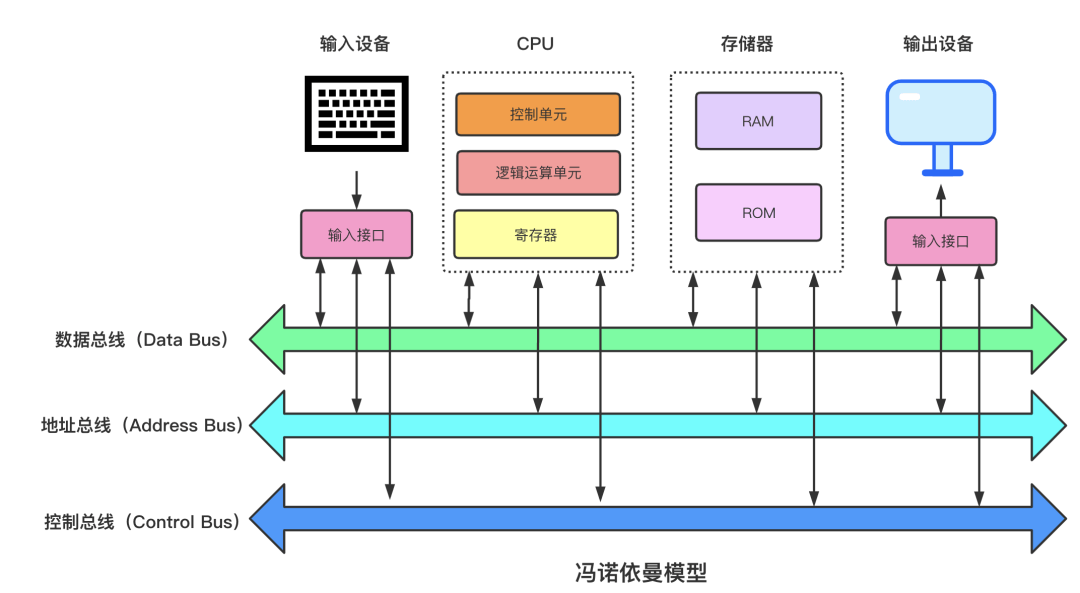
冯*诺伊曼体系
中央处理器[CPU]、存储器、运算器、输入设备、输出设备。
- CPU:计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。cpu由控制单元,逻辑运算单元,寄存器组成。cpu用寄存器存储计算时需要的数据,寄存器分为三种:
- 通用寄存器:存储进行运算的数据
- 程序计数器:存储CPU要执行的下一条指令所在的内存地址
- 指令寄存器:存放程序计数器指向的指令本身
- 存储器:代码根数据在RAM和ROM中的线性存储。数据存储的单位是二进制位,最小的存储单位是字节。
- 输入/输出设备:输入设备向计算机输入数据,经过计算机计算后把结果显示出来
- 总线:总线是CPU和内存以及其他设备之间的通信,总线主要三种:
- 地址总线:用于指定CPU将要操作的内存地址
- 数据总线:读写内存数据
- 控制总线:用于发送和接收信号,比如中断、设备复位等信号。
CPU
CPU简介
CPU是计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。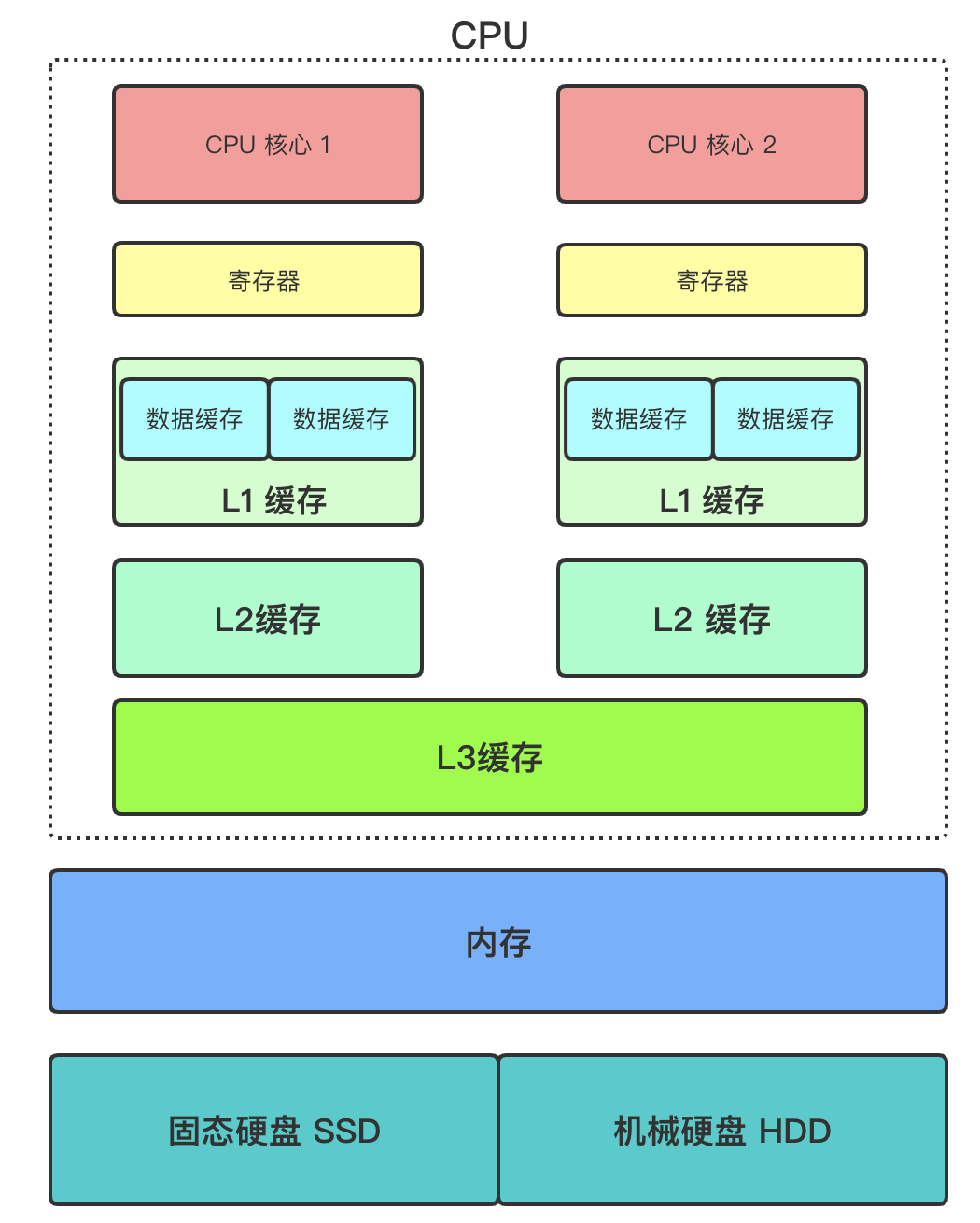
CPU核心:一般一个CPU会有多个CPU核心,平常说的多核是指在一枚处理器中集成两个或多个完整的计算引擎。核跟CPU的关系是:核属于CPU的一部分。寄存器:最靠近CPU对存储单元,32位CPU寄存器可存储4字节,64位寄存器可存储8字节。寄存器访问速度一般是半个CPU时钟周期,属于纳秒级别,L1缓存:每个CPU核心都有,用来缓存数据跟指令,访问空间大小一般在32~256KB,访问速度一般是2~4个CPU时钟周期。cat /sys/devices/system/cpu/cpu0/cache/index0/size # L1 数据缓存cat /sys/devices/system/cpu/cpu0/cache/index1/size # L1 指令缓存
