快速入门教程
语法
常用的元字符
量词元字符:设置出现的次数
| * | 0个或多个 |
|---|---|
| + | 一个或多个 |
| ? | 0个或一个 |
| {n} | 出现n次 |
| {n, } | 出现n到多次 |
| {n, m} | 出现n到m次 |
转义元字符:单个或组合在一起代表特殊含义
| \ | 转义字符 | \b | 单词边界 |
|---|---|---|---|
| ^ | 以什么开头 | $ | 以什么结尾 |
| . | 除\n(换行符)以外的所有字符 | \w | 数字、字母、下划线中的任意字符 |
| \d | 表示数字 | \D | 表示非数字 |
| \n | 换行符 | \r | 换页符 |
| \s | 一个空白符(空格、换页符、制表符) | \t | 制表符(tab键,4个空格) |
| \f | 换页符 | () | 表示分组 |
| x|y | x或y中的一个字符 | [xyz] | x或y或z中的一个字符 |
| [^xyz] | 除x/y/z之外的任意字符 | [a-z] | 指定a-z范围中的任意字符 |
| (?:) | 只匹配不捕获 | ||
| (?=exp) | 符合包含exp,匹配出左边的字符 | (?<=exp) | 符合包含exp,匹配出右侧字符 |
| (?!exp) | 符合不包含exp,匹配出左边字符 | (?<!exp) | 符合不包含exp,匹配出右侧字符 |
(?=) 正 先行断言:x(?=y) 表示匹配x仅仅当x后面跟着y。
(?!) 负 先行断言:x(?!y) 表示仅仅当x后面不跟着y时匹配x
(?<=) 正 后行预查 (?<=y)x 表示匹配x仅当x前面是y
(?<!) 负 后行预查 (?<!)x 表示匹配x仅当x前面不是y时匹配x
注:先行后行表示方向【先行匹配出左侧的字符,后行表示右侧字符】。正负表示存在还是否定
修饰符
i 表示不区分大小写
g 表示全局匹配
m 表示多行匹配
s 表示允许.匹配换行符
u 使用unicode码的模式进行匹配
y 执行“粘性(sticky)”搜索,匹配从目标字符串的当前位置开始。
惰性(.?)和贪婪性(.),?号的使用
.* 是单个字符匹配任意次,即贪婪匹配
// 默认的贪婪模式匹配,会匹配到后边的}符合,即把中间的years old,Bob is内容给替换掉了var str = 'Anna is {age} years old,Bob is {age} years old too';var expr = /{.*}/g;console.log(str.replace(expr, '13'));/*输出: Anna is 13 years old too*/
.*? 是满足条件的情况只匹配一次,即懒惰匹配
// 懒惰匹配,匹配到}就立马结束。把两个{age}都匹配是因为g修饰符var str = 'Anna is {age} years old,Bob is {age} years old too';var expr = /{.*?}/g;console.log(str.replace(expr, '13'));/*输出: Anna is 13 years old,Bob is 13 years old too*/
正则的方法exec和test
exec返回值含义
let words= "happy learn RegExp's exec method";let regx=/(\w{3})Ex(.{3})/g; //第一个括号可以用\w进行匹配第二个必须用.才能匹配到',否则为nullconsole.log(regx.exec(words));// 返回数组["RegExp's",'Reg',"p's",index: 12,input: "happy learn RegExp's exec method",groups: undefined]
exec()接受一个字符串参数,返回包含第一个匹配项信息的数组;如果没有匹配项的情况下返回null
返回的数组是Array实例,并且包含额外的属性: index 和 input, groups。
其中,
- index 表示匹配项在字符串中的位置。(匹配项为RegExp’s ,对应的位置是16);
- input 表示应用正则表达式的字符串。(happy learn RegExp’s exec method);
在数组中,
- 第一项:表示与整个模式匹配的字符串 (代码中的 RegExp’s 匹配 正则校验);
其它项: 与表达式中用()包裹起来的,即捕获组匹配的字符串,第二项表示第一个捕获组的值,第三项表示第二个括号捕获的值(如果模式中没有捕获组regx = /\w{3}Ex.{3}/g;,则该数组只包含一项即RegExp’s)
let words = "happy learn RegExp's exec method";let regx = /\w{3}Ex.{3}/g; // 没有捕获组console.log(regx.exec(words));["RegExp's",index: 12,input: "happy learn RegExp's exec method",groups: undefined]
test返回布尔值
let words = "happy learn RegExp's test method";let regx = /\w{3}Ex.{3}/g;let regOk = /\w{3}Ok.{3}/g;console.log(regx.test(words)); // trueconsole.log(regOk.test(words)); // false
字符串的正则方法有:match、replace
match的返回值
match的使用和exec的作用一样,只不过是string身上的方法。
let words = "happy learn string's match method";console.log(words.match(/(\w{3})ing(.{2})/));// 返回结果["string's",'str',"'s",index: 12,input: "happy learn string's match method",groups: undefined]
replace的返回值加回调
匹配值并进行替换
var re = /apples/gi;var str = "Apples are round, and apples are juicy.";var newstr = str.replace(re, "oranges");console.log(newstr);//输出内容 oranges are round, and oranges are juicy.
