段】假设要对5个不同长度的有序子序列(初始归并段)进行5路的归并排序
【常规步骤】
- 在5个有序子序列的头选出min,最小值所在序列的指针后移,并将min输出到外存中
- 继续从5个序列中选出最小值,输出
- 重复第二步,直到5个序列的全部元素都被选完
【败者树的作用】一般步骤中,每次选择的最小值没有用到上一次比较的结果。而使用败者树,可以记录之前比较的结果,大大减少时间复杂度,只是建树的时候比较麻烦
- 常规步骤下一共需要比较logk(m)(n-1)(k-1)次
- 每次对k路有序子序列选择最小值,则需要比较k-1次
- 文件中一共有n个记录,则需要(n-1)*(k-1)次比较
- 若一共有m个归并段,则归并的趟数是logkm
- 引入败者树之后,共需要logk(m)(n-1)log2k次比较
- 每次不需要k-1次比较,只需要log2k次比较(第一次建树除外)
【败者树是什么?】一个完全二叉树(ls[0]不属于败者树的一部分),采用顺序存储结构
【k路归并败者树】k路归并的k是指b[]的长度,即有k个归并段的第一个元素参与比赛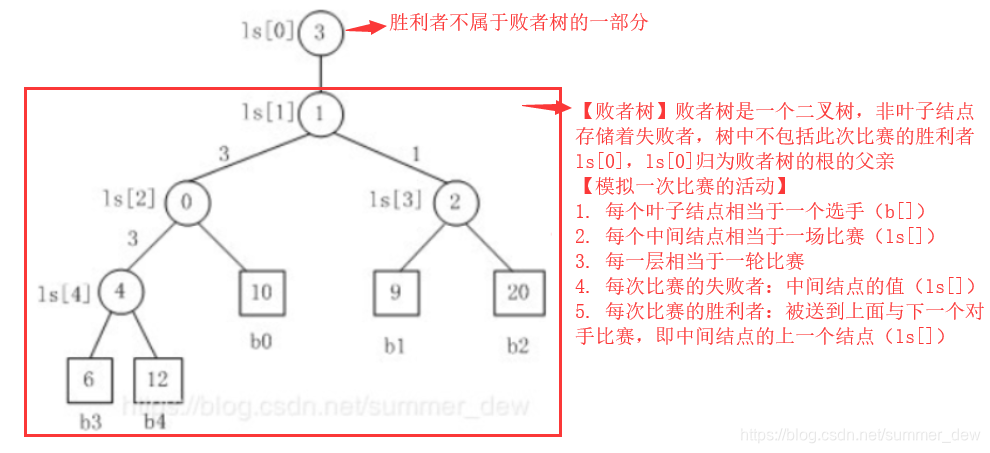
【引入败者树后归并排序的步骤】
- 根据k个归并段的头指针建立败者树
- 取出败者树根对应的最小值
- 然后用归并段的下一个值替换最小值的位置,重新调整败者树
- 重复2、3两步,直到归并段为空
评价
【空间复杂度】O(1)
【时间复杂度】
| 步骤 | 说明 | 时间复杂度 | I/O操作 |
|---|---|---|---|
| 【第一阶段】初始归并段的生成 | 置换选择排序 | 选择最值那一步的时间复杂度要根据考试要求选择算法而定 | 所有记录都要进行两次I/O操作 |
| 【可选阶段】最佳归并树 | 生成哈夫曼树 | ||
| 【第二阶段】选择最值 | 用败者树选择最值 | 1. 【败者树建树】O(klog2k) 2. k路归并的败者树高度⌈log2k⌉+1,从k个记录中选择最值需要进行⌈log2k⌉此比较,即时间复杂度是O(log2k) |
|
| 【第二阶段】归并 | 归并 | m个初始归并段进行k路归并,归并的趟数⌈logkm⌉ | 每次归并,所有记录都要进行两次I/O操作 |
总结

参考文章

若有收获,就点个赞吧
0 人点赞