L2缓存:每个CPU核心都有,访问空间大小在128KB~2MB,访问速度一般是10~20个CPU时钟周期。cat /sys/devices/system/cpu/cpu0/cache/index2/size # L2 缓存容量大小
L3缓存:多个CPU核心共用,访问空间大小在2MB~64MB,访问速度一般是20~60个CPU时钟周期。cat /sys/devices/system/cpu/cpu0/cache/index3/size # L3 缓存容量大小
内存:多个CPU共用,现在一般是4G~512G,访问速度一般是200~300个CPU时钟周期。固体硬盘SSD:现在台式机主流都会配备,上述的寄存器、缓存、内存都是断电数据立马丢失的,而SSD里不会丢失,大小一般是128G~1T,比内存慢10~1000倍。机械盘HDD:很早以前流行的硬盘了,容量可在512G~8T不等,访问速度比内存慢10W倍不等。访问数据顺序:CPU在拿数据处理的时候几乎也是按照上面说得流程来操纵的,只有上面一层找不到才会找下一层。Cache Line: CPU读取数据时会按照 Cache Line 方式把数据加载到缓存中,每个Cacheline = 64KB,因为L1、L2是每个核独有到可能会触发伪共享,所以可能会将数据划分到不同到CacheLine中来避免伪共享,比如在JDK8 新增加的 LongAdder 就涉及到此知识点。
- 伪共享:缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
java内存模型: JMM: 数据经过种种分层会导致访问速度在不断提升,同时也带来了各种问题,多个CPU同时操作相同数据可能会造成各种安全问题,需要加锁。
CPU访问方式
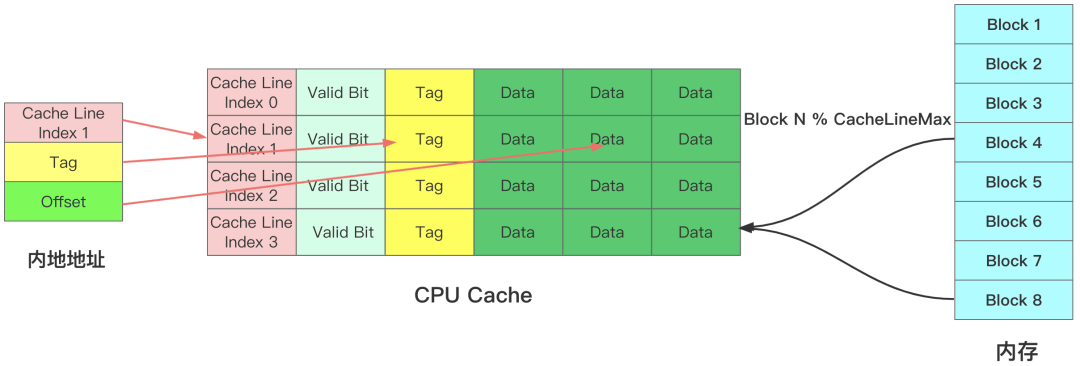
内存数据映射到CPU Cache 时通过公式 Block N % CacheLineMax决定内存Block数据放到那个CPU Cache Line 里。CPU Cache 主要有4部分组成。
- Cache Line Index :CPU缓存读取数据时不是按照字节来读取的,而是按照CacheLine方式存储跟读取数据的。