打印出通过()捕获的内容
let words = "happy learn string's replace method";words.replace(/(\w{3})ing(.{2})/g, function ($1, $2) {console.log($1, $2); // $1 $2分别为两个()捕获到的内容});
将所有单词首字母大写
let words = "hello everybody, come on!";console.log(words.replace(/\b\w*\b/g, (word) => {return word.substring(0, 1).toUpperCase() + word.substring(1);}));// Hello Everybody, Come On!
将句首单词首字母大写
let words = "everybody, go! ";console.log(words.replace(/^\b(\w)/g, (L) => L.toUpperCase()));
处理数字千分位
https://www.yuque.com/beiniaonanyou/igewkv/gmn3o8#auIN0
去除所有空格
let words = "every body, go!";console.log(words.replace(/\s+/g, ""));// everybody,go!
去除左侧空格
let words = " everybody, go! ";console.log(words.replace(/^\s*/g, ""));// everybody, go!
去除右侧空格
let words = " everybody, go! ";console.log(words.replace(/\s*$/g, ""));// everybody, go!
去除两端空格
let words = " every body, go! ";console.log(words.replace(/(^\s*)|(\s*$)/g, ""));// every body, go!
正则表达式的先行断言(lookahead)和后行断言(lookbehind)
正则表达式的先行断言和后行断言一共有 4 种形式:
(?=pattern)零宽正向先行断言(zero-width positive lookahead assertion)
- (?!pattern)零宽负向先行断言(zero-width negative lookahead assertion)
- (?<=pattern)零宽正向后行断言(zero-width positive lookbehind assertion)
- (?<!pattern)零宽负向后行断言(zero-width negative lookbehind assertion)
这里面的pattern是一个正则表达式。
如同^代表开头,$代表结尾,\b代表单词边界一样,先行断言和后行断言也有类似的作用,它们只匹配某些位置,在匹配过程中,不占用字符,所以被称为“零宽”。所谓位置,是指字符串中(每行)第一个字符的左边、最后一个字符的右边以及相邻字符的中间(假设文字方向是头左尾右)。
下面分别举例来说明这 4 种断言的含义。
(?=p) 正向先行断言
代表字符串中的一个位置,紧接该位置之后的字符序列能够匹配 p。
(?=p)表示p前面的位置,p只是一个参数值。
例如对“a regular expression”,要想匹配 regular 中的 re,但不能匹配 expression 中的 re,可以用re(?=gular),该表达式限定 re 右边的位置,这个位置之后是 gular,但并不消耗 gular 这些字符。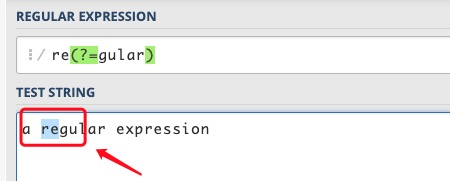
将表达式改为re(?=gular).,将会匹配 reg,元字符.匹配了g,括号这一砣匹配了e和g之间的位置。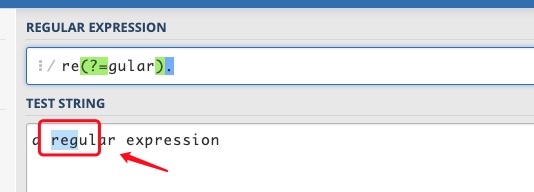
(?!p) 负向先行断言
代表字符串中的一个位置,紧接该位置之后的字符序列不能匹配 p。
表示不是p字母前面的位置,
例如对“regex represents regular expression”,要想匹配除 regex 和 regular 之外的 re,可以用re(?!g),该表达式限定了re右边的位置,这个位置后面不是字符g。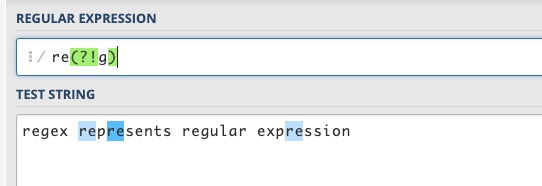
正向和负向的区别,在于该位置之后的字符能否匹配括号中的表达式。
先行和后行的区别,在于看匹配参数的左侧还是右侧。先行—-左侧,后行—-右侧
(?<=p) 正向后行断言
代表字符串中的一个位置,紧接该位置之前的字符序列能够匹配 p。
p字母右侧的位置
例如对regex represents regular expression,有 4 个单词,要想匹配单词内部的 re,但不匹配单词开头的 re,可以用(?<=\w)re,单词内部的 re,在 re 前面应该是一个单词字符。
之所以叫后行断言,是因为正则表达式引擎在匹配字符串和表达式时,是从前向后逐个扫描字符串中的字符,并判断是否与表达式符合,当在表达式中遇到该断言时,正则表达式引擎需要往字符串前端检测已扫描过的字符,相对于扫描方向是向后的。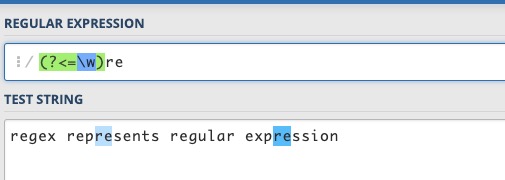
(?<!p) 负向后行断言
代表字符串中的一个位置,紧接该位置之前的字符序列不能匹配 p。
表示(不是p字母)右侧的位置。
例如对“regex represents regular expression”这个字符串,要想匹配单词开头的 re,可以用(?<!\w)re。单词开头的re,在本例中,也就是指不在单词内部的re,即re前面不是单词字符。当然也可以用\bre来匹配。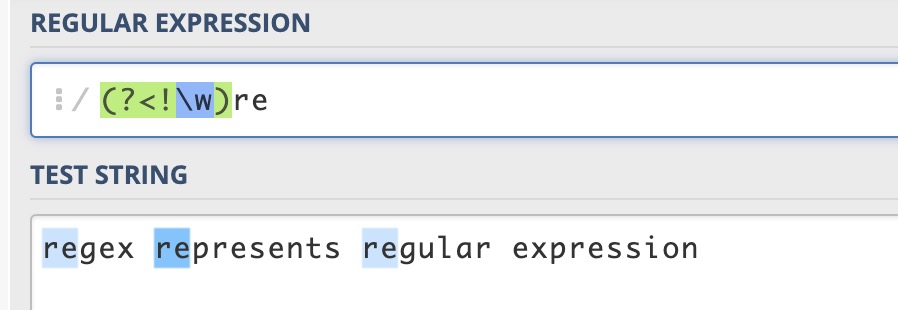
对于这 4 个断言的理解,可以从两个方面入手:
- 1、关于先行(lookahead)和后行(lookbehind):正则表达式引擎在执行字符串和表达式匹配时,会从头到尾(从前到后)连续扫描字符串中的字符,设想有一个扫描指针指向字符边界处并随匹配过程移动。先行断言,是当扫描指针位于某处时,引擎会尝试匹配指针还未扫过的字符,先于指针到达该字符,故称为先行。后行断言,引擎会尝试匹配指针已扫过的字符,后于指针到达该字符,故称为后行。
- 2、关于正向(positive)和负向(negative):正向就表示匹配括号中的表达式,负向表示不匹配。
对这 4 个断言形式的记忆:
- 1、先行和后行:后行断言(?<=pattern)、(?<!pattern)中,有个小于号,同时也是箭头,对于自左至右的文本方向,这个箭头是指向后的,这也比较符合我们的习惯。把小于号去掉,就是先行断言。
- 2、正向和负向:不等于(!=)、逻辑非(!)都是用!号来表示,所以有!号的形式表示不匹配、负向;将!号换成=号,就表示匹配、正向。
我们经常用正则表达式来检测一个字符串中包含某个子串,要表示一个字符串中不包含某个字符或某些字符也很容易,用[^…]形式就可以了。要表示一个字符串中不包含某个子串(由字符序列构成)呢?