- Valid Bit : 有效位标志符,值为0时表示无论 CPU Line 中是否有数据,CPU 都会直接访问内存,重新加载数据。
- Tag:组标记,用来标记内存中不同BLock映射到相同CacheLine,用Tag来区分不同的内存Block。
- Data:真实到内存数据信息。
CPU真实访问内存数据时只需要指定三个部分即可。
- Cache Line Index :要访问到Cache Line 位置。
- Tag:表示用那个数据块。
Offset:CPU从CPU Cache 读取数据时不是直接读取Cache Line整个数据块,而是读取CPU所需的数据片段,称为Word。如何找到Word就需要个偏移量Offset。
CPU访问速度
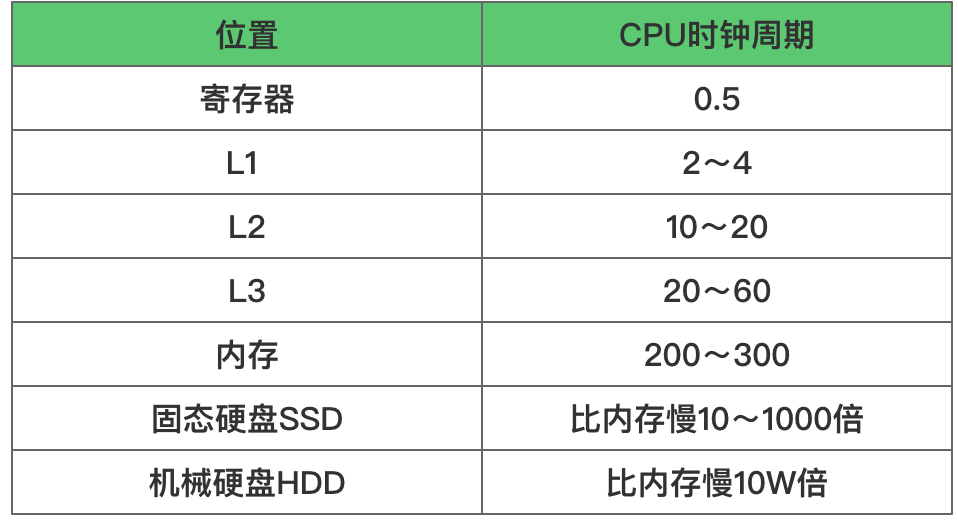
如上图所示,CPU访问速度是逐步变慢,所以CPU访问数据时需尽量在距离CPU近的高速缓存区访问,根据摩尔定律CPU访问速度每18个月就会翻倍,而内存的访问每18个月也就增长10% 左右,导致的结果就是CPU跟内存访问性能差距逐步变大,那如何尽可能提高CPU缓存命中率呢?数据缓存:遍历数据时候按照内存布局顺序访问,因为CPU Cache是根据Cache Line批量操作数据的,所以你顺序读取数据会提速,道理跟磁盘顺序写一样。
- 指令缓存:尽可能的提供有规律的条件分支语句,让 CPU 的分支预测器发挥作用,进一步提高执行的效率,因为CPU是自带分支预测器,自动提前将可能需要的指令放到指令缓存区。
- 线程绑定到CPU:一个任务A在前一个时间片用CPU核心1 运行,后一个时间片用CPU核心2 运行,这样缓存L1、L2就浪费了。因此操作系统提供了将进程或者线程绑定到某一颗 CPU 上运行的能力。如 Linux 上提供了 sched_setaffinity 方法实现这一功能,其他操作系统也有类似功能的 API 可用。当多线程同时执行密集计算,且 CPU 缓存命中率很高时,如果将每个线程分别绑定在不同的 CPU 核心上,性能便会获得非常可观的提升。
操作系统

若有收获,就点个赞吧
0 人点赞