用[^…]这种形式就不行了,这时就要用到(负向)先行断言或后行断言、或同时使用。
例如判断一句话中包含this,但不包含that。
包含this比较好办,一句话中不包含that,可以认为这句话中每个字符的前面都不是that或每个字符的后面都不是that。正则表达式如下:
^((?<!that).)this((?<!that).)$
或
^(.(?!that))this(.(?!that))$
对于this is runoob test这句话,两个表达式都能够匹配成功,而this and that is runoob test都匹配失败。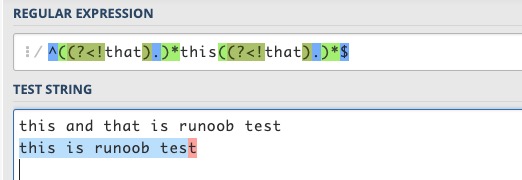
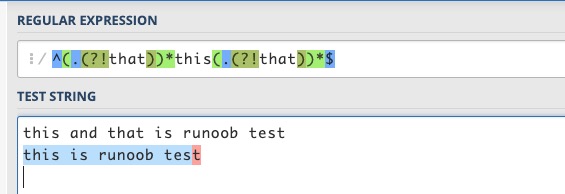
在一般情况下,这两个表达式基本上都能够满足要求了。考虑极端情况,如一句话以that开头、以that结尾、that和this连在一起时,上述表达式就可能不胜任了。 如runoob thatthis is the case或者this is the case, not that等。
只要灵活运用这几个断言,就很容易解决:
^(.(?<!that))this(.(?<!that))$
^(.(?<!that))this((?!that).)$
^((?!that).)this(.(?<!that))$
^((?!that).)this((?!that).)$
这 4 个正则表达式测试上述的几句话,结果都能够满足要求。
上述 4 种断言,括号里的 pattern 本身是一个正则表达式。但对 2 种后行断言有所限制,在 Perl 和 Python 中,这个表达式必须是定长(fixed length)的,即不能使用*、+、?等元字符,如(?<=abc)没有问题,但(?<=a*bc)是不被支持的,特别是当表达式中含有|连接的分支时,各个分支的长度必须相同。之所以不支持变长表达式,是因为当引擎检查后行断言时,无法确定要回溯多少步。Java 支持?、{m}、{n,m}等符号,但同样不支持*、+字符。Javascript 干脆不支持后行断言,不过一般来说,这不是太大的问题。
先行断言和后行断言某种程度上就好比使用if语句对匹配的字符前后做判断验证。
以下列出 ?=、?<=、?!、?<!= 的使用
exp1(?=exp2):查找 exp2 前面的 exp1。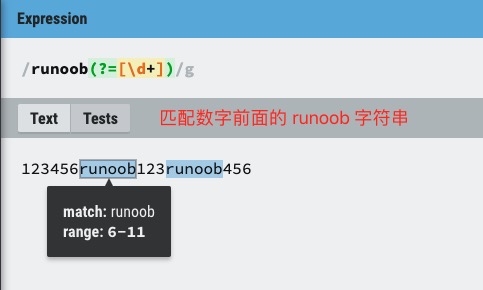
(?<=exp2)exp1:查找 exp2 后面的 exp1。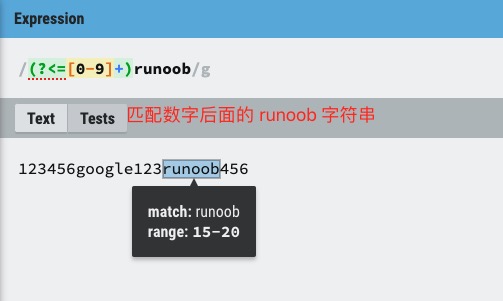
exp1(?!exp2):查找后面不是 exp2 的 exp1。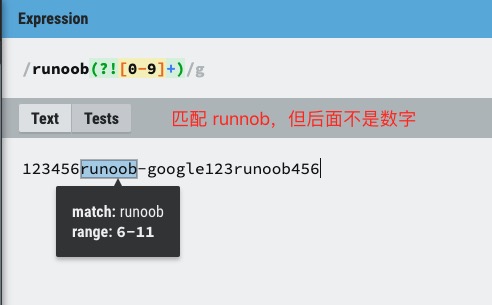
(?<!=exp2)exp1:查找前面不是 exp2 的 exp1。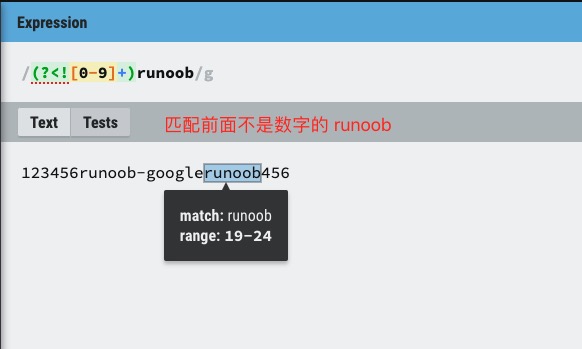
案例
数字千分位分割表示法

'12323232456'.replace(/(\d{1,3})(?=(\d{3})+$)/g,item=> item + ',')
分析:
首先匹配出一个逗号,使用(?=\d{3}$)就可以做到:
var result = "12345678".replace(/(?=\d{3}$)/g, ',')console.log(result);// => "12345,678"
匹配出所有逗号,逗号出现的位置,要求后面3个数字一组,也就是\d{3}至少出现一次。可以使用量词+
var result = "12345678".replace(/(?=(\d{3})+$)/g, ',')console.log(result);// => "12,345,678"
此时的正则不能适应所有情况,当长度是3的整数倍,就会在最前面加一个“,”,出现此现象是因为该正则从右往左一旦是3的倍数就在前面位置替换为“,”。
var result = "123456789".replace(/(?=(\d{3})+$)/g, ',')console.log(result);// => ",123,456,789"
解决办法:要求匹配到的位置不能是开头。匹配开头可以使用^,但要求这个位置不是开头怎么办?可以使用(?!^) ```javascript var string1 = “12345678”, string2 = “123456789”; reg = /(?!^)(?=(\d{3})+$)/g;
var result = string1.replace(reg, ‘,’) console.log(result); // => “12,345,678”
result = string2.replace(reg, ‘,’); console.log(result); // => “123,456,789”
5. 匹配其他特殊情境。把"12345678 123456789"替换成"12,345,678 123,456,789"修改正则,把里面的开头^和结尾$,替换成\b:```javascriptvar string = "12345678 123456789",reg = /(?!\b)(?=(\d{3})+\b)/g;var result = string.replace(reg, ',')console.log(result);// => "12,345,678 123,456,789"
(?!\b)怎么理解呢?要求当前是一个位置,但不是\b前面的位置,\b表示单词的边界。以边界结尾,但是不能以边界开头。
匹配两个字符串A与B中间的字符串包含A与B:
表达式: A.*?B(“.“表示任意字符,“?”表示匹配0个或多个)
示例: Abaidu.comB
结果: Awww.apizl.comB
匹配两个字符串A与B中间的字符串包含A但是不包含B:
表达式: A.*?(?=B)
示例: Awww.apizl.comB
结果: Awww.apizl.com
匹配两个字符串A与B中间的字符串且不包含A与B:
表达式: (?<=A).*?(?=B)
如果不包含前面匹配的字符写法(?<=要匹配的开始字符),不包含后面要匹配的字符写法(?=要匹配的结束字符)
示例: Awww.baidu.comB 结果: www.baidu.com

若有收获,就点个赞吧
0 人点赞
